前言
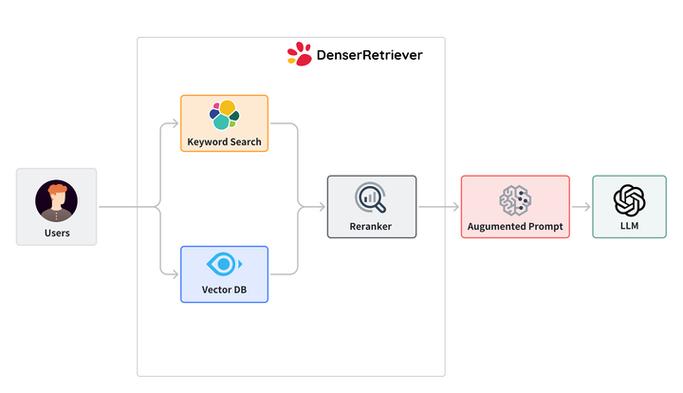
在上一章【课程总结】day28:大模型之深入探索RAG流程中,我们对RAG流程中 文档读取(LOAD) -> 文档切分(SPLIT) -> 向量化(EMBED) -> 存储(STORE) 进行了深入了解,本章将接着深入了解 解析(Retrieval) 的使用
解析器简介
简介:在 RAG(Retrieval-Augmented Generation)流程中,Retrieval(检索)是关键环节,其主要目标是从大量文档或知识库中提取与用户查询相关的信息。
目的:
- 信息获取:根据用户的查询,从外部知识库中获取相关文档或片段,以增强生成模型的上下文信息。
- 提高准确性:通过提供具体的、相关的信息,帮助生成模型(如语言模型)产生更准确和上下文相关的回答。
流程
- 用户查询:用户输入一个查询或问题。
- 检索器:使用检索算法(如 BM25、TF-IDF 或基于嵌入的检索)搜索知识库,找到与查询最相关的文档。
- 文档评分:对检索到的文档进行评分,通常依据相关性得分来排序。
- 返回结果:将最相关的文档或片段返回给生成模型。
解析器的基础使用
创建知识库
第一步:启动Chroma数据库
chroma run --path chroma_xiyou --port 8000第二步:使用RAG基础流程:Load->Split->EMBED->STORE创建一个知识库
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders import PyMuPDFLoader
from langchain_chroma import Chroma
from chromadb import Settings
from chromadb import Client
from utils import get_ernie_models
import chromadb
# 连接大模型
llm_ernie, chat_ernie, embed_ernie = get_ernie_models()
# 初始化 HuggingFaceEmbeddings
embedding_function = HuggingFaceEmbeddings(model_name="bert-base-chinese")
# 加载文档
pdf_loader = PyMuPDFLoader("testfiles/西游记.pdf")
documents = pdf_loader.load()
# 切分文档
spliter = RecursiveCharacterTextSplitter(chunk_size=128, chunk_overlap=64)
docs = spliter.split_documents(documents)
# 配置连接信息
client = chromadb.HttpClient(host='localhost', port=8000)
chroma_db = Chroma(
embedding_function=embedding_function,
client=client
)
batch_size = 6 # 每次处理的样本数量
# 分批入库
for i in range(0, len(docs), batch_size):
batch = docs[i:i + batch_size] # 获取当前批次的样本
print(f'Processing batch {i} to {i + batch_size}, total {len(batch)} samples')
chroma_db.add_documents(documents=batch) # 入库说明:
- 向量化说明:由于Qwen和百度千帆的向量接口限制较多,对于向量化西游记这本书来说,经常会遇到超出限制等问题,所以此处我将向量化接口换为HuggingFaceEmbeddings(),该接口可能会存在被Ban的风险,请自行更换向量化接口。
- 测试文档:西游记下载地址请见夸克网盘:西游记
创建解析器
第三步:创建一个解析器
retriever = chroma_db.as_retriever()创建chain链
创建chain链有两种方法:一种是管道符连接,一种是使用 create_retrieval_chain 。本章我们两种方法都做尝试,以便对比代码的写法。
方式一:传统的管道符构建chain
# RAG系统经典的 Prompt
prompt = ChatPromptTemplate.from_messages([
("human", """You are an assistant for question-answering tasks. Use the following pieces
of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:""")
])
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# RAG 链
rag_chain = (
{"context": retriever | format_docs,
"question": RunnablePassthrough()}
| prompt
| chat_ernie
| StrOutputParser()
)
rag_chain.invoke(input="孙悟空三打白骨精时,白骨精分别变成了哪些形态?")运行结果:

方式二:使用create_retrieval_chain构建
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", """Answer any use questions based solely on the context below:
<context>
{context}
</context>"""),
("placeholder", "{chat_history}"),
("human", "{input}"),
])
combine_docs_chain = create_stuff_documents_chain(
llm=chat_ernie,prompt= prompt
)
chain = create_retrieval_chain(retriever=retriever, combine_docs_chain=combine_docs_chain)
chain.invoke(input={"input":"孙悟空三打白骨精时,白骨精分别变成了哪些形态?"})说明:
- 上述的prompt可以在smith.langchain.com上查询
langchain-ai/retrieval-qa-chat得到。
运行结果:

通过对比,可以看到使用 create_retrieval_chain 创建chain时,可以减少format_docs()步骤以及使用管道符部分的代码量,简化调用步骤。
以上调用即为完整的解析器使用流程,其中第三步中 retriever = chroma_db.as_retriever() 可以有多种方式构建解析器。本章内容,我们着重对此深入研究。
解析器的不同类型
除了上面基础的向量存储检索器之外,Langchain 还提供了多种高级检索类型,包括多查询检索器(MultiQueryRetriever)、结合检索器(EnsembleRetriever)等。
多查询检索器 MultiQueryRetriever
简介:
MultiQueryRetriever 是一种检索算法,它通过使用大型语言模型(LLM)生成多个查询,从而自动化提示调优过程。
功能:
它为给定的用户输入查询生成多个不同视角的查询。对于每个查询,它检索一组相关文档,并通过所有查询的唯一联合来获得更大的一组潜在相关文档。这种方法提高了检索的准确性和多样性。
使用场景:
当用户的问题复杂并且需要多条不同的信息来回答时,MultiQueryRetriever 特别有用。它可以在需要关于多个主题的信息时提供更全面的结果
使用方法:
第一步:构建知识库(此处复用上面的知识库,详细内容不再赘述)
第二步:使用MultiQueryRetriever
import logging
from langchain.retrievers.multi_query import MultiQueryRetriever
question = "孙悟空三打白骨精时,白骨精分别变成了哪些形态?"
# 把向量操作封装为一个基本检索器
retriever = chroma_db.as_retriever()
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=chroma_db.as_retriever(), llm=chat_ernie
)
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
unique_docs = retriever_from_llm.get_relevant_documents(query=question)
unique_docs
print(f'返回的文档个数:{len(unique_docs)}')
print(f'返回的文档内容:')
for doc in unique_docs:
print(doc.page_content)运行结果:
INFO:langchain.retrievers.multi_query:Generated
queries: ['以下是三个不同版本的生成问题,旨在从不同角度探索原始问题的相关信息:',
'1. 孙悟空在三打白骨精的情节中,白骨精分别化作了哪些生物或物体形态?',
'2. 孙悟空三打白骨精时,白骨精变身的形态有哪些?请详细列出。',
'3. 在《西游记》中,白骨精在孙悟空三打她的过程中,她变换成了哪些不同的身份或外观?',
'希望以上问题可以帮助你从不同的角度获取相关信息,从而更全面地回答原始问题。']
第三步:使用 create_retrieval_chain 进行完整查询
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
# 创建结合文档的链
prompt = ChatPromptTemplate.from_messages([
("system", """Answer any user questions based solely on the context below:
<context>
{context}
</context>"""),
("placeholder", "{chat_history}"),
("human", "{input}"),
])
combine_docs_chain = create_stuff_documents_chain(
llm=chat_ernie, prompt=prompt
)
# 创建检索链
chain = create_retrieval_chain(retriever=retriever_from_llm, combine_docs_chain=combine_docs_chain)
# 使用链进行查询
result = chain.invoke(input={"input": question})
# 输出最终结果
print("最终回答:", result)运行结果:
最终回答: {'input': '孙悟空三打白骨精时,白骨精分别变成了哪些形态?',
'context': [
Document(metadata={'author': '吴承恩', 'creationDate': "D:20240329064911+00'00'", 'creator': 'calibre 3.23.0 [https://calibre-ebook.com]', 'file_path': 'testfiles/西游记.pdf', 'format': 'PDF 1.4', 'keywords': '', 'modDate': '', 'page': 7, 'producer': 'calibre 3.23.0 [https://calibre-ebook.com]', 'source': 'testfiles/西游记.pdf', 'subject': '', 'title': '西游记(人文社经典彩皮版,长销70年,以明代世德堂本为底本;三次修订重校;豆瓣上万条评论;2020年教育部指导目录图书)', 'total_pages': 675, 'trapped': ''}, page_content='了许多新的成果,为了能让广大读者更好地理解该作品,这次特意邀请北京大学刘勇强教授重新为该书撰\n写了前言。\n六、关于取经途中所遇的八十一难顺序,第九十九回诸神给观音菩萨提供的簿子所记,与小说的叙述'),
....(内容过多,此处省略)
Document(metadata={'author': '吴承恩', 'creationDate': "D:20240329064911+00'00'", 'creator': 'calibre 3.23.0 [https://calibre-ebook.com]', 'file_path': 'testfiles/西游记.pdf', 'format': 'PDF 1.4', 'keywords': '', 'modDate': '', 'page': 6, 'producer': 'calibre 3.23.0 [https://calibre-ebook.com]', 'source': 'testfiles/西游记.pdf', 'subject': '', 'title': '西游记(人文社经典彩皮版,长销70年,以明代世德堂本为底本;三次修订重校;豆瓣上万条评论;2020年教育部指导目录图书)', 'total_pages': 675, 'trapped': ''}, page_content='五、更换前言。本书的前言,过去一直沿用华东师范大学郭豫适、简茂森教授一九七二年所写的文\n字,限于当时的历史环境,政治化色彩较浓,而《西游记》研究在过去的几十年中取得了很大发展,出现')],
'answer': '根据原文信息得出,孙悟空三打白骨精时,白骨精分别变成了美丽的村姑、年满八旬的老妇人、和一位白发苍苍的老公公。'}通过以上实践,可以看到:
1、MultiQueryRetriever会借助大模型生成新的多个查询 queries;
2、MultiQueryRetriever会通过这些 queries 检索出相关的文档;
3、最后,通过 combine_docs_chain 将检索出的文档交给大模型得到最终答案。
结合检索器 EnsembleRetriever
简介:
EnsembleRetriever是一种结合多个检索器结果的算法,通过重新排序来提高检索效果。
功能:
该算法从多个检索器中获取文档,并将它们组合在一起,以提高文本相似性匹配和信息检索的准确性。通过结合多种补充的向量搜索算法,EnsembleRetriever提供了最先进的文本相似性匹配和信息检索能力。
使用场景:
当需要结合多种检索方法以获得更高的检索准确性时,EnsembleRetriever是理想的选择。这种方法适用于需要从大量文档集合中进行信息检索的应用场景
使用方法
第一步:安装依赖包
pip install rank_bm25
pip install faiss-gpu第二步:准备知识数据
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
from langchain_community.vectorstores import FAISS
# 初始化 HuggingFaceEmbeddings
embedding = HuggingFaceEmbeddings(model_name="bert-base-chinese")
# 中文文档列表
doc_list_1 = [
"我喜欢苹果",
"我喜欢橙子",
"苹果和橙子都是水果",
]
doc_list_2 = [
"你喜欢苹果吗?",
"你喜欢橙子吗?",
]
第三步:创建组合检索器
# 初始化 BM25 检索器
bm25_retriever = BM25Retriever.from_texts(
doc_list_1, metadatas=[{"source": 1}] * len(doc_list_1)
)
bm25_retriever.k = 2
# 创建 FAISS 向量存储
faiss_vectorstore = FAISS.from_texts(
doc_list_2, embedding, metadatas=[{"source": 2}] * len(doc_list_2)
)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2})
# 初始化组合检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)第四步:进行查询
# 输入查询
docs = ensemble_retriever.invoke("我想知道关于苹果的信息")
print(docs)运行结果:
[
Document(metadata={'source': 1}, page_content='苹果和橙子都是水果'),
Document(metadata={'source': 2}, page_content='你喜欢苹果吗?'),
Document(metadata={'source': 1}, page_content='我喜欢橙子'),
Document(metadata={'source': 2}, page_content='你喜欢橙子吗?')
]说明:
- BM25Retriever 是一种基于经典信息检索模型 BM25 的检索器。它的优点:
- 简单易用,适合处理短文本和关键词检索。
- 对于传统的文本匹配任务表现良好。
- FAISS(Facebook AI Similarity Search)是一个高效的相似性搜索库,专门用于处理大规模向量数据。它的优点:
- 适合处理复杂的语义检索任务,尤其是在向量空间中。
- 能够处理大规模数据集,检索速度快。
- 将 BM25Retriever 和 FAISS 组合在一起:
- 互补性:BM25 更适合处理基于关键词的检索,能够有效地从文本中找到相关文档;FAISS 则擅长处理语义相似性,通过向量化表示捕捉文本的深层含义。
- 提高检索:通过组合两种方法,可以充分利用 BM25 的词频特性和 FAISS 的向量相似性,从而提高整体检索的准确性和全面性。
长上下文重排序 LongContextReorder
简介:
LongContextReorder是一种用于处理长上下文信息的技术,旨在提高模型在长文本中的信息提取和理解能力。它通过重新排序文档,以使最相关的信息更易于被模型捕捉。
功能:
信息重排序: LongContextReorder从多个检索器中获取文档,并对它们进行重新排序,使得最相关的文档位于上下文窗口的开头和结尾。这有助于模型更好地关注整个上下文中的关键内容。
上下文优化: 通过优化上下文的排列,模型能够更有效地利用长文本中的信息,从而提高回答的准确性和相关性。
使用场景:
这种技术特别适合需要在长文本中提取关键信息的应用场景,比如法律文书分析、学术论文阅读和长篇故事理解等。
使用方法:
第一步:启动 Chroma 数据库
chroma run --path chroma_test --port 8000说明:
- 此处是避免与前面的代码产生数据污染,所以最好关闭之前的chroma数据库,重新启动一个新的。
第二步:准备数据
import os
from langchain.chains import LLMChain, StuffDocumentsChain
from langchain.prompts import PromptTemplate
from langchain_chroma import Chroma
from langchain_community.document_transformers import (
LongContextReorder,
)
from langchain_community.embeddings import HuggingFaceEmbeddings
# 测试数据
texts = [
"篮球是一项很棒的运动。",
"《Fly me to the moon》 是我最喜欢的歌曲之一。",
"凯尔特人是我最喜欢的球队。",
"这是关于波士顿凯尔特人的一篇文章。",
"我最喜欢的游戏是《黑神话:悟空》",
"波士顿凯尔特人以20分的优势赢得了比赛。",
"在《西游记》中,孙悟空三打白骨精时,白骨精分别变成了村姑、老妇和老翁这三种形态。"
"孙悟空三大白骨精是西游记中一段精彩的篇章。",
"L. Kornet 是凯尔特人队中最优秀的球员之一",
"Larry Bird 是一位标志性的NBA球员。",
]
# 初始化 HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="bert-base-chinese")第三步:创建Retriever并查询相关信息
# 创建一个 retriever
retriever = Chroma.from_texts(texts, embedding=embeddings).as_retriever(
search_kwargs={"k": 10}
)
query = "请告诉我关于白骨精的事情"
# Get relevant documents ordered by relevance score
docs = retriever.get_relevant_documents(query)
for doc in docs:
print(doc.page_content)运行结果:
在《西游记》中,孙悟空三打白骨精时,白骨精分别变成了村姑、老妇和老翁这三种形态。孙悟空三大白骨精是西游记中一段精彩的篇章。
这是关于波士顿凯尔特人的一篇文章。
我最喜欢的游戏是《黑神话:悟空》
L. Kornet 是凯尔特人队中最优秀的球员之一
《Fly me to the moon》 是我最喜欢的歌曲之一。
凯尔特人是我最喜欢的球队。
Larry Bird 是一位标志性的NBA球员。
篮球是一项很棒的运动。
波士顿凯尔特人以20分的优势赢得了比赛。第四步:使用LongContextReorder进行重排序
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
for doc in reordered_docs:
print(doc.page_content)运行结果:
在《西游记》中,孙悟空三打白骨精时,白骨精分别变成了村姑、老妇和老翁这三种形态。孙悟空三大白骨精是西游记中一段精彩的篇章。
我最喜欢的游戏是《黑神话:悟空》
《Fly me to the moon》 是我最喜欢的歌曲之一。
Larry Bird 是一位标志性的NBA球员。
波士顿凯尔特人以20分的优势赢得了比赛。
篮球是一项很棒的运动。
凯尔特人是我最喜欢的球队。
L. Kornet 是凯尔特人队中最优秀的球员之一
这是关于波士顿凯尔特人的一篇文章。对比上面的结果,可以看到,通过使用 LongContextReorder,可以将文档重新排序,将与西游相关的信息排在前面,有助于提高模型的理解能力。
ElasticSearchBM25Retriever
简介:
ElasticSearchBM25Retriever使用BM25算法,这是信息检索中的一种经典方法,广泛应用于ElasticSearch等搜索引擎中。
功能:
BM25是一种基于概率模型的检索算法,能够根据文档和查询之间的词频和逆文档频率,计算文档的相关性得分。
使用场景:
ElasticSearchBM25Retriever适用于需要高效文本搜索的场景,尤其是在需要处理大量非结构化文本数据时。它在搜索引擎优化和文本挖掘中非常有用。
使用方法:
第一步:安装必要的库
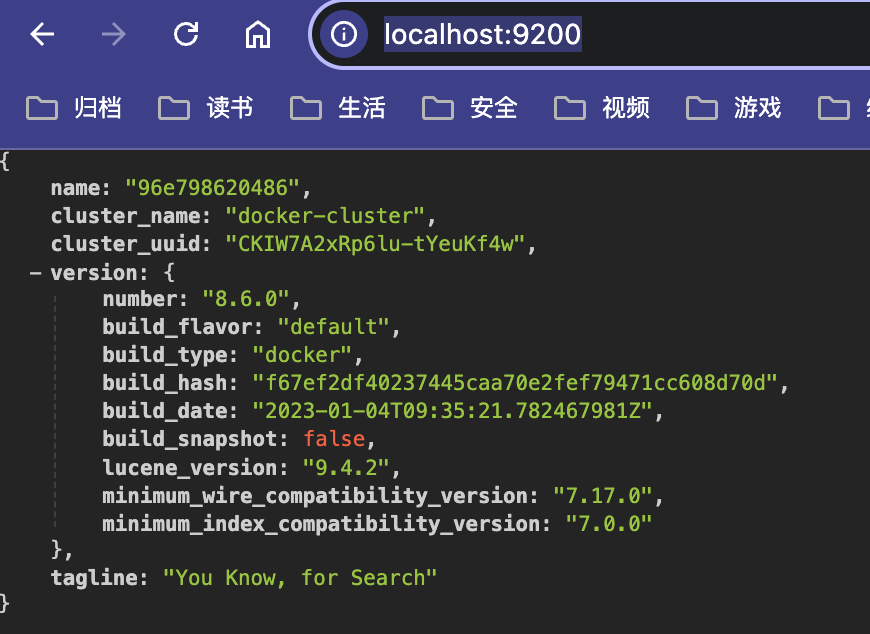
pip install elasticsearch langchain第二步:安装Elasticsearch并启动服务
- 启动Elasticsearch的Docker容器,确保 Elasticsearch 服务正在运行。
- 在浏览器中访问 http://localhost:9200 可以得到如下内容。
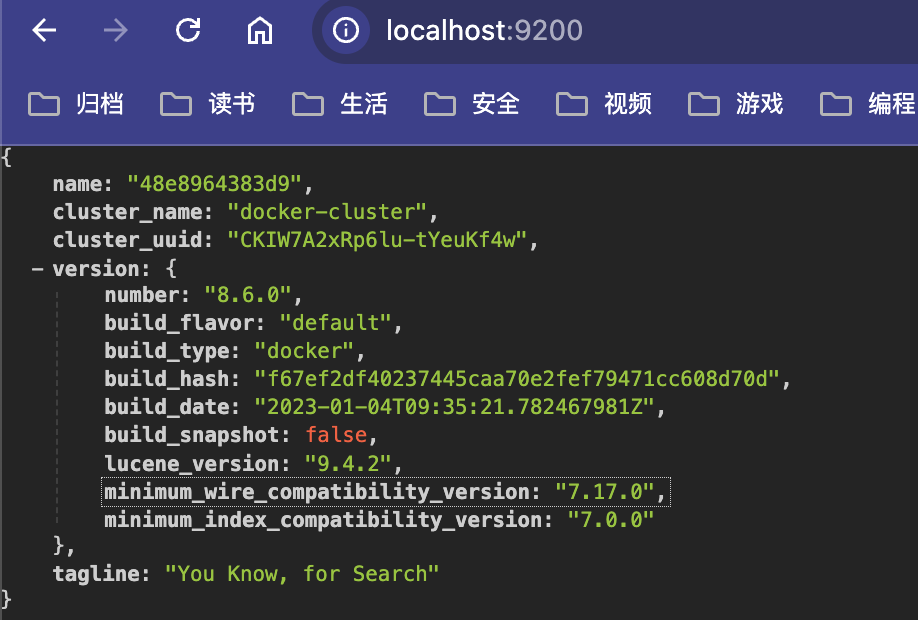
说明:Elasticsearch 的安装方法较长,由于不是本章的主线内容,所以我将这方面内容放在附录部分。
第三步:准备数据并创建索引
from elasticsearch import Elasticsearch
from langchain.retrievers import ElasticSearchBM25Retriever
elasticsearch_url = "http://elastic:mytest@localhost:9200"
# 创建检索器
retriever = ElasticSearchBM25Retriever.create(elasticsearch_url, "langchain-index-5")
# 准备测试数据
documents = [
"篮球是一项很棒的运动。",
"《Fly me to the moon》 是我最喜欢的歌曲之一。",
"凯尔特人是我最喜欢的球队。",
"这是关于波士顿凯尔特人的一篇文章。",
"我最喜欢的游戏是《黑神话:悟空》"
]
# 添加文本
retriever.add_texts(documents)运行结果:
['39c92ff7-4aba-42fb-bc88-2997b5e0c297',
'b1e9c357-b67c-43e0-bf95-2591c9e2a103',
'e4f964cf-92a0-4b4a-b648-9d0c2f8594b0',
'9edcfd38-e954-4bb1-b0d5-68ebf13b3443',
'ea0fc62f-6afd-4e27-9f85-a357ef9221a3']说明:
http://elastic:mytest@localhost:9200 中:
elastic是用户名mytest是密码
第四步:使用 retriever 进行查询
# 查询
query = "请告诉我关于凯尔特人的事情"
try:
docs = retriever.get_relevant_documents(query)
# 输出结果
for doc in docs:
print(doc.page_content)
print("-" * 20)
except Exception as e:
print(f"An error occurred: {e}")运行结果:
这是关于波士顿凯尔特人的一篇文章。
--------------------
凯尔特人是我最喜欢的球队。
--------------------
我最喜欢的游戏是《黑神话:悟空》
--------------------
《Fly me to the moon》 是我最喜欢的歌曲之一。
--------------------
篮球是一项很棒的运动。
--------------------自定义一个retriever
(待补充)
附录
ElasticSearch的Docker安装教程
由于在系统环境中安装ElasticSearch非常繁琐,需要安装(JDK等)基础环境,所以我们使用Docker来安装ElasticSearch。
安装Docker
Docker的安装教程比较多且详细,所以本文不再赘述,详情请查看:
10分钟学会Docker的安装和使用
创建网络
docker network create es-net运行结果:

拉取镜像
docker pull elasticsearch:8.6.0运行结果:
创建挂载点目录
# 选择合适的目录创建三个文件夹
mkdir -p /Users/deadwalk/Code/elasticsearch/data /Users/deadwalk/Code/elasticsearch/config /Users/deadwalk/Code/elasticsearch/plugins运行结果:
启动容器
命令行中输入命令启动Docker容器
docker run -d \
--restart=always \
--name es \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-v /Users/deadwalk/Code/elasticsearch/data:/usr/share/elasticsearch/data \
-v /Users/deadwalk/Code/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:8.6.0
运行结果:
使用 docker ps 可以看到Docker容器已经启动。

修改elasticsearch的密码
第一步:进入es容器
docker exec -it es /bin/bash第二步:命令行输入重置密码命令
bin/elasticsearch-reset-password -i -u elastic根据提示重置密码,例如:mytest
第三步:使用浏览器访问http://localhost:9200/
使用用户名 elastic 和重置的密码 mytest ,验证可以登录。
内容小结
- RAG系统在进行Load->Split->Embedding->Store->Query流程时,需要使用
Retriever进行文档检索。 - Retriever进行文档检索时,有两种方法构建Chain链:一种是传统的管道符构建,另一种是使用
create_retrieval_chain。 - 使用Retriever时,除了基础的向量存储检索器之外,还可以使用多查询检索器(
MultiQueryRetriever)、结合检索器(EnsembleRetriever)等。 MultiQueryRetriever是一种检索算法,它通过使用大型语言模型(LLM)生成多个查询,从而自动化提示调优过程。MultiQueryRetriever的工作流程如下:- 1、
MultiQueryRetriever会借助大模型生成新的多个查询queries; - 2、
MultiQueryRetriever会通过这些queries检索出相关的文档; - 3、最后,通过
combine_docs_chain将检索出的文档交给大模型得到最终答案。
- 1、
EnsembleRetriever是一种结合多个检索器结果的算法,通过重新排序来提高检索效果。BM25Retriever是一种基于经典信息检索模型 BM25 的检索器。FAISS(Facebook AI Similarity Search)是一个高效的相似性搜索库,专门用于处理大规模向量数据。EnsembleRetriever可以将BM25Retriever和FAISS组合使用,从而提高整体检索的准确性和全面性。
LongContextReorder是一种用于处理长上下文信息的技术,旨在提高模型在长文本中的信息提取和理解能力。ElasticSearchBM25Retriever可以与开源搜索引擎ElasticSearch进行交互,以实现向量搜索。
参考资料
LangChain教程 | Retrival之Retrievers详解 | 检索器教程
欢迎关注公众号以获得最新的文章和新闻




