文章来源于互联网:简单通用:视觉基础网络最高3倍无损训练加速,清华EfficientTrain++入选TPAMI 2024

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本论文作者王语霖是清华大学自动化系 2019 级直博生,师从吴澄院士和黄高副教授,主要研究方向为高效深度学习、计算机视觉等。他曾以第一作者在 TPAMI、NeurIPS、ICLR、ICCV、CVPR、ECCV 等期刊、会议上发表论文,曾获百度奖学金、微软学者、CCF-CV 学术新锐奖、字节跳动奖学金等荣誉。个人主页:wyl.cool

-
论文链接:https://arxiv.org/pdf/2405.08768 -
代码和预训练模型已开源:https://github.com/LeapLabTHU/EfficientTrain -
会议版本论文(ICCV 2023):https://arxiv.org/pdf/2211.09703
-
即插即用地实现视觉基础网络 1.5−3.0× 无损训练加速。上游、下游模型性能均不损失。实测速度与理论结果一致。 -
通用于不同的训练数据规模(例如 ImageNet-1K/22K,22K 效果甚至更为明显)。通用于监督学习、自监督学习(例如 MAE)。通用于不同训练开销(例如对应于 0-300 或更多 epochs)。 -
通用于 ViT、ConvNet 等多种网络结构(文中测试了二十余种尺寸、种类不同的模型,一致有效)。 -
对较小模型,训练加速之外,还可显著提升性能(例如在没有额外信息帮助、没有额外训练开销的条件下,在 ImageNet-1K 上得到了 81.3% 的 DeiT-S,可与原版 Swin-Tiny 抗衡)。 -
对两种有挑战性的常见实际情形开发了专门的实际效率优化技术:1)CPU / 硬盘不够强力,数据预处理效率跟不上 GPU;2)大规模并行训练,例如在 ImageNet-22K 上使用 64 或以上的 GPUs 训练大型模型。
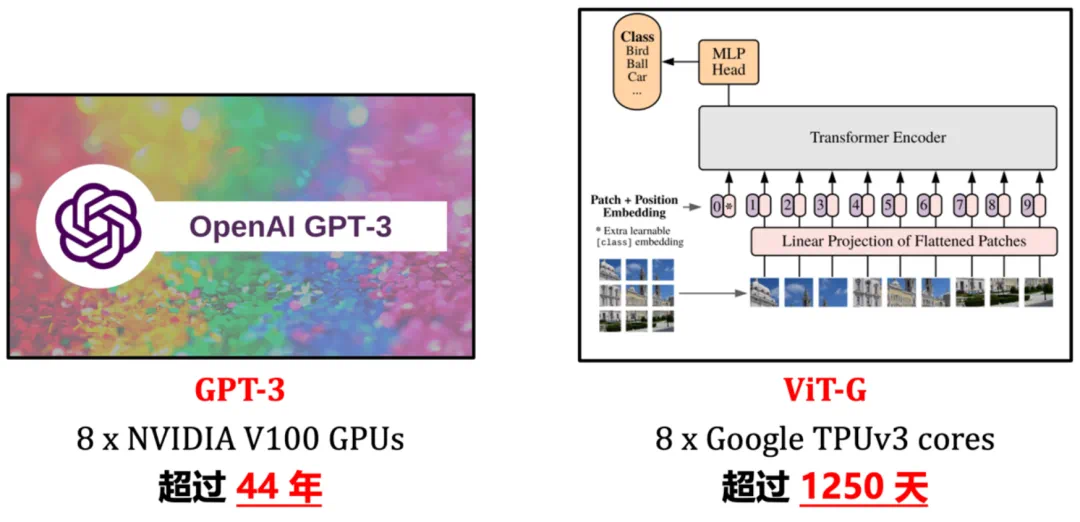 图 1 示例:大型深度学习基础模型的高昂训练开销
图 1 示例:大型深度学习基础模型的高昂训练开销
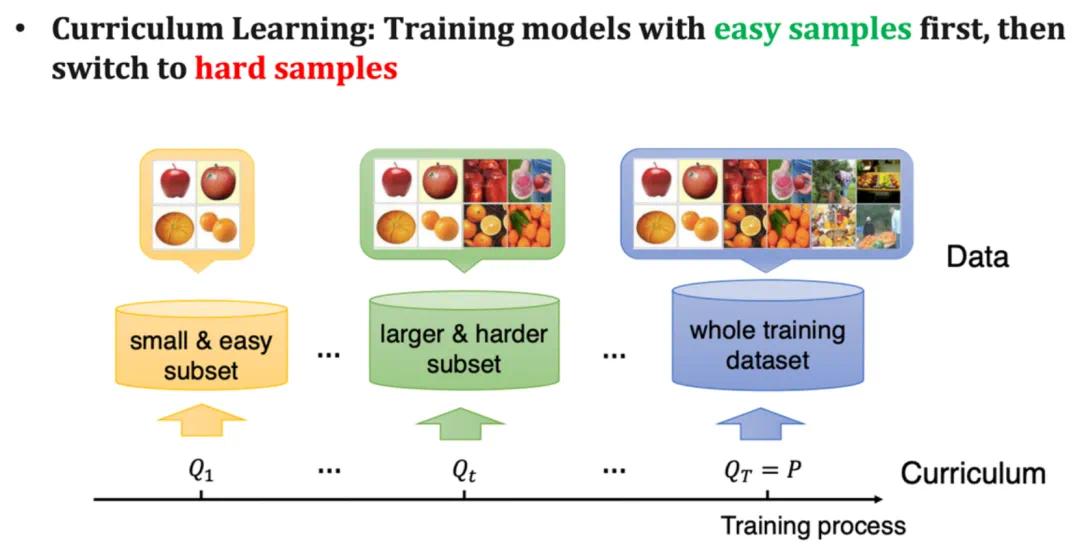 图 2 经典课程学习范式(图片来源:《A Survey on Curriculum Learning》,TPAMI’22)
图 2 经典课程学习范式(图片来源:《A Survey on Curriculum Learning》,TPAMI’22)
 图 3 阻碍课程学习大规模应用于训练视觉基础模型的两个关键瓶颈
图 3 阻碍课程学习大规模应用于训练视觉基础模型的两个关键瓶颈
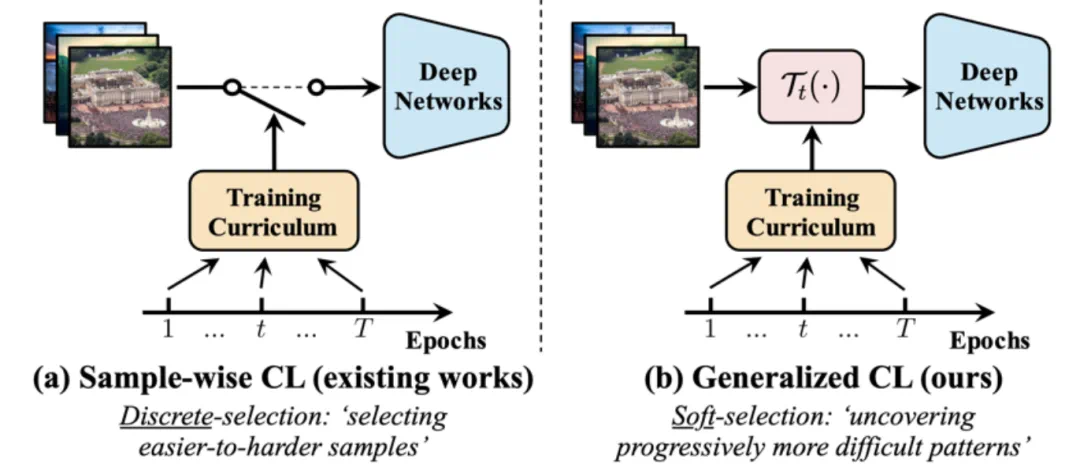 图 4 传统课程学习(样本维度) v.s. 广义课程学习(特征维度)
图 4 传统课程学习(样本维度) v.s. 广义课程学习(特征维度)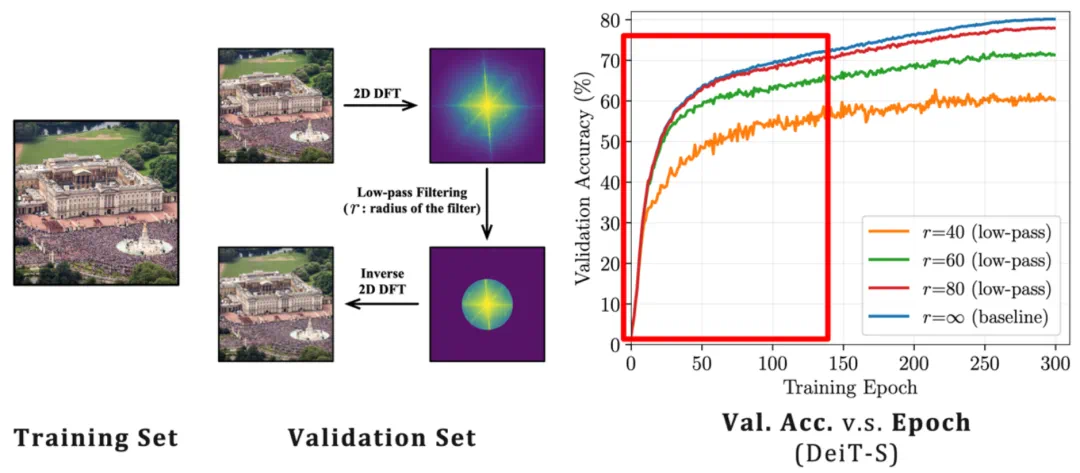 图 5 频域角度上,模型自然倾向于先学习识别低频特征
图 5 频域角度上,模型自然倾向于先学习识别低频特征
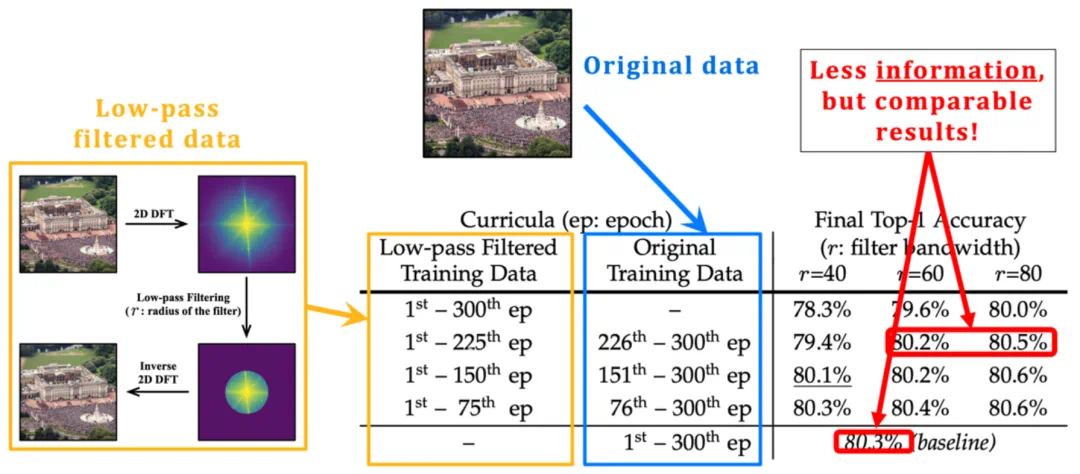 图 6 在相当长的一段早期训练阶段中仅向模型提供低频分量并不会显著影响最终性能
图 6 在相当长的一段早期训练阶段中仅向模型提供低频分量并不会显著影响最终性能
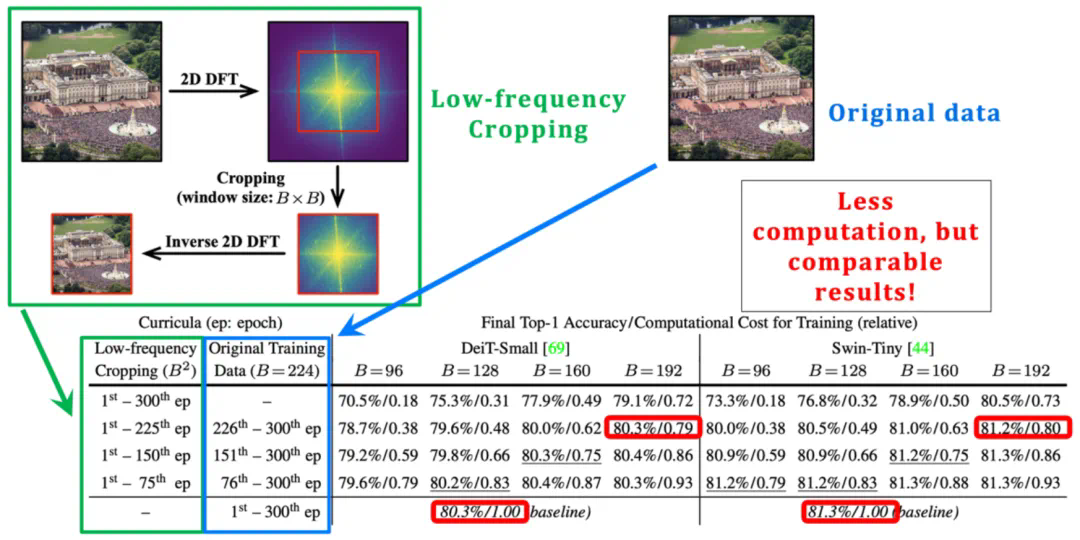 图 7 低频裁切(low-frequency cropping):使模型高效地仅从低频信息中学习
图 7 低频裁切(low-frequency cropping):使模型高效地仅从低频信息中学习
 图 8 从空域的角度寻找模型 “较容易学习” 的特征:一个数据增强的视角
图 8 从空域的角度寻找模型 “较容易学习” 的特征:一个数据增强的视角
-
融合频域、空域的两个核心发现,提出和改进了专门设计的优化算法,建立了一个统一、整合的 EfficientTrain++ 广义课程学习方案。 -
探讨了低频裁切操作在实际硬件上高效实现的具体方法,并从理论和实验两个角度比较了两种提取低频信息的可行方法:低频裁切和图像降采样,的区别和联系。 -
对两种有挑战性的常见实际情形开发了专门的实际效率优化技术:1)CPU / 硬盘不够强力,数据预处理效率跟不上 GPU;2)大规模并行训练,例如在 ImageNet-22K 上使用 64 或以上的 GPUs 训练大型模型。
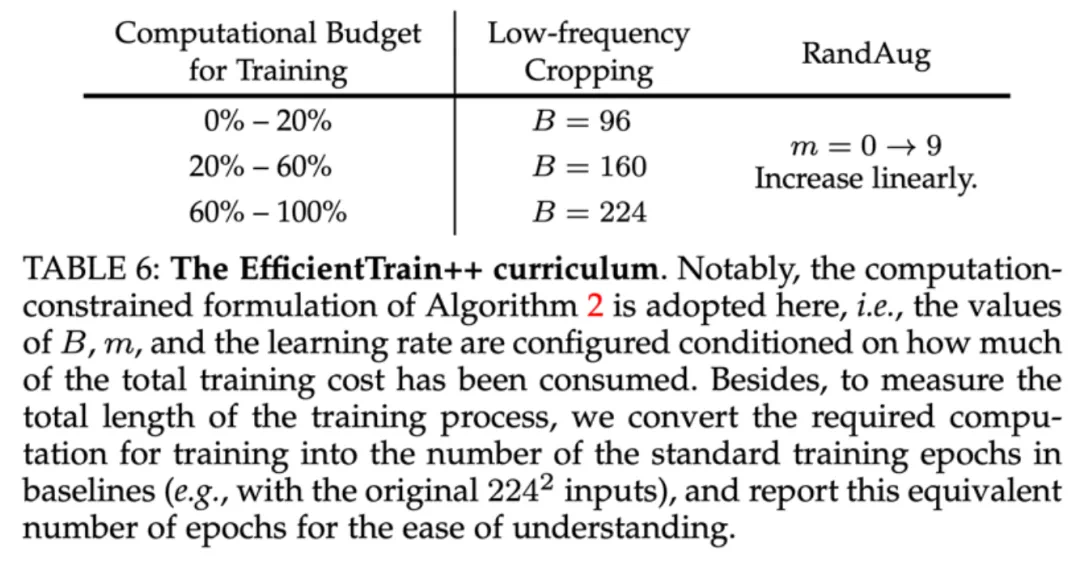 图 9 统一、整合的广义课程学习方案:EfficientTrain++
图 9 统一、整合的广义课程学习方案:EfficientTrain++
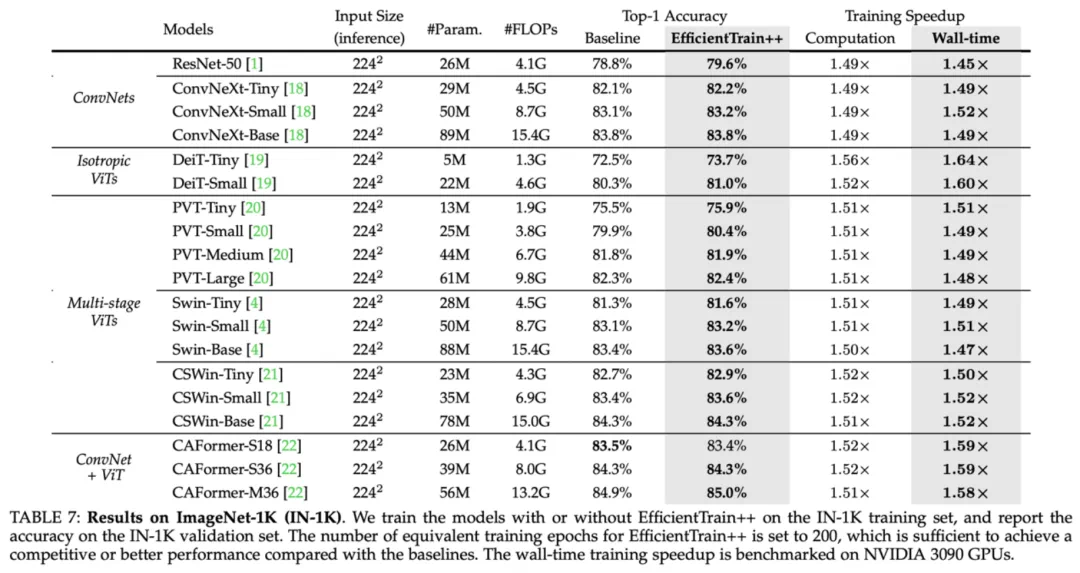 图 10 ImageNet-1K 实验结果:EfficientTrain++ 在多种视觉基础网络上的表现
图 10 ImageNet-1K 实验结果:EfficientTrain++ 在多种视觉基础网络上的表现
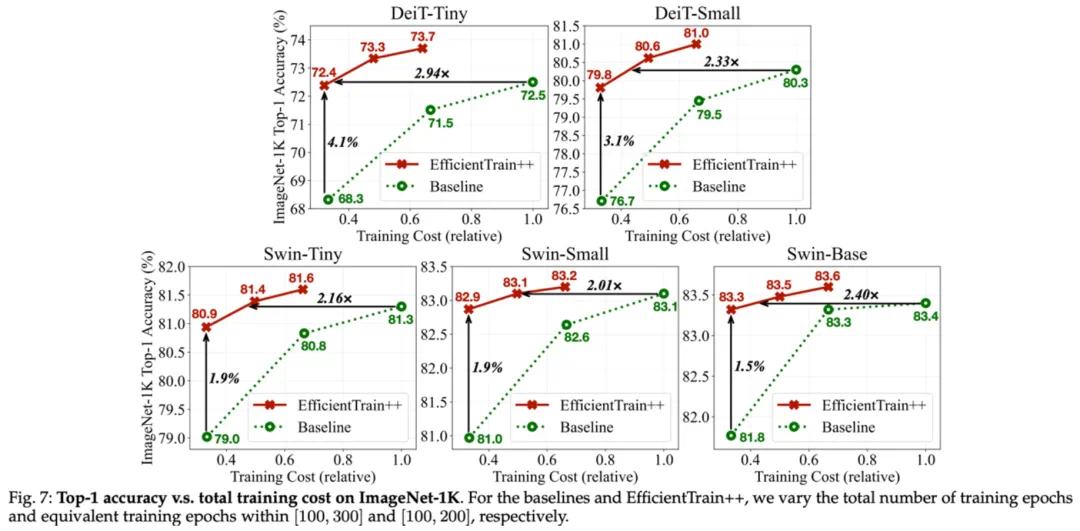 图 11 ImageNet-1K 实验结果:EfficientTrain++ 在不同训练开销预算下的表现
图 11 ImageNet-1K 实验结果:EfficientTrain++ 在不同训练开销预算下的表现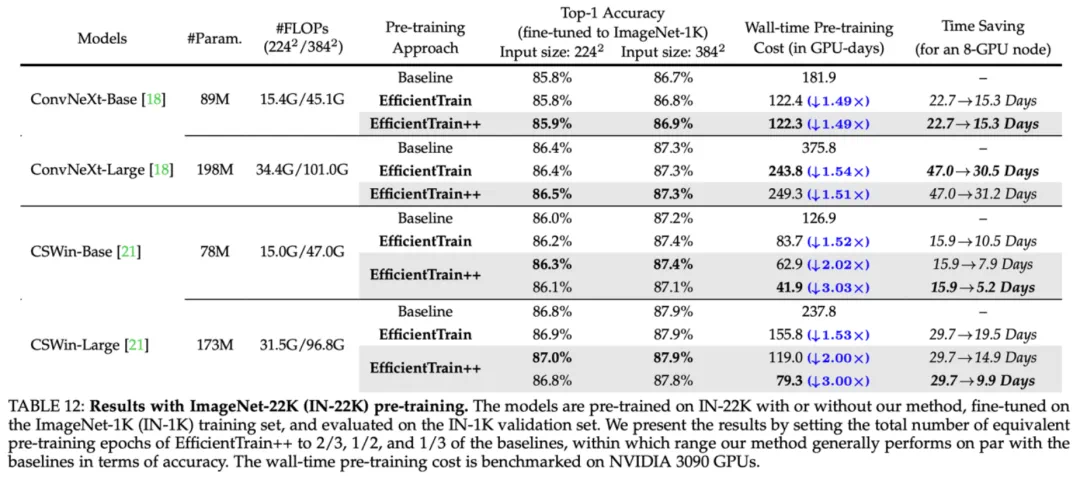 图 12 ImageNet-22K 实验结果:EfficientTrain++ 在更大规模训练数据上的表现
图 12 ImageNet-22K 实验结果:EfficientTrain++ 在更大规模训练数据上的表现
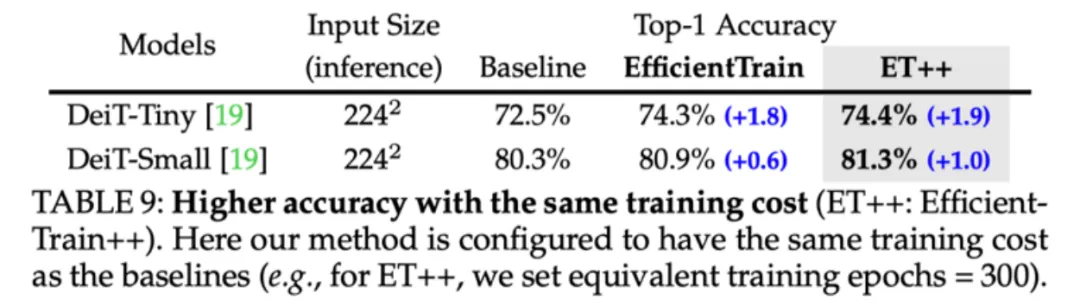 图 13 ImageNet-1K 实验结果:EfficientTrain++ 可以显著提升较小模型的性能上界
图 13 ImageNet-1K 实验结果:EfficientTrain++ 可以显著提升较小模型的性能上界
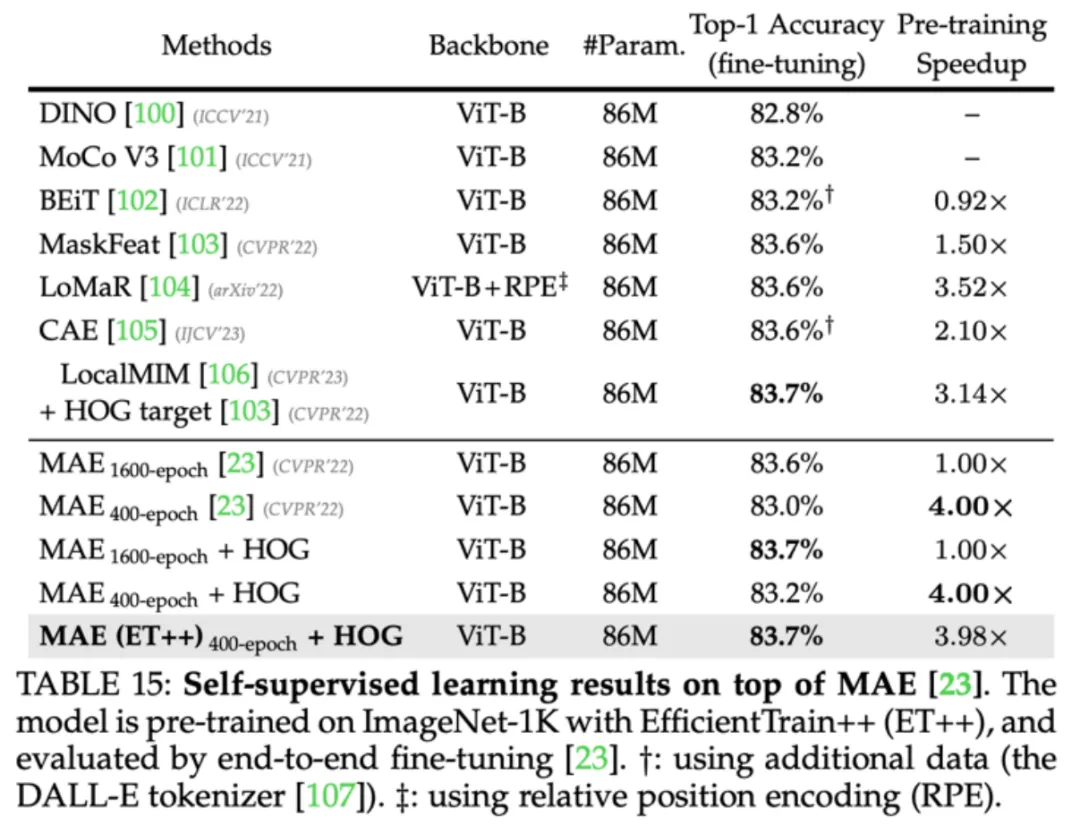 图 14 EfficientTrain++ 可以应用于自监督学习(如 MAE)
图 14 EfficientTrain++ 可以应用于自监督学习(如 MAE)
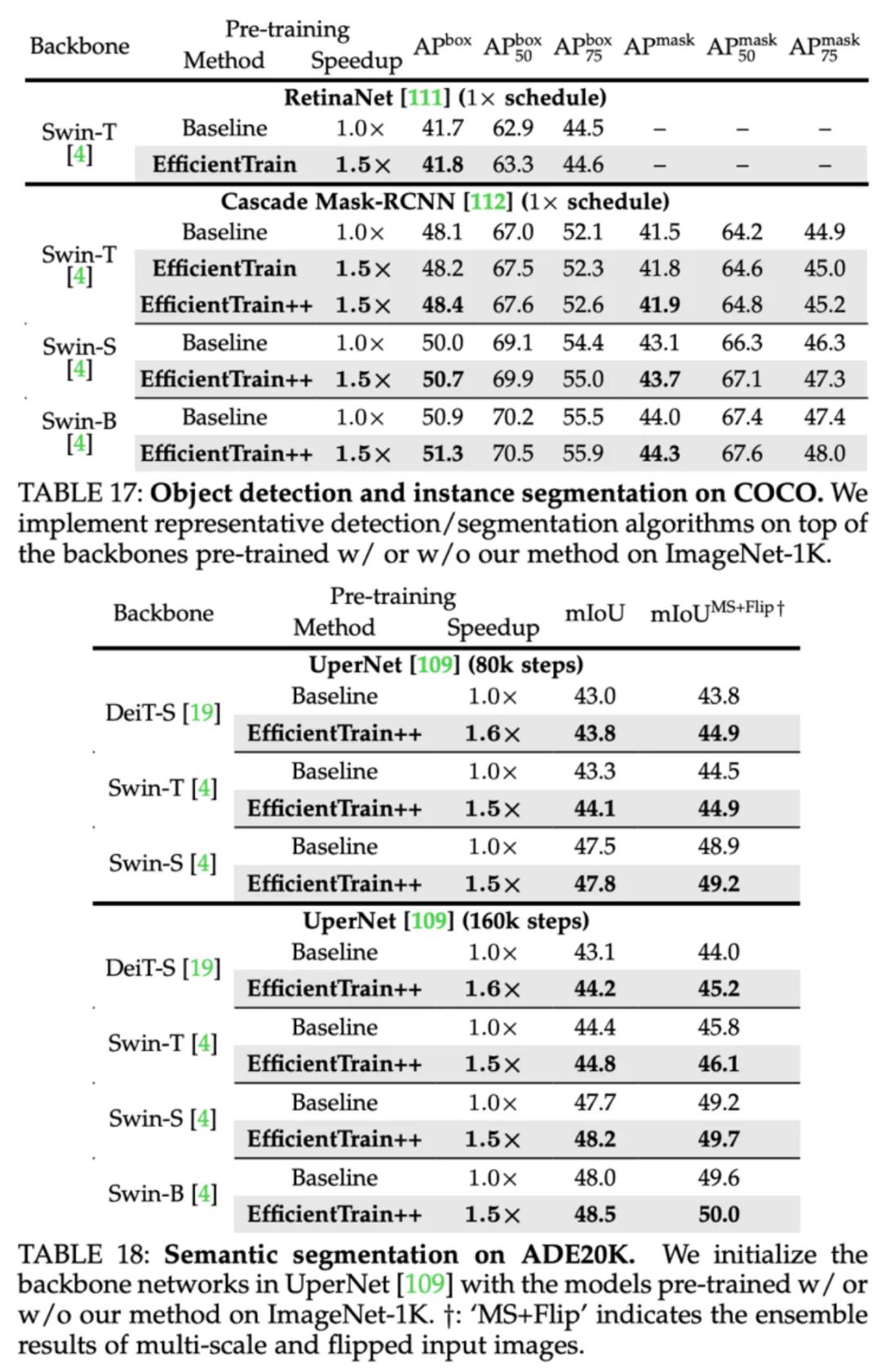 图 15 COCO 目标检测、COCO 实例分割、ADE20K 语义分割实验结果
图 15 COCO 目标检测、COCO 实例分割、ADE20K 语义分割实验结果
文章来源于互联网:简单通用:视觉基础网络最高3倍无损训练加速,清华EfficientTrain++入选TPAMI 2024

