文章来源于互联网:AI训练数据的版权保护:公地的悲剧还是合作的繁荣?
就算是 OpenAI 在舆论场也无法逃过版权保护的呼声。

-
论文链接:https://arxiv.org/abs/2404.13964

-
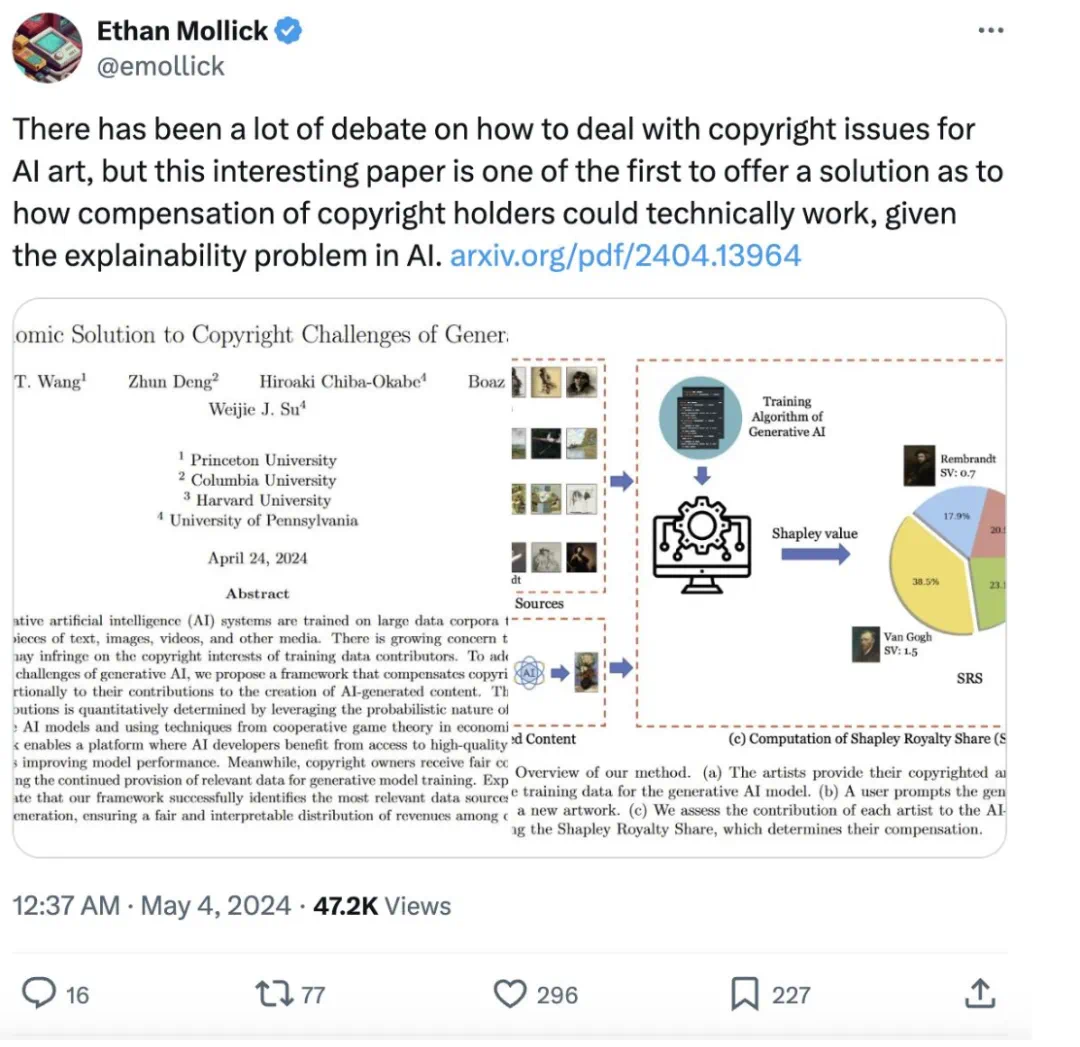
第一步是评估模型在整个数据集的每一个可能子集上训练的效用。直观上,如果在某数据子集上训练的模型能够有很大的可能性生成与部署模型相似的AI生成内容(例如艺术作品),那么该数据子集的效用就会很大。
-
第二步是根据第一步的效用使用合作博弈论工具(即Shapley值)来确定任何训练数据版权所有者的应得份额。简而言之,如果将其数据包括在模型训练中能够增加效用,那么版权所有者的份额就会大。 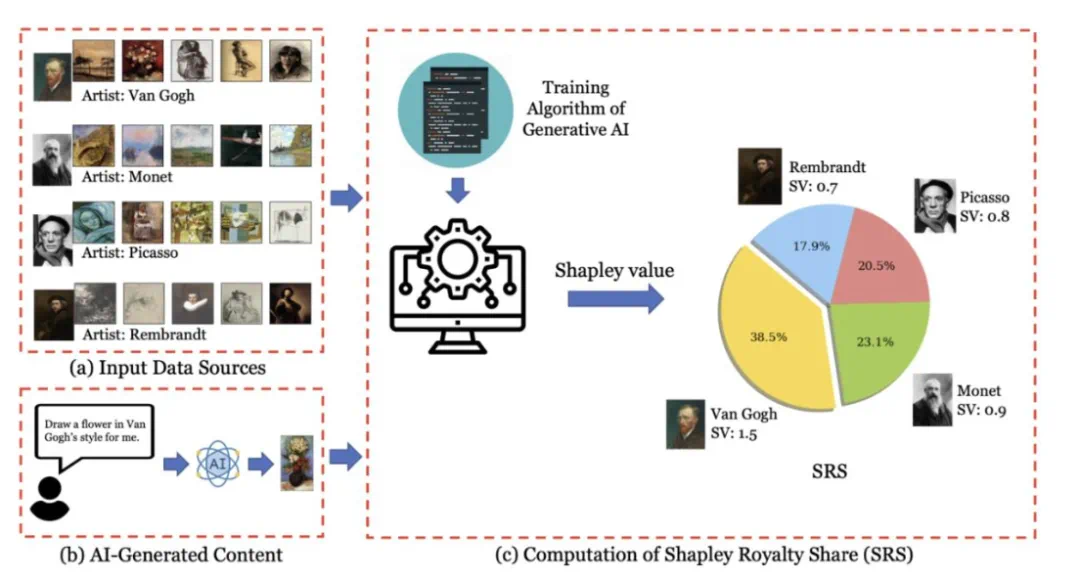
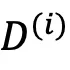 的版权,其中i∈N≔{1,2,…n}。部署的模型训练在整个数据集
的版权,其中i∈N≔{1,2,…n}。部署的模型训练在整个数据集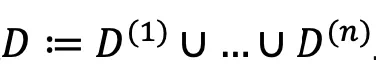 上,并生成内容
上,并生成内容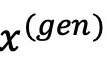 。考虑一个在数据子集
。考虑一个在数据子集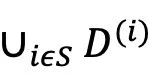 上训练的反事实模型,其中S⊆N表示数据所有者的一个子集。
上训练的反事实模型,其中S⊆N表示数据所有者的一个子集。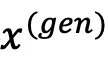 的概率密度函数由
的概率密度函数由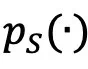 表示。对于生成模型生成的内容,一个子集的效用最容易反映在该反事实模型生成目标内容的概率。当比较不同模型时,可以通过生成目标内容的概率比例衡量它们之间的效用差距。
表示。对于生成模型生成的内容,一个子集的效用最容易反映在该反事实模型生成目标内容的概率。当比较不同模型时,可以通过生成目标内容的概率比例衡量它们之间的效用差距。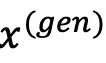 效用为
效用为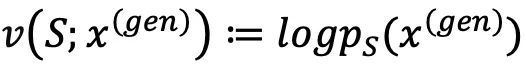 ,这样可以直接根据
,这样可以直接根据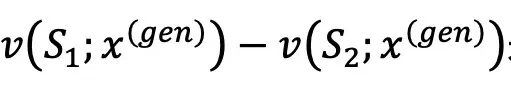 来比较两个数据集之间的效用。
来比较两个数据集之间的效用。

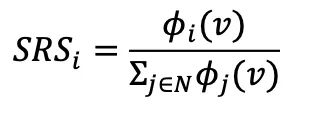
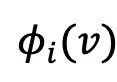 是版权所有者i的Shapley值。
是版权所有者i的Shapley值。
-
数据所有者A单独贡献:v({A})=5 -
数据所有者A和B的贡献:v({A,B})-v({B})=15-7=8 -
数据所有者A和C的贡献:v({A,C})-v({C})=10-3=7 -
数据所有者A、B和C的贡献:v({A,B,C})-v({B,C})=20-12=8
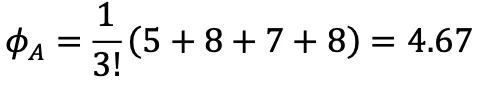
-
第一种是使用蒙特卡洛方法来近似计算Shapley值,这种技术特别适用于版权所有者众多的情况。 -
第二种方法是通过从另一个在较小数据子集上训练的模型微调来训练模型。因此,可以通过对整个训练数据只训练一次,来近似在不同数据子集上训练的模型。具体来说,对于随机抽样的版权所有者排列,可以首先在第一个版权所有者上训练,然后是第二个,一直到最后一个版权所有者。这种技术可以与著名的Shapley值排列抽样估计器一起使用。
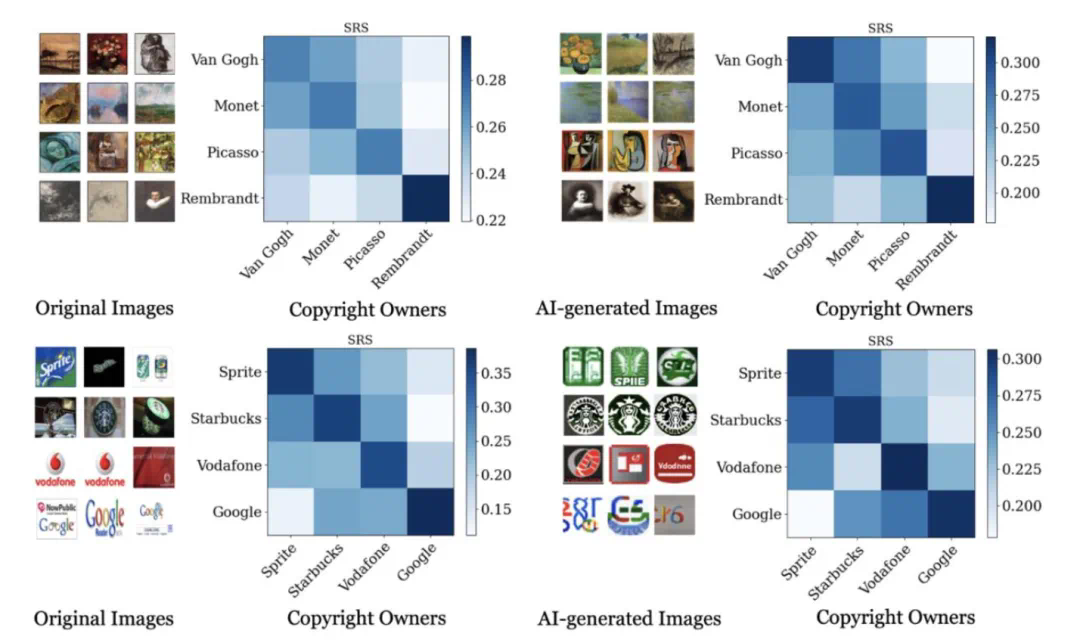
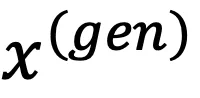 的风格与训练数据源的风格非常接近时,SRS值最高。这一关系凸显了SRS框架准确归因于AI生成图像创作贡献的能力。
的风格与训练数据源的风格非常接近时,SRS值最高。这一关系凸显了SRS框架准确归因于AI生成图像创作贡献的能力。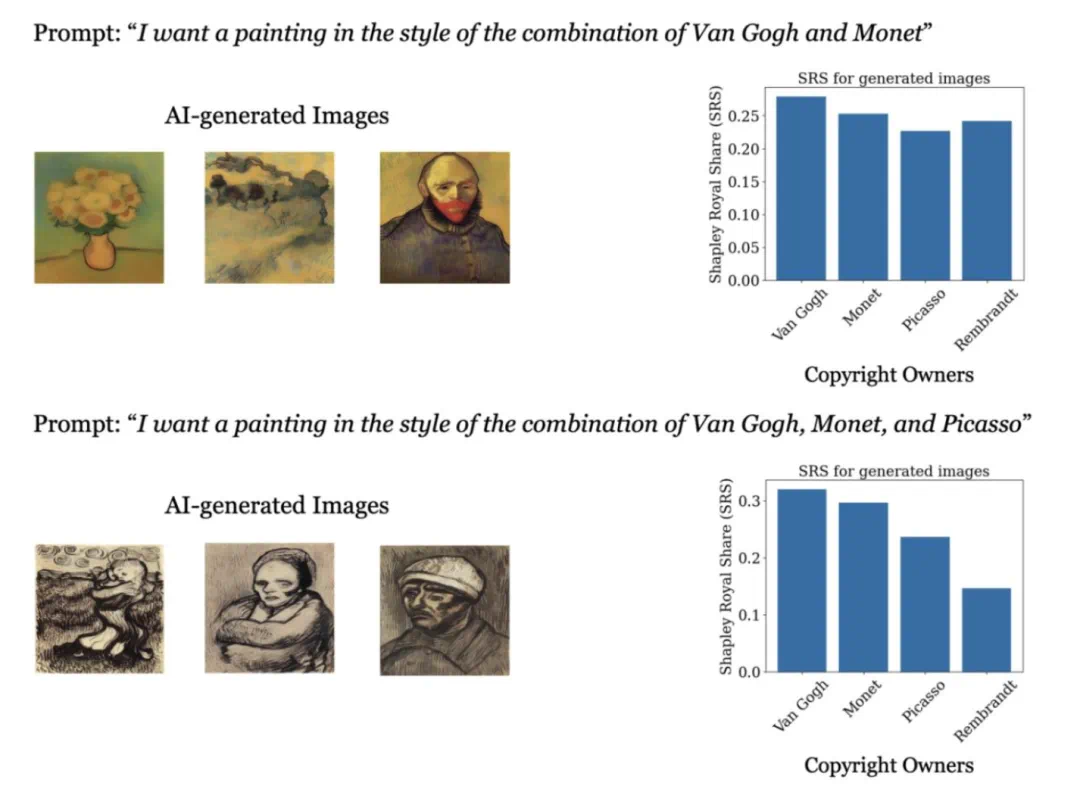
1. Jiachen Wang (王嘉宸):现为普林斯顿大学电子工程系博士生,主攻人工智能数据估值(data valuation)等方向。
2. Zhun Deng (邓准):现为哥伦比亚大学计算机系博后,博后导师为 Richard Zemel。此前为哈佛大学计算机系博士生,师从Cynthia Dwork,主攻机器学习可靠性和社会责任性等方向。
3. Hiroaki Chiba-Okabe:现为宾夕法尼亚大学应用数学和计算科学博士生,主攻方向是人工智能引发的道德问题和社会问题。
4. Boaz Barak: 哈佛大学正教授,主攻方向理论计算机和机器学习方向。同时在OpenAI 任职。
5. Weijie Su (苏炜杰):现为宾夕法尼亚大学沃顿商学院、计算机系和数学系副教授,研究方向包括人工智能的理论基础等方向。
文章来源于互联网:AI训练数据的版权保护:公地的悲剧还是合作的繁荣?

