文章来源于互联网:具身智能体三维感知新链条,TeleAI &上海AI Lab提出多视角融合具身模型「SAM-E」

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com


-
论文名称:SAM-E: Leveraging Visual Foundation Model with Sequence Imitation for Embodied Manipulation -
论文链接: https://sam-embodied.github.io/static/SAM-E.pdf -
项目地址: https://sam-embodied.github.io/
-
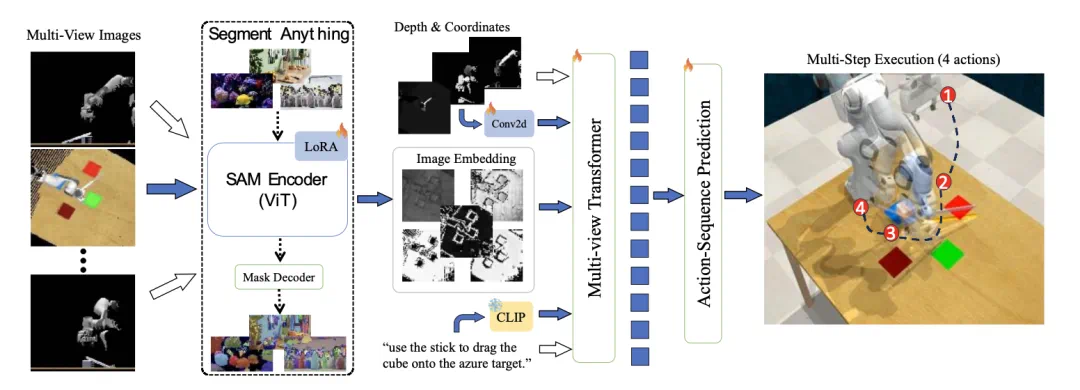
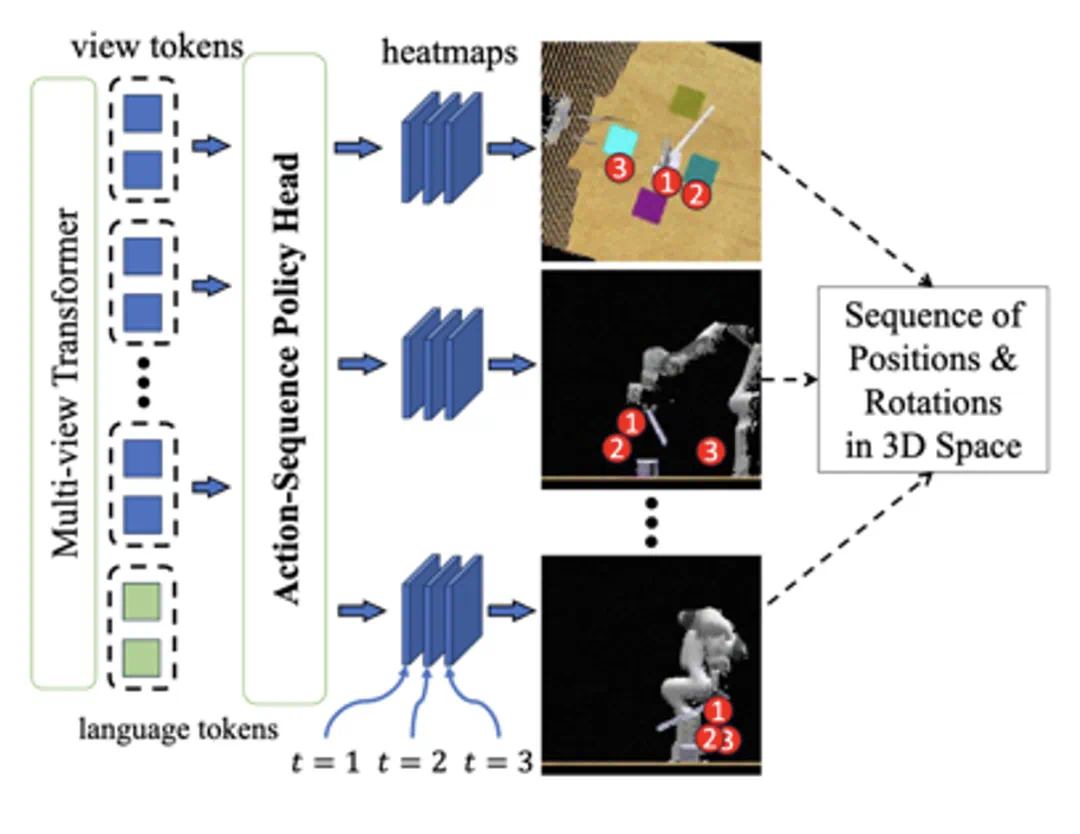
利用SAM的提示驱动结构,构建了一个强大的基座模型,在任务语言指令下拥有出色的泛化性能。通过LoRA微调技术,将模型适配到具身任务中,进一步提升了其性能。 -
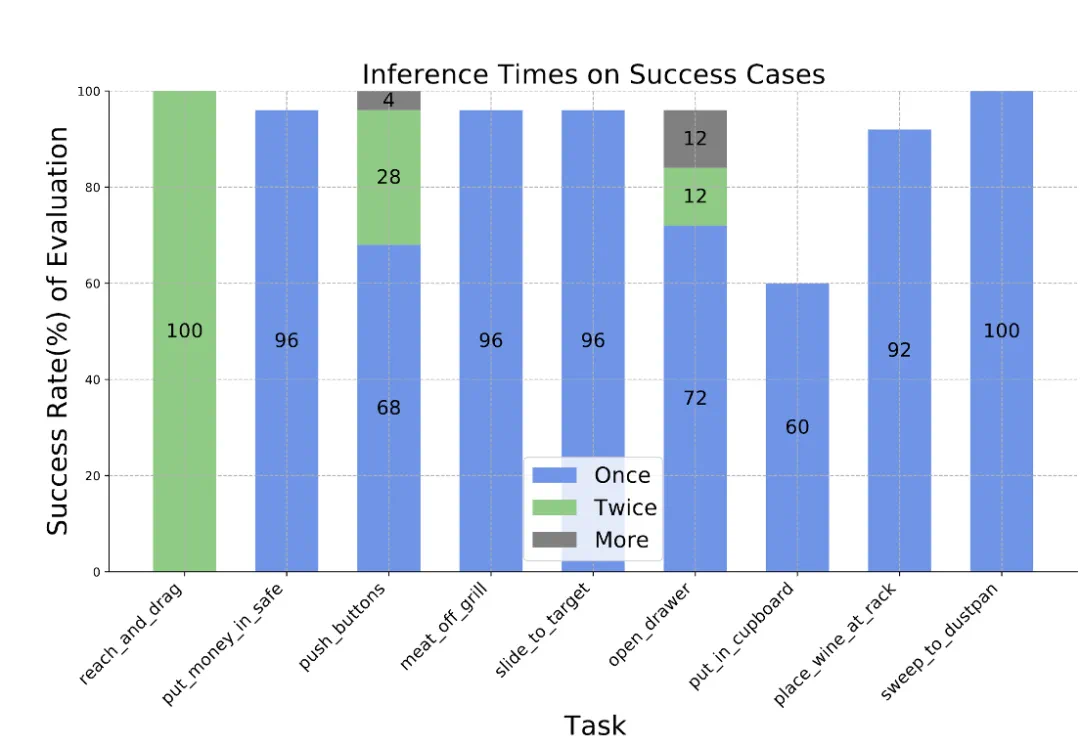
采用时序动作建模技术,捕捉动作序列中的时序信息,更好地理解任务的动态变化,并及时调整机器人的策略和执行方式,使机器人保持较高的执行效率。
在具身场景中任务「提示」以自然语言的形式呈现,作为任务描述指令,视觉编码器发挥其可提示的感知能力,提取与任务相关的特征。策略网络则充当解码器的角色,基于融合的视觉嵌入和语言指令输出动作。
在训练阶段,SAM-E 使用 LoRA 进行高效微调,大大减少了训练参数,使视觉基础模型能够快速适应于具身任务。
-
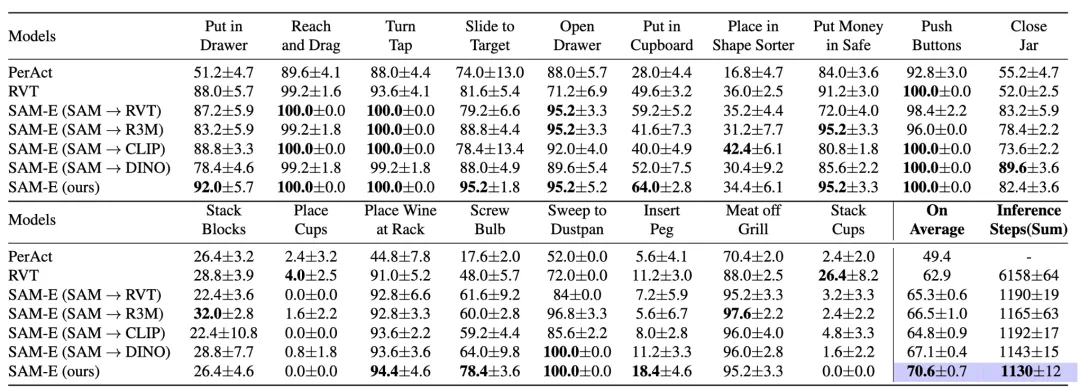
在多任务场景下,SAM-E模型显著提高了任务成功率。 -
在面对少量样本迁移至新任务的情况下,SAM-E凭借强大的泛化性能和高效的执行效率,有效提升新任务的表现。