文章来源于互联网:ICML 2024 Oral|外部引导的深度聚类新范式

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

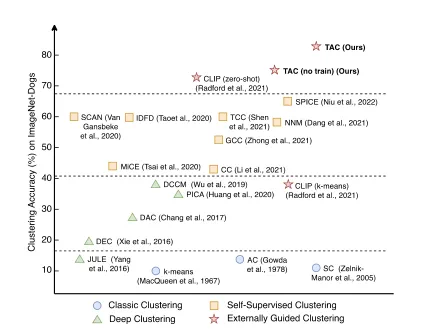
如果单从图像识别角度而言,两种犬类在外观上极为相似,拥有相近的色块像素,仅凭数据内蕴信息(即图像自身)可能难以对二者进行区分,但如果借助外部数据和知识,情况可能会大幅改观。

-
论文题目:Image Clustering with External Guidance -
论文地址:https://arxiv.org/abs/2310.11989 -
代码地址:https://github.com/XLearning-SCU/2024-ICML-TAC
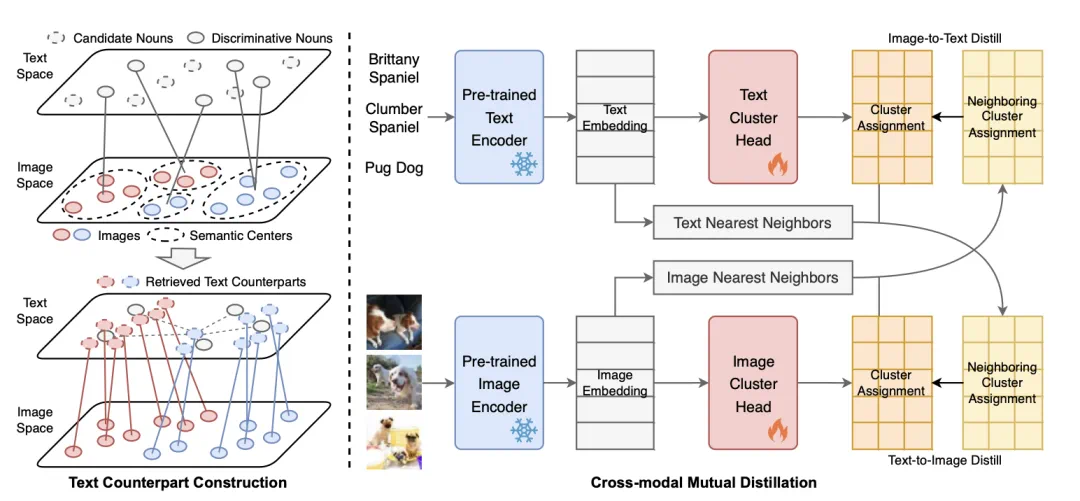
-
如何构建图像的文本表征; -
如何协同图像和文本进行聚类。
 当且仅当图像
当且仅当图像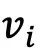 属于第l个聚类,
属于第l个聚类,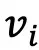 表示第i张图像经过CLIP图像编码器后得到的表征。在得到图像语义中心后,为了选取具有代表性的名词集合,与常见的CLIP Zero-shot分类相反,本文将所有WordNet中的名词划分到k个图像语义中心,其中第i个名词属于第l和语义中心的概率为:
表示第i张图像经过CLIP图像编码器后得到的表征。在得到图像语义中心后,为了选取具有代表性的名词集合,与常见的CLIP Zero-shot分类相反,本文将所有WordNet中的名词划分到k个图像语义中心,其中第i个名词属于第l和语义中心的概率为: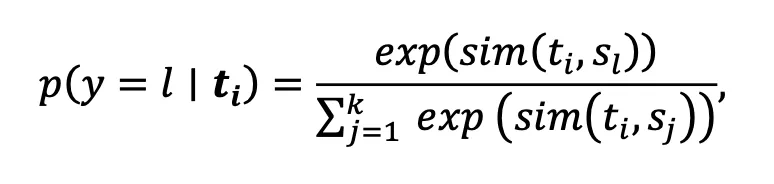
 表示第i个名词经过预训练好的文本编码器后得到的表征。保留每个语义中心对应概率最高的名词,作为组成文本空间的候选词。
表示第i个名词经过预训练好的文本编码器后得到的表征。保留每个语义中心对应概率最高的名词,作为组成文本空间的候选词。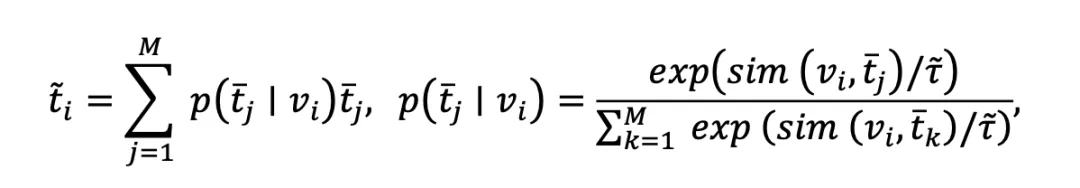
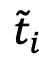 表示第i张图像对应的文本模态中的表征,
表示第i张图像对应的文本模态中的表征,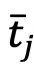 表示组成文本空间的第j个候选名词,
表示组成文本空间的第j个候选名词, 控制检索的平滑程度。
控制检索的平滑程度。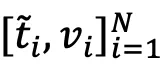 直接使用经典k-means聚类方法来实现图像聚类。
直接使用经典k-means聚类方法来实现图像聚类。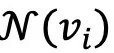 ,并引入一个聚类网络f对每个图像表征做出聚类指派,在每次迭代中,计算所有图像和其邻居集合中随机的一个图像的聚类指派,记为:
,并引入一个聚类网络f对每个图像表征做出聚类指派,在每次迭代中,计算所有图像和其邻居集合中随机的一个图像的聚类指派,记为: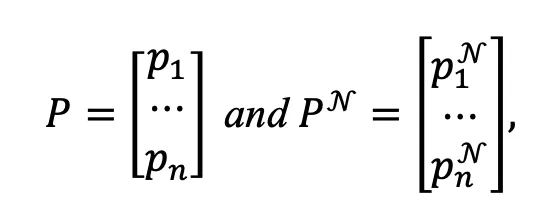 其中
其中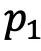 和
和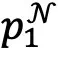 分别对应图像i及其邻居的聚类指派,P和
分别对应图像i及其邻居的聚类指派,P和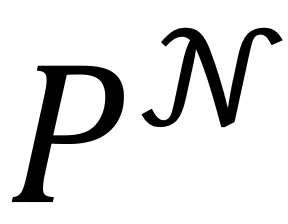 均为n*K的矩阵,其中K表示目标聚类个数。
均为n*K的矩阵,其中K表示目标聚类个数。
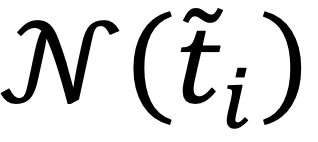 ,在每次迭代中,计算所有文本和其邻居集合中随机的一个文本的聚类指派,记为:
,在每次迭代中,计算所有文本和其邻居集合中随机的一个文本的聚类指派,记为: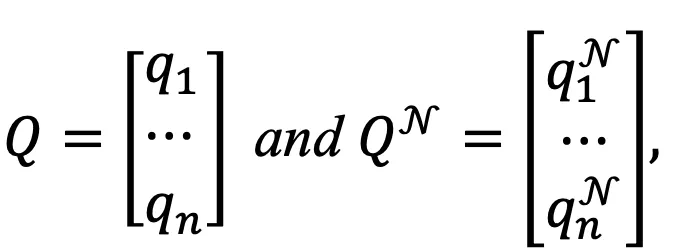 其中
其中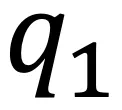 和
和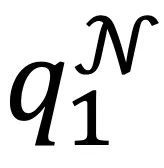 分别对应文本i及其邻居的聚类指派,Q和Q^N同样均为n*K的矩阵。
分别对应文本i及其邻居的聚类指派,Q和Q^N同样均为n*K的矩阵。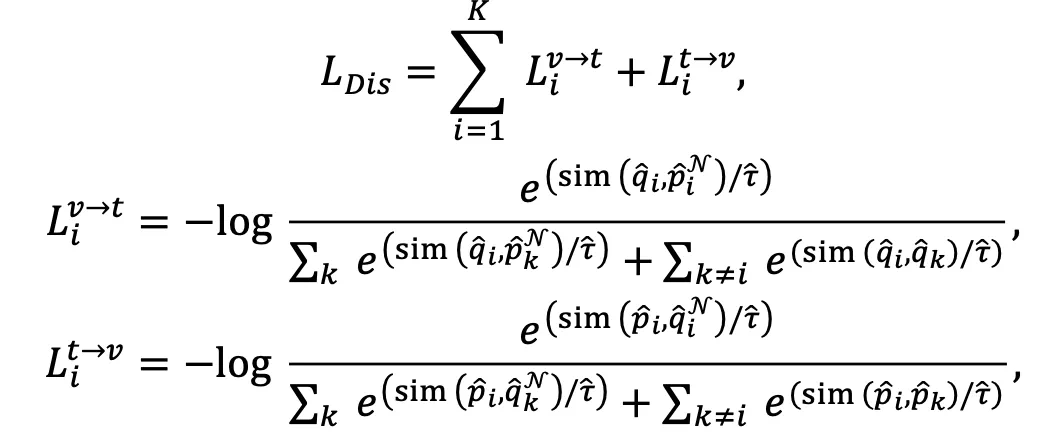
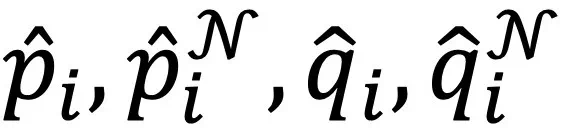 分别表示聚类指派矩阵P,P^N,Q,Q^N的第i列,
分别表示聚类指派矩阵P,P^N,Q,Q^N的第i列, 为温度系数。该损失函数一方面能通过跨模态邻居之间的聚类指派一致性实现图文模态的协同,另一方面能扩大不同的类簇之间的差异性。
为温度系数。该损失函数一方面能通过跨模态邻居之间的聚类指派一致性实现图文模态的协同,另一方面能扩大不同的类簇之间的差异性。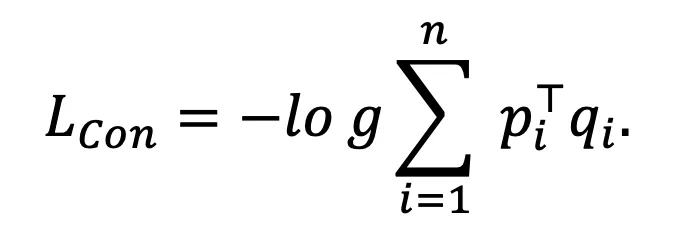 该损失函数在
该损失函数在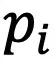 和
和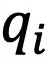 均为独热(One-hot)编码时被最小化,因此能提升聚类指派的置信度。另外,为了防止模型将大量图像和文本都分配到个别类簇中,提出了以下损失函数:
均为独热(One-hot)编码时被最小化,因此能提升聚类指派的置信度。另外,为了防止模型将大量图像和文本都分配到个别类簇中,提出了以下损失函数: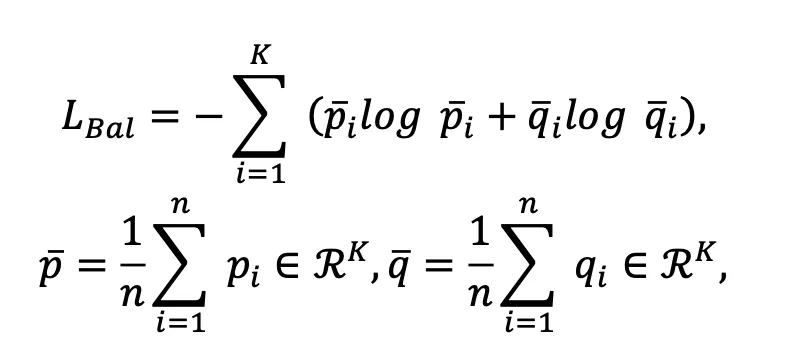
 和
和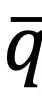 分别表示图像和文本模态中整体的聚类分布。
分别表示图像和文本模态中整体的聚类分布。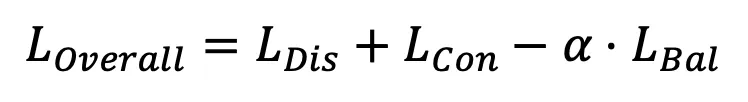 其中
其中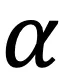 为权重参数。需要指出的是,上述损失函数只用来优化额外引入的聚类网络,并不修改CLIP预训练好的文本和图像编码器,因此其整体训练开销较小,实验表明所提出的方法在CIFAR-10的6万张图像上训练仅需使用1分钟。
为权重参数。需要指出的是,上述损失函数只用来优化额外引入的聚类网络,并不修改CLIP预训练好的文本和图像编码器,因此其整体训练开销较小,实验表明所提出的方法在CIFAR-10的6万张图像上训练仅需使用1分钟。
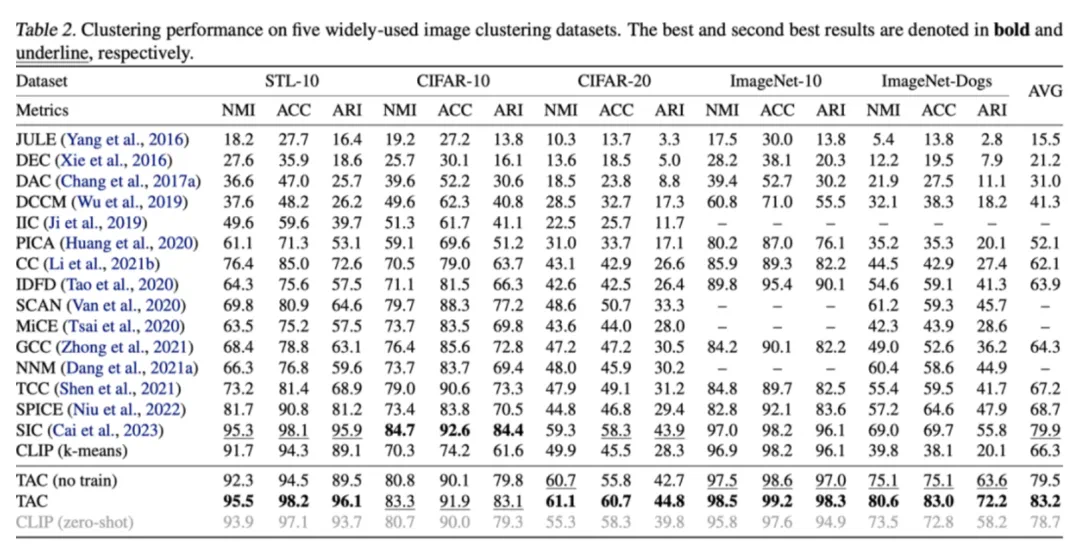
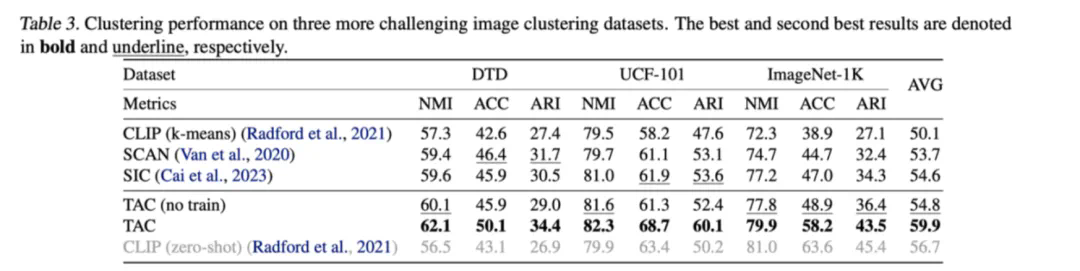
-
如何选择合适的外部知识; -
如何有效的整合外部知识以辅助聚类。
文章来源于互联网:ICML 2024 Oral|外部引导的深度聚类新范式

