文章来源于互联网:万字综述大模型高效推理:无问芯穹与清华、上交最新联合研究全面解析大模型推理优化

-
预填充(Prefilling)阶段:大语言模型计算并存储输入序列中词块的Key和Value向量,并生成第一个输出词块。 -
解码(Decoding)阶段:大语言模型利用KV缓存技术逐个生成输出词块,并在每步生成后存储新词块的Key和Value向量。 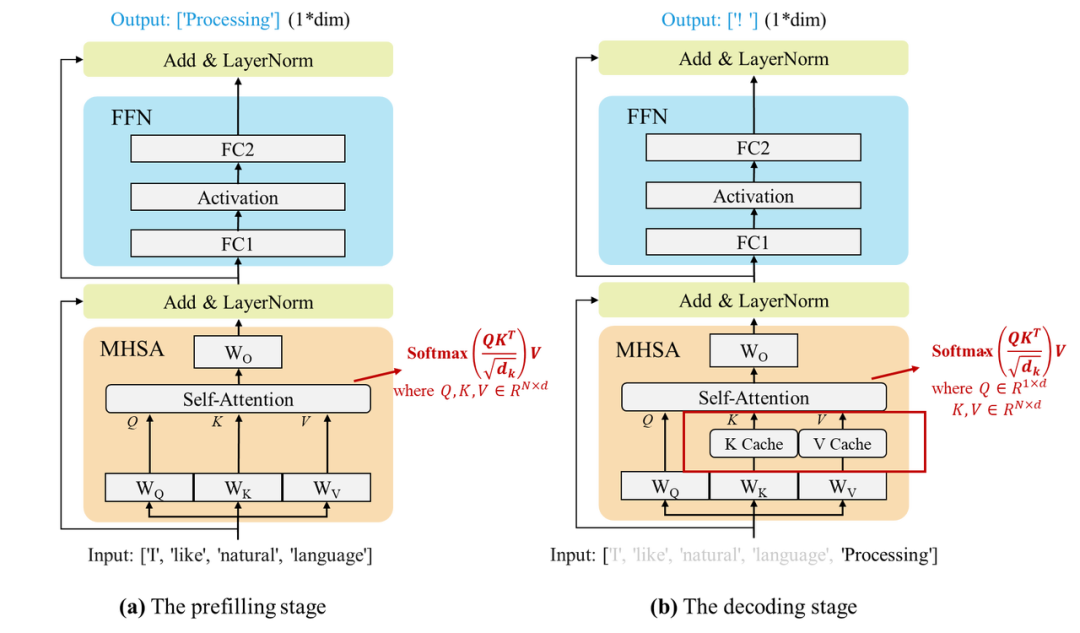
-
模型规模:主流大语言模型庞大的模型规模会导致巨大的计算量、访存量和存储量; -
注意力算子:作为大语言模型的核心算子,注意力算子具有与输入长度呈平方关系增长的计算和存储复杂度; -
解码方式:主流的自回归解码方式导致极低的计算-访存比和硬件利用率,同时动态增长的KV缓存会导致碎片化的内存使用,对访存开销和存储开销带来增长。 
-
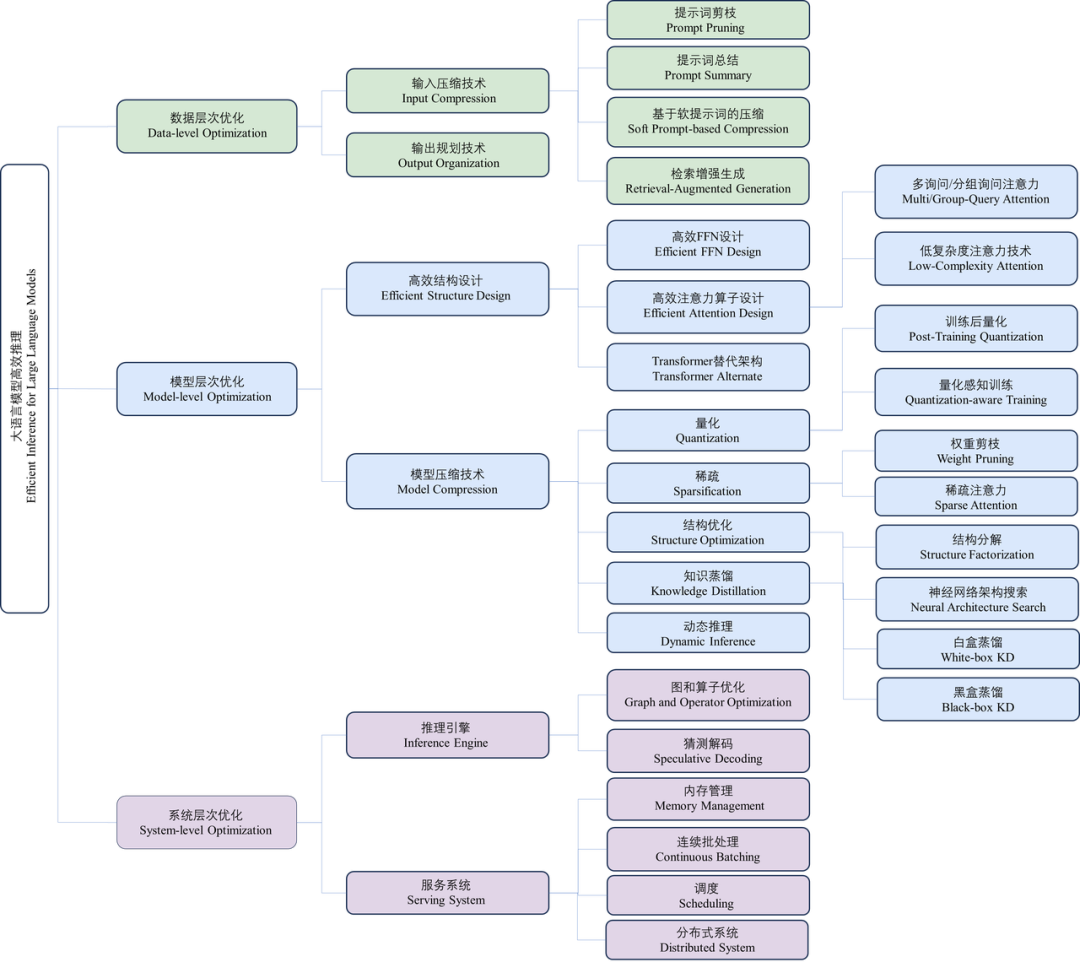
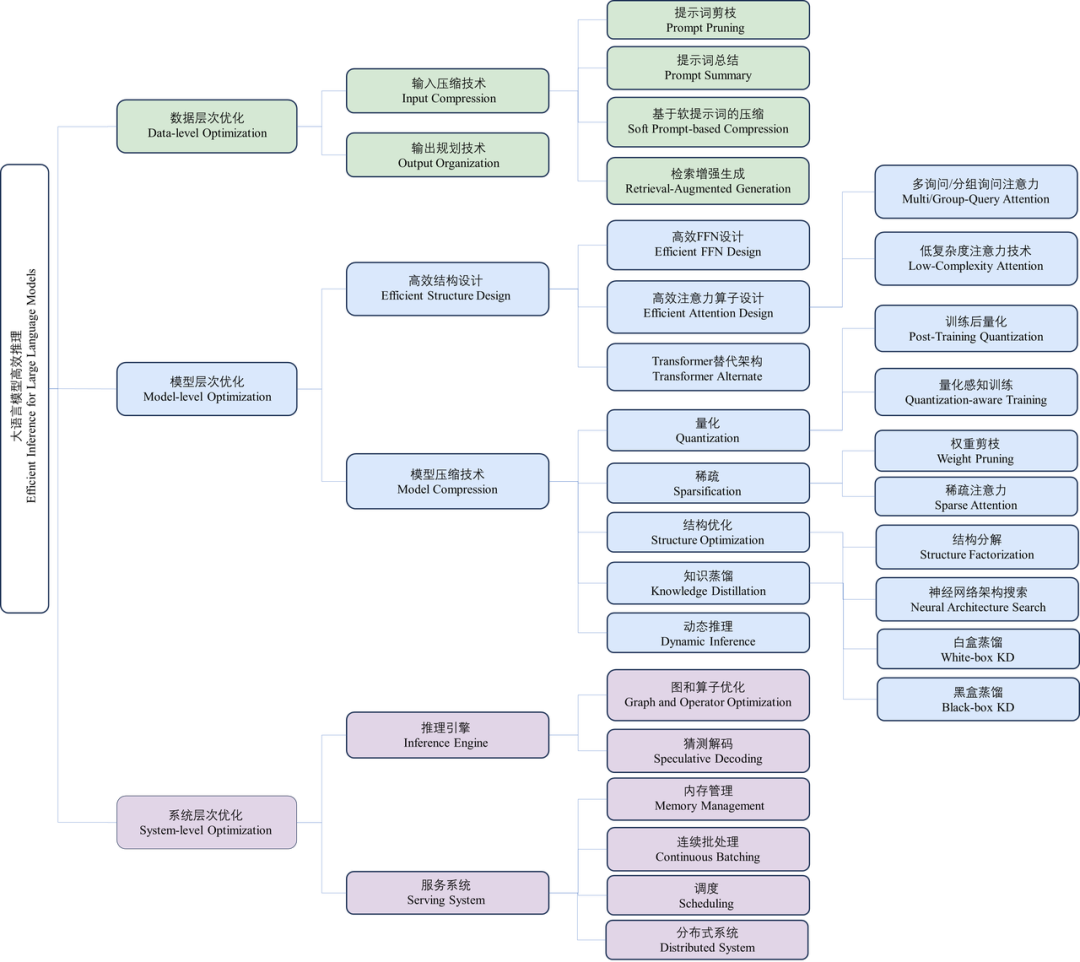
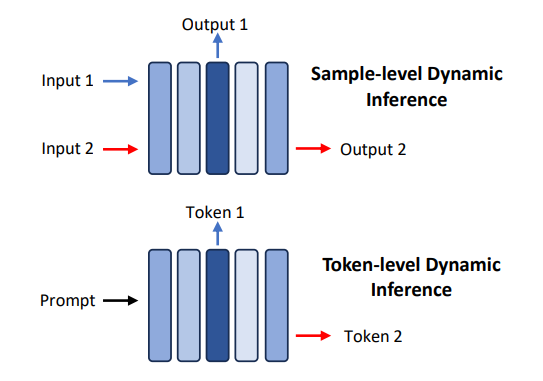
数据层优化技术:指通过优化输入提示词或规划模型输出内容优化推理效率。这类优化技术通常不需要修改模型本身,因此避免了大量的模型训练或微调开销; -
模型层优化技术:指通过设计高效的模型结构或模型压缩技术优化推理效率。这类技术通常需要对模型进行预训练或微调来恢复任务精度,同时通常对输出结果是有损的; -
系统层优化技术:指通过优化推理引擎或服务系统优化推理效率。这类技术通常不需要额外的模型训练开销,同时可以保证对输出结果是无损的。
本综述将该类技术进一步划分为四个小类,分别为:
-
提示词剪枝(Prompt Pruning):通常根据设计好的重要度评估指标删除输入提示词中不重要的词块、句子或文段,对被压缩的输入提示词执行在线压缩。 -
提示词总结(Prompt Summary):通过对输入提示词做文本总结任务,在保证其语义信息相同地情况下缩短输入的长度。该压缩过程通常也是在线执行的。 -
基于软提示词的压缩(Soft Prompt-based Compression):通过微调训练的方式得到一个长度较短的软提示词,代替原先的输入提示词(在线执行)或其中固定的一部分内容(离线执行)。其中,软提示词指连续的、可学习的词块序列,可以通过训练的方式学习得到。 -
检索增强生成(Retrieval-Augmented Generation):通过检索和输入相关的辅助内容,并只将这些相关的内容加入到输入提示词中,来降低原本的输入长度(相比于加入所有辅助内容)。
-
更高效地获取专家FFN的权重或构建更轻量化的专家FFN; -
优化路由模型使其分配更加平衡,避免因分配不平衡导致的精度和效率下降; -
优化MoE模型的训练方式,使得训练更加稳定。
-
多询问(Multi-Query)注意力技术,即在不同的注意力头之间共享部分Key和Value来降低访存开销和内存占用; -
低复杂度(Low-Complexity)注意力技术,主要包括基于核函数(Kernel-based)的注意力算子和低秩注意力(Low-Rank)算子。
-
状态空间模型(State Space Models,SSMs)。这类模型的核心思想是将历史信息压缩到一个隐状态(state)中,通过状态间的转移建模新的信息。聚焦于状态空间模型的研究可以分为两个方向,一方面研究状态转移矩阵初始化和参数化的方式,另一方面研究与其他模型结构(如Transformer、门控单元等)的融合架构。 -
非状态空间模型。这类工作主要包含两个分支,分别是采用长卷积做序列建模,以及采用基于注意力机制做改进的线性建模算子。下表列举了典型的Transformer替代架构的复杂度,可以总结出该类架构的研究趋势: 🔸在训练方面,新架构倾向于采用卷积或类注意力算子的形式来保持训练的并行性; 🔸在推理方面,新架构倾向于在预填充阶段保证和输入长度呈线性的计算复杂度,在解码阶段保证与文本长度无关的计算复杂度。

-
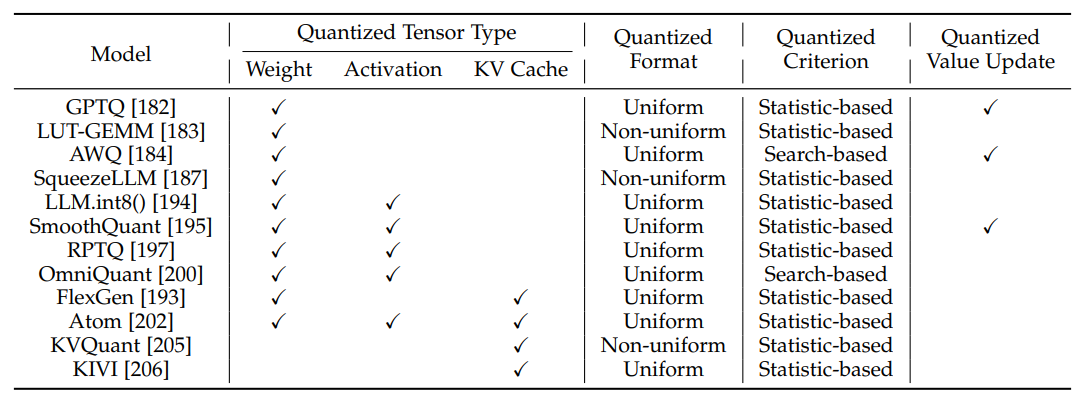
训练后量化(Post-Training Quantization,PTQ):指对预训练后的模型直接做量化,不需要重新训练量化后的模型。这类方法对量化后模型的精度损失较大,但因其不需要额外的模型训练开销,因此在大语言模型领域应用最为广泛。下表总结了典型的训练后量化方法在各个维度的比较。此外,在实际应用中,开发者通常还需要关注量化对大语言模型各种能力的损失,无问芯穹于2024年1月发布的工作QLLM-Eval[204](已被ICML2024录用)从不同量化模型、量化参数和量化维度全面研究了量化对模型能力的影响,并给出了针对量化技术的使用指南。
-
训练感知量化(Quantization-Aware Training,QAT):指在模型的训练中加入模型量化过程,并通过训练减小量化带来的精度损失。相比于训练后量化,训练感知量化方法通常具有更高的精度,但其需要大量的数据和计算量来做模型训练。因此,目前该子领域的研究主要关注于如何在数据层面和计算量层面降低模型训练带来的开销。
-
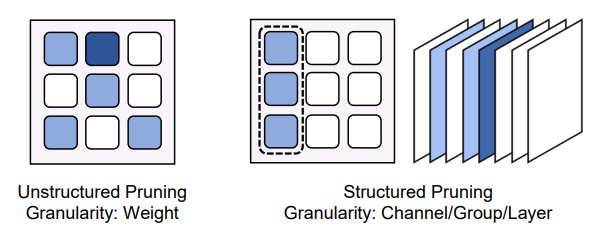
权重剪枝(Weight Pruning):指通过将模型中不重要的权重和对应结构移除,降低模型的计算和存储开销。权重剪枝可以分为非结构化剪枝(Unstructural Pruning)和结构化剪枝(Structural Pruning)两大类,两者区别主要在于剪枝粒度不同,如下图所示。其中,在非结构化剪枝领域,目前的研究工作主要关注于如何加速对大模型的剪枝过程,以及如何设计更有效的重要度分析指标和剪枝率分配策略。而在结构化剪枝领域,目前的研究工作大多关注于如何设计规整的剪枝结构来支持结构化的剪枝。
-
稀疏注意力(Sparse Attention):指通过减少冗余的注意力计算,来降低预填充阶段的计算开销和解码阶段中KV cache带来存储和访存开销。该领域的研究工作主要关注于设计更有效的稀疏模式(Sparse Pattern),包括静态稀疏(下图中(a)和(b)所示)以及动态稀疏(下图中(c)和(d)所示)。无问芯穹于2023年9月发布的工作SemSA[204],通过对每个注意力头自动选择注意力掩膜和掩膜扩展方式,在平均稀疏度相同的情况下,大幅提升稀疏注意力大语言模型的有效上下文长达3.9倍。 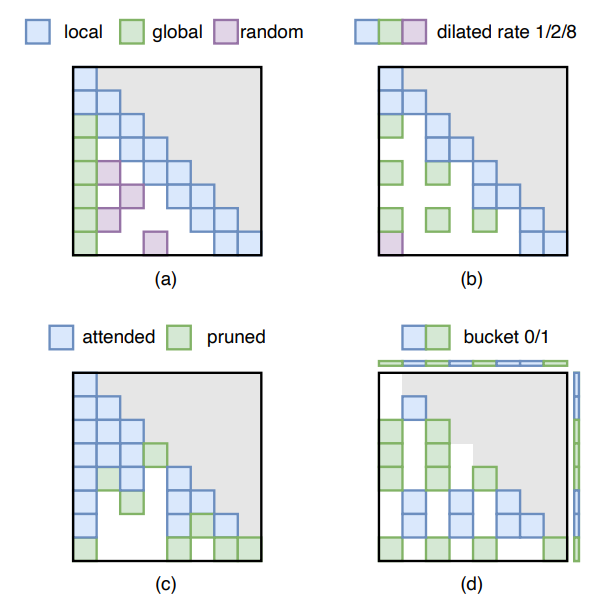
-
神经网络架构搜索(Neural Architecture Search):指自动化地搜索出最优的模型架构。然而,这类方法目前只在中等规模的语言模型上得到应用,在大语言模型上还未获得实际的优化效果,原因是该技术通常需要在搜索过程中对采样到的架构进行训练评估,对大模型来说需要花费巨大的训练开销。 -
低秩分解(Low Rank Factorization):指将一个大的权重矩阵近似分解成两个低质小矩阵的乘积,通过该技术,可以降低大语言模型权重的存储开销和访存开销。该领域的研究工作主要聚焦于设计分解方式,以及将该技术与其他模型压缩技术(例如量化、剪枝等)结合获得更高的效率优化效果。

2.2.3 知识、建议和未来方向
-
模型量化是目前最常用也是最推荐使用的模型压缩技术,一方面,该技术可以很方便快捷地压缩大语言模型,另一方面,该技术能在有效提升模型效率的同时,尽可能地保证模型的精度损失最小。然而,模型量化技术仍然不可避免地会对模型的能力造成负面影响,因此需要根据任务和应用场景谨慎选取最合适的模型量化算法。 -
模型稀疏方面,目前有许多研究工作关注稀疏注意力技术,并将其应用在处理长文本的场景中,然而这类技术通常会损失部分信息,导致任务精度的下降,因此如何在保留有效信息的同时还能高效处理长文本是一个值得探索的问题。而在权重剪枝领域,有研究工作[217]指出目前的剪枝方法在不显著影响任务精度的前提下,仅能达到较低的剪枝率水平,因此设计更有效的模型剪枝算法是一个值得研究的方向。 -
结构优化方面,神经网络架构搜索技术受限于其高昂的评估成本,难以被应用在大语言模型的压缩上,然而这种自动化压缩的思想仍然值得进一步的探索。另一方面,低秩分解技术受限于其难以同时保证任务精度和压缩比例。 -
此外,还有一些工作探究将不同的模型层技术结合,例如将混合专家技术和低秩分解结合、将模型量化和权重稀疏结合、将模型量化和低秩分解结合、将权重剪枝和低秩分解结合。这些方法展示了整合多种压缩技术以实现大型语言模型更佳优化的潜力。
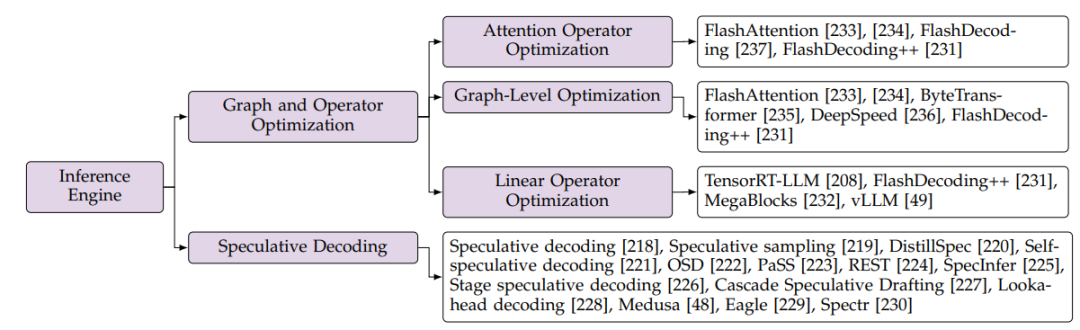

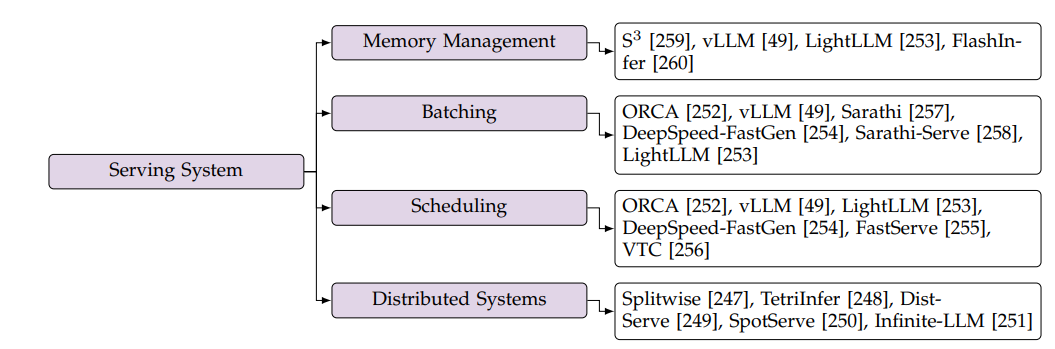

-
智能体和多模型框架。在最近的研究中,大语言模型智能体和多模型协同框架受到了许多关注,这类技术可以提升大语言模型的应用能力,使得模型能更好地服务于人类。然而模型的数量增多,以及输入到模型中的指令变长,都会使得智能体或框架系统的推理效率变低。因此需要面向这些框架和场景进行大模型的推理效率优化。 -
长文本场景。随着输入模型文本变得越来越长,大语言模型的效率优化需求变得愈发提升。目前在数据层、模型层和系统层均有相关的技术来优化长文本场景下大语言模型的推理效率,其中设计Transformer的替代新架构受到了许多关注,然而这类架构还未被充分探索,其是否能匹敌传统的Transformer模型仍未清楚。 -
边缘端部署。最近,许多研究工作开始关注于将大语言模型部署到边缘设备上,例如移动手机。一类工作致力于设计将大模型变小,通过直接训练小模型或模型压缩等途径达到该目的;另一类工作聚焦于系统层的优化,通过算子融合、内存管理等技术,直接将70亿参数规模的大模型成功部署到移动手机上。 -
安全-效率协同优化。除了任务精度和推理效率外,大语言模型的安全性也是一个需要被考量的指标。当前的高效性研究均未考虑优化技术对模型安全性的影响。若这些优化技术对模型的安全性产生了负面影响,一个可能的研究方向就是设计新的优化方法,或改进已有的方法,使得模型的安全性和效率能一同被考量。

