文章来源于互联网:ACL 2024论文盖棺定论:大语言模型≠世界模拟器,Yann LeCun:太对了
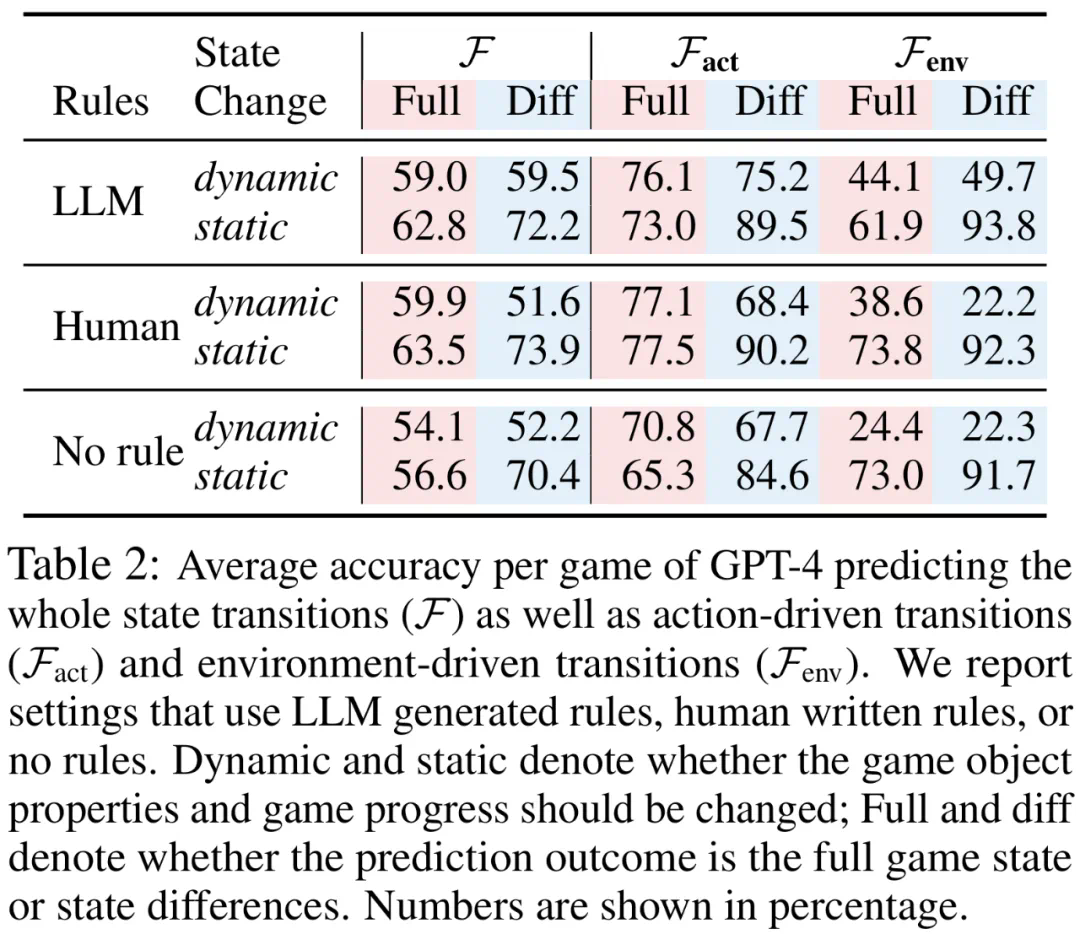
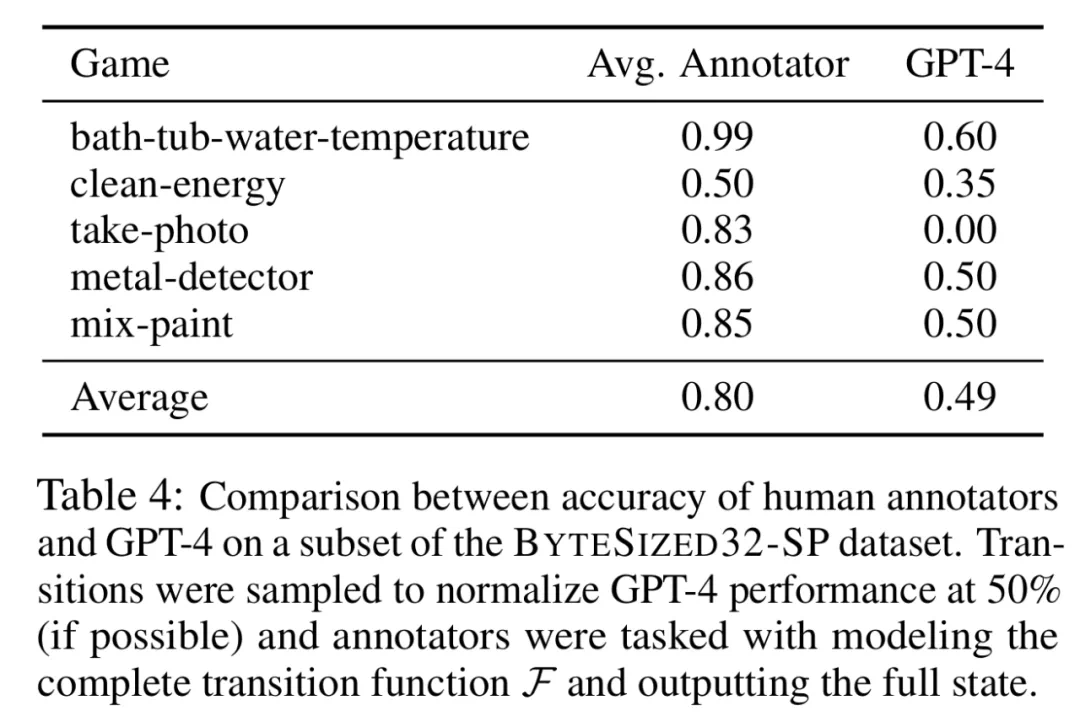
如果 GPT-4 在模拟基于常识任务的状态变化时准确率都只有约 60%,那么我们还要考虑将大语言模型作为世界模拟器来使用吗?
 x 地址:https://x.com/peterjansen_ai/status/1801687501557665841
x 地址:https://x.com/peterjansen_ai/status/1801687501557665841
 X 地址:https://x.com/ylecun/status/1801978192950927511
X 地址:https://x.com/ylecun/status/1801978192950927511


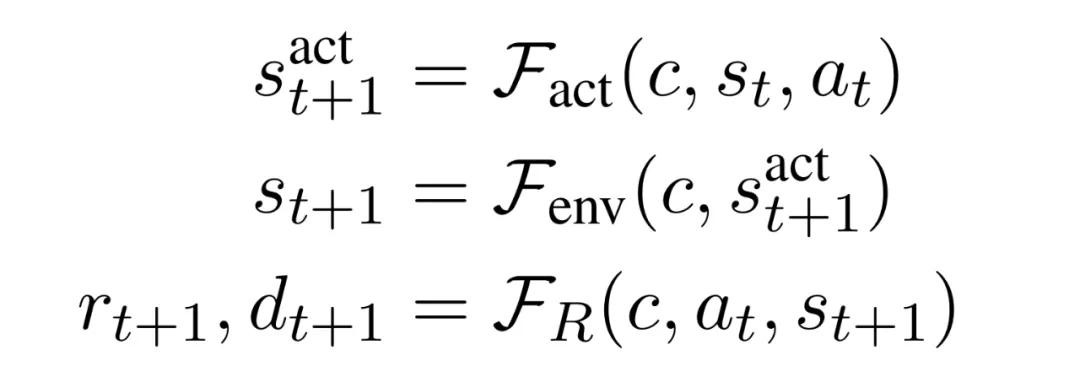
-
动作驱动转换模拟器:给定 c、s_t 和 a_t, F_act:C×S×A→S 预测 s^act_t+1,其中 s^act_t+1 表示动作引起的直接状态变化。 -
环境驱动转换模拟器:给定 c 和 s^act_t+1,F_env:C×S→S 预测 s_t+1,其中 s_t+1 是任何环境驱动转换后产生的状态。 -
游戏进度模拟器:给定 c、s_t+1 和 a_t, F_R:C×S×A→R×{0,1} 预测奖励 r_t+1 和游戏完成状态 d_t+1。
-
完整状态预测:LLM 输出完整状态。 -
状态差异预测:LLM 仅输出输入和输出状态之间的差异。

-
对象属性:游戏中所有对象、每个对象的属性(如温度、大小),以及与其他对象的关系(如在另一个对象内或之上)。 -
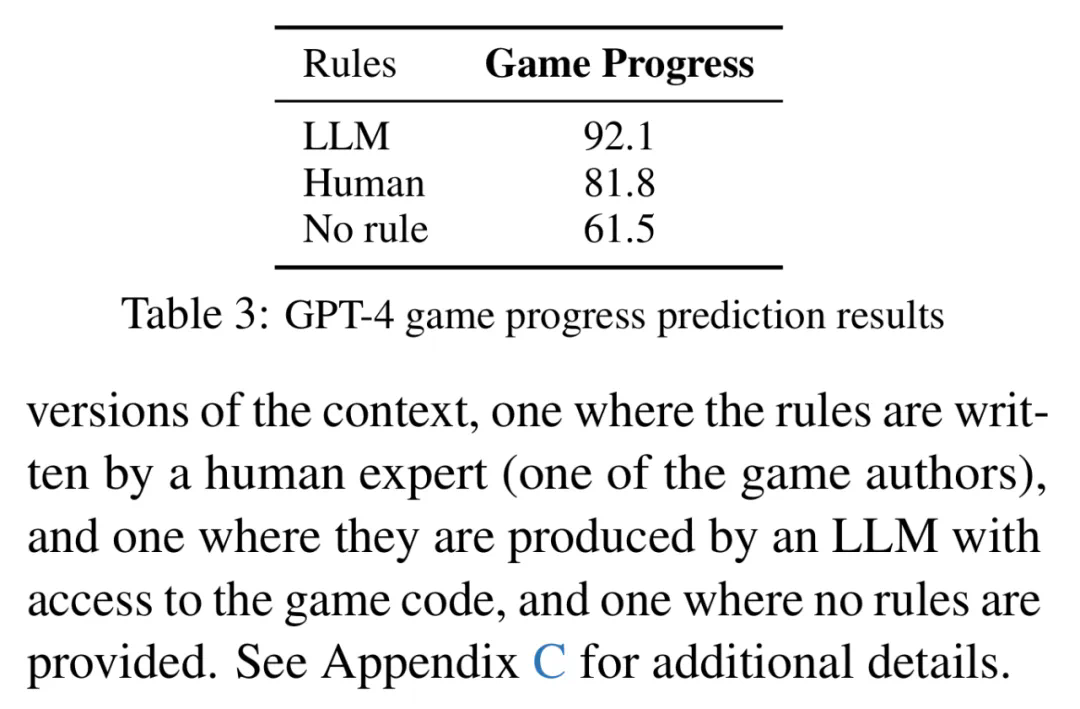
游戏进度:智能体相对于总体目标的状态,包括当前累积的奖励、游戏是否已终止以及总体目标是否已实现。