文章来源于互联网:中科大联合华为诺亚提出Entropy Law,揭秘大模型性能、数据压缩率以及训练损失关系

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
团队:中科大认知智能全国重点实验室陈恩红团队,华为诺亚方舟实验室 -
论文链接: https://arxiv.org/pdf/2407.06645 -
代码链接: https://github.com/USTC-StarTeam/ZIP
-
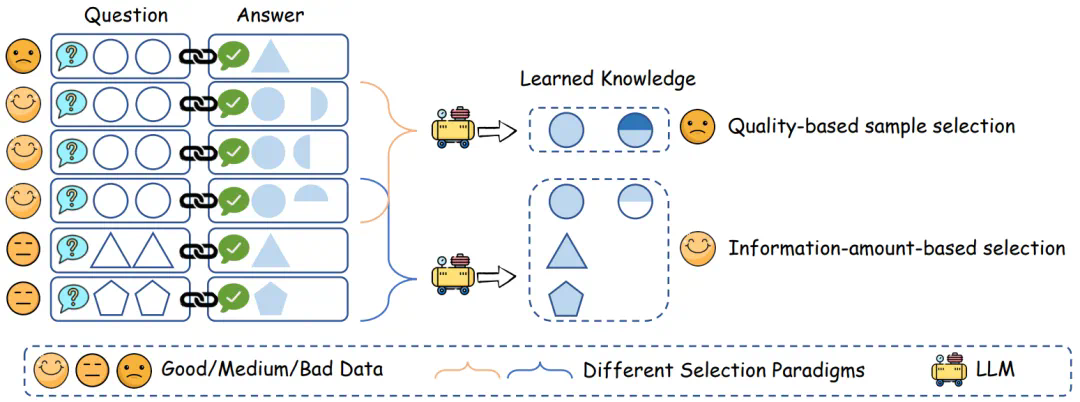
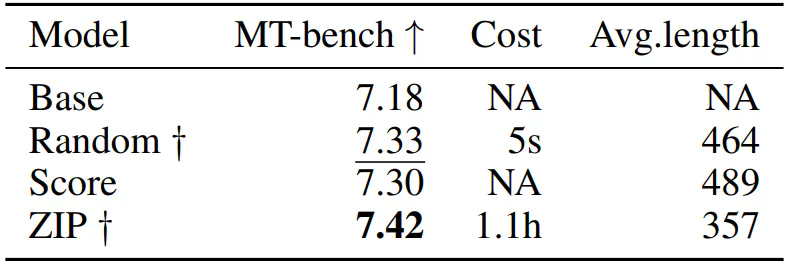
数据压缩率 R:直觉上,压缩率越低的数据集表明信息密度越高。 -
训练损失 L:表示数据对模型来说是否难以记忆。在相同的基础模型下,高训练损失通常是由于数据集中存在噪声或不一致的信息。 -
数据一致性 C:数据的一致性通过给定前文情况下下一个 token 的概率的熵来反映。更高的数据一致性通常会带来更低的训练损失。 -
平均数据质量 Q:反映了数据的平均样本级质量,可以通过各种客观和主观方面来衡量。
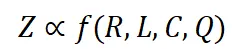
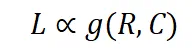
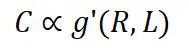
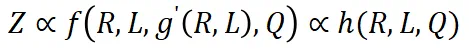
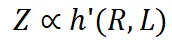
-
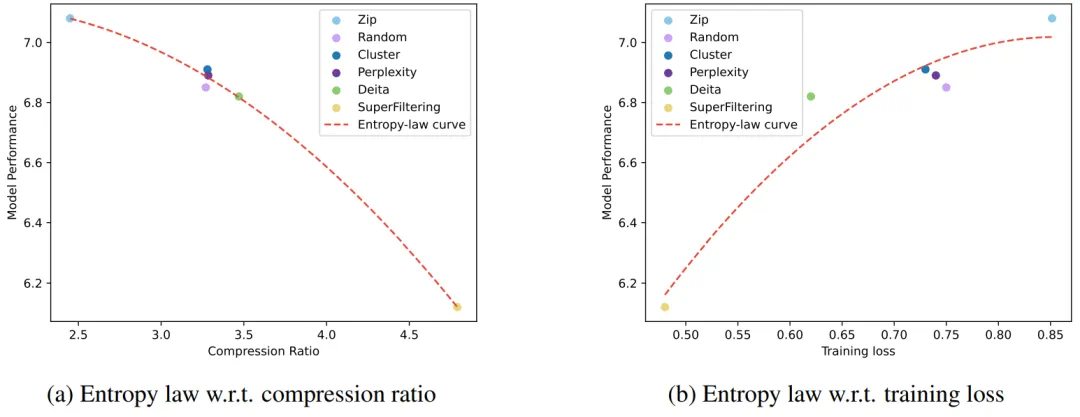
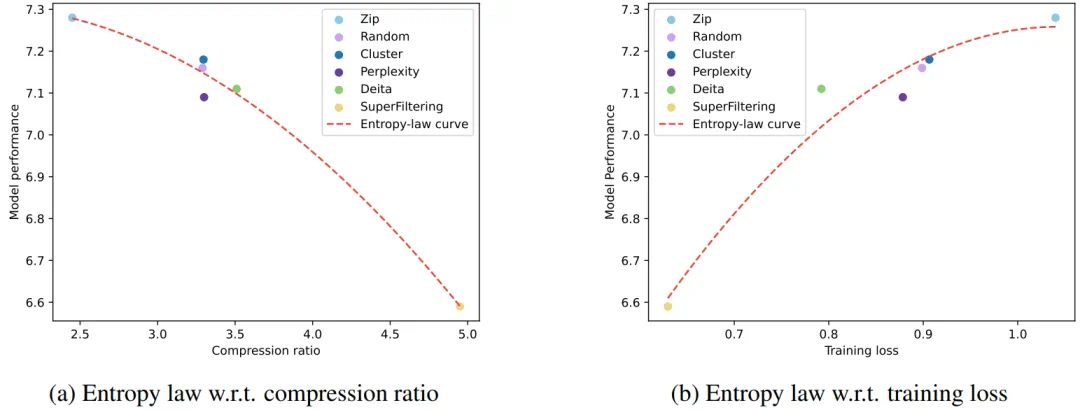
如果将 C 视为常数,训练损失直接受压缩率影响。因此,模型性能由压缩率控制:如果数据压缩率 R 较高,那么 Z 通常较差,这将在我们的实验中得到验证。 -
在相同的压缩率下,较高训练损失意味着较低的数据一致性。因此,模型学到的有效知识可能更有限。这可以用来预测 LLM 在具有相似压缩率和样本质量的不同数据上的性能。我们将在后续展示这一推论在实践中的应用。

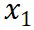 到
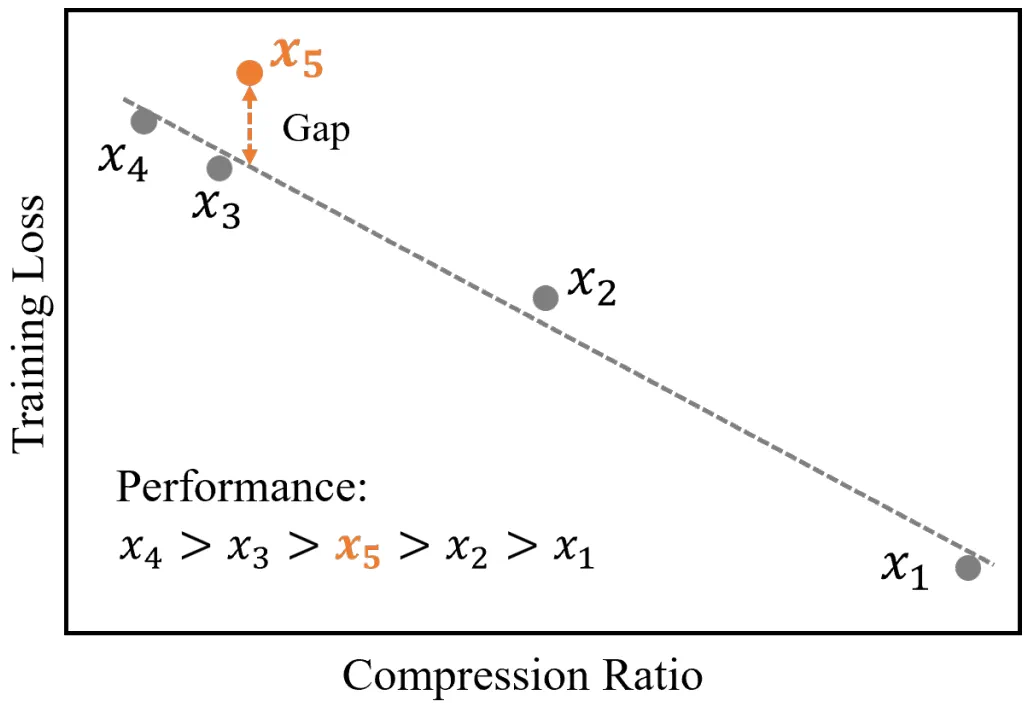
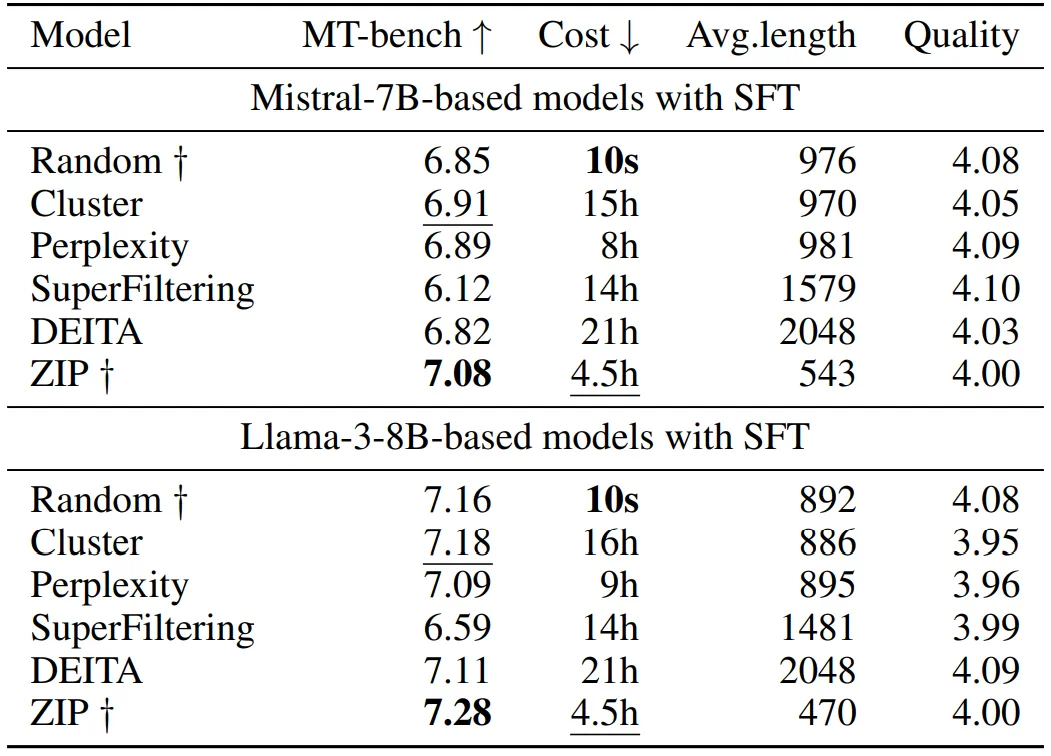
到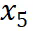 是逐渐增量更新的 5 个数据版本,出于保密要求,仅提供不同压缩率下模型效果的相对关系。根据 entropy law 预测,假设每次增量更新后数据质量没有显著下降,可以预期随着数据压缩率的降低,模型性能会有所提升。这一预测与图中数据版本
是逐渐增量更新的 5 个数据版本,出于保密要求,仅提供不同压缩率下模型效果的相对关系。根据 entropy law 预测,假设每次增量更新后数据质量没有显著下降,可以预期随着数据压缩率的降低,模型性能会有所提升。这一预测与图中数据版本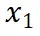 到
到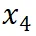 的结果一致。然而,数据版本
的结果一致。然而,数据版本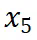 显示出损失和数据压缩率的异常增加,这预示了由于训练数据一致性下降导致的模型性能下降的潜在可能。这一预测通过随后的模型性能评估进一步得到证实。因此,entropy law 可以作为 LLM 训练的指导原则,无需在完整数据集上训练模型直到收敛,便可预测 LLM 训练失败的潜在风险。鉴于训练 LLM 的高昂成本,这一点尤其重要。
显示出损失和数据压缩率的异常增加,这预示了由于训练数据一致性下降导致的模型性能下降的潜在可能。这一预测通过随后的模型性能评估进一步得到证实。因此,entropy law 可以作为 LLM 训练的指导原则,无需在完整数据集上训练模型直到收敛,便可预测 LLM 训练失败的潜在风险。鉴于训练 LLM 的高昂成本,这一点尤其重要。