文章来源于互联网:无限生成视频,还能规划决策,扩散强制整合下一token预测与全序列扩散
当前,采用下一 token 预测范式的自回归大型语言模型已经风靡全球,同时互联网上的大量合成图像和视频也早已让我们见识到了扩散模型的强大之处。
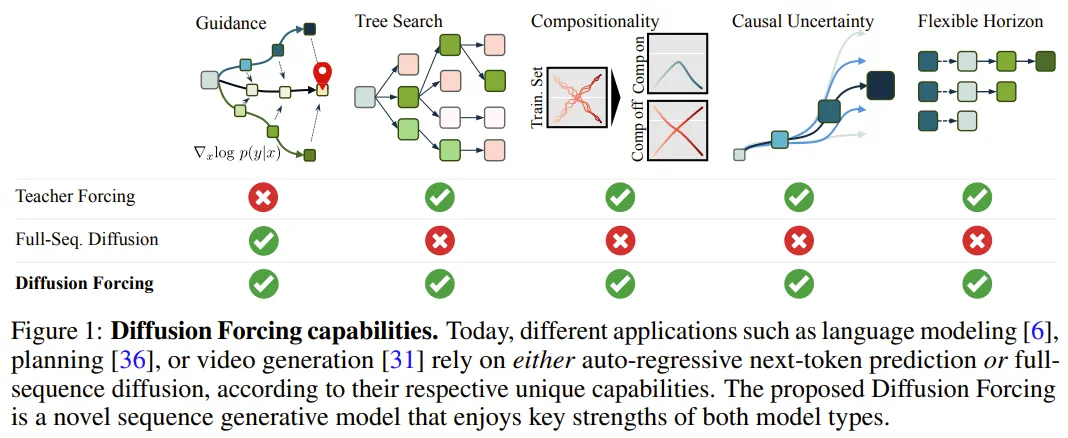
近日,MIT CSAIL 的一个研究团队(一作为 MIT 在读博士陈博远)成功地将全序列扩散模型与下一 token 模型的强大能力统合到了一起,提出了一种训练和采样范式:Diffusion Forcing(DF)。

-
论文标题:Diffusion Forcing:Next-token Prediction Meets Full-Sequence Diffusion
-
论文地址:https://arxiv.org/pdf/2407.01392
-
项目网站:https://boyuan.space/diffusion-forcing
-
代码地址:https://github.com/buoyancy99/diffusion-forcing
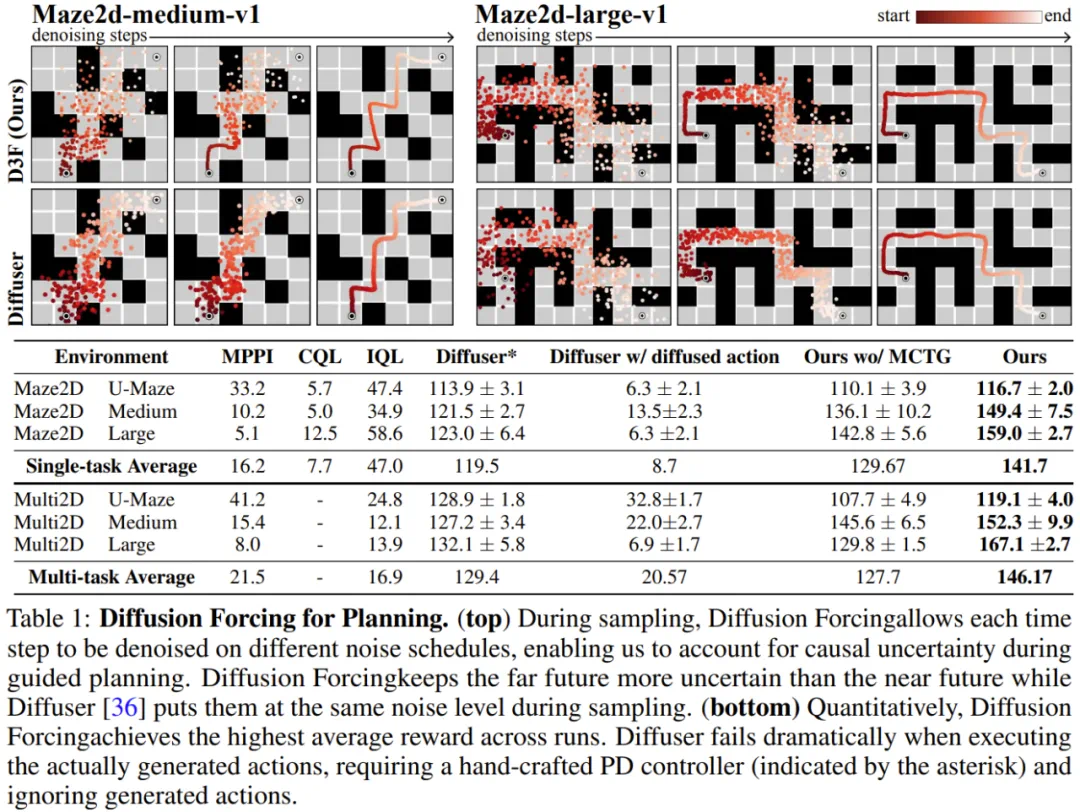
如下所示,扩散强制在一致性和稳定性方面都明显胜过全序列扩散和教师强制这两种方法。

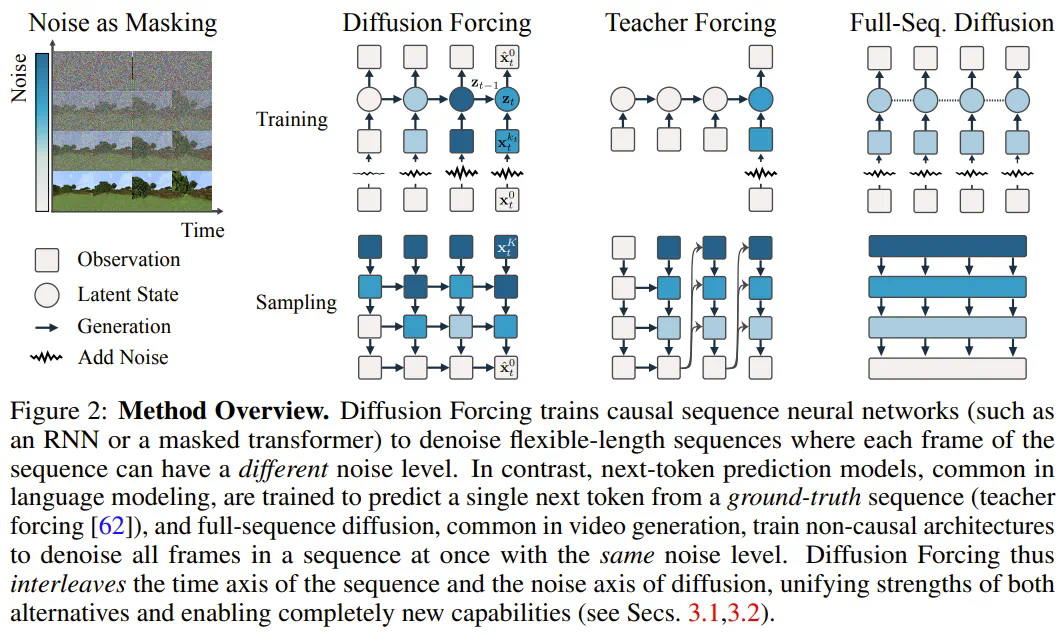
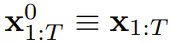 添加噪声的过程)看作一种部分掩码(partial masking),这可被称为「沿噪声轴执行掩码)。
添加噪声的过程)看作一种部分掩码(partial masking),这可被称为「沿噪声轴执行掩码)。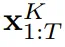 (大概)就是白噪声了,不再有任何有关原数据的信息。
(大概)就是白噪声了,不再有任何有关原数据的信息。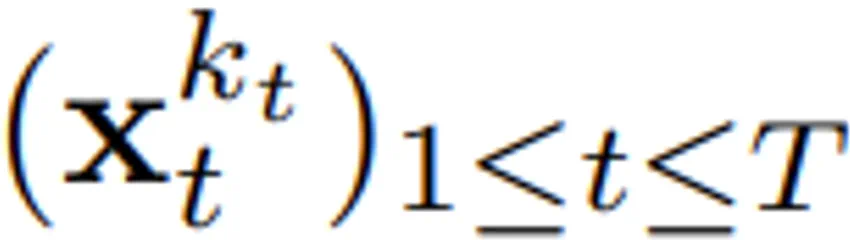 ,其中的关键在于每个 token 的噪声水平 k_t 会随时间步骤而变化。
,其中的关键在于每个 token 的噪声水平 k_t 会随时间步骤而变化。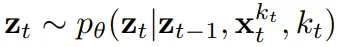 而演化。当获得输入噪声观察
而演化。当获得输入噪声观察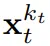 时,就以马尔可夫方式更新该隐藏状态。
时,就以马尔可夫方式更新该隐藏状态。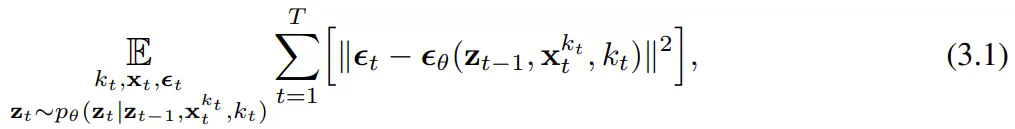

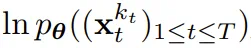 上优化证据下限(ELBO)的重新加权,其中期望值会在噪声水平上平均,而
上优化证据下限(ELBO)的重新加权,其中期望值会在噪声水平上平均,而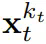 是根据前向过程加噪。此外,在适当条件下,优化 (3.1) 式还可以同时最大化所有噪声水平序列的似然下限。
是根据前向过程加噪。此外,在适当条件下,优化 (3.1) 式还可以同时最大化所有噪声水平序列的似然下限。
-
让自回归生成变得稳定 -
保持未来的不确定 -
长期引导能力
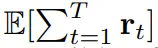 的预期累积奖励最大化。这里分配 token x_t = [a_t, r_t, o_{t+1}]。一条轨迹就是一个序列 x_{1:T},其长度可能是可变的;训练方式则如算法 1 所示。
的预期累积奖励最大化。这里分配 token x_t = [a_t, r_t, o_{t+1}]。一条轨迹就是一个序列 x_{1:T},其长度可能是可变的;训练方式则如算法 1 所示。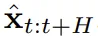 ,其中
,其中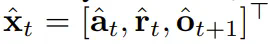 包含预测的动作、奖励和观察。H 是一个前向观察窗口,类似于模型预测控制中的未来预测。在采用了规划的动作之后,环境会得到一个奖励和下一个观察,从而得到下一个 token。其中隐藏状态可以根据后验 p_θ(z_t|z_{t−1}, x_t, 0) 获得更新。
包含预测的动作、奖励和观察。H 是一个前向观察窗口,类似于模型预测控制中的未来预测。在采用了规划的动作之后,环境会得到一个奖励和下一个观察,从而得到下一个 token。其中隐藏状态可以根据后验 p_θ(z_t|z_{t−1}, x_t, 0) 获得更新。-
具有灵活的规划范围 -
可实现灵活的奖励引导 -
能实现蒙特卡洛树引导(MCTG),从而实现未来不确定性




文章来源于互联网:无限生成视频,还能规划决策,扩散强制整合下一token预测与全序列扩散

