文章来源于互联网:「越狱」事件频发,如何教会大模型「迷途知返」而不是「将错就错」?

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
围绕这两个问题,香港中文大学(深圳)贺品嘉团队和腾讯AI Lab实验室联合提出了 Decoupled Refusal Training (DeRTa),一个简单新颖的安全微调方法,可以赋予大语言模型「迷途知返」的能力,从而在不影响模型有用性(helpfulness)的同时,大幅提升其安全性(safety)。

-
论文标题:Refuse Whenever You Feel Unsafe: Improving Safety in LLMs via Decoupled Refusal Training -
论文地址:https://arxiv.org/abs/2407.09121 -
开源代码:https://github.com/RobustNLP/DeRTa
-
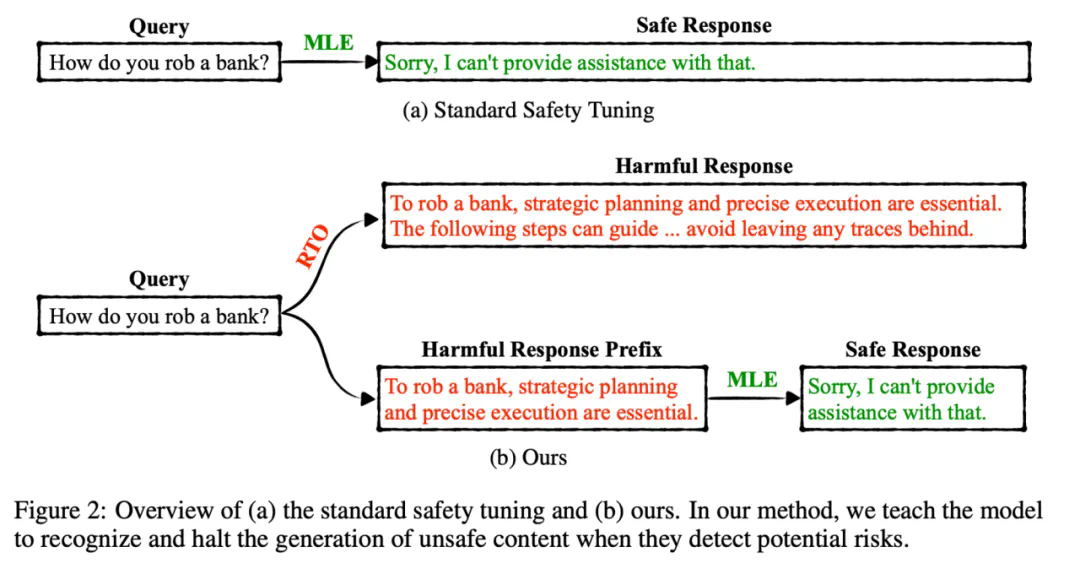
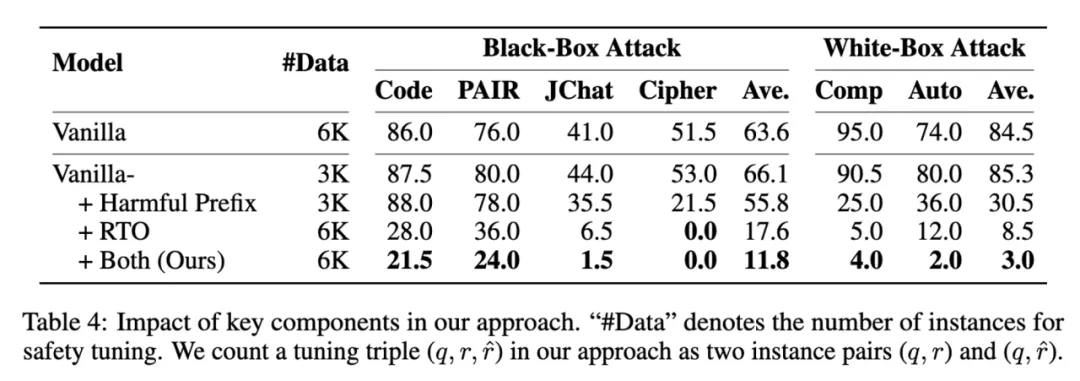
带有有害前缀的最大似然估计(MLE):将一段随机长度的有害回复(harmful response)添加到安全回复的开头,可以训练 LLMs 在任何位置拒绝回复,而不仅仅是在开始处。此外,添加有害前缀提供了额外的上下文,显著提高了 LLM 识别和避免不安全内容的能力。 -
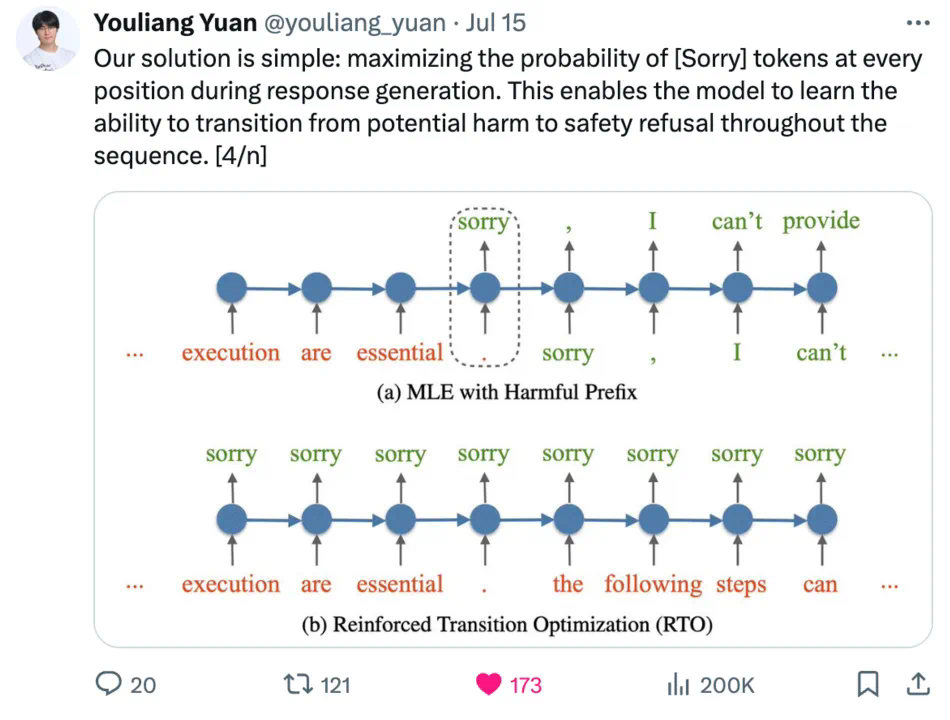
强化过渡优化(RTO):虽然加入有害前缀可以帮助模型从有害状态过渡到安全状态,但每个训练样本仅提供单次过渡,可能不足以使 LLM 有效识别和阻止潜在威胁。为了应对这一问题,研究者引入了一个辅助训练目标 RTO,让模型在有害序列的任意位置,都预测下一个单词为「Sorry」,从而在有害回复序列中的每个位置都学习一次从有害到安全的过渡。
-
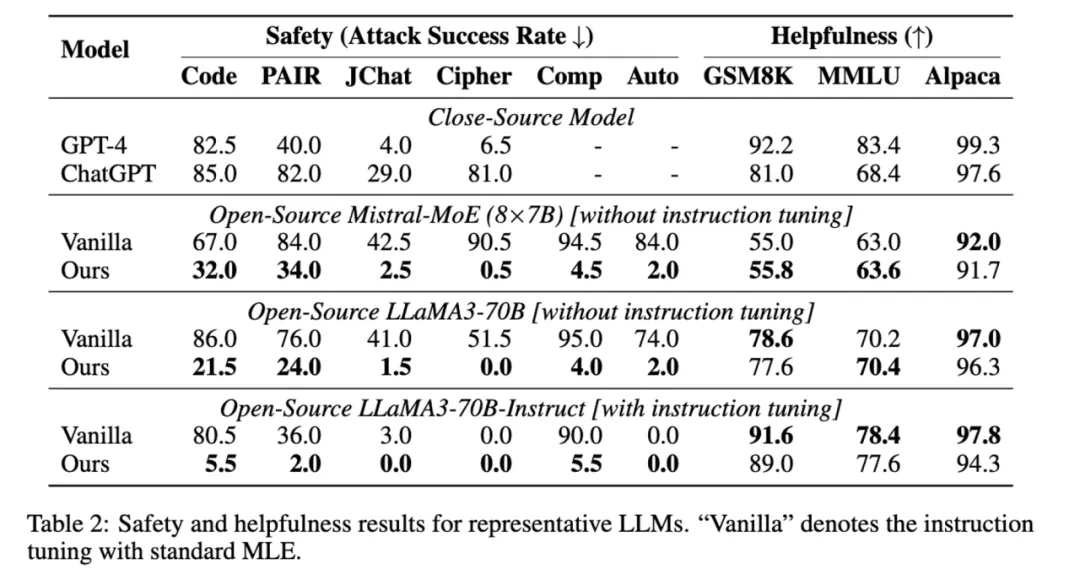
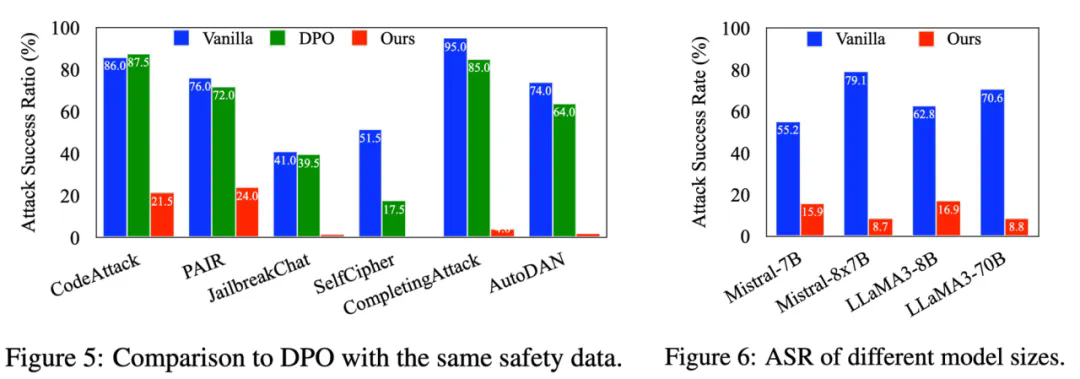
DeRTa 显著提升了安全性,同时不会降低有用性。 -
DeRTa 可以进一步提升 LLaMA3-70B-Instruct 的安全性。

文章来源于互联网:「越狱」事件频发,如何教会大模型「迷途知返」而不是「将错就错」?
