文章来源于互联网:清华、北大等发布Self-Play强化学习最新综述

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者来自于清华大学电子工程系,北京大学人工智能研究院、第四范式、腾讯和清华-伯克利深圳学院。其中第一作者张瑞泽为清华大学硕士,主要研究方向为博弈算法。通讯作者为清华大学电子工程系汪玉教授、于超博后和第四范式研究员黄世宇博士。

-
论文题目:A Survey on Self-play Methods in Reinforcement Learning
-
研究机构:清华大学电子工程系、北京大学人工智能研究院、第四范式、腾讯、清华-伯克利深圳学院
-
论文链接:https://arxiv.org/abs/2408.01072
强化学习(Reinforcement Learning,RL)是机器学习中的一个重要范式,旨在通过与环境的交互不断优化策略。基本问题建模是基于马尔可夫决策过程(Markov decision process,MDP),智能体通过观察状态、根据策略执行动作、接收相应的奖励并转换到下一个状态。最终目标是找到能最大化期望累计奖励的最优策略。
自博弈(self-play)通过与自身副本或过去版本进行交互,从而实现更加稳定的策略学习过程。自博弈在围棋、国际象棋、扑克以及游戏等领域都取得了一系列的成功应用。在这些场景中,通过自博弈训练得到了超越人类专家的策略。尽管自博弈应用广泛,但它也伴随着一些局限性,例如可能收敛到次优策略以及显著的计算资源需求等。
背景
该部分分别介绍了强化学习框架以及博弈论基本知识。强化学习框架我们考虑最一般的形式:部分可观察的马尔可夫博弈(partially observable Markov game, POMGs),即多智能体场景,且其中每个智能体无法完全获取环境的全部状态。
博弈论基础知识介绍了博弈具体类型,包括(非)完美信息博弈和(非)完全信息博弈、标准型博弈和扩展型博弈、传递性博弈和非传递性博弈、阶段博弈和重复博弈、团队博弈等。同样也介绍了博弈论框架重要概念包括最佳回应(Best responce, BR)和纳什均衡 (Nash equilibrium, NE)等。
复杂的博弈场景分析通常采用更高层次的抽象,即元博弈(meta-game)。元博弈关注的不再是单独的动作,而是更高层的复杂策略。在这种高层次抽象下,复杂博弈场景可以看作是特殊的标准型博弈,策略集合由复杂策略组成。元策略(meta-strategies)是对策略集合中的复杂策略进行概率分配的混合策略。
在该部分最后,我们介绍了多种常用的自博弈评估指标,包括 Nash convergence(NASHCONV)、Elo、Glicko、Whole-History Rating(WHR) 和 TrueSkill。
算法

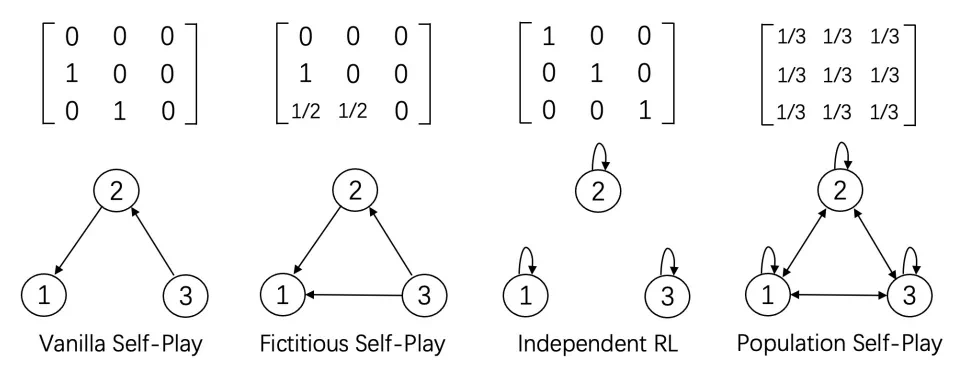


 类型一:传统自博弈算法
类型一:传统自博弈算法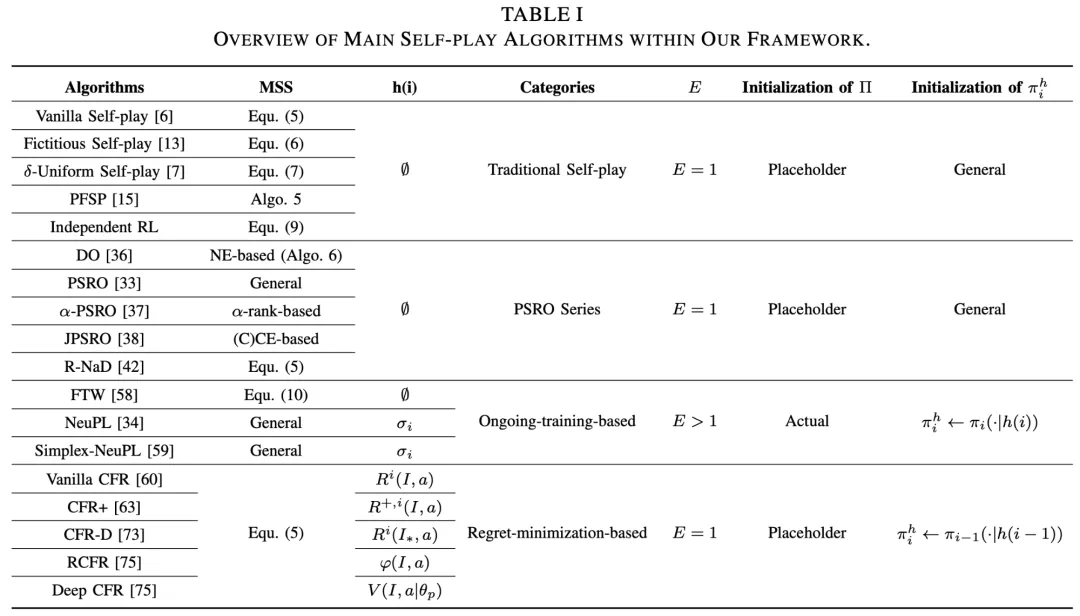
应用
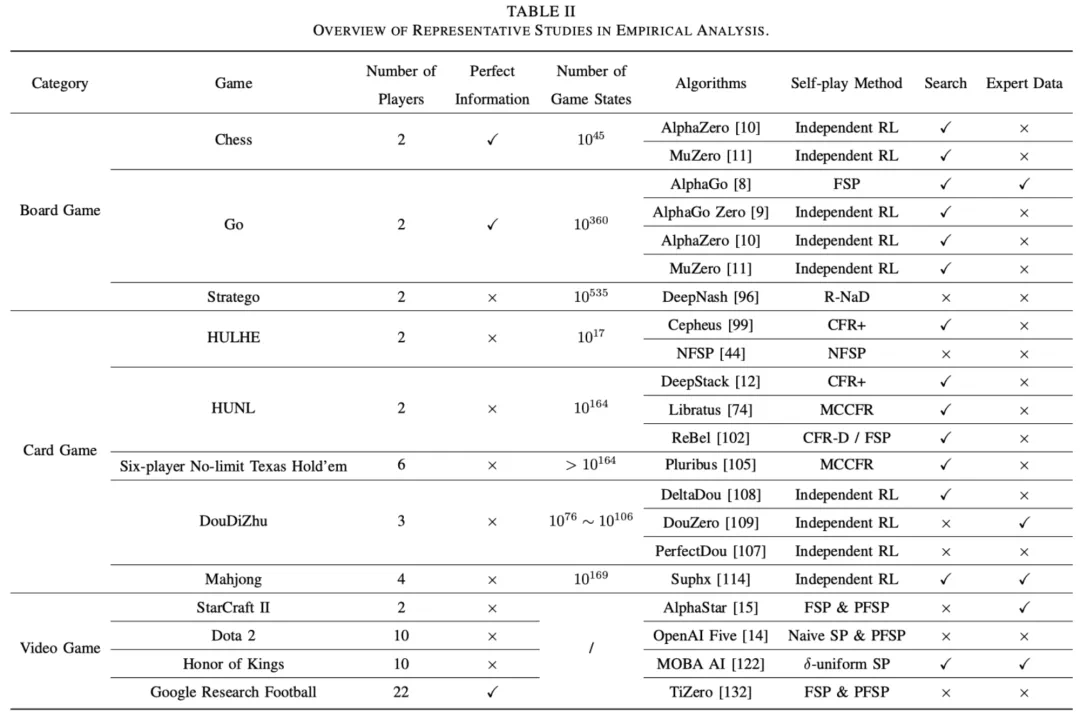 讨论
讨论文章来源于互联网:清华、北大等发布Self-Play强化学习最新综述
