文章来源于互联网:视觉模型学会LLM独门秘籍「上下文记忆」,迎来智能涌现的大爆发!
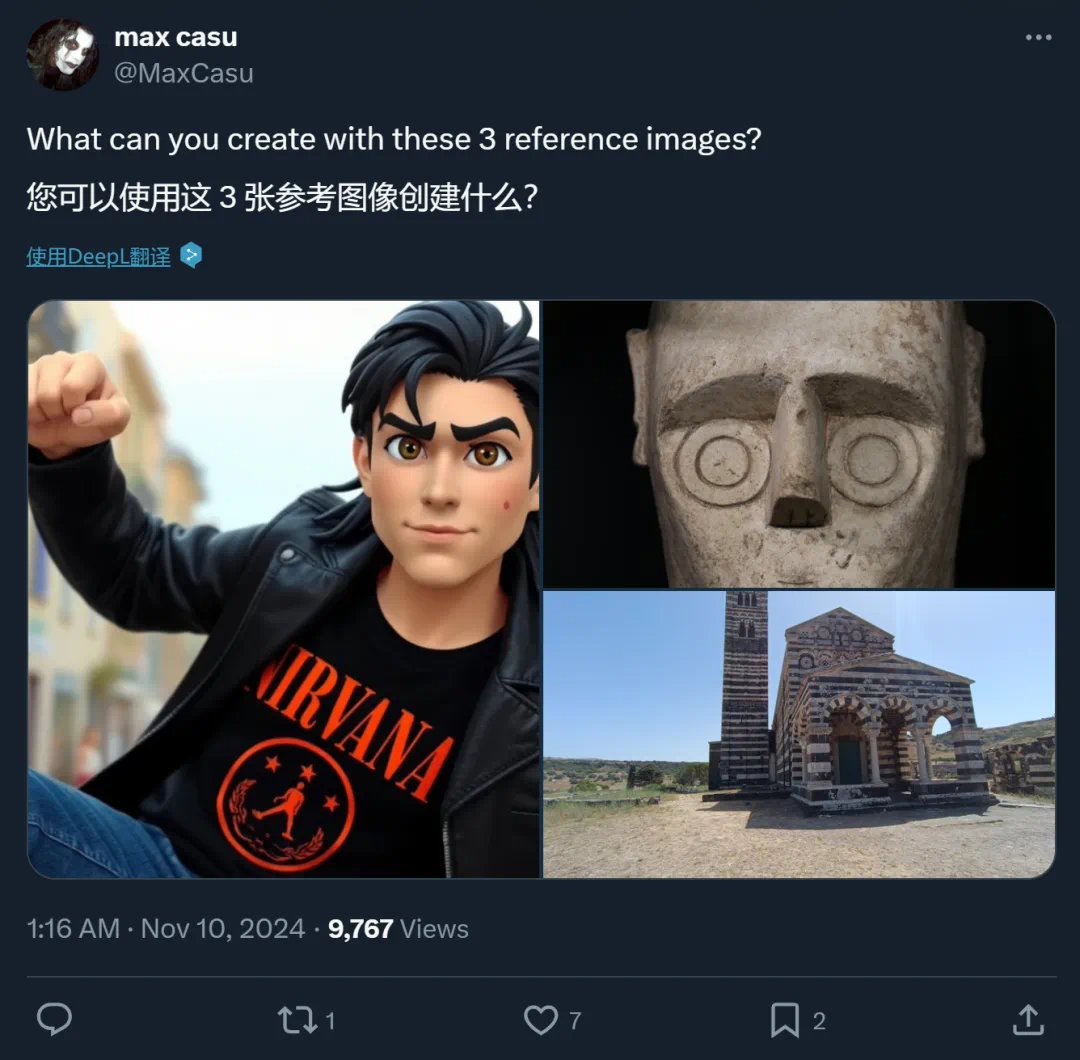













-
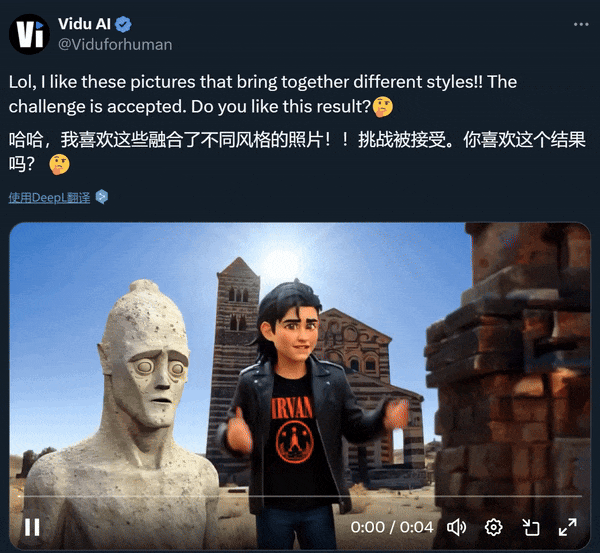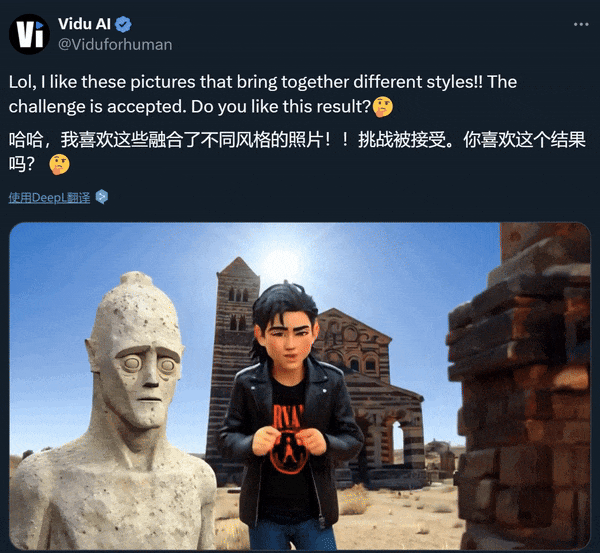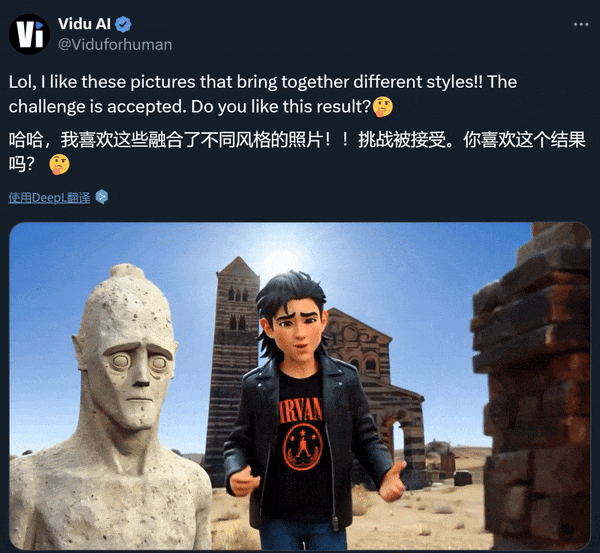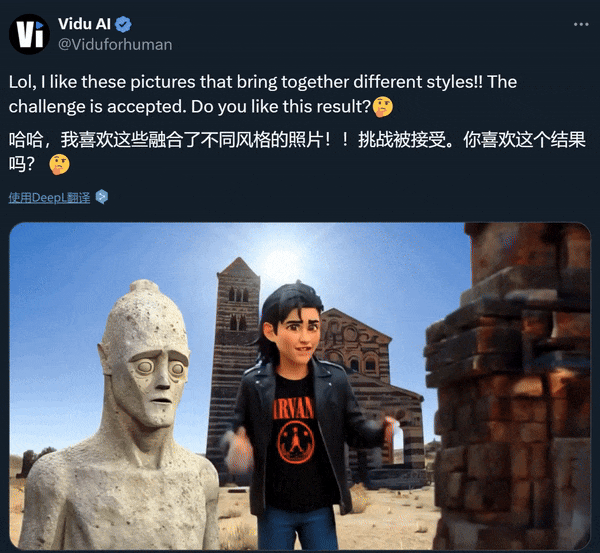
理解多主体的特征,简单说,有哪几样主体,都长什么样,模型能理解和记住;
-
理解描述指令的含义,知道要输出一个什么画面;
-
对不同主体、不同特征进行关联,比如「小男孩拿着蛋糕」这一画面,模型在记住男孩和蛋糕的特征之后,还需理解空间方位是怎样,将两个主体合理关联到一起。
-
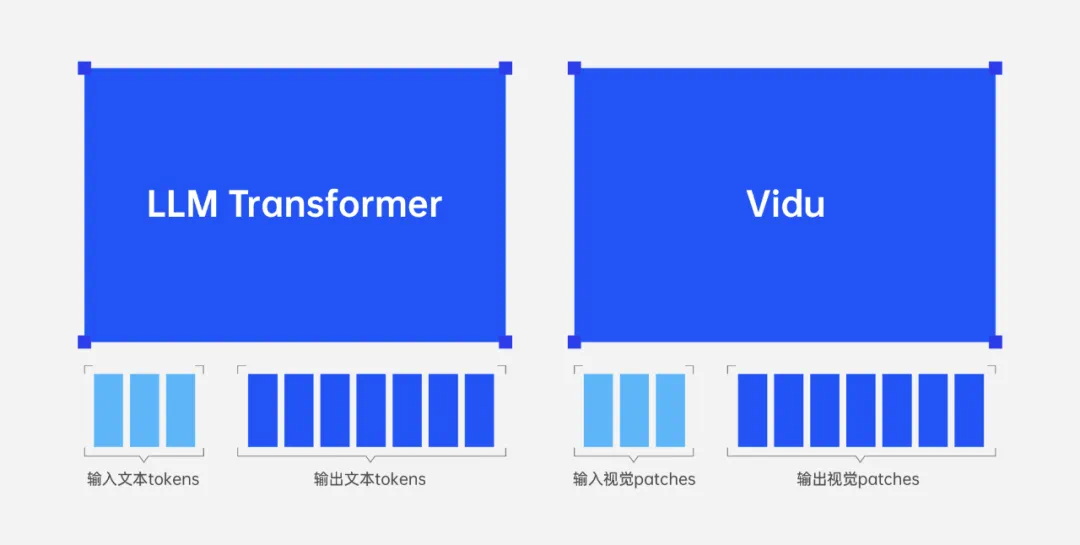
统一问题形式:LLM 将所有问题,不管是对话、翻译,还是代码,都统一为(文本输入,文本输出),Vidu 则是将所有问题统一为(视觉输入,视觉输出);
-
统一架构:均用单个网络统一建模变长的输入和输出;
-
压缩即智能:LLM 从文本数据的压缩中获取智能,Vidu 从视频数据的压缩中获取智能,都是从海量预训练数据中压缩提取丰富的知识。
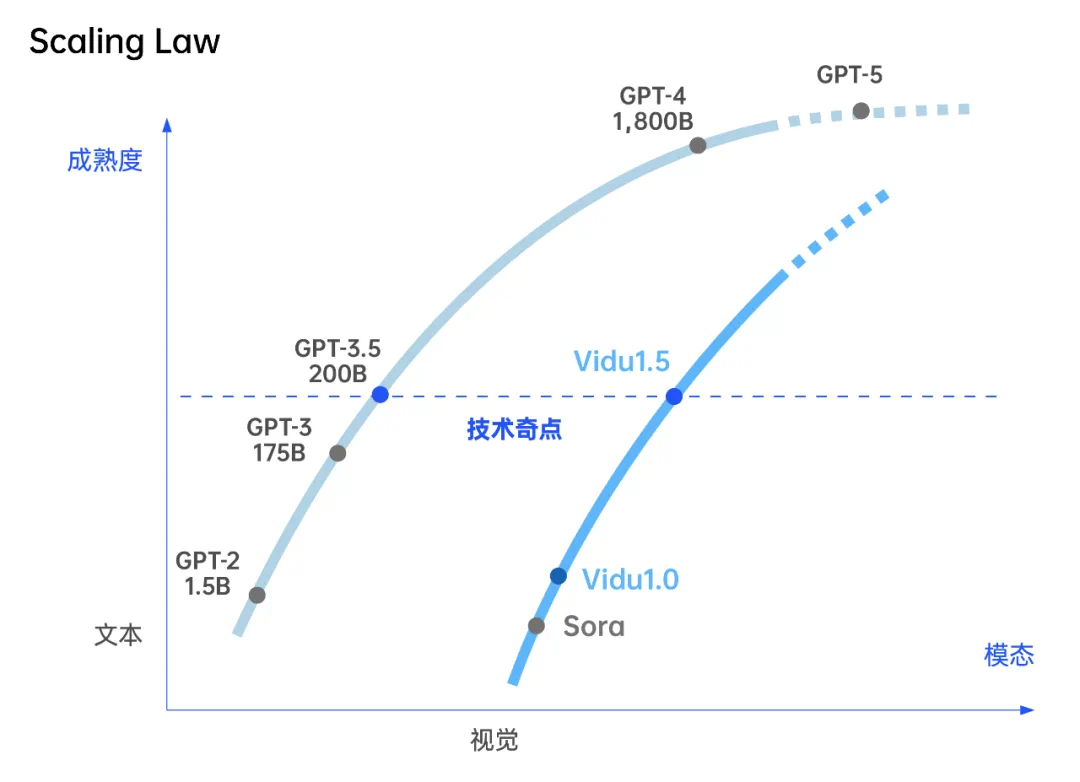
文章来源于互联网:视觉模型学会LLM独门秘籍「上下文记忆」,迎来智能涌现的大爆发!
