文章来源于互联网:精度与通用性不可兼得,北大华为理论证明低精度下scaling law难以实现

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本工作来自北京大学智能学院王立威、贺笛老师课题组与华为诺亚方舟实验室李震国、孙嘉城研究员。作者包括智能学院博士生冯古豪、古云天、罗胜杰;信息科学技术学院本科生杨铠、艾心玥。
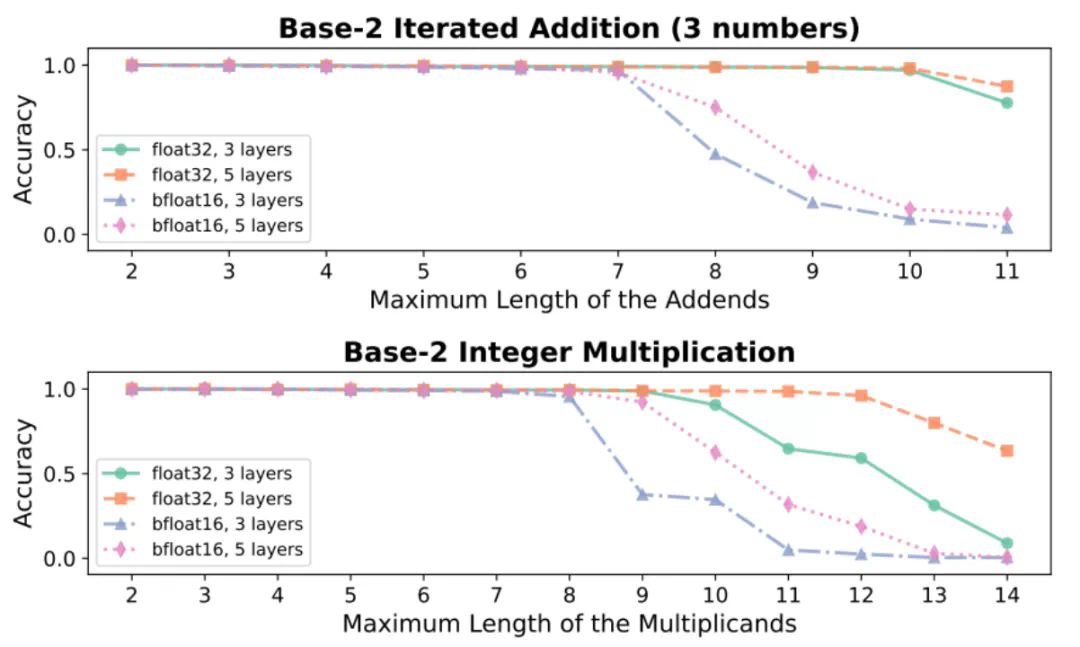
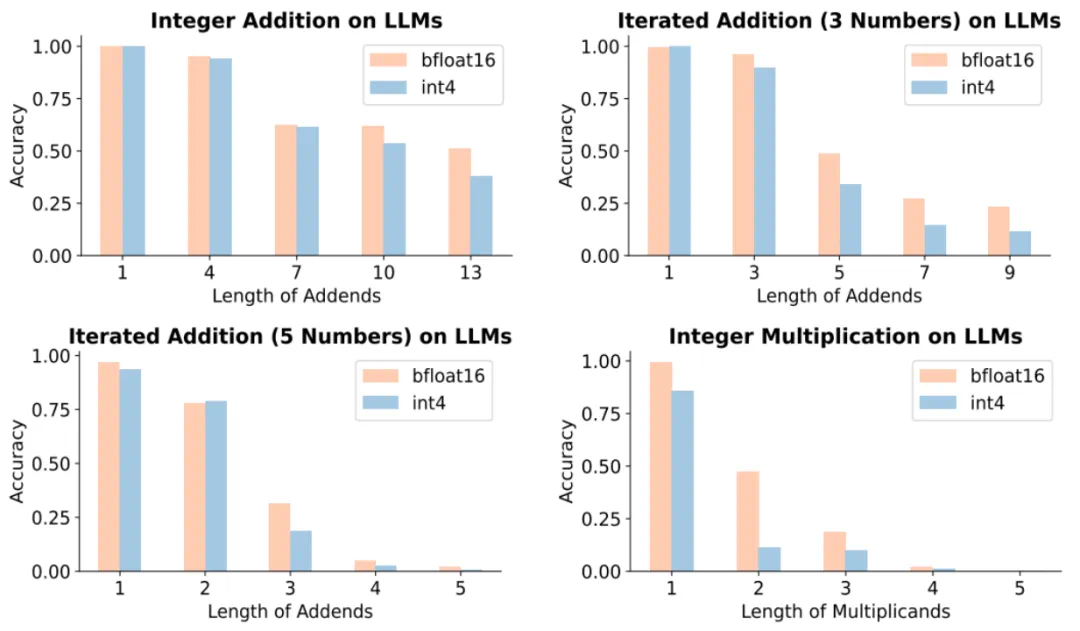
大模型量化通过将模型参数从较高的精度(如 bfoat16)压缩到低精度(如 int8 或 int4)来降低模型推理的开销,提高模型推理的速度。在大语言模型的实际部署中,量化技术能够显著提高大语言模型推理的效率。但近日,来自哈佛大学,MIT,CMU,斯坦福大学和 Databricks 的研究团队通过大量实验总结出了大语言模型关于精度的 Scaling Law,实验发现模型的量化压缩会较大影响大语言模型的性能。
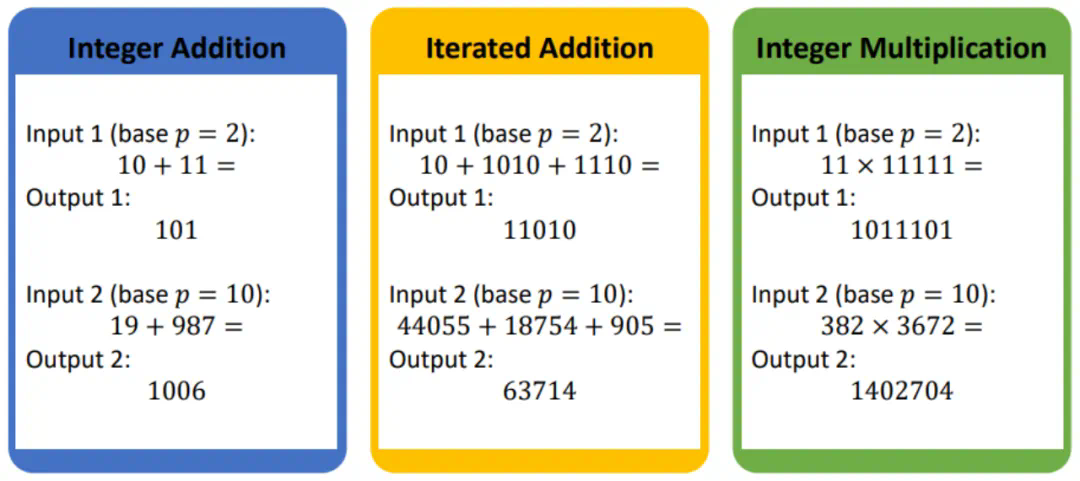
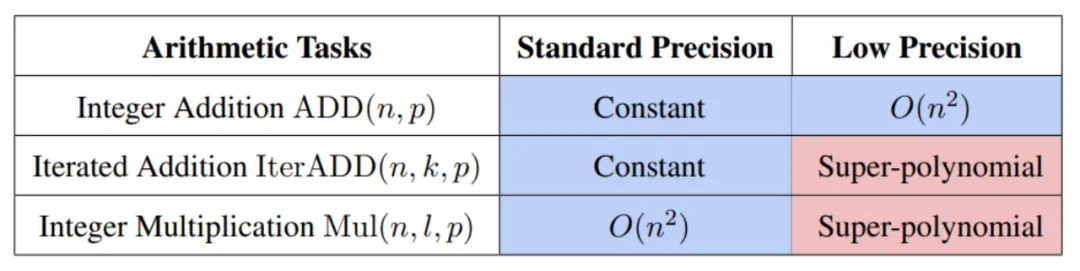
无独有偶,来自北大和华为的研究团队近期则从理论角度研究了量化对于大模型通用性的影响。具体而言,研究者关注了量化对于大模型数学推理能力的影响。其研究理论表明足够的模型精度是大模型解决基本数学任务的重要前提,而量化会大大降低大模型在基本数学任务上的表现,甚至提升足够参数量也无法弥补。