文章来源于互联网:全球十亿级轨迹点驱动,首个轨迹基础大模型来了

-
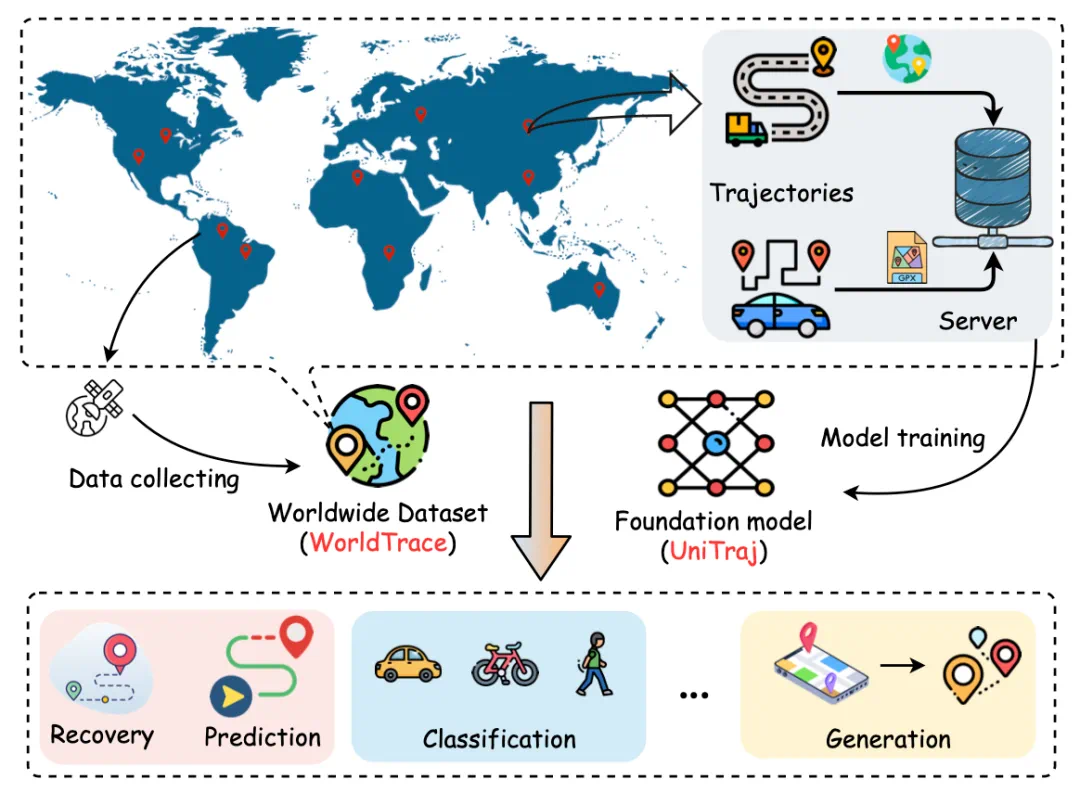
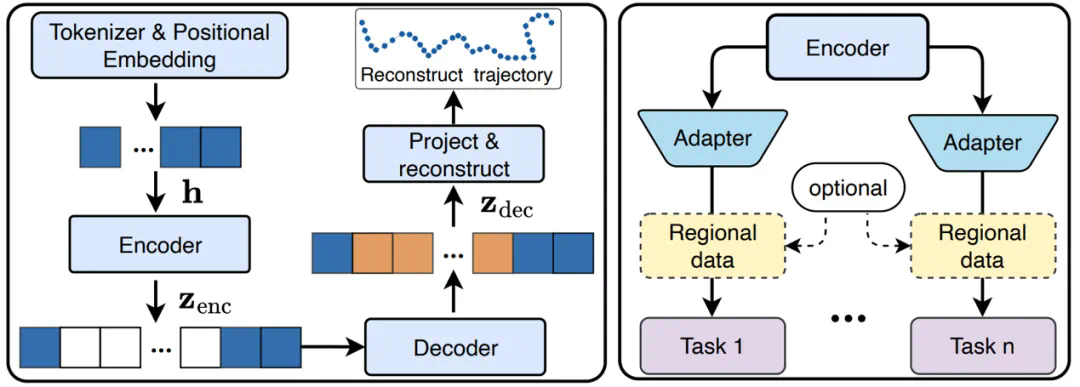
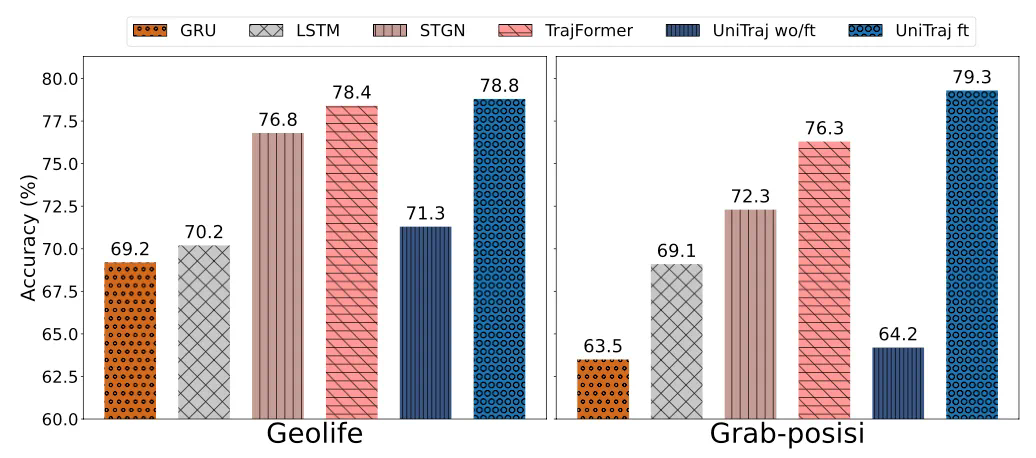
任务特异性:现有方法通常为特定任务设计,缺乏跨任务的灵活性。UniTraj 能够适应不同的应用,无需大量修改。 -
区域依赖性:许多模型在特定地理区域之外效果不佳。UniTraj 通过全球数据训练,减少了对特定区域数据的依赖。 -
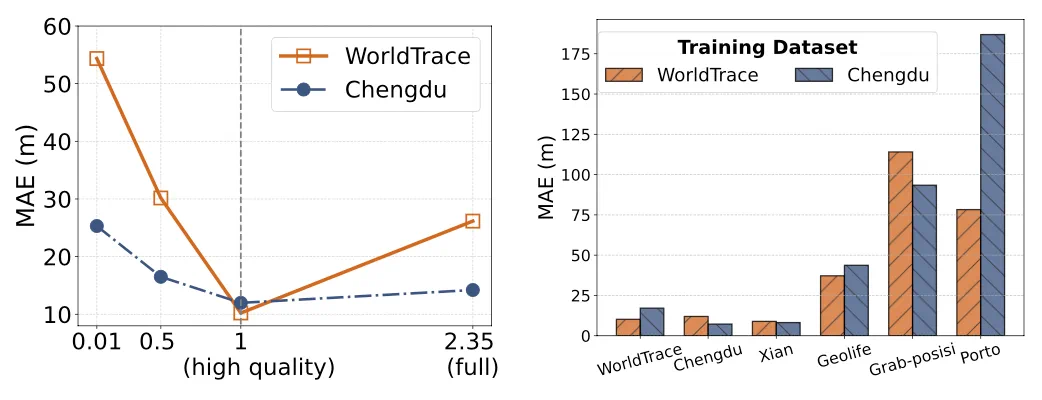
数据质量敏感性:现实世界中的轨迹数据质量参差不齐,现有模型对这些不一致性很敏感。UniTraj 能够有效处理不同质量的轨迹。
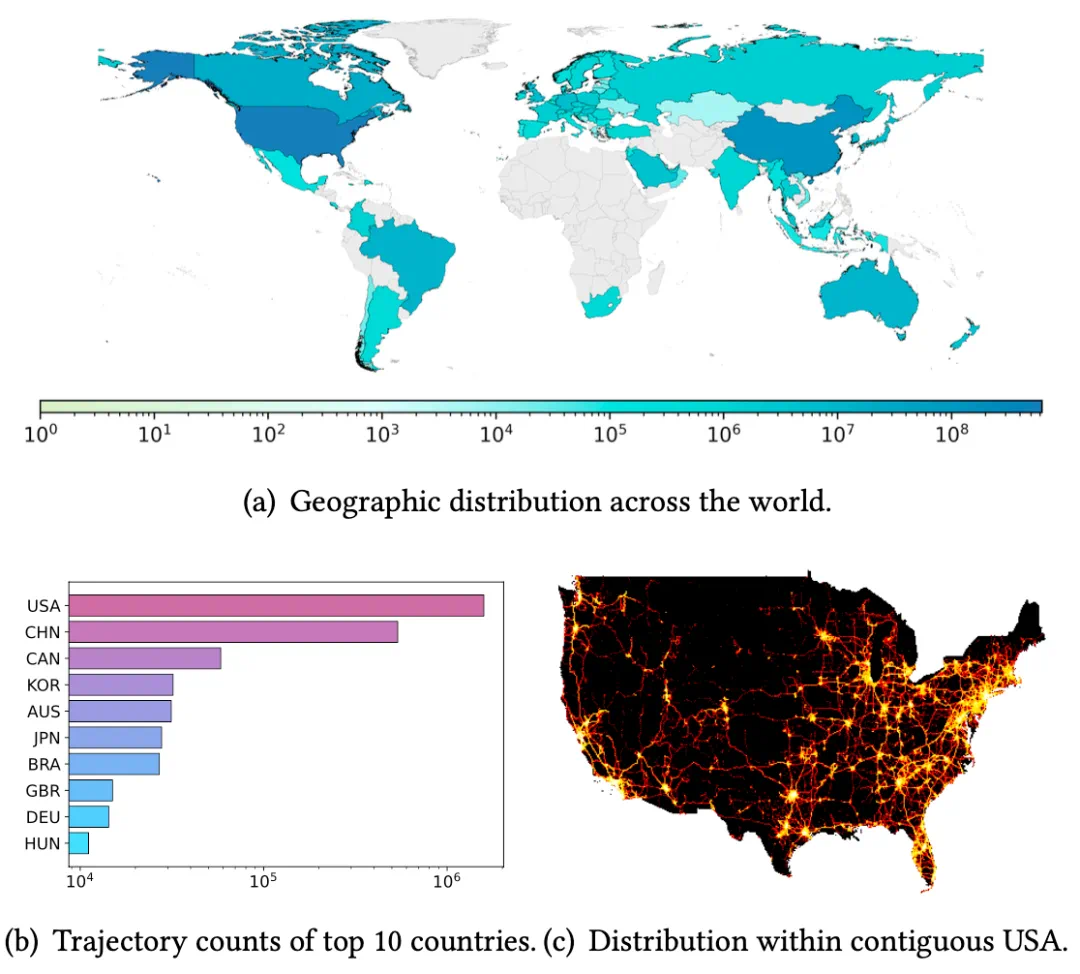
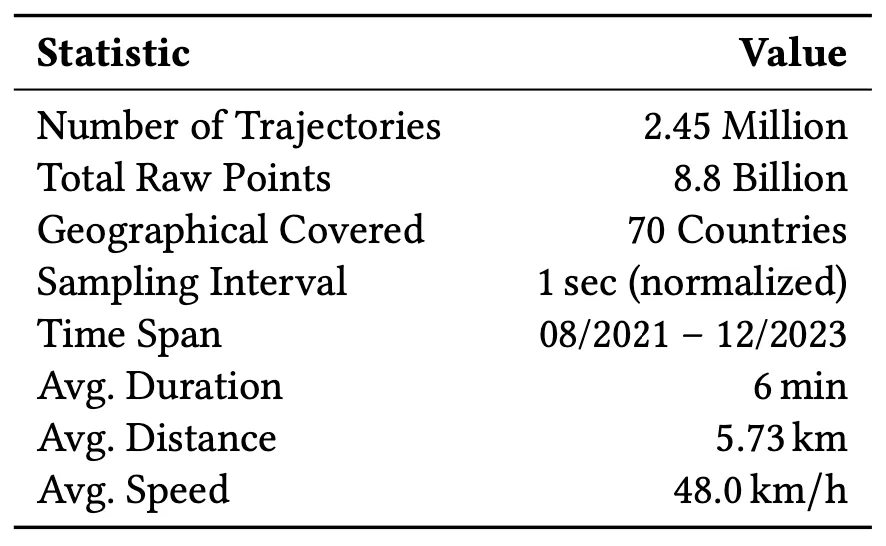
-
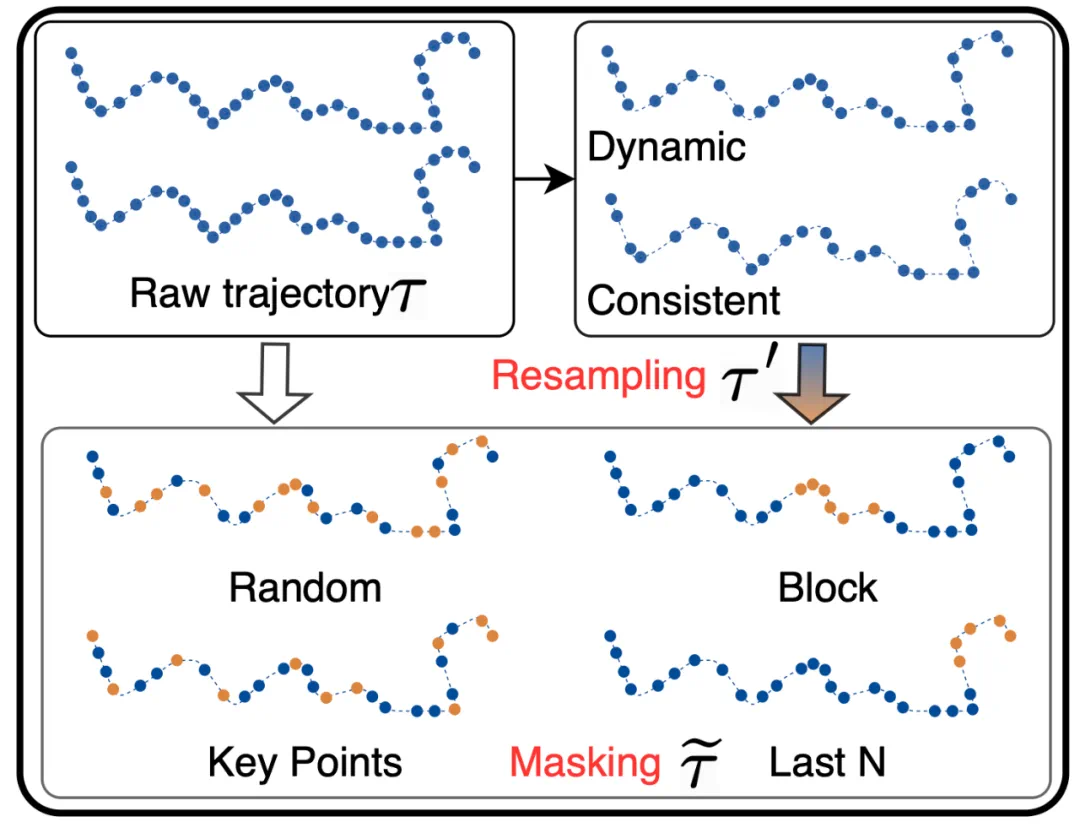
第一种是基于对数采样率衰减的随机动态重采样策略,根据轨迹长度动态调整采样率。动态重采样策略主要应用于解决两个问题,第一是控制数据冗余、减少模型的计算成本;第二是对轨迹数据进行随机重采样,可以得到不同时间间隔的轨迹点,这对增加轨迹数据的多样性至关重要。 -
第二种采样策略是基于轨迹采样频率的间隔一致性重采样策略,其核心思想是将原始轨迹调整为一个随机的固定采样率,以适应不同的设备和场景需要,同时也能够显著降低轨迹点的数量。
-
随机掩码:按照一定的比率,随机掩盖一定数量的轨迹点。随机掩码训练模型捕获一般时空模式,增强其对缺失数据点的鲁棒性。 -
块状掩码:掩盖轨迹内的连续数量点,模拟连续数据段可能缺失的场景。这对于训练模型处理长期依赖或者长距离关系较为有效,使模型重建可能由于传感器故障、低采样率、或暂时通信丢失而发生的缺失段。 -
关键点掩码:关键点掩码关注轨迹中重要的轨迹点(例如转弯或速度或方向明显变化)。这里,作者使用 RDP 算法来识别这些关键点,从而加强了模型对轨迹内关键结构模式的理解。 -
最后点掩码:此策略会屏蔽轨迹的最后 N 个点,模拟未来点不可用且必须从观察到的数据推断的场景。
文章来源于互联网:全球十亿级轨迹点驱动,首个轨迹基础大模型来了

