文章来源于互联网:开源社区参数量最大的文生视频模型来了,腾讯版Sora免费使用

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
想要体验文生视频的小伙伴又多了一个选择!
今日,腾讯宣布旗下的混元视频生成大模型(HunYuan-Video )对外开源,模型参数量 130 亿,可供企业与个人开发者免费使用。目前该模型已上线腾讯元宝 APP,用户可在 AI 应用中的「AI 视频」板块申请试用。
腾讯混元视频生成开源项目相关链接:
-
官网:https://aivideo.hunyuan.tencent.com
-
代码:https://github.com/Tencent/HunyuanVideo -
模型:https://huggingface.co/tencent/HunyuanVideo -
技术报告:https://github.com/Tencent/HunyuanVideo/blob/main/assets/hunyuanvideo.pdf
腾讯混元视频生成模型 HunYuan-Video(HY-Video)是一款突破性的视频生成模型,提供超写实画质质感,能够在真实与虚拟之间自由切换。它打破了小幅度动态图的限制,实现完整大幅度动作的流畅演绎。
HY-Video 具备导演级的运镜效果,具备业界少有的多视角镜头切换主体保持能力,艺术镜头无缝衔接,一镜直出,展现出如梦似幻的视觉叙事。同时,模型在光影反射上遵循物理定律,降低了观众的跳戏感,带来更具沉浸感的观影体验。模型还具备强大的语意遵从能力,用户只需简单的指令即可实现多主体准确的描绘和流畅的创作,激发无限的创意与灵感,充分展现 AI 超写实影像的独特魅力。
总的来说,HunYuan-Video 生成的视频内容具备以下特点:
-
卓越画质:呈现超写实的视觉体验,轻松实现真实与虚拟风格的切换。
-
动态流畅:突破动态图像的局限,完美展现每一个动作的流畅过程。
-
语义遵从:业界首个以多模态大语言模型为文本编码器的视频生成模型,天然具备超高语义理解能力,在处理多主体及属性绑定等生成领域的难点挑战时表现出色。
-
原生镜头转换:多视角镜头切换主体保持能力,艺术镜头无缝衔接,打破传统单一镜头生成形式,达到导演级的无缝镜头切换效果。
AI 文生图开源生态蓬勃发展,众多创作者与开发者为生态贡献作品与插件。然而,视频生成领域的开源模型与闭源模型差距较大。腾讯混元作为第一梯队大模型,将视频生成开源,相当于将闭源模型的最强水平带到开源社区,有望促进视频生成开源生态像图像生成社区一样繁荣。
 腾讯混元视频生成模型提示词:超大水管浪尖,冲浪者在浪尖起跳,完成空中转体。摄影机从海浪内部穿越而出,捕捉阳光透过海水的瞬间。水花在空中形成完美弧线,冲浪板划过水面留下轨迹。最后定格在冲浪者穿越水帘的完美瞬间。
腾讯混元视频生成模型提示词:超大水管浪尖,冲浪者在浪尖起跳,完成空中转体。摄影机从海浪内部穿越而出,捕捉阳光透过海水的瞬间。水花在空中形成完美弧线,冲浪板划过水面留下轨迹。最后定格在冲浪者穿越水帘的完美瞬间。 
 视频由腾讯混元视频生成,提示词:一位中国美女穿着汉服,头发飘扬,背景是伦敦,然后镜头切换到特写镜头
视频由腾讯混元视频生成,提示词:一位中国美女穿着汉服,头发飘扬,背景是伦敦,然后镜头切换到特写镜头 



-
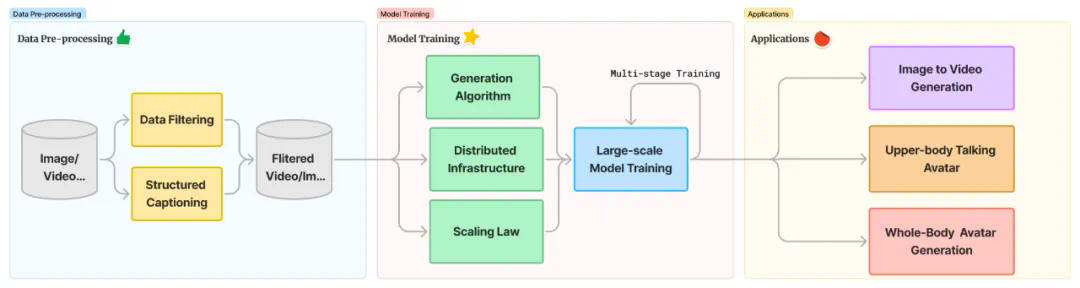
精细的数据处理架构

-
模型架构设计
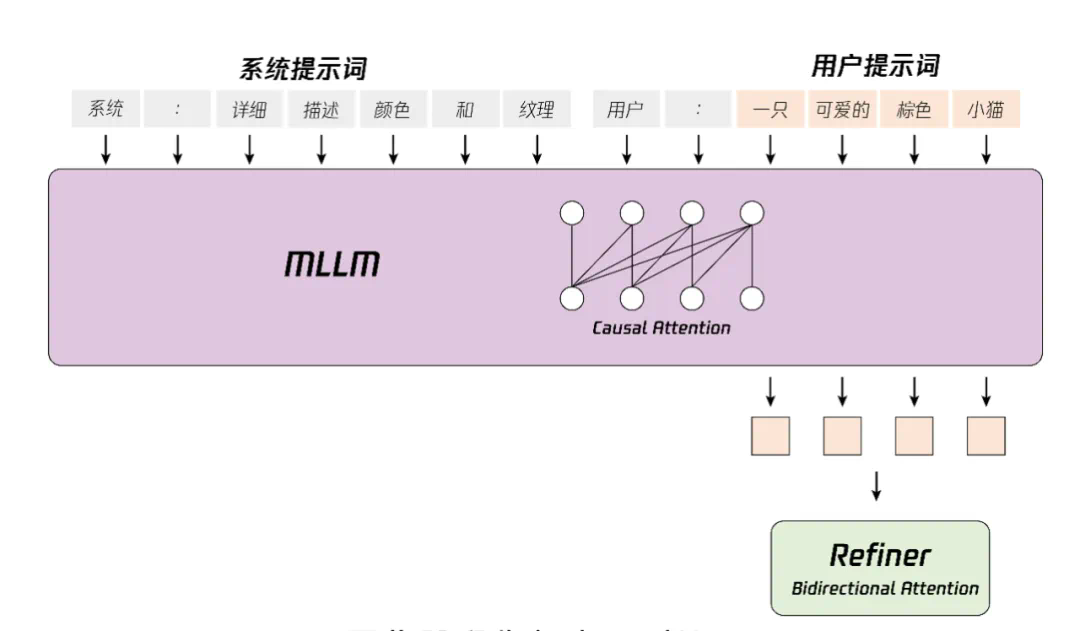
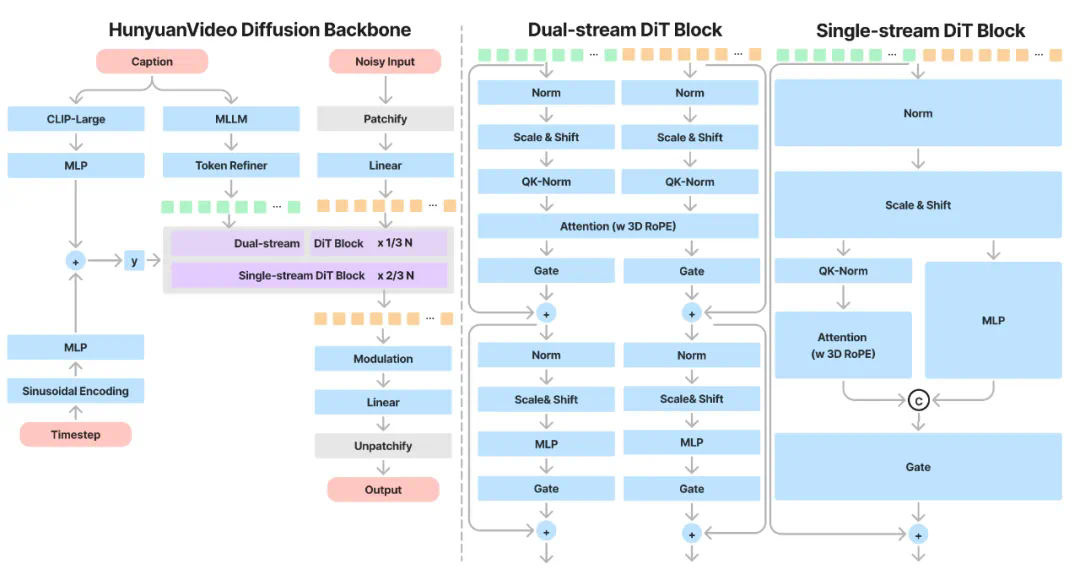
文本到视频等生成任务中,文本编码器在隐式表征空间中提供的指导信息起着关键作用。业界常见模型通常使用预训练的 CLIP 和 T5 作为文本编码器,其中 CLIP 使用 Transformer Encoder,而 T5 使用的是 Encoder-Decoder 结构。相比之下,我们利用最先进的多模态大语言模型(MLLM)进行编码操作,它具有以下优势:
(1)与 T5 相比,MLLM 在视觉指令微调后的表征空间中具有更好的图像 – 文本对齐性,这减轻了扩散模型中指令跟随的难度; (2)与 CLIP 相比,MLLM 在图像细节描述和复杂推理方面有着更加优越的能力;
(3)MLLM 可以通过设计系统指令前置于用户提示来充当零样本学习器,帮助文本特征更加关注关键词。此外,如图 8 所示,MLLM 基于因果注意力,而 T5-XXL 利用双向注意力,为扩散模型产生更好的文本指导。因此,我们遵循的方法,引入了一个额外的双向令牌细化器,以增强文本特征。此外,CLIP 文本特征也是文本信息的摘要。如图所示。我们采用了 CLIP-Large 文本特征的最终非填充令牌作为全局指导,将其整合到双流和单流的 DiT 块中。
—— 腾讯混元视频生成模型开源技术报告
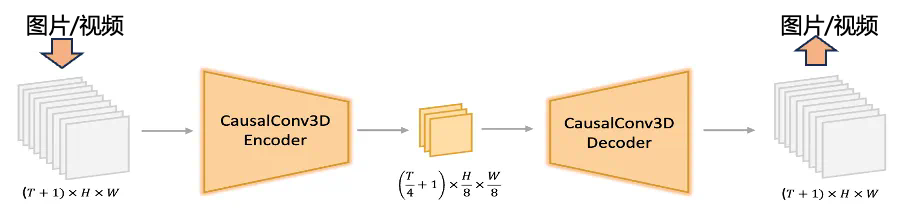
 语音驱动数字人
语音驱动数字人  姿态控制
姿态控制 
文章来源于互联网:开源社区参数量最大的文生视频模型来了,腾讯版Sora免费使用
