文章来源于互联网:关于LLM-as-a-judge范式,终于有综述讲明白了

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本篇综述的作者团队包括亚利桑那州立大学的博士研究生李大卫,蒋博涵,Alimohammad Beigi, 赵成帅,谭箴,Amrita Bhattacharje, 指导老师刘欢教授,来自伊利诺伊大学芝加哥分校的黄良杰,程璐教授,来自马里兰大学巴尔的摩郡分校的江宇轩,来自伊利诺伊理工的陈灿宇,来自加州大学伯克利分校的吴天昊以及来自埃默里大学的舒凯教授。
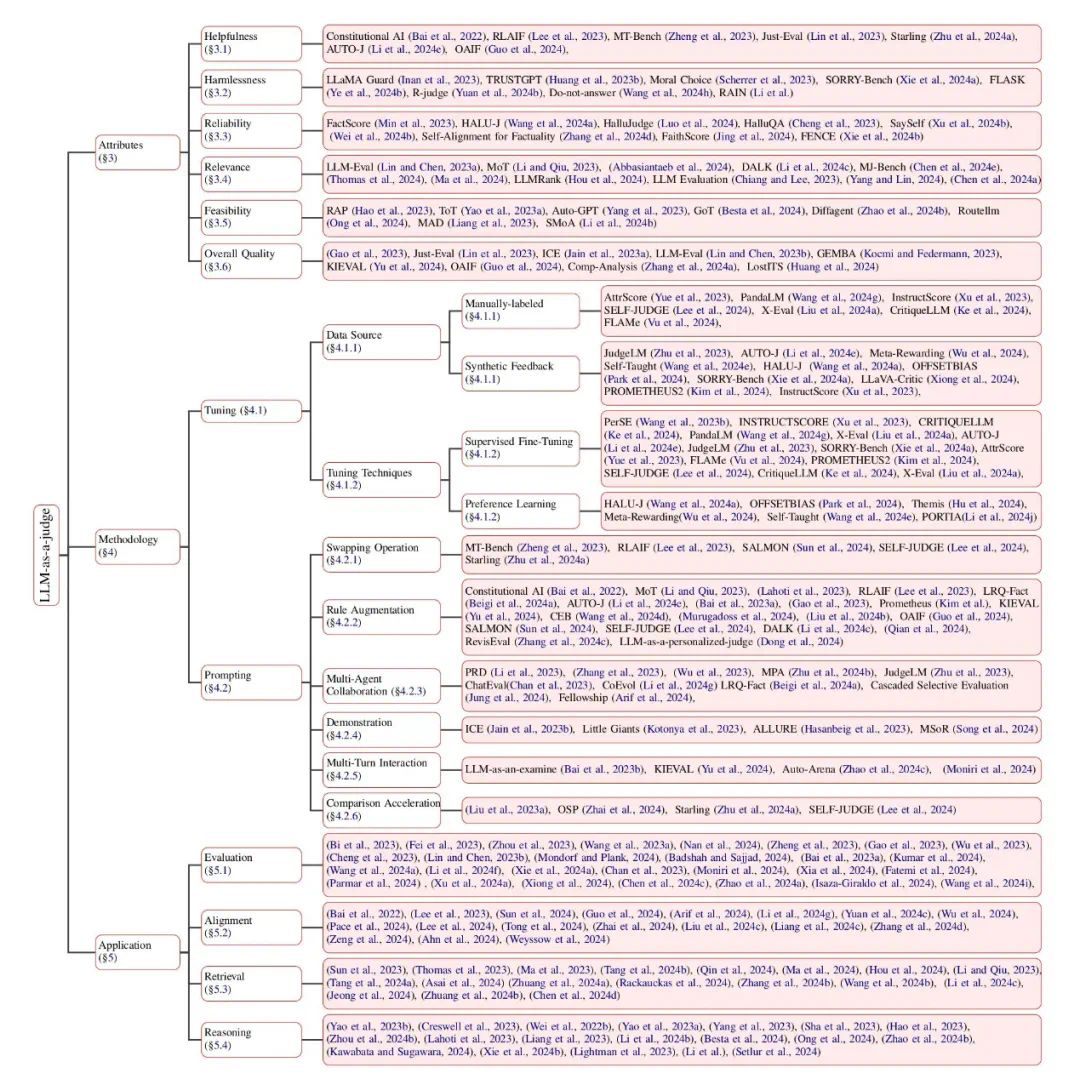
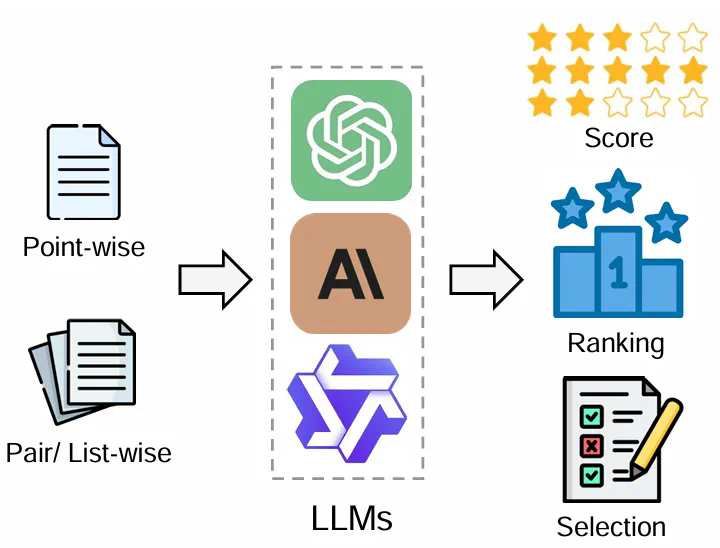
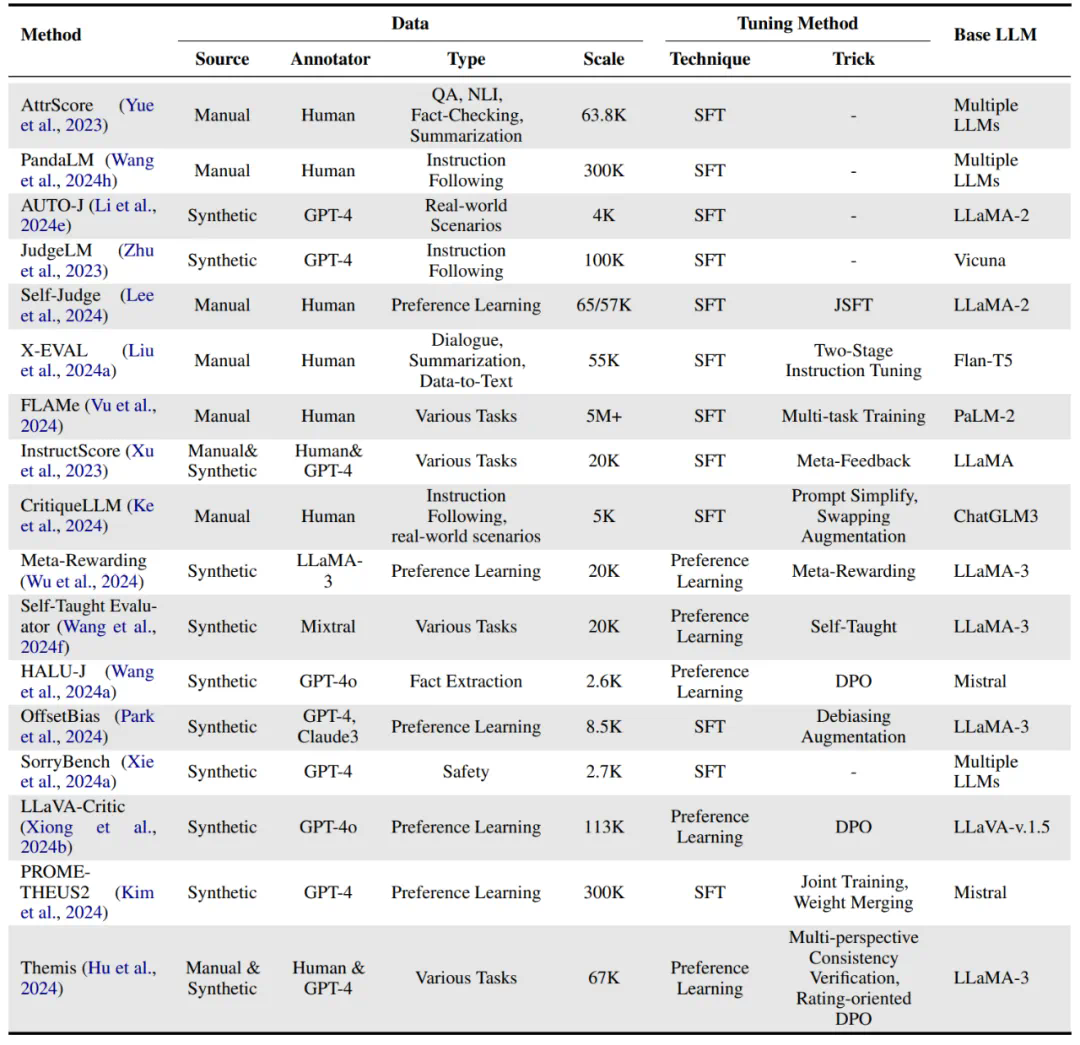
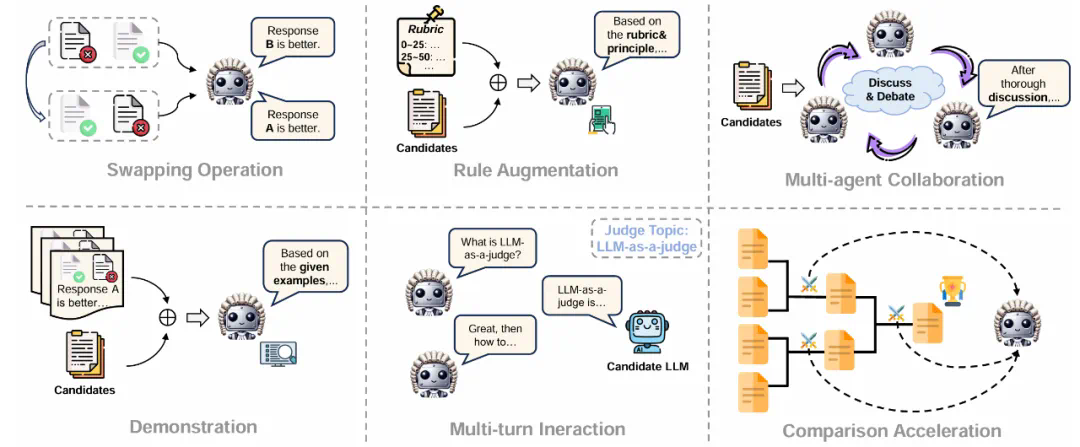
摘要:评估和评价长期以来一直是人工智能 (AI) 和自然语言处理 (NLP) 中的关键挑战。然而,传统方法,无论是基于匹配还是基于词嵌入,往往无法判断精妙的属性并提供令人满意的结果。大型语言模型 (LLM) 的最新进展启发了 “LLM-as-a-judge” 范式,其中 LLM 被用于在各种任务和应用程序中执行评分、排名或选择。本文对基于 LLM 的判断和评估进行了全面的调查,为推动这一新兴领域的发展提供了深入的概述。我们首先从输入和输出的角度给出详细的定义。然后,我们介绍一个全面的分类法,从三个维度探索 LLM-as-a-judge:评判什么(what to judge)、如何评判(how to judge)以及在哪里评判(where to judge)。最后,我们归纳了评估 LLM 作为评判者的基准数据集,并强调了关键挑战和有希望的方向,旨在提供有价值的见解并启发这一有希望的研究领域的未来研究。

-
论文链接:https://arxiv.org/abs/2411.16594 -
网站链接:https://llm-as-a-judge.github.io/ -
论文列表:https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge

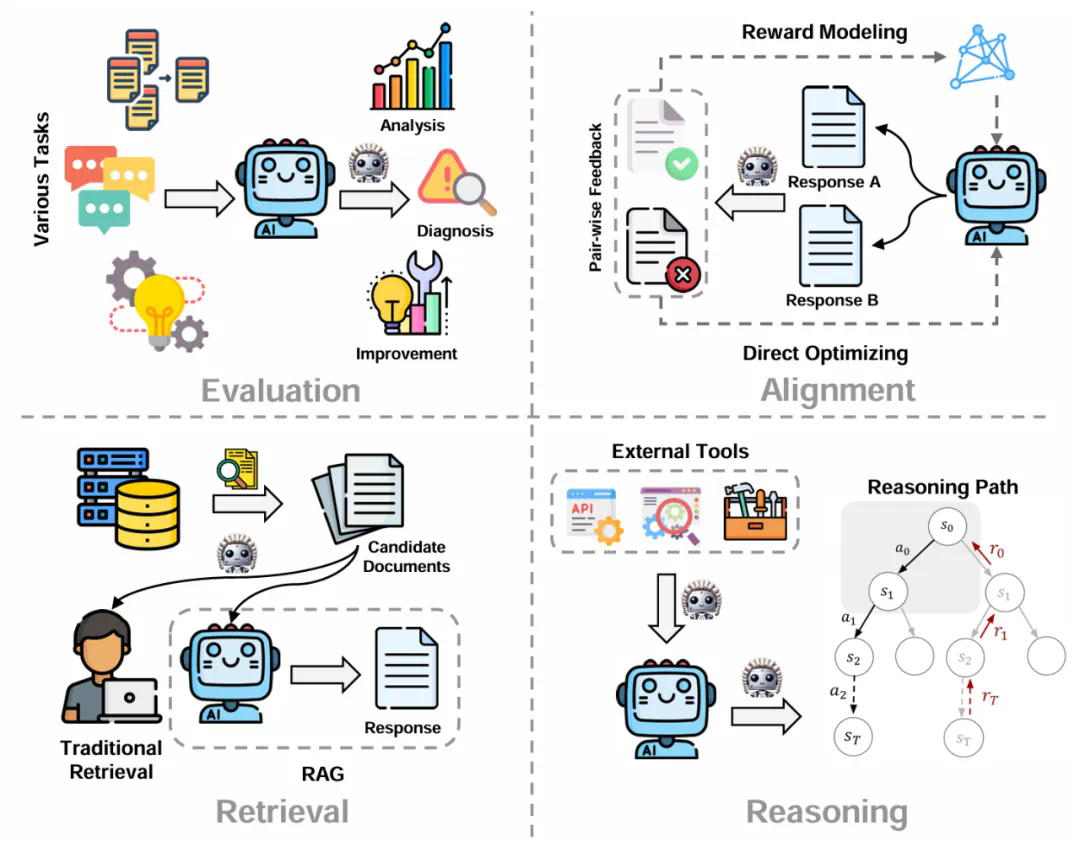
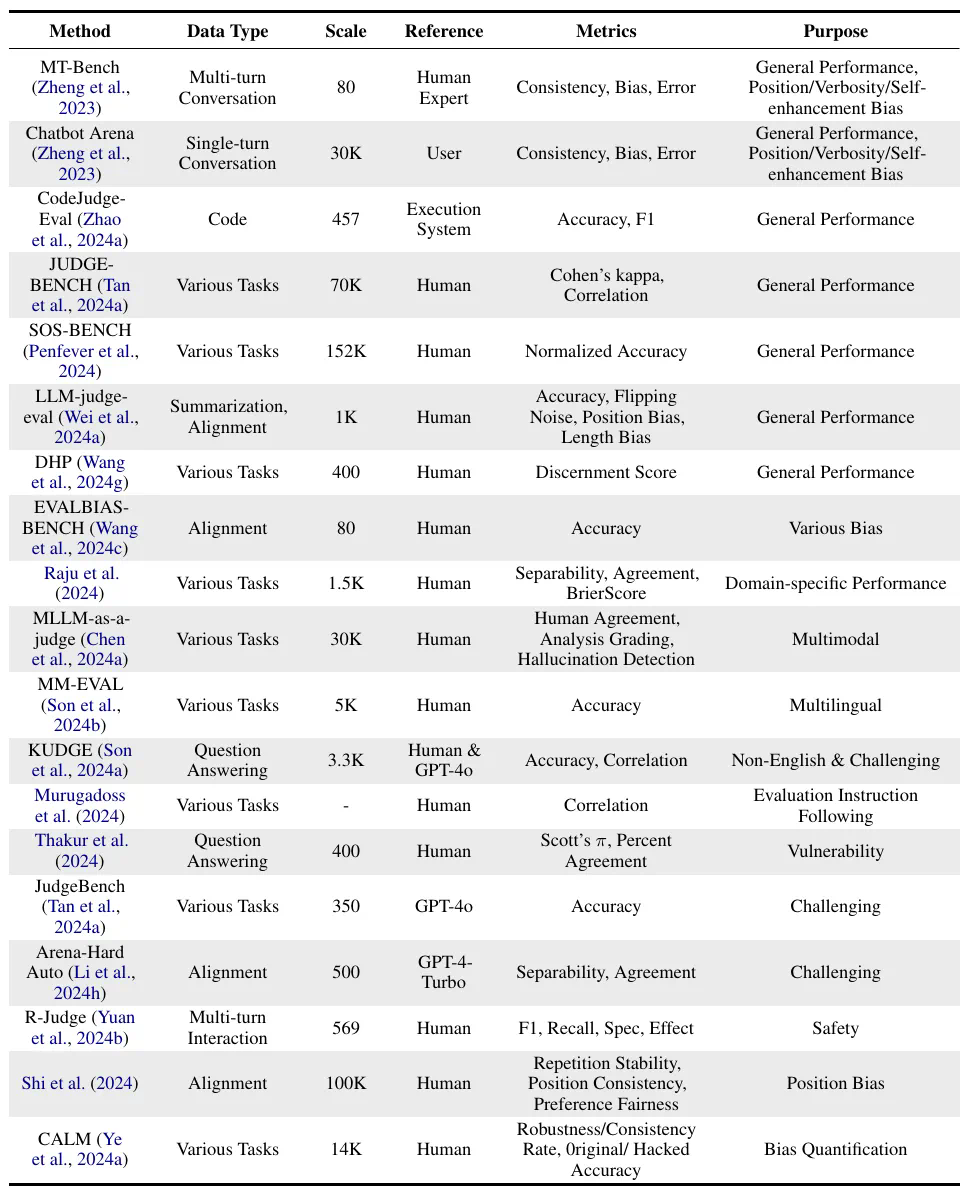
文章来源于互联网:关于LLM-as-a-judge范式,终于有综述讲明白了
