文章来源于互联网:Sora之后,苹果发布视频生成大模型STIV,87亿参数一统T2V、TI2V任务

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
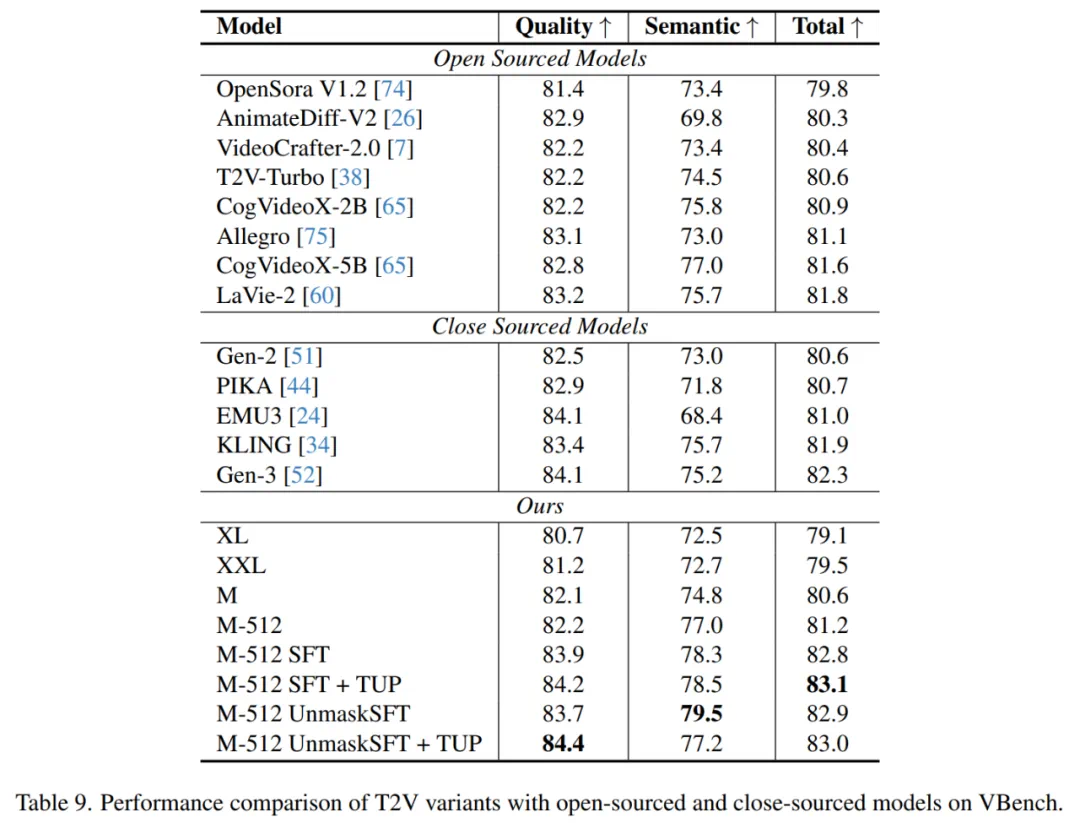
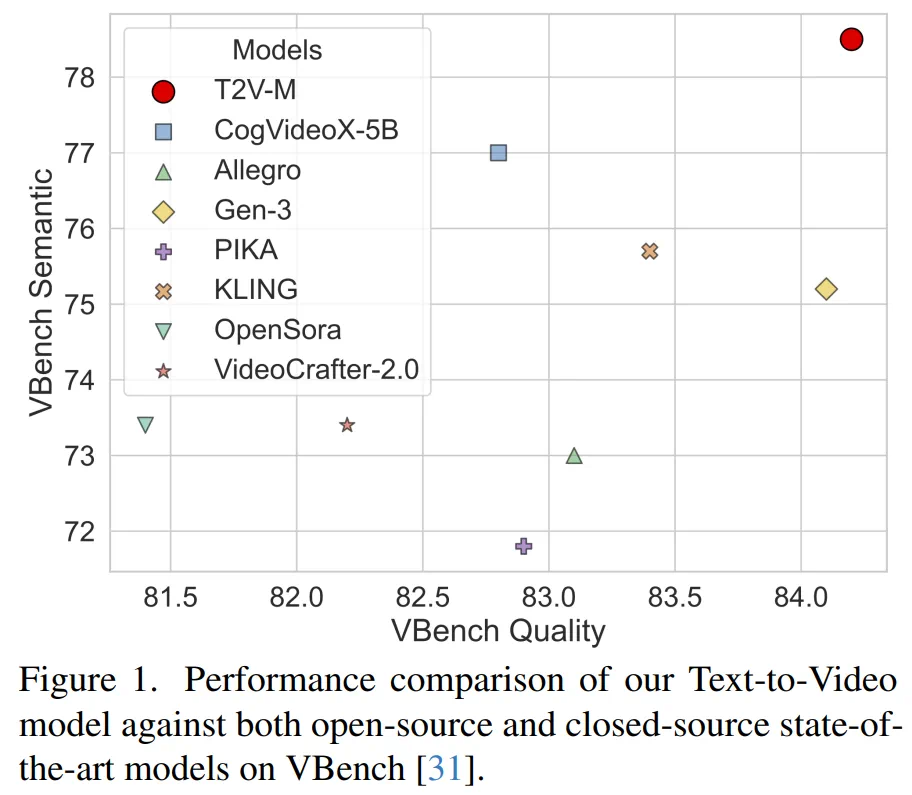
Apple MM1Team 再发新作,这次是苹果视频生成大模型,关于模型架构、训练和数据的全面报告,87 亿参数、支持多模态条件、VBench 超 PIKA,KLING,GEN-3。

-
论文地址: https://arxiv.org/abs/2412.07730 -
Hugging Face link: https://huggingface.co/papers/2412.07730
-
提出 STIV 模型,实现 T2V 和 TI2V 任务的统一处理,并通过 JIT-CFG 显著提升生成质量; -
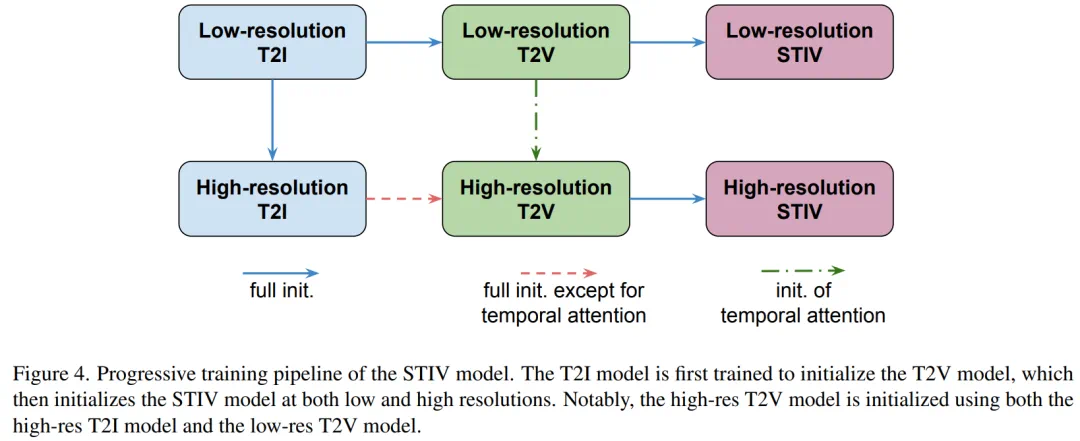
系统性研究包括 T2I、T2V 和 TI2V 模型的架构设计、高效稳定的训练技术,以及渐进式训练策略; -
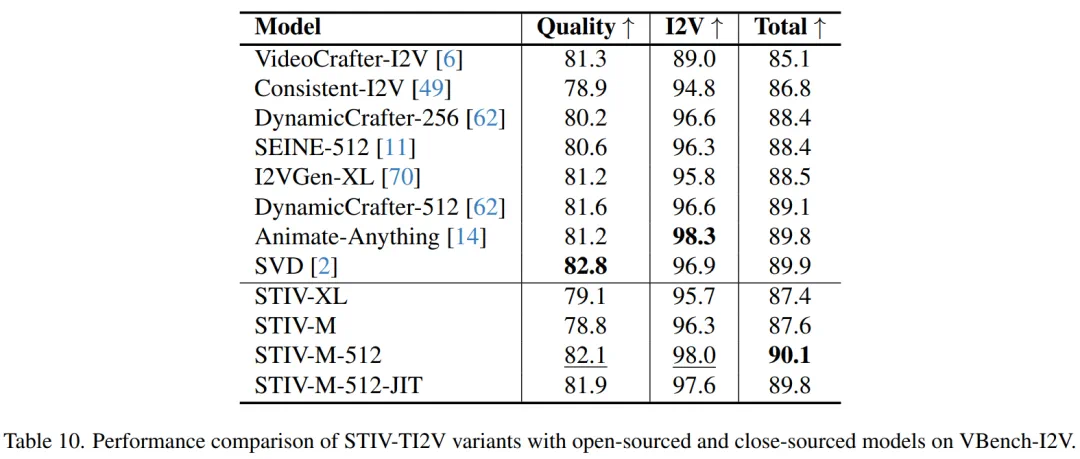
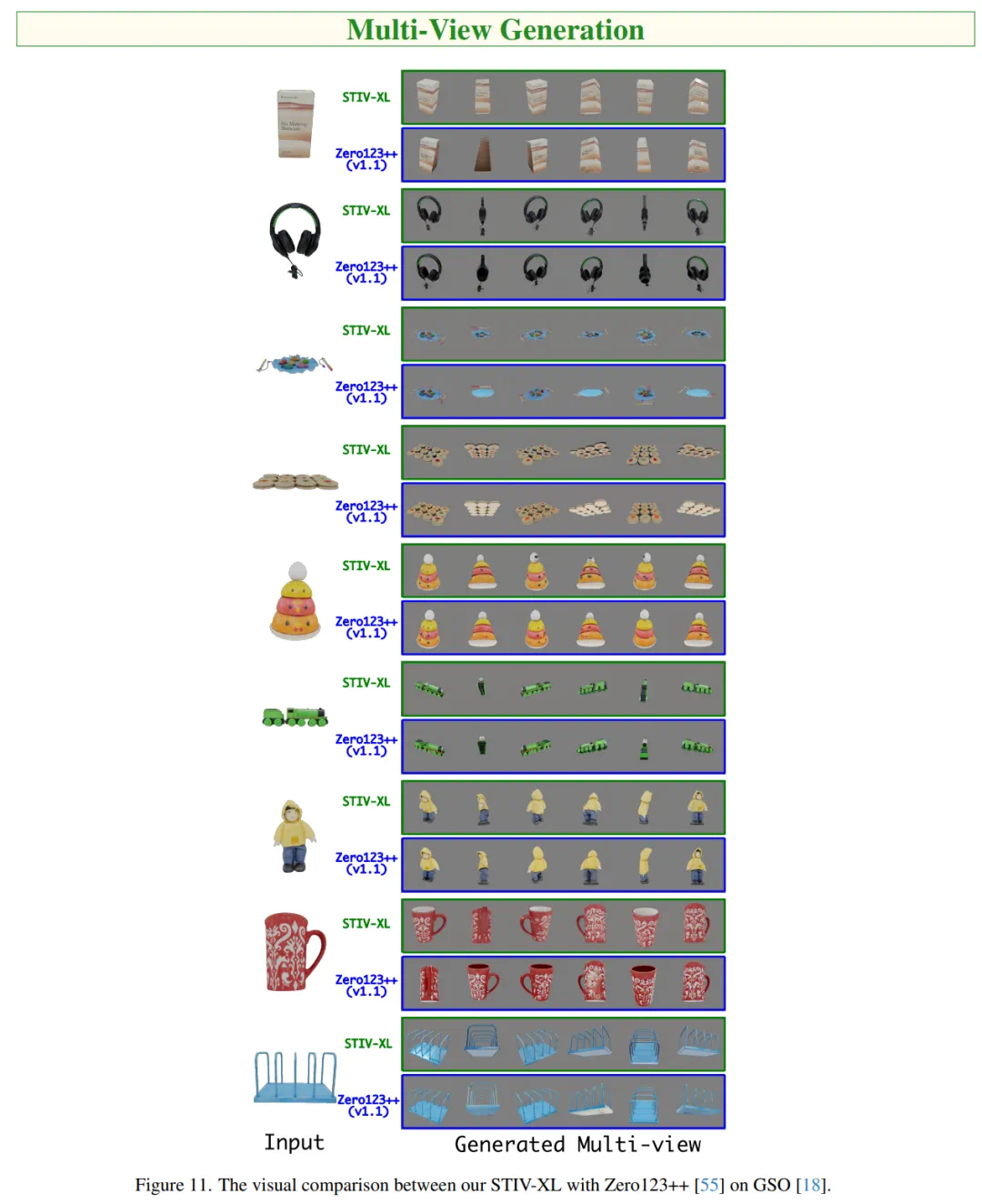
模型易于训练且适配性强,可扩展至视频预测、帧插值和长视频生成等任务; -
实验结果展示了 STIV 在 VBench 基准数据集上的优势,包括详细的消融实验和对比分析。

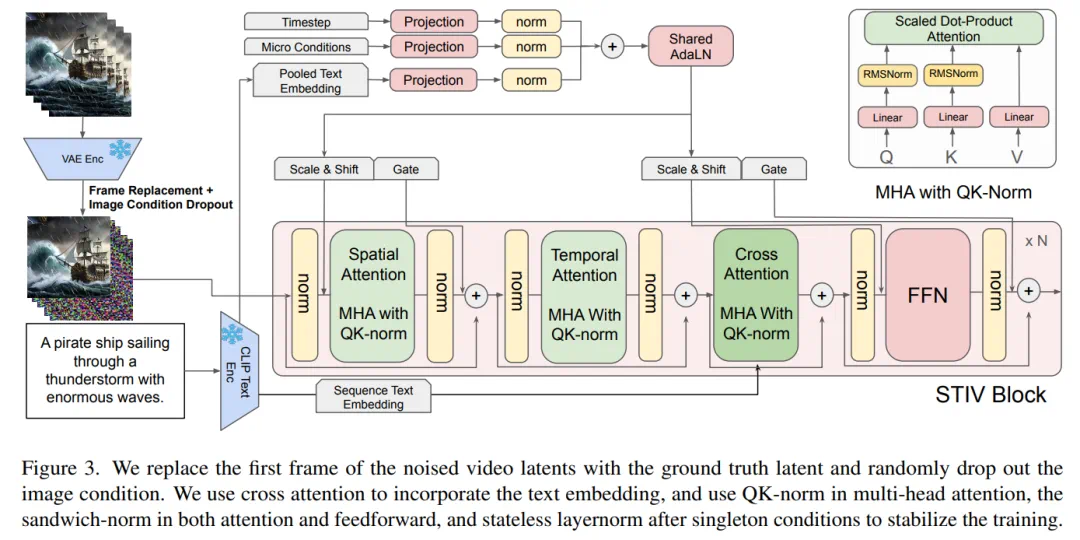
-
时空注意力分解:采用分解的时空注意力机制,分别处理空间和时间维度的特征,这使得模型能够复用 T2I 模型的权重,同时降低了计算复杂度。 -
条件嵌入:通过对图像分辨率、裁剪坐标、采样间隔和帧数等元信息进行嵌入,并结合扩散步长和文本嵌入,生成一个统一的条件向量,应用于注意力层和前馈网络。 -
旋转位置编码(RoPE):利用 RoPE 提升模型处理时空相对关系的能力,适配不同分辨率的生成任务。 -
流匹配目标:采用流匹配(Flow Matching)训练目标,以更优的条件最优传输策略替代传统扩散损失,提升生成质量。
-
稳定训练策略:通过在注意力机制中应用 QK-Norm 和 sandwich-norm,以及对每层的多头注意力(MHA)和前馈网络(FFN)进行归一化,显著提升了模型训练稳定性。 -
高效训练改进:借鉴 MaskDiT 方法,对 50% 的空间 token 进行随机掩码处理以减少计算量,并切换优化器至 AdaFactor,同时使用梯度检查点技术显著降低内存需求,支持更大规模模型的训练。
简单的帧替换方法
在训练过程中,我们将第一个帧的噪声潜变量替换为图像条件的无噪声潜变量,然后将这些潜变量传递到 STIV 模块中,并屏蔽掉被替换帧的损失。在推理阶段,我们在每次 扩散步骤中使用原始图像条件的无噪声潜变量作为第一个帧的潜变量。
帧替换策略为 STIV 的多种应用扩展提供了灵活性。例如,当 c_I (condition of image)=∅ 时,模型默认执行文本到视频(T2V)生成。而当 c_I 为初始帧时,模型则转换为典型的文本-图像到视频(TI2V)生成。此外,如果提供多个帧作为 c_I,即使没有 c_T (condition of text),也可以用于视频预测。同时,如果将首尾帧作为 c_I提供,模型可以学习帧插值,并生成首尾帧之间的中间帧。进一步结合 T2V 和帧插值,还可以生成长时视频:T2V 用于生成关键帧,而帧插值则填补每对连续关键帧之间的中间帧。最终,通过随机选择适当的条件策略,可以训练出一个能够执行所有任务的统一模型。
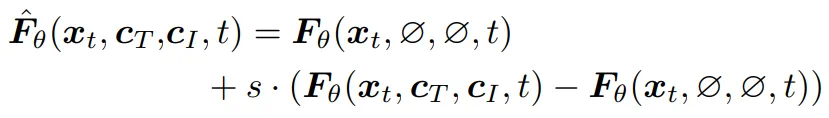
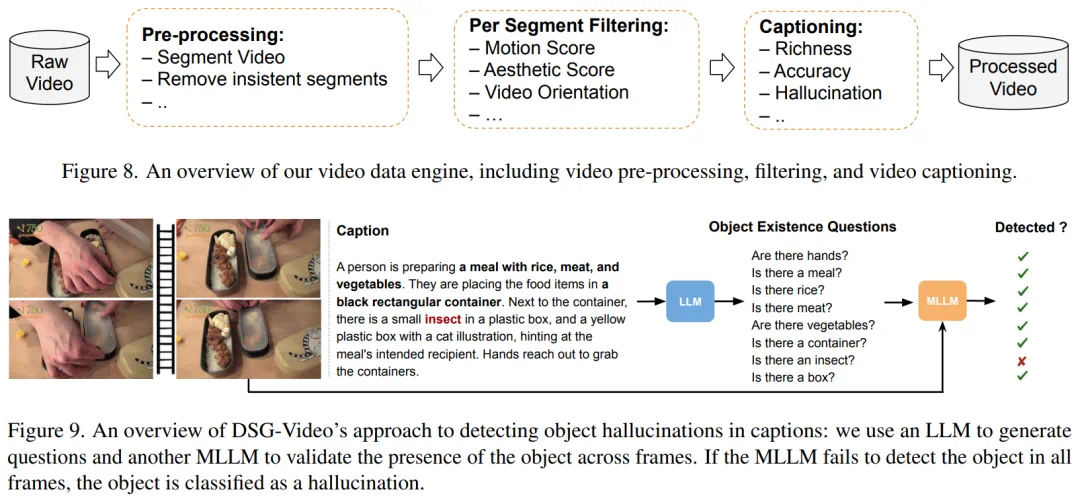
-
DSG-Video_i:虚构对象实例的比例(即提到的所有对象中被检测为虚构的比例); -
DSG-Video_s:包含虚构对象的句子的比例(即所有句子中含虚构对象的比例)。