文章来源于互联网:Florence-VL来了!使用生成式视觉编码器,重新定义多模态大语言模型视觉信息

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文由马里兰大学,微软研究院联合完成。作者包括马里兰大学博士生陈玖海,主要研究方向为语言模型,多模态模型。通讯作者为 Bin Xiao, 主要研究方向为计算机视觉,深度学习和多模态模型。其他作者包括马里兰大学助理教授Tianyi Zhou , 微软研究院研究员 Jianwei Yang , Haiping Wu, Jianfeng Gao 。

-
论文:https://arxiv.org/pdf/2412.04424 -
开源代码:https://github.com/JiuhaiChen/Florence-VL -
项目主页:https://jiuhaichen.github.io/florence-vl.github.io/ -
在线 Demo:https://huggingface.co/spaces/jiuhai/Florence-VL-8B -
模型下载:https://huggingface.co/jiuhai/florence-vl-8b-sft
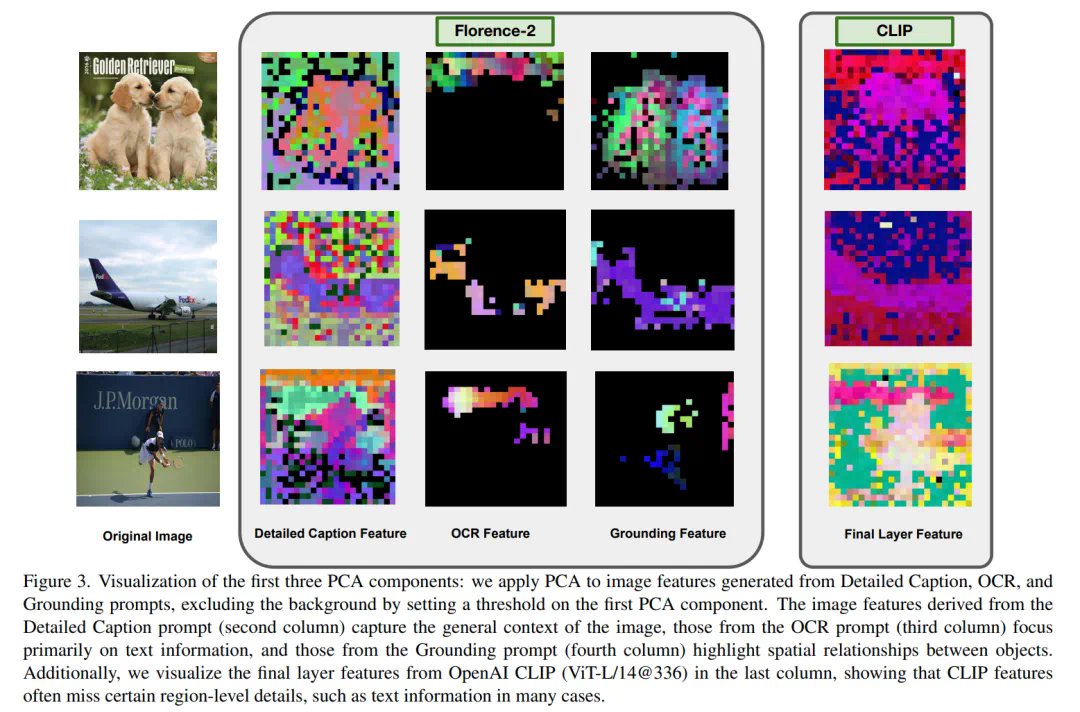
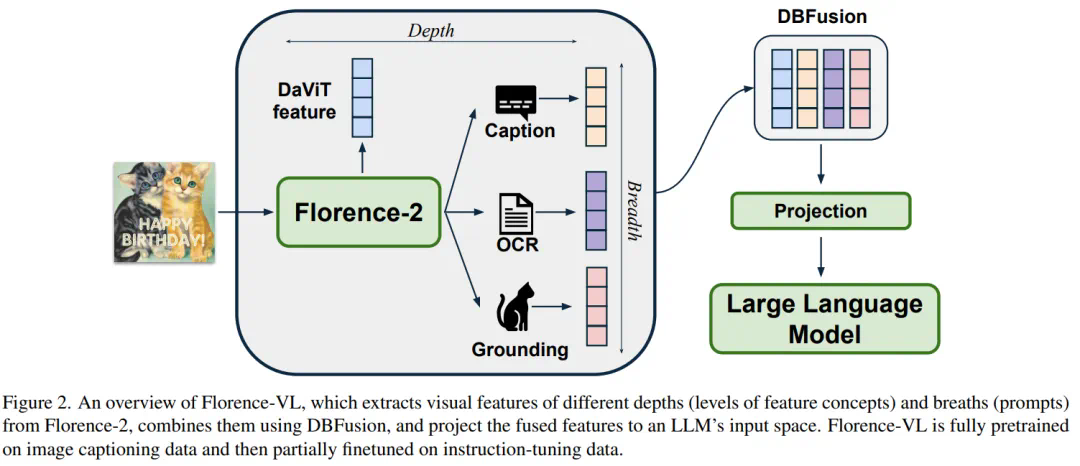
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。 然而 Florence-2 通过生成式预训练,将多种视觉任务(如图像描述、目标检测、文字识别和对象定位)统一为 sequence-to-sequence 结构,并通过 prompt 来完成多样化的视觉任务。在 Florence- VL 中,我们仅使用一个视觉编码器 Florence-2,但采用多个不同的 prompt,分别注重 caption,OCR 和 grounding,来获得不同层次的视觉表征。通过融合这些不同深度的特征,Florence-VL 实现了更全面的视觉理解。

-
缺乏细粒度理解:仅捕获图像的整体语义,忽略像素级和局部区域的细节。 -
任务泛化能力有限:难以适配 OCR、物体定位等需要特定视觉特征的任务。
-
视觉编码器 DaViT:将输入图像转换为基础视觉特征。 -
任务提示机制:通过不同的文本提示调整生成目标,从而提取任务特定的视觉信息。 -
编码 – 解码框架:结合视觉和文本特征,输出满足不同任务需求的结果。
-
Captioning:用于理解图像整体语义,生成描述性文本。 -
OCR:提取图像中的文本内容,尤其适用于带有文字的图像。 -
Grounding:用于定位物体,捕捉物体之间的关系。
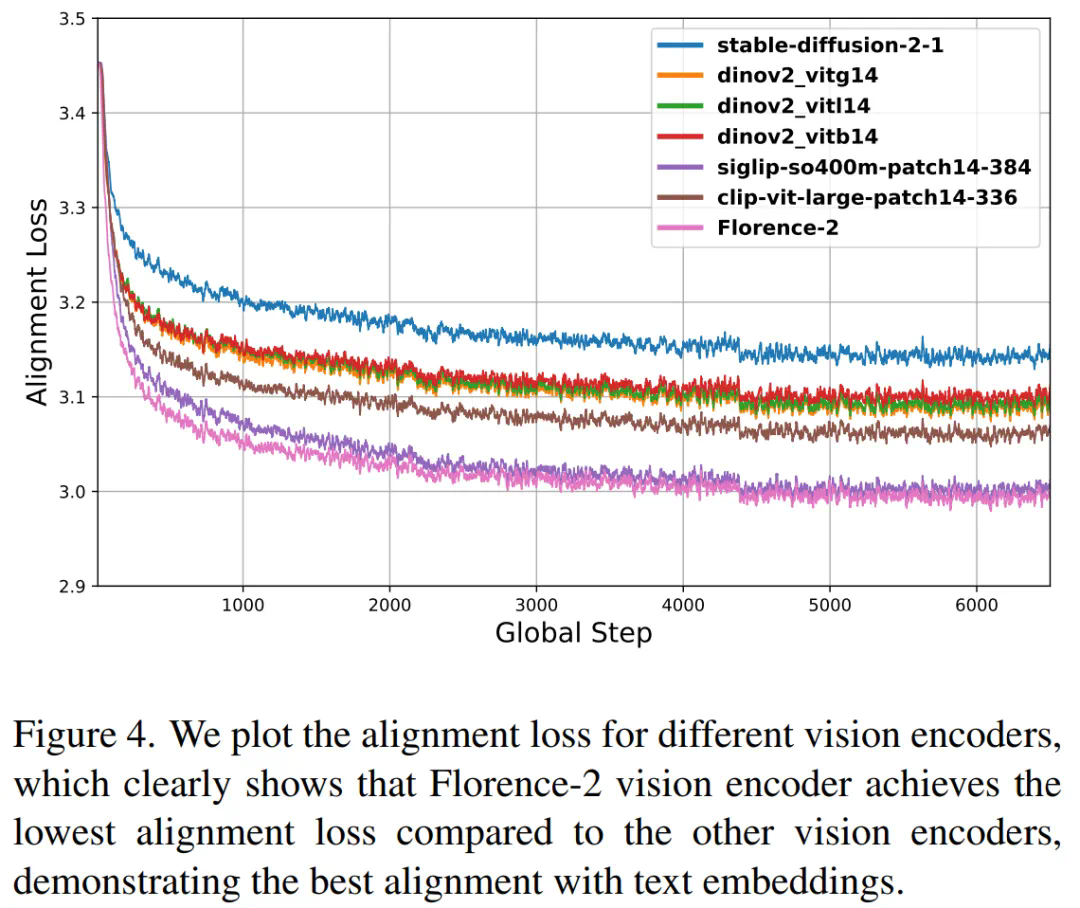
-
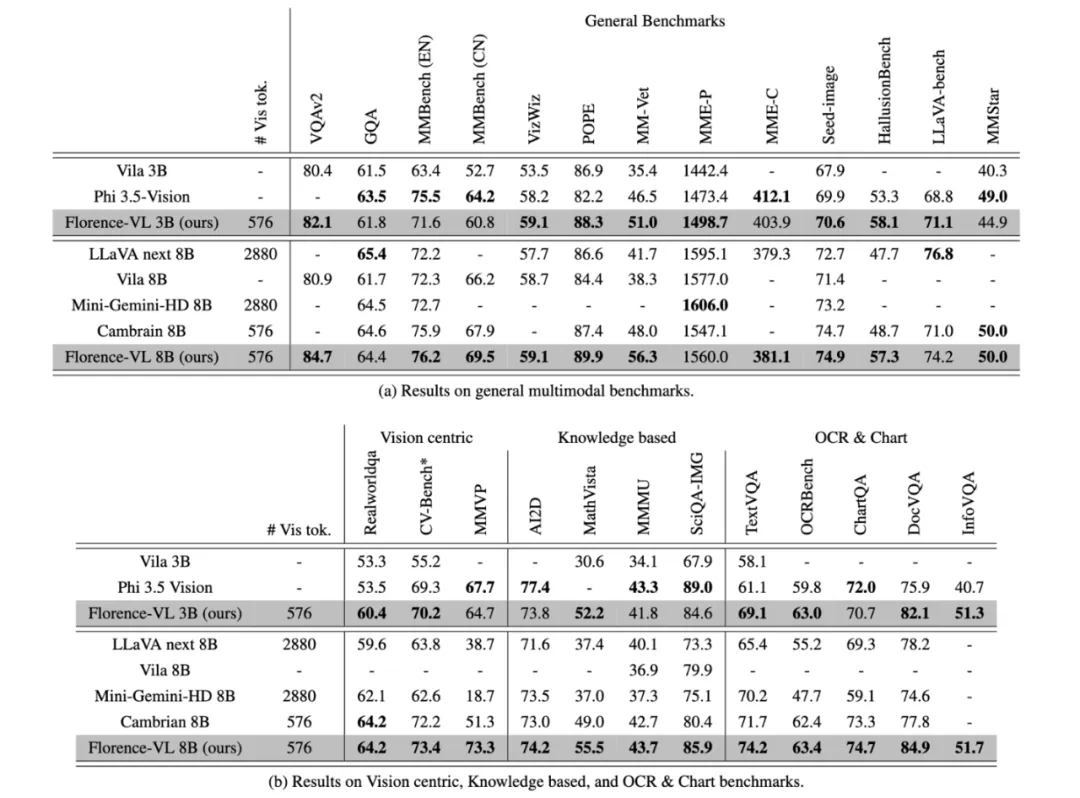
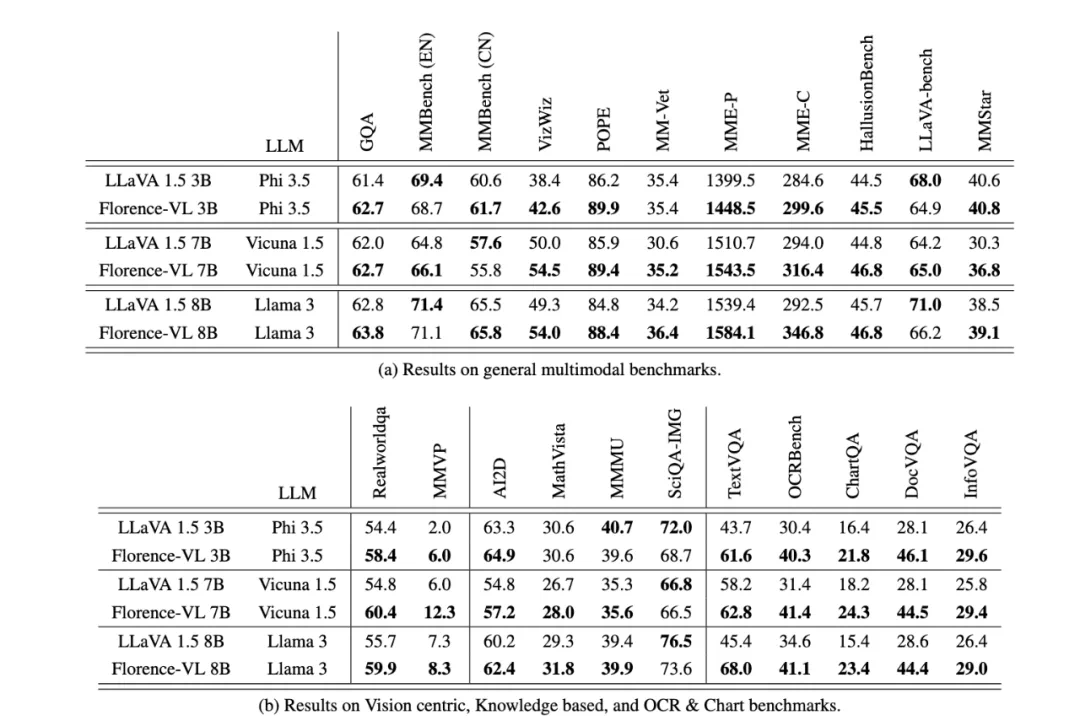
通用视觉问答:如 VQAv2、GQA 等。 -
OCR 与图表任务:如 TextVQA 和 ChartQA,侧重文本提取与图表分析。 -
视觉主导任务:如 CV-bench 和 MMVP, 侧重视觉信息理解。 -
知识密集型任务:如 AI2D、MathVista 等,测试模型对基本知识的理解能力。