文章来源于互联网:统一视觉理解与生成,MetaMorph模型问世,LeCun、谢赛宁、刘壮等参与
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。
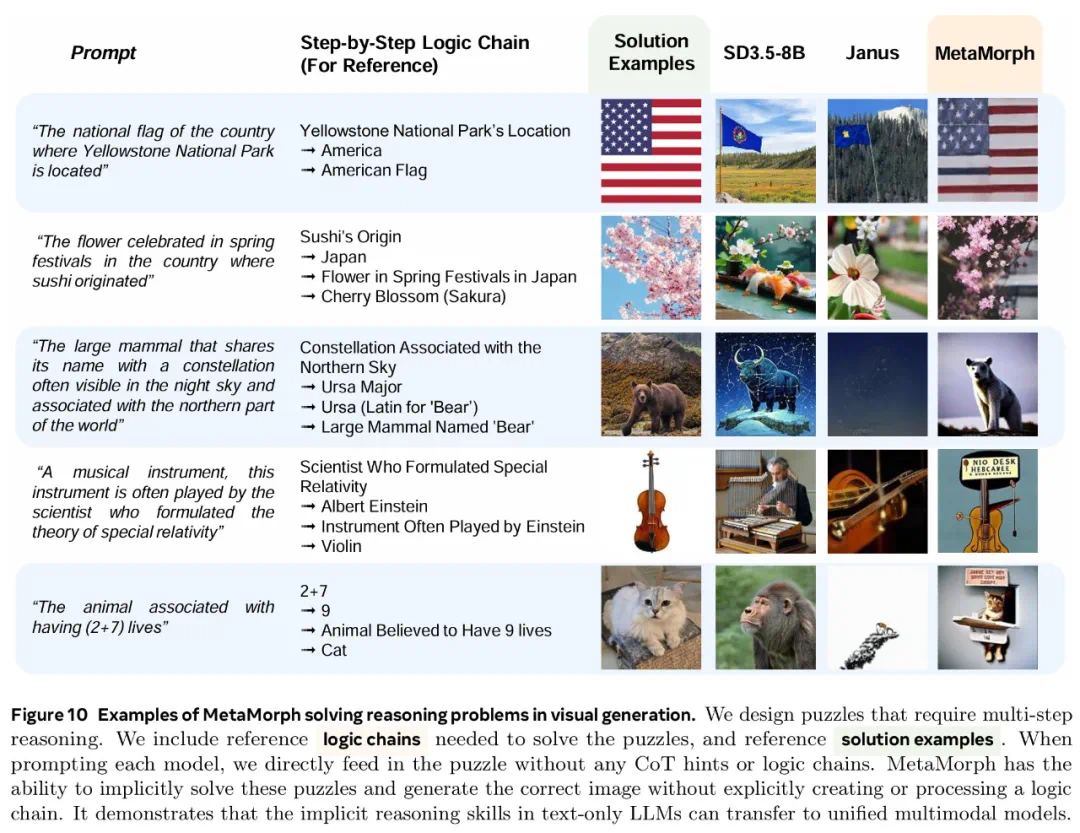
在 Meta 和纽约大学合作的一篇论文中,研究者探究了 LLM 是否也可以通过微调来生成具有同等效率和有效性的视觉信息?论文作者中包括了 AI 领域的几位知名学者,包括图灵奖得主 Yann LeCun、纽约大学计算机科学助理教授谢赛宁、FAIR 研究科学家刘壮(将于明年 9 月加盟普林斯顿大学,担任计算机科学系助理教授)。

-
论文标题:MetaMorph: Multimodal Understanding and Generation via Instruction Tuning -
论文地址:https://arxiv.org/pdf/2412.14164v1 -
项目地址:https://tsb0601.github.io/metamorph/

-
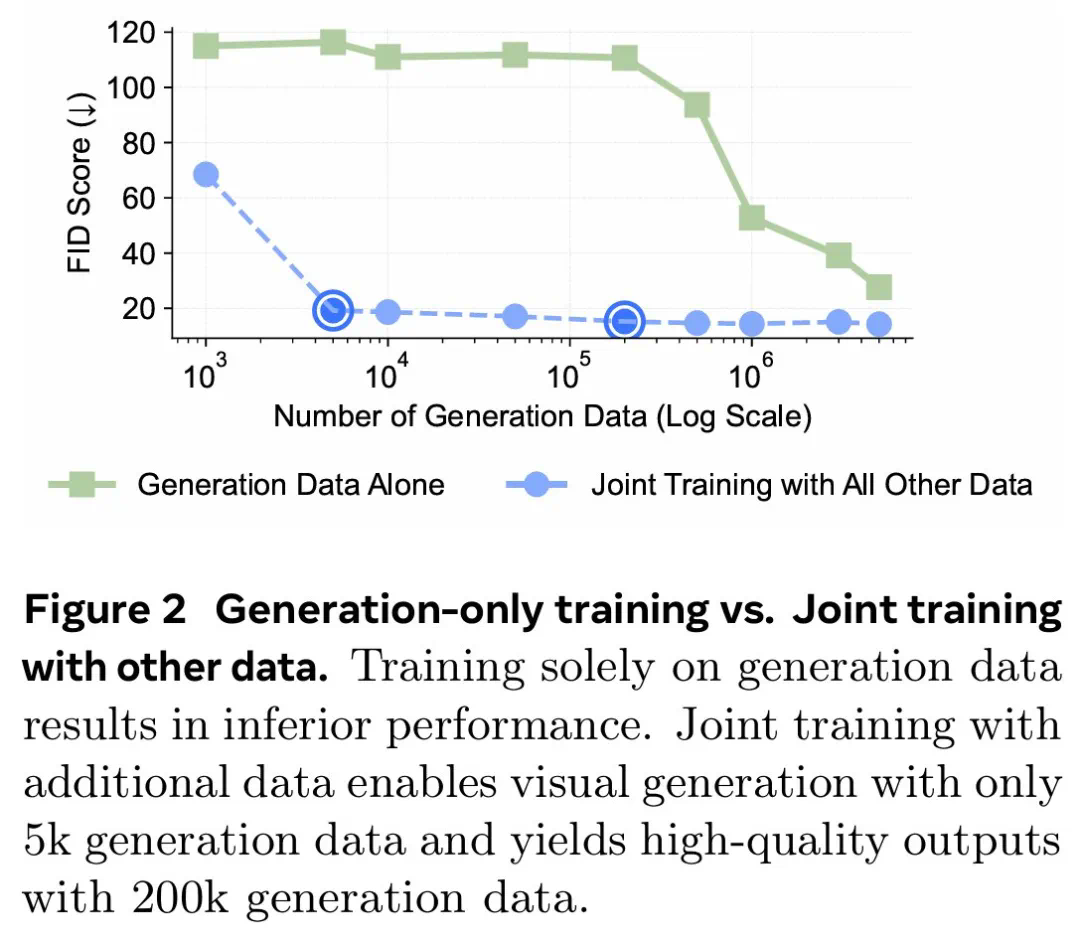
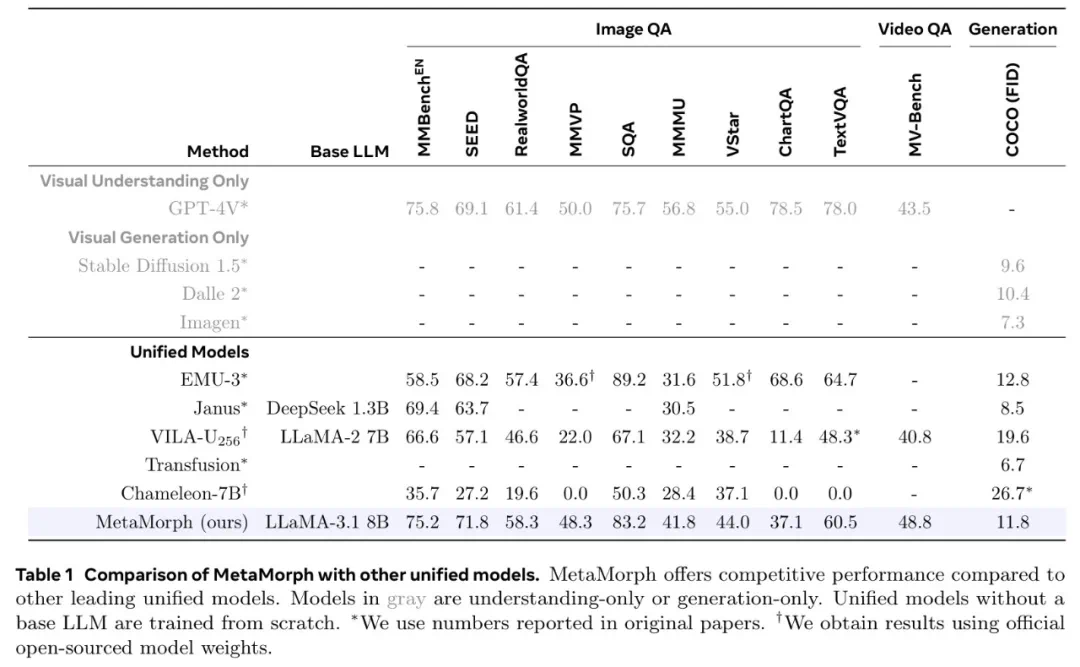
使用指令调整来训练统一模型是可行的。 -
LLM 具有强大的预先存在的视觉功能,与广泛的预训练相比,这些功能可以使用少得多的样本来激活。
-
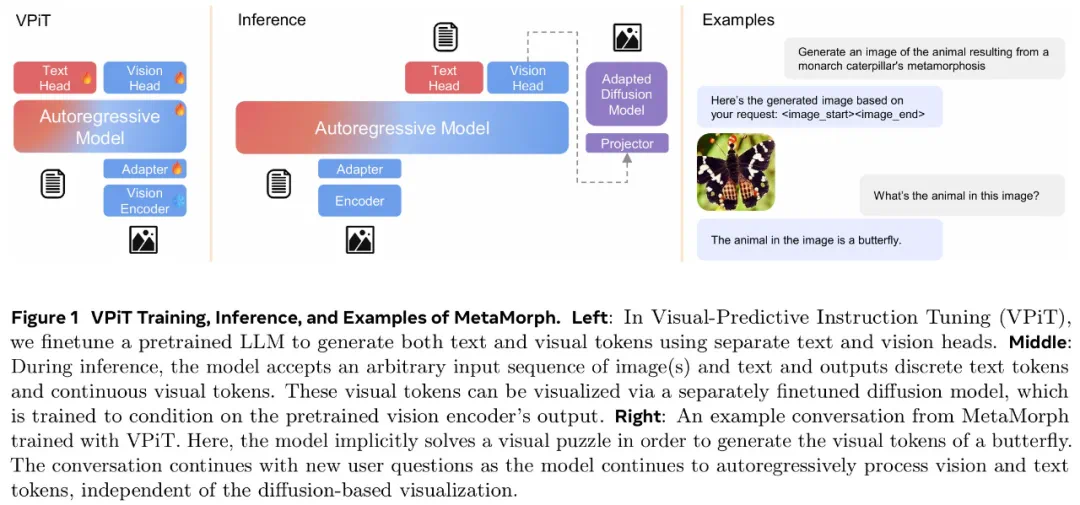
视觉理解数据:包括以图像或视频作为输入并输出文本响应的数据。 -
视觉生成数据:MetaCLIP 数据,根据图像描述预测视觉 token。研究者最多使用 500 万对,并将数据整理成问答格式。 -
其他视觉数据:包括需要模型根据「交错输入的视觉 token 和文本 token」来预测视觉 token 的数据。
-
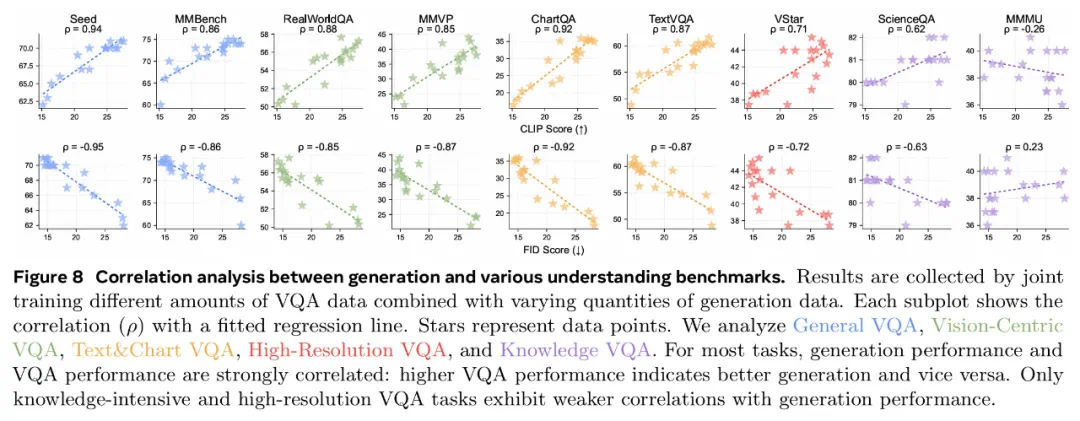
视觉生成可以通过轻量级调整来解锁吗?还是需要大量数据?视觉理解和生成是互惠互利还是相互对立? -
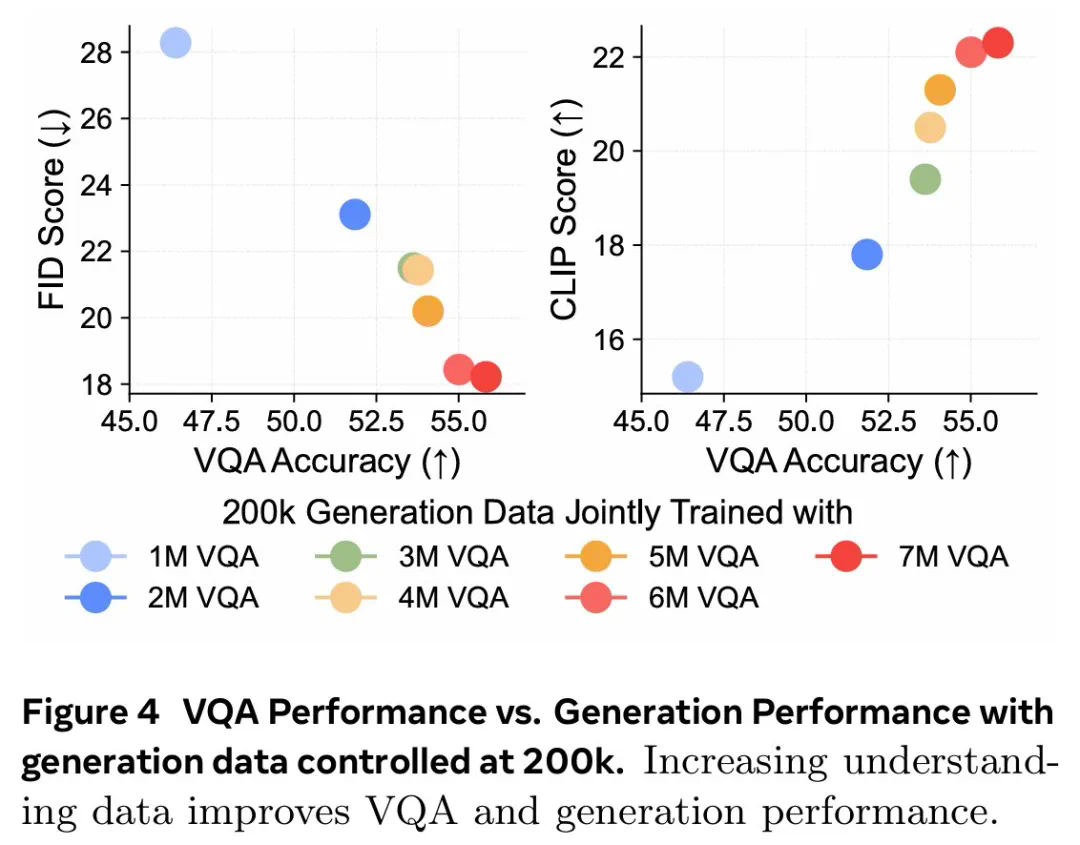
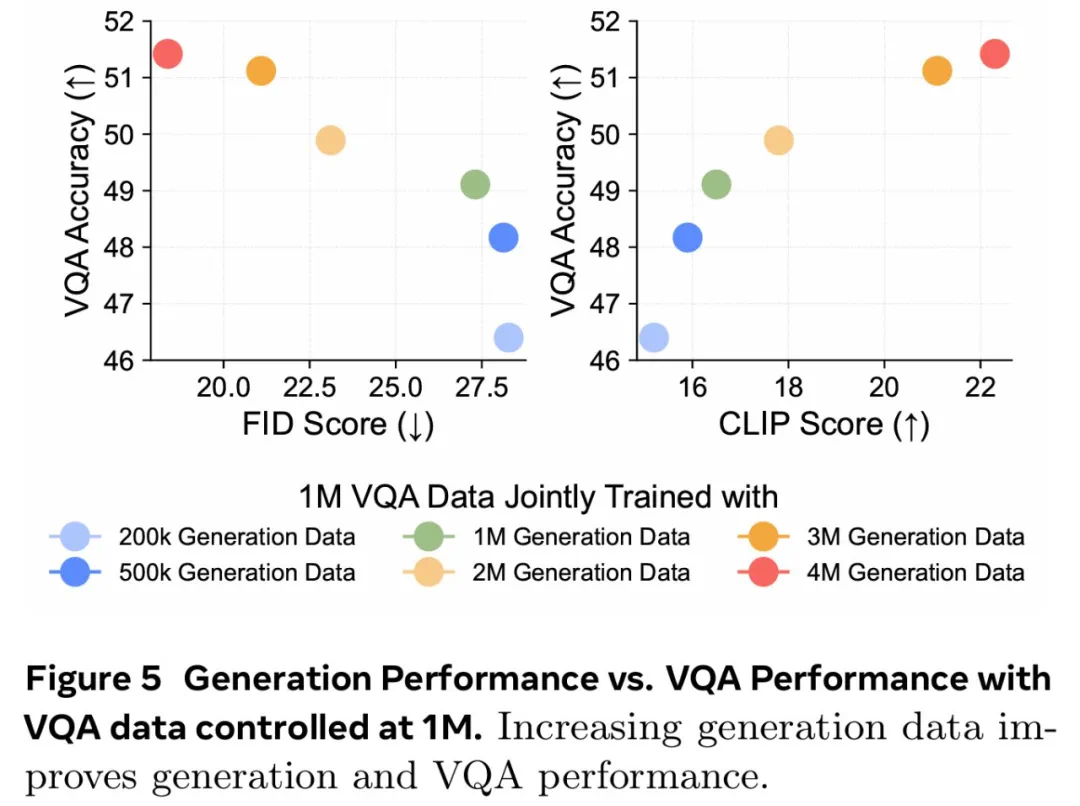
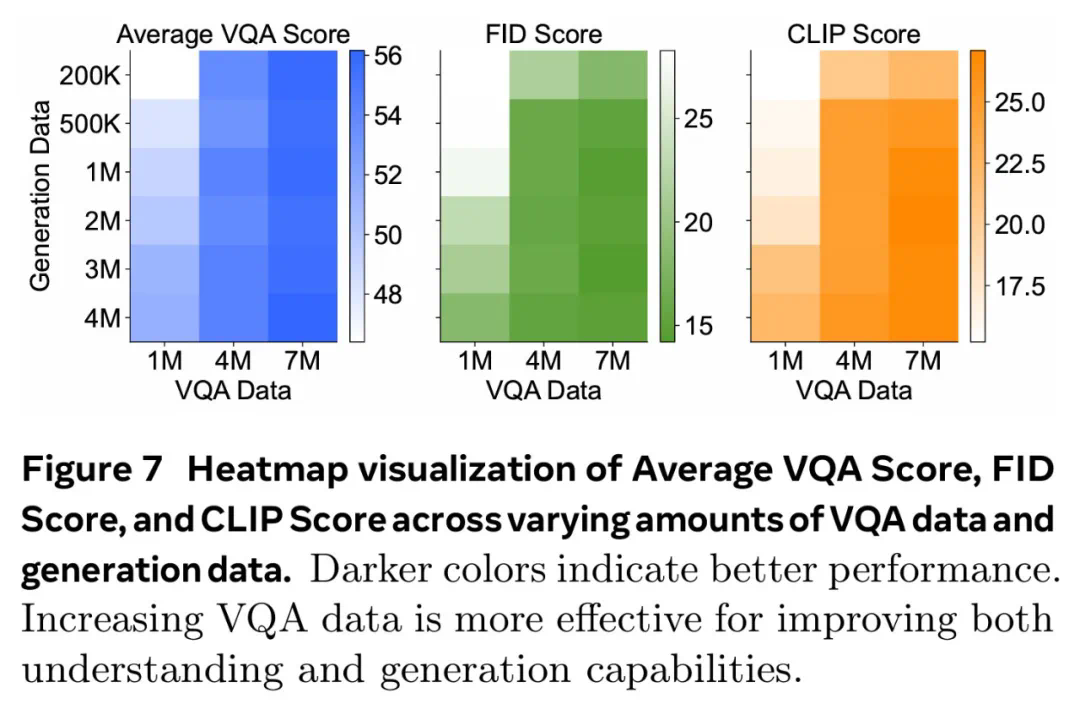
更多的视觉理解或生成数据对理解和生成质量的贡献有多大? -
哪些视觉理解任务与生成性能最相关?