
前言
在生成式AI浪潮席卷全球的当下,国产大模型DeepSeek凭借其开源生态和技术突破异军突起。近期其推出的7B/67B参数模型在权威评测中表现亮眼,更以"1元1百万tokens"的定价策略引发行业震动。
本文聚焦DeepSeek首篇奠基性论文《DeepSeek LLM: Scaling Open-Source Language Models with Longtermism》展开阅读理解,通过对其模型架构、训练方法论理解,揭示中国AI团队在大型语言模型领域的创新突破。
论文
论文标题:《DeepSeek LLM: Scaling Open-Source Language Models with Longtermism》
论文地址:https://arxiv.org/pdf/2401.02954
核心内容阅读
0. 摘要
论文原文
The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling laws described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate the scaling of large scale models in two prevalent used opensource configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and direct preference optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B across a range of benchmarks, especially in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that our DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
论文翻译
开源大语言模型(LLMs)的快速发展着实令人瞩目。然而,以往文献中描述的缩放定律存在不同结论,这给大语言模型的扩展蒙上了一层阴影。我们深入研究缩放定律,并呈现独特发现,这些发现有助于在两种常用的开源配置(70 亿和 670 亿参数)下进行大规模模型的扩展。在缩放定律的指导下,我们推出 DeepSeek LLM 项目,致力于从长远角度推进开源语言模型的发展。为支持预训练阶段,我们开发了一个目前包含 2 万亿词元的数据集,且该数据集还在持续扩展。我们进一步对 DeepSeek LLM 基础模型进行监督微调(SFT)和直接偏好优化(DPO),从而创建了 DeepSeek Chat 模型。评估结果表明,DeepSeek LLM 670 亿参数模型在一系列基准测试中优于 LLaMA – 2 700 亿参数模型,尤其是在代码、数学和推理领域。此外,开放式评估显示,我们的 DeepSeek LLM 670 亿参数 Chat 模型的性能优于 GPT – 3.5。
论文理解
在摘要部分,论文主要阐述了2个要点:
- 研究
Scaling Law的必要性:由于大语言模型(LLMs)的快速发展,人们对于缩放定律(Scaling Law)缺少深入研究;而在以往的文献中,对于Scaling Law的描述存在不同结论,所以需要对其进行深入研究。 - 研究
Scaling Law的结论:通过深入研究缩放定律,最终在两种常用的开源配置(70亿和670亿参数)下进行大规模模型的扩展,使得DeepSeek LLM67B 在多个基准测试中表现优异,尤其是在代码、数学和推理领域。
1. 引言
论文原文
Over the past few years, Large Language Models (LLMs) based on decoder-only Transformers (Vaswani et al., 2017) have increasingly become the cornerstone and pathway to achieving Artificial General Intelligence (AGI). By predicting the next word in continuous text, LLMs undergo self-supervised pre-training on massive datasets, enabling them to achieve various purposes and possess many abilities, such as novel creation, text summarization, code completion, and more. Subsequent developments like supervised fine-tuning and reward modeling have enabled Large Language Models (LLMs) to better follow user intentions and instructions. This has endowed them with more versatile conversational capabilities and rapidly expanded their influence.
This wave is sparked with closed products, such as ChatGPT (OpenAI, 2022), Claude (Anthropic, 2023), and Bard (Google, 2023), which are developed with extensive computational resources and substantial annotation costs. These products have significantly raised the community’s expectations for the capabilities of open-source LLMs, consequently inspiring a series of work (Bai et al., 2023; Du et al., 2022; Jiang et al., 2023; Touvron et al., 2023a,b; Yang et al., 2023). Among these, the LLaMA series models (Touvron et al., 2023a,b) stand out. It consolidates a range of works to create an efficient and stable architecture, building well-performing models ranging from 7B to 70B parameters. Consequently, the LLaMA series has become the de facto benchmark for architecture and performance among open-source models.
Following LLaMA, the open-source community has primarily focused on training fixed-size (7B, 13B, 34B, and 70B), high-quality models, often neglecting research exploration into LLM scaling laws (Hoffmann et al., 2022; Kaplan et al., 2020). Nonetheless, research on scaling laws is of utmost importance, considering that the current open-source models are merely at the initial stage of Artificial General Intelligence (AGI) development. In addition, early works (Hoffmann et al., 2022; Kaplan et al., 2020) reached varying conclusions on the scaling of model and data with increased compute budgets and inadequately addressed hyperparameter discussions. In this paper, we extensively investigate the scaling behavior of language models and apply our findings in two widely used large-scale model configurations, namely 7B and 67B. Our study aims to lay the groundwork for future scaling of open-source LLMs, paving the way for further advancements in this domain. Specifically, we first examined the scaling laws of batch size and learning rate, and found their trends with model size. Building on this, we conducted a comprehensive study of the scaling laws of the data and model scale, successfully revealing the optimal model/data scaling-up allocation strategy and predicting the expected performance of our large-scale models. Additionally, during development, we discovered that the scaling laws derived from different datasets show significant differences. This suggests that choice of dataset remarkably affects the scaling behavior, indicating that caution should be exercised when generalizing scaling laws across datasets.
Under the guidance of our scaling laws, we build from scratch open-source large language models, and release as much information as possible for community reference. We collect 2 trillion tokens for pre-training, primarily in Chinese and English. At the model level, we generally followed the architecture of LLaMA, but replaced the cosine learning rate scheduler with a multi-step learning rate scheduler, maintaining performance while facilitating continual training. We collected over 1 million instances for supervised fine-tuning (SFT) (Ouyang et al., 2022) from diverse sources. This paper shares our experiences with different SFT strategies and findings in data ablation techniques. Additionally, we have utilized direct preference optimization (DPO) (Rafailov et al., 2023) to improve the conversational performance of the model.
We conduct extensive evaluations using our base and chat models. The evaluation results demonstrate that DeepSeek LLM surpasses LLaMA-2 70B across various benchmarks, particularly in the fields of code, mathematics, and reasoning. Following SFT and DPO, the DeepSeek 67B chat model outperforms GPT-3.5 in both Chinese and English open-ended evaluations. This highlights the superior performance of DeepSeek 67B in generating high-quality responses and engaging in meaningful conversations in both languages. Furthermore, the safety evaluation indicates that DeepSeek 67B Chat can provide harmless responses in practice.
论文翻译
在过去几年里,基于仅解码器架构的
Transformer(Vaswani 等人,2017)的大语言模型(LLMs)越来越成为实现通用人工智能(AGI)的基石和途径。通过预测连续文本中的下一个单词,大语言模型在大规模数据集上进行自监督预训练,这使它们能够达成多种目的,并具备诸多能力,如小说创作、文本摘要、代码补全等。随后出现的监督微调、奖励建模等技术,让大语言模型能更好地理解用户意图、遵循指令,赋予其更丰富的对话能力,影响力也迅速扩大。这一波发展由闭源产品引发,比如
ChatGPT(OpenAI,2022 年)、Claude(Anthropic,2023 年)和Bard(谷歌,2023 年),这些产品的开发需要大量计算资源和高昂的标注成本。这些产品极大地提高了社区对开源大语言模型能力的期望,从而激发了一系列研究工作(Bai 等人,2023 年;Du 等人,2022 年;Jiang 等人,2023 年;Touvron 等人,2023a,b;Yang 等人,2023 年)。在这些工作中,LLaMA系列模型(Touvron 等人,2023a,b)脱颖而出。它整合了一系列成果,创建了高效稳定的架构,构建了参数规模从70 亿到700 亿不等的高性能模型。因此,LLaMA系列已成为开源模型中架构和性能方面事实上的基准。在
LLaMA之后,开源社区主要专注于训练固定规模(70 亿、130 亿、340 亿和 700 亿参数)的高质量模型,却常常忽视对大语言模型缩放定律的研究探索(Hoffmann 等人,2022;Kaplan 等人,2020)。尽管如此,鉴于当前的开源模型仅仅处于通用人工智能(AGI)发展的初始阶段,对缩放定律的研究至关重要。此外,早期的研究(Hoffmann 等人,2022;Kaplan 等人,2020)在模型和数据随着计算资源增加的缩放问题上得出了不同结论,而且对超参数的讨论也不够充分。在本文中,我们广泛研究了语言模型的缩放行为,并将研究结果应用于两种广泛使用的大规模模型配置,即70 亿和670 亿参数的模型。我们的研究旨在为未来开源大语言模型的扩展奠定基础,为该领域的进一步发展铺平道路。具体而言,我们首先研究了批量大小和学习率的缩放定律,发现了它们随模型规模变化的趋势。在此基础上,我们对数据和模型规模的缩放定律进行了全面研究,成功揭示了最优的模型/数据扩展分配策略,并预测了大规模模型的预期性能。此外,在开发过程中我们发现,不同数据集得出的缩放定律存在显著差异。这表明数据集的选择对缩放行为有显著影响,意味着在跨数据集推广缩放定律时应谨慎行事。在我们的缩放定律指导下,我们从头开始构建开源大语言模型,并尽可能多地发布信息供社区参考。我们收集了
2 万亿个词元用于预训练,主要是中文和英文数据。在模型层面,我们总体上遵循LLaMA的架构,但将余弦退火学习率的调度器替换为多步学习率调度器,这样在保持模型性能的同时,更便于持续训练。我们从多种来源收集了超过100万个实例,用于监督微调(SFT)(欧阳等人,2022)。本文将分享我们在不同监督微调策略方面的经验,以及在数据消融技术上的发现。此外,我们利用直接偏好优化(DPO)(拉法伊洛夫等人,2023)来提升模型的对话性能。我们使用基础模型和聊天模型进行了广泛评估。评估结果表明,
DeepSeek LLM在各种基准测试中均优于LLaMA-2 70B,尤其是在代码、数学和推理领域。经过监督微调(SFT)和直接偏好优化(DPO)后,DeepSeek 67B聊天模型在中文和英文开放式评估中均优于GPT-3.5。这凸显了DeepSeek 67B在生成高质量回复以及用两种语言进行有意义对话方面的卓越性能。此外,安全评估表明,DeepSeek 67B Chat在实际应用中能够给出无害的回复。
论文理解
通过对引言的阅读,我们了解到:
- 缩放定律(Scaling Law)的研究至关重要,特别是在当前开源模型处于通用人工智能(AGI)发展的初始阶段;
- 在以往的研究中,对于
Scaling Law的描述存在不同结论,而且对于超参数的讨论也不够充分; - 基于以上的问题,这篇论文主要研究了Scaling Law,发现数据集的选择对于Scaling Law的影响显著,并提出了Scaling Law的优化策略;
- 在具体研究过程中,总体上遵循了
LLaMA的架构,但将余弦退火学习率的调度器替换为多步学习率调度器,同时通过监督微调(SFT)和直接偏好优化(DPO)来提升模型的对话性能。 - 在评估过程中,
DeepSeek LLM 67B在多个基准测试中表现优异,尤其是在代码、数学和推理领域。
2. 预训练
2.1 数据集
论文原文
Our main objective is to comprehensively enhance the richness and diversity of the dataset. We have gained valuable insights from reputable sources such as (Computer, 2023; Gao et al., 2020; Penedo et al., 2023; Touvron et al., 2023a). To achieve these goals, we have organized our approach into three essential stages: deduplication, filtering, and remixing. The deduplication and remixing stages ensure a diverse representation of the data by sampling unique instances. The filtering stage enhances the density of information, thereby enabling more efficient and effective model training.
We adopted an aggressive deduplication strategy, expanding the deduplication scope. Our analysis revealed that deduplicating the entire Common Crawl corpus results in higher removal of duplicate instances compared to deduplicating within a single dump. Table 1 illustrates that deduplicating across 91 dumps eliminates four times more documents than a single dump method.

For our tokenizer, we implemented the Byte-level Byte-Pair Encoding (BBPE) algorithm based on the tokenizers library (Huggingface Team, 2019). Pre-tokenization was employed to prevent the merging of tokens from different character categories such as new lines, punctuation, and Chinese-Japanese-Korean (CJK) symbols, similar to GPT-2 (Radford et al., 2019). We also chose to split numbers into individual digits following the approach used in (Touvron et al., 2023a,b). Based on our prior experience, we set the number of conventional tokens in the vocabulary at 100000. The tokenizer was trained on a multilingual corpus of approximately 24 GB, and we augmented the final vocabulary with 15 special tokens, bringing the total size to 100015. To ensure computational efficiency during training and to reserve space for any additional special tokens that might be needed in the future, we configured the model’s vocabulary size to 102400 for training.
论文翻译
我们的主要目标是全面提升数据集的丰富性和多样性。我们从一些可靠的资料来源(如 Computer, 2023; Gao 等人,2020; Penedo 等人,2023; Touvron 等人,2023a)中获得了宝贵的见解。为实现这些目标,我们将方法分为三个关键阶段:去重、筛选和重新混合。去重和重新混合阶段通过对独特实例进行采样,确保数据具有多样化的代表性。筛选阶段则提高了信息密度,从而使模型训练更加高效。
我们采用了激进的去重策略,扩大了去重范围。我们的分析显示,与在单个数据转储中进行去重相比,对整个
Common Crawl语料库进行去重能删除更多的重复实例。表 1 表明,跨 91 个数据转储进行去重所删除的文档数量是单数据转储去重方法的四倍。对于我们的分词器,我们基于
Huggingface团队(2019 年)开发的tokenizers库,实现了字节级字节对编码(BBPE)算法。我们采用了预分词技术来防止不同字符类别的标记合并,例如换行符、标点符号以及中日韩(CJK)符号,这与GPT-2(Radford 等人,2019 年)的做法类似。我们还参照(Touvron 等人,2023a,b)的方法,选择将数字拆分为单个数字。根据我们之前的经验,我们将词汇表中的常规标记数量设置为100000。分词器在大约24GB的多语言语料库上进行训练,并且我们在最终的词汇表中增加了15个特殊标记,使总大小达到100015。为确保训练期间的计算效率,并为未来可能需要的任何额外特殊标记预留空间,我们将训练时模型的词汇表大小配置为102400。
论文理解
- 论文中介绍到,在数据集处理方面主要采用三种方法:去重、筛选和重新混合。
- 在去重方面,采用了激进的去重策略,扩大了去重范围。实验数据表明,跨91个数据转储进行去重所删除的文档数量是单数据转储去重方法的四倍。
- 在分词器方面,采用了字节级字节对编码(BBPE)算法,并采用了预分词技术来防止不同字符类别的标记合并,例如换行符、标点符号以及中日韩(CJK)符号,这与 GPT-2(Radford 等人,2019 年)的做法类似。
个人理解,训练大模型就好比读书一样,重点在于读好书,而不是乱八七糟什么书都读。
2.2 模型结构

论文原文
The micro design of DeepSeek LLM largely follows the design of LLaMA (Touvron et al., 2023a,b), adopting a Pre-Norm structure with RMSNorm (Zhang and Sennrich, 2019) function and using SwiGLU (Shazeer, 2020) as the activation function for the Feed-Forward Network (FFN), with an intermediate layer dimension of $\frac{8}{3} d_{model }$ . It also incorporates Rotary Embedding (Su et al., 2024) for positional encoding. To optimize inference cost, the 67B model uses GroupedQuery Attention (GQA) (Ainslie et al., 2023) instead of the traditional Multi-Head Attention (MHA).
However, in terms of macro design, DeepSeek LLM differs slightly. Specifically, DeepSeek LLM 7B is a 30-layer network, while DeepSeek LLM 67B has 95 layers. These layer adjustments, while maintaining parameter consistency with other open-source models, also facilitate model pipeline partitioning to optimize training and inference.
论文翻译
DeepSeek LLM 的微观设计在很大程度上遵循
LLaMA(Touvron 等人,2023a,b)的设计,采用带有RMSNorm(Zhang 和 Sennrich,2019)函数的Pre-Norm结构,并使用SwiGLU(Shazeer,2020)作为MARKDOWN_HASH7d211f462f3b56c0dbf9f92028c9903aMARKDOWNHASH的激活函数,其中间层维度为 $\frac{8}{3} d{model }$ 。它还采用旋转嵌入(Su 等人,2024)进行位置编码。为了优化推理成本,670 亿参数的模型使用分组查询注意力机制(GQA)(Ainslie 等人,2023),而非传统的多头注意力机制(MHA)。然而,在宏观设计方面,
DeepSeek LLM略有不同。具体来说,DeepSeek LLM7B 是一个30层的网络,而DeepSeek LLM67B 有95层。这些层数的调整,在保持与其他开源模型参数一致性的同时,也有利于模型流水线分区,从而优化训练和推理过程。
论文理解
通过对比Deepseek与LLaMa,主要区别点有:
- 前馈网络:DeepSeek LLM 采用了带有
RMSNorm的Pre-Norm结构,并使用SwiGLU作为前馈网络(FFN)的激活函数,其中间层维度为\frac{8}{3} d_{model }。 - 位置编码:采用了
旋转嵌入进行位置编码。 - 注意力机制:为了优化推理成本,670 亿参数的模型使用
分组查询注意力机制(GQA),而非传统的多头注意力机制(MHA)。 - 宏观设计:如下表所示,DeepSeek在
7B和670B两个参数下,网络层数、学习率、批量大小等均有不同。
| 参数 | 层数 | 模型维度 | 头数 | 键头数 | 上下文长度 | 序列批量大小 | 学习率 | 词元数 |
|---|---|---|---|---|---|---|---|---|
| 70亿参数模型 | 30 | 4096 | 32 | 32 | 4096 | 2304 | 4.2×10⁻⁴ | 2.0万亿 |
| 670亿参数模型 | 95 | 8192 | 64 | 8 | 4096 | 4608 | 3.2×10⁻⁴ | 2.0万亿 |
延伸了解
相关知识点的辅助资料查询如下:
-
RMSNorm:RMSNorm是LayerNorm的一个简单变体,来自 2019 年的论文 Root Mean Square Layer Normalization,被 T5 和当前流行 lamma 模型所使用。其提出的动机是LayerNorm运算量比较大,所提出的RMSNorm性能和LayerNorm相当,但是可以节省7%到64%的运算。 -
SwiGLU:swiGLU是对GLU的改进一种激活函数模块,通过引入Swish激活函数来提供更平滑的非线性映射,有助于提升深度学习模型的表现,尤其是在Transformer架构中。资料来源:激活函数-swiGLU
-
分组查询注意力机制(GQA):Grouped Multi-Query Attention是一种Multi-Head Attention的变体,它是在计算成本和生成结果质量之间的一种折中方法。 -
余弦退火算法:CosineAnnealing是一种学习率衰减的算法,它通过余弦函数来调整学习率,从而达到学习率随迭代次数增加而衰减的效果。
2.3 超参数
论文原文
A multi-step learning rate scheduler is employed during pre-training instead of the typical
cosine scheduler. Specifically, the learning rate of the model reaches its maximum value after
2000 warmup steps, and then decreases to 31.6% of the maximum value after processing 80% of
the training tokens. It further reduces to 10% of the maximum value after 90% of the tokens.
The gradient clipping during the training phase is set to 1.0Based on our empirical findings, we observed that despite differences in the loss reduction trend during training, the final performance using a multi-step learning rate scheduler is essentially consistent with that of a cosine scheduler, as shown in Figure 1(a). When adjusting the training scale while keeping the model size fixed, the multi-step learning rate scheduler allows for the reuse of training from the first phase, offering a unique convenience for continual training. Therefore, we chose the multi-step learning rate scheduler as our default setting. We also demonstrate in Figure 1(b) that adjusting the proportions of different stages in the multi-step learning rate scheduler can yield slightly better performance. However, for the sake of balancing reuse ratios in continual training and model performance, we opted for the aforementioned distribution of 80%, 10%, and 10% for the three stages respectively.
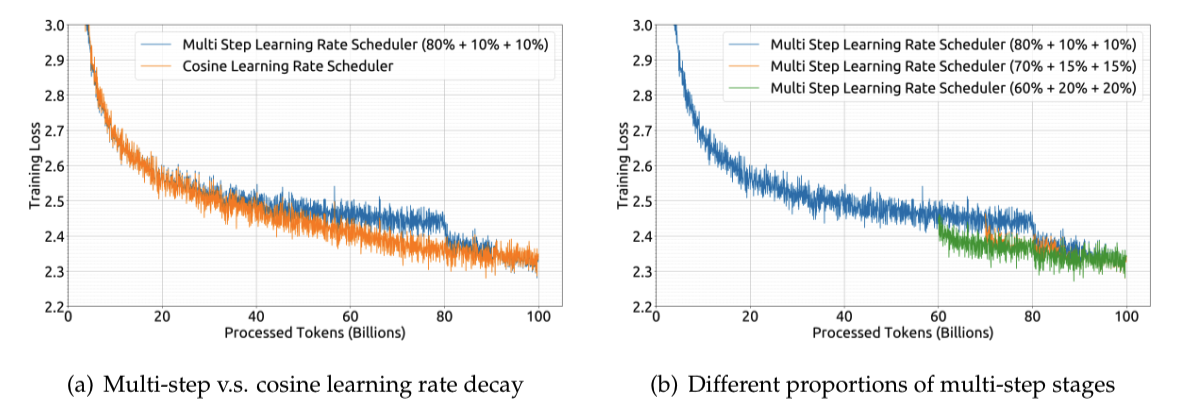
论文翻译
预训练期间采用多步学习率调度器,而非典型的余弦退火调度器。具体而言,模型的学习率在经过
2000个预热步骤后达到最大值,随后在处理完80%的训练词元后降至最大值的31.6%。在处理完90%的词元后,学习率进一步降至最大值的10%。训练阶段的梯度裁剪设置为1.0。基于我们的实证研究结果,我们注意到,尽管在训练过程中不同阶段损失减少趋势有所不同,但使用多步学习率调度器得到的最终性能与余弦调度器基本一致,如图 1(a)所示。在保持模型规模不变的情况下调整训练规模时,多步学习率调度器允许重复利用第一阶段的训练成果,为持续训练提供了独特的便利。因此,我们选择多步学习率调度器作为默认设置。我们还在图 1(b)中展示了,调整多步学习率调度器中不同阶段的比例,可使性能略有提升。然而,为了平衡持续训练中的复用率和模型性能,我们选择了上述三个阶段分别为 80%、10% 和 10% 的比例分配。
论文理解
- 相比较LlaMa,DeepSeek采用的是
多步学习率调度器。 - 它是一种学习率调度器,通过多步学习率调整,从而达到学习率随迭代次数增加而衰减的效果。
- 其性能与常规的余弦调度器基本一致,通过调整多步学习率调度器中不同阶段的比例,可以略微提升性能。
2.4 基础设施
论文原文
We use an efficient and light-weight training framework named HAI-LLM (High-flyer, 2023) to train and evaluate large language models. Data parallelism, tensor parallelism, sequence parallelism, and 1F1B pipeline parallelism are integrated into this framework as done in Megatron (Korthikanti et al., 2023; Narayanan et al., 2021; Shoeybi et al., 2019). We also leverage the flash attention (Dao, 2023; Dao et al., 2022) technique to improve hardware utilization. ZeRO-1 (Rajbhandari et al., 2020) is exploited to partition optimizer states over data parallel ranks. Efforts are also made to overlap computation and communication to minimize additional waiting overhead, including the backward procedure of the last micro-batch and reduce-scatter operation in ZeRO-1, and GEMM computation and all-gather/reduce-scatter in sequence parallel. Some layers/operators are fused to speed up training, including LayerNorm, GEMM whenever possible, and Adam updates. To improve model training stability, we train the model in bf16 precision but accumulate gradients in fp32 precision. In-place cross-entropy is performed to reduce GPU memory consumption, i.e.: we convert bf16 logits to fp32 precision on the fly in the cross-entropy CUDA kernel (instead of converting it beforehand in HBM), calculate the corresponding bf16 gradient, and overwrite logits with its gradient.
Model weights and optimizer states are saved every 5 minutes asynchronously, which means we will lose no more than 5 minutes of training in the worst case of occasional hardware or network failures. These temporary model checkpoints are cleared up regularly to avoid consuming too much storage space. We also support resuming training from a different 3D parallel configuration to cope with dynamic changes in computing cluster load.
As for evaluation, we employ vLLM (Kwon et al., 2023) in generative tasks, and continuous batching in non-generative tasks to avoid manual batch size tuning and reduce token padding.
论文翻译
我们使用一个名为
HAI-LLM(High – flyer,2023)的高效轻量级训练框架来训练和评估大语言模型。与 Megatron(Korthikanti 等人,2023;Narayanan 等人,2021;Shoeybi 等人,2019)一样,数据并行、张量并行、序列并行和 1F1B 流水线并行都集成到了这个框架中。我们还利用了FlashAttention(Dao,2023;Dao 等人,2022)技术来提高硬件利用率。采用ZeRO-1(Rajbhandari 等人,2020)在数据并行等级上对优化器状态进行分区。我们还努力让计算和通信重叠,以尽量减少额外的等待开销,包括最后一个微批次的反向传播过程以及 ZeRO-1 中的规约-散射操作,还有序列并行中的通用矩阵乘法(GEMM)计算与全收集/规约-散射操作。为加快训练速度,对一些层 / 操作符进行了融合,包括尽可能对层归一化(LayerNorm)、通用矩阵乘法(GEMM)以及Adam 更新操作。为提高模型训练的稳定性,我们以bf16精度训练模型,但以fp32精度累积梯度。通过执行原地交叉熵计算来减少GPU内存消耗,即:我们在交叉熵CUDA内核中即时将bf16格式的对数几率(logits)转换为fp32精度(而不是事先在高带宽内存(HBM)中进行转换),计算相应的bf16梯度,并用梯度覆盖对数几率。模型权重和优化器状态每 5 分钟异步保存一次,这意味着在偶尔出现硬件或网络故障的最坏情况下,我们损失的训练进度不会超过 5 分钟。这些临时的模型检查点会定期清理,以避免占用过多存储空间。我们还支持从不同的三维并行配置恢复训练,以应对计算集群负载的动态变化。
论文理解
(以上内容过于专业,对于半路出家的我来说,理解其原理超纲了)
本着求知的心态,我在Deepseek的所属公司(幻方),查询到相关的资料如下:
HAI-LLM是幻方-深度求索(Deepseek)研发的一款深度学习训练工具。HAI-LLM实现了四种并行训练方式:ZeRO 支持的数据并行、流水线并行、张量切片模型并行和序列并行。
备注:近期英伟达股价暴跌,可能就是由于Deepseek的这个训练方式,绕过了英伟达的CUDA护城河。
3. 缩放定律(Scaling Laws)
论文原文
Research on scaling laws (Hestness et al., 2017) predates the emergence of large language models. Scaling laws (Henighan et al., 2020; Hoffmann et al., 2022; Kaplan et al., 2020) suggest that model performance can be predictably improved with increases in compute budget c , model scale N and data scale D . When model scale N is represented by model parameters and data scale D by the number of tokens, c can be approximated as
C=6 N D. Therefore, how to optimize the allocation between model and data scales when increasing the compute budget is also a crucial research objective in scaling laws.…(中间部分省略)
We then study the scaling laws of the model and data scales. To reduce experimental costs and fitting difficulties, we adopted the IsoFLOP profile approach from Chinchilla (Hoffmann et al., 2022) to fit the scaling curve. To represent the model scale more accurately, we utilized a new model scale representation, non-embedding FLOPs/token M , replacing the earlier-used model parameters N , and substituted the approximate compute budget formula
C=6 N Dwith the more preciseC=M D. The experimental results provided insights into the optimal model/data scaling-up allocation strategy and performance predictions, and also accurately forecasted the expected performance of DeepSeek LLM 7B and 67B models.Additionally, in the process of exploring scaling laws, the data we used underwent multiple iterations, continually improving in quality. We attempted to fit the scaling curve on various datasets and found that the data quality significantly influences the optimal model/data scalingup allocation strategy. The higher the data quality, the more the increased compute budget should be allocated to model scaling. This implies that high-quality data can drive the training of larger models given the same data scale. The differences in the optimal model/data scaling-up allocation strategy may also serve as an indirect approach to assess the quality of data. We will continue to pay close attention to the changes in data quality and its impact on scaling laws, and provide more analysis in future works.
In summary, our contributions and findings in scaling laws can be summarized as follows:
• We established the scaling laws for hyperparameters, providing an empirical framework for determining the optimal hyperparameters.
• Instead of model parameters N , we adopt non-embedding FLOPs/token M to represent the model scale, leading to a more accurate optimal model/data scaling-up allocation strategy and a better prediction of generalization loss for large-scale models.
• The quality of pre-training data impacts the optimal model/data scaling-up allocation strategy. The higher the data quality, the more the increased compute budget should be allocated to model scaling.
论文翻译
关于缩放定律的研究(赫斯内斯等人,2017 年)早于大语言模型的出现。缩放定律(亨尼根等人,2020 年;霍夫曼等人,2022 年;卡普兰等人,2020 年)表明,随着计算资源预算
C、模型规模N和 数据规模D的增加,模型性能有望得到可预测的提升。当模型规模N用模型参数表示,数据规模D用令牌数量表示时,C可近似表示为C=6 N D。因此,在增加计算资源预算时,如何优化模型与数据规模之间的分配,也是缩放定律研究中的一个关键目标。…(中间部分省略)
接着,我们研究模型规模和数据规模的缩放定律。为降低实验成本与拟合难度,我们采用了 Chinchilla 论文(霍夫曼等人,2022 年)中的等浮点运算次数(IsoFLOP)曲线法来拟合缩放曲线。为更准确地表示模型规模,我们使用了一种新的模型规模表示方式 —— 每个词元的非嵌入浮点运算次数
M,以取代之前使用的模型参数N,并对近似计算预算公式C=6 N D进行了替换,将其替换为更精确的公式C=M D。实验结果为最优的模型/数据扩容分配策略及性能预测提供了深刻见解,还准确预测了 DeepSeek LLM 70 亿参数和 670 亿参数模型的预期性能。此外,在探索缩放定律的过程中,我们所使用的数据历经多次迭代,质量不断提升。我们尝试在各种数据集上拟合缩放曲线,发现数据质量对最优的模型 / 数据扩容分配策略有显著影响。数据质量越高,增加的计算预算就越应分配给模型扩容。这意味着在相同的数据规模下,高质量数据能够推动更大规模模型的训练。最优模型 / 数据扩容分配策略的差异,也可作为一种间接评估数据质量的方法。我们将继续密切关注数据质量的变化及其对缩放定律的影响,并在未来的研究中提供更多分析。
综上所述,我们在缩放定律方面的贡献和发现可总结如下:
- 我们建立了超参数的缩放定律,为确定最优超参数提供了一个实证框架。
- 我们采用每个词元的非嵌入浮点运算次数
M来代替模型参数N表示模型规模,这带来了更准确的最优模型 / 数据扩容分配策略,并且能更好地预测大规模模型的泛化损失。- 预训练数据的质量会影响最优的模型 / 数据扩容分配策略。数据质量越高,增加的计算预算就越应分配给模型扩容。
论文理解
-
训练AI的"三原色"原理 🎨
- 计算力量 (C):训练AI需要的"电力"
- 模型大小 (N):AI大脑的"神经元数量"
- 数据量 (D):给AI看的"教材厚度"
- 传统公式:
训练电力 ≈ 6 × 神经元数 × 教材厚度
-
DeepSeek的新发现 🔍
- 更聪明的测量尺 📏
改用每个字的计算量(M)代替参数数量,就像用"脑力劳动量"比"脑细胞数量"更能反映真实智商 - 教材质量决定培养方案 📚
✅ 好教材(高质量数据):可以培养"大脑发达"的AI学霸
❌ 差教材:只能培养"死记硬背"的AI学渣
- 更聪明的测量尺 📏
内容小结:
-
AI江湖现状 🌍
- 闭源大佬:ChatGPT等像"米其林餐厅"(配方保密,吃得起但学不会)
- 开源新秀:LLaMA系列如"网红菜谱"(免费公开,但需要自家厨房够大)
- 当前困境:大多数开源模型像"固定菜式套餐"(只有7B/13B等固定参数版本)
-
DeepSeek的核心突破 💥
| 研究重点 | 通俗解释 | 实际应用 |
|---|---|---|
| 缩放定律 | 找到AI训练的"黄金配比公式" | 知道何时该加"脑容量"或"读书量" |
| 动态学习率 | 像智能电饭煲调节火候 | 训练更稳定,效果更好 |
| 数据质量检测 | 给训练数据做"体检" | 自动识别优质学习资料 |
| 安全防护 | 给AI装"刹车系统" | 避免说错话/做危险事 |
备注:以上论文理解内容以及内容小结,由Deepseek-R1辅助生成。论文翻译部分由豆包的PDF阅读翻译功能完成。



