文章来源于互联网:MV-DUSt3R+: 只需2秒!Meta Reality Labs开源最新三维基座模型,多视图大场景重建

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文一作为唐正纲,目前为博士生,就读于伊利诺伊大学厄巴纳 – 香槟分校,本科毕业于北京大学。通讯作者是严志程,Meta Reality Labs 高级科研研究员 (Senior Staff Research Scientist),主要研究方向包括三维基础模型,终端人工智能 (On-device AI) 和混合现实。
近期,Fei-Fei Li 教授的 World Labs 和 Google 的 Genie 2 展示了 AI 从单图生成 3D 世界的能力。这技术让我们能步入任何图像并以 3D 形式探索,预示着数字创造的新未来。
Meta 也加入了这场构建世界模型的竞赛,推出并且开源了全新的世界模型构建基座模型 MV-DUSt3R+。Meta 的技术通过 Quest 3 和 Quest 3S 头显,快速还原 3D 场景。只需几张照片,用户就能在 Meta 头显中体验不同的混合环境。
在这一领域,DUSt3R 曾是 SOTA 的标杆。其 GitHub 上的 5.5k star 证明了它在 3D 重建领域的影响力。然而,DUSt3R 每次只能处理两张图。处理更多图时,需要使用 bundle adjustment,这非常耗时,限制了它在复杂场景上的应用。
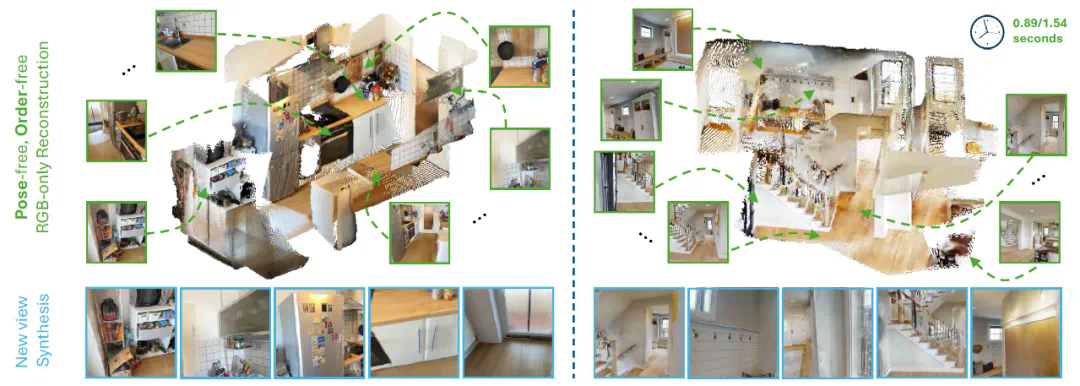
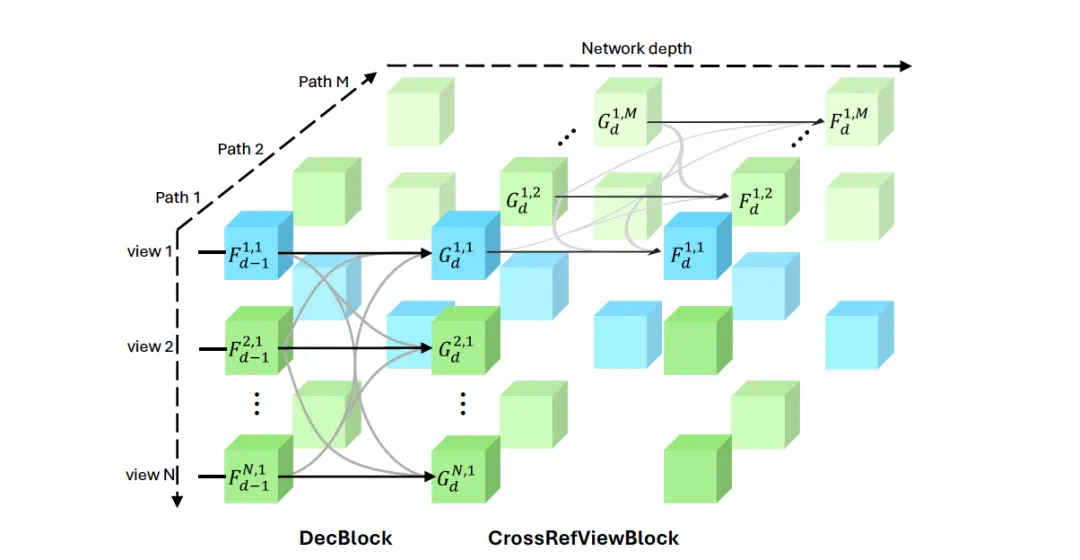
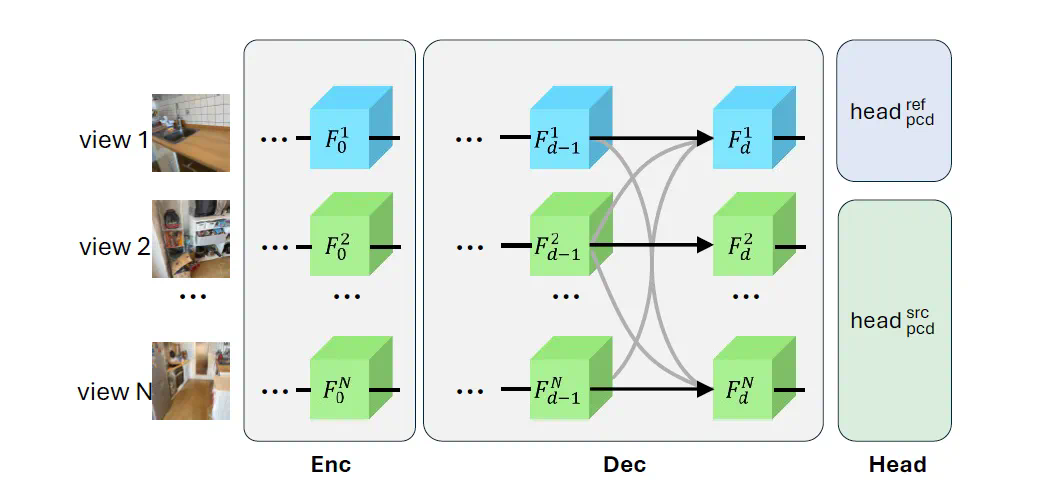
现在,Meta Reality Labs 和伊利诺伊大学厄巴纳 – 香槟分校(UIUC)推出了新工作《MV-DUSt3R+: Single-Stage Scene Reconstruction from Sparse Views In 2 Seconds》。这项研究全面提升了 DUSt3R。通过全新的多视图解码器块和交叉视图注意力块机制,MV-DUSt3R + 可以直接从稀疏视图中重建复杂的三维场景。而且重建只需 2 秒钟!
-
单阶段场景重建:2 秒内完成复杂三维场景的重建。 -
多视图解码器块:无需相机校准和姿态估计,处理任意数量的视图。 -
交叉视图注意力块:增强对不同参考视图选择的鲁棒性。

-
论文链接:https://arxiv.org/abs/2412.06974 -
项目主页:https://mv-dust3rp.github.io/ -
代码仓库:https://github.com/facebookresearch/mvdust3r/ 

-
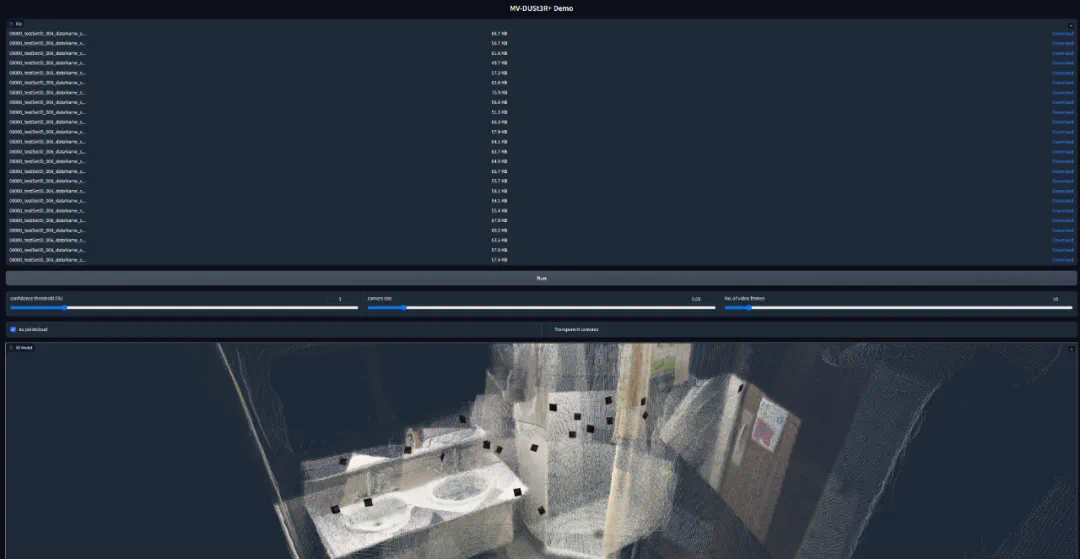
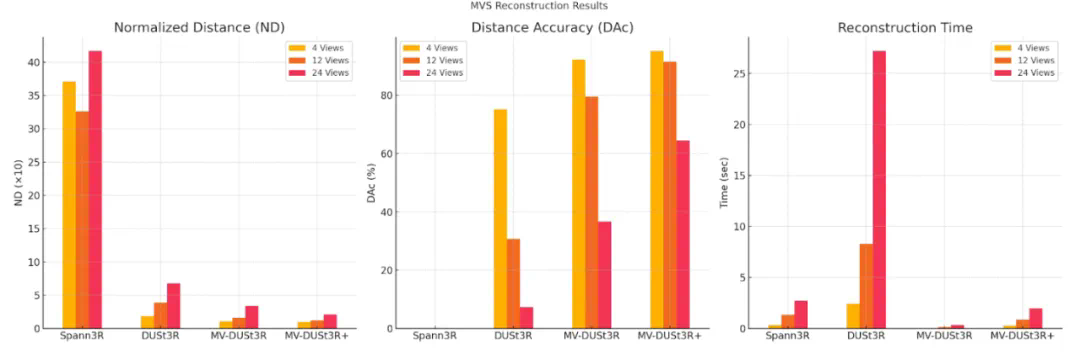
MV-DUSt3R:在 HM3D 数据集上,与 DUSt3R 相比,ND 降低 1.7 至 2 倍,DAc 提升 1.2 至 5.3 倍。随着输入视图数量增加,重建质量显著提升。 -
MV-DUSt3R+:12 视图输入下,ND 降低 1.3 倍,DAc 提升 1.2 倍。24 视图输入下,ND 降低 1.6 倍,DAc 提升 1.8 倍,表现更优。 -
零样本测试:在 MP3D 数据集上,MV-DUSt3R 和 MV-DUSt3R+ 始终优于 DUSt3R,展现了强大的泛化能力。
-
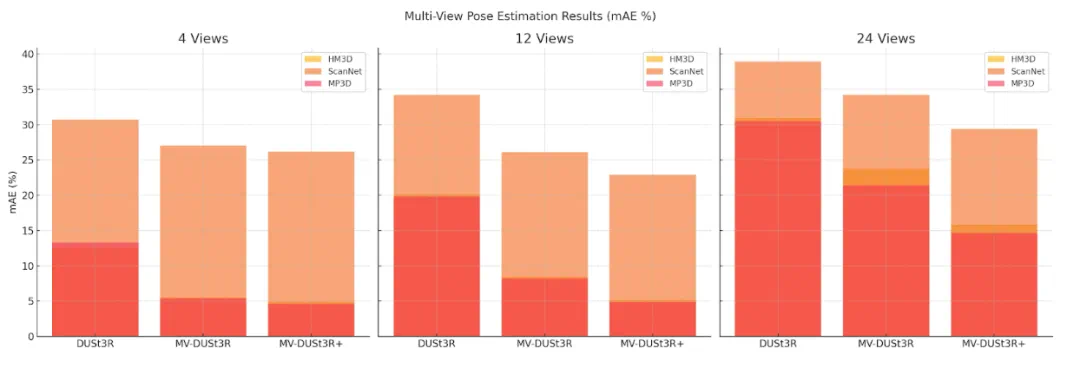
HM3D:MV-DUSt3R 的 mAE 相比 DUSt3R 降低 2.3 至 1.3 倍,MV-DUSt3R+ 降低 2.6 至 2.0 倍。 -
其他数据集:MV-DUSt3R+ 始终优于 DUSt3R,表现最佳。
-
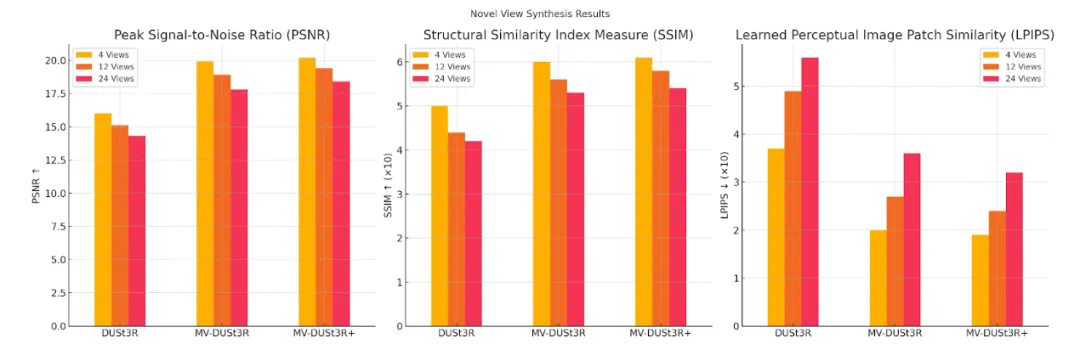
PSNR:MV-DUSt3R+ 在所有视图设置下表现最佳,显著提升重建质量。 -
SSIM:MV-DUSt3R+ 结构相似性最高,随着视图增加视觉保真度进一步提高。 -
LPIPS:MV-DUSt3R+ 感知误差最低,生成的新视图最接近真实图像。
-
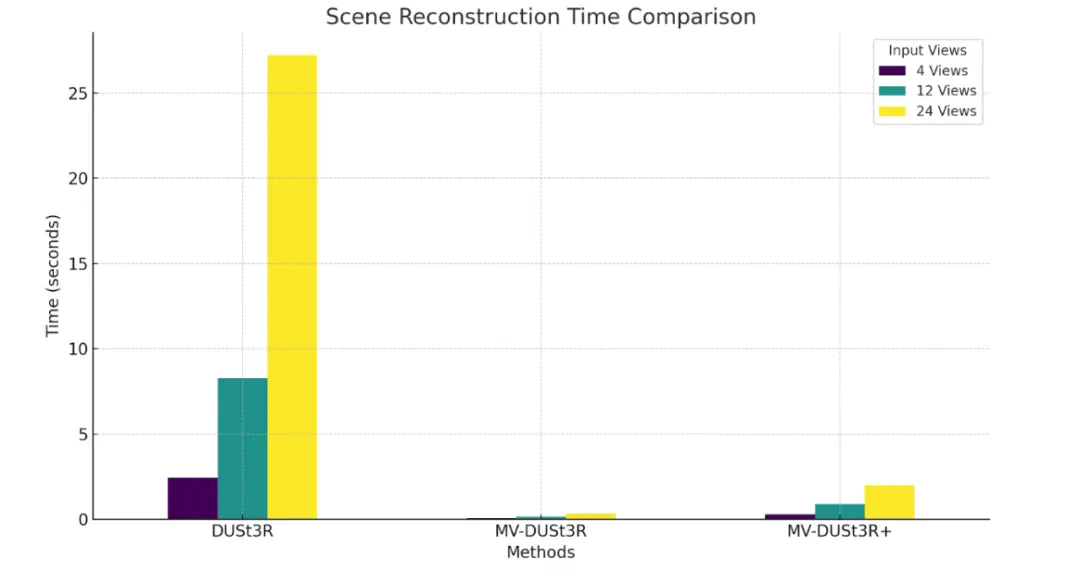
MV-DUSt3R+:在 24 视图输入下,仅需 1.97 秒,速度比 DUSt3R 快 14 倍。 -
MV-DUSt3R:时间更短,仅需 0.35 秒,比 DUSt3R 快 78 倍。 -
DUSt3R:重建时间明显更长,24 视图输入需 27.21 秒。







文章来源于互联网:MV-DUSt3R+: 只需2秒!Meta Reality Labs开源最新三维基座模型,多视图大场景重建

