文章来源于互联网:AI「视觉图灵」时代来了!字节OmniHuman,一张图配上音频,就能直接生成视频
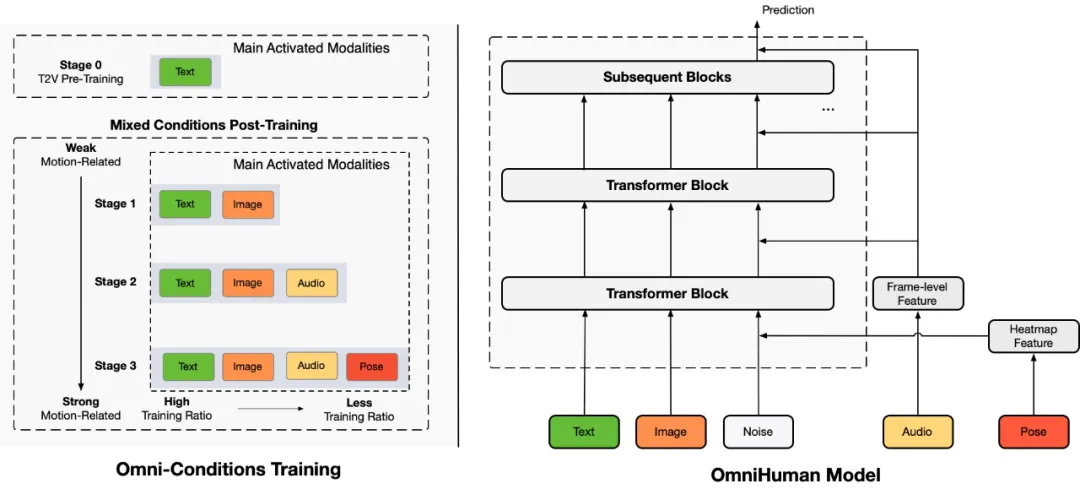
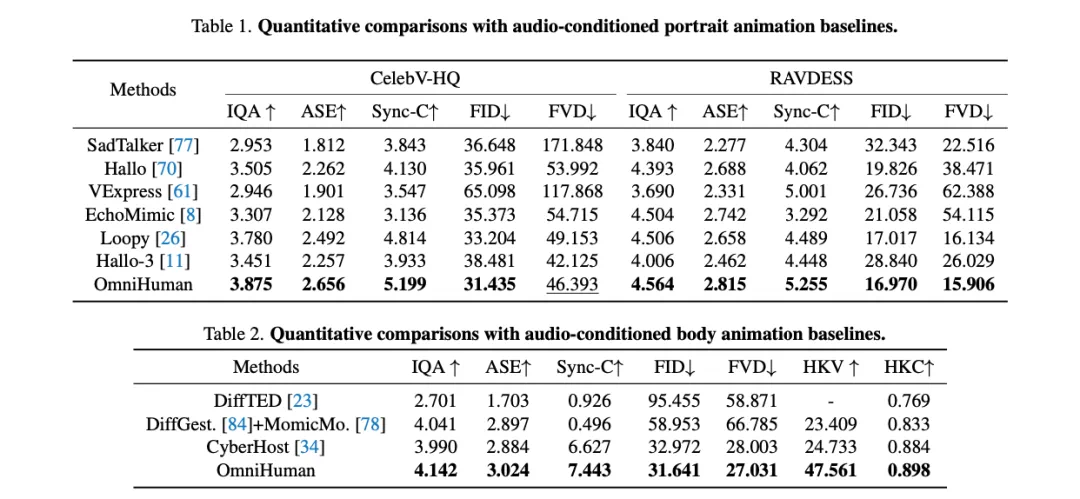
还记得半年前在 X 上引起热议的肖像音频驱动技术 Loopy 吗?升级版技术方案来了,字节跳动数字人团队推出了新的多模态数字人方案 OmniHuman, 其可以对任意尺寸和人物占比的单张图片结合一段输入的音频进行视频生成,生成的人物视频效果生动,具有非常高的自然度。
如对下面图片和音频:

 OmniHuman 生成的人物可以在视频中自然运动:
OmniHuman 生成的人物可以在视频中自然运动: 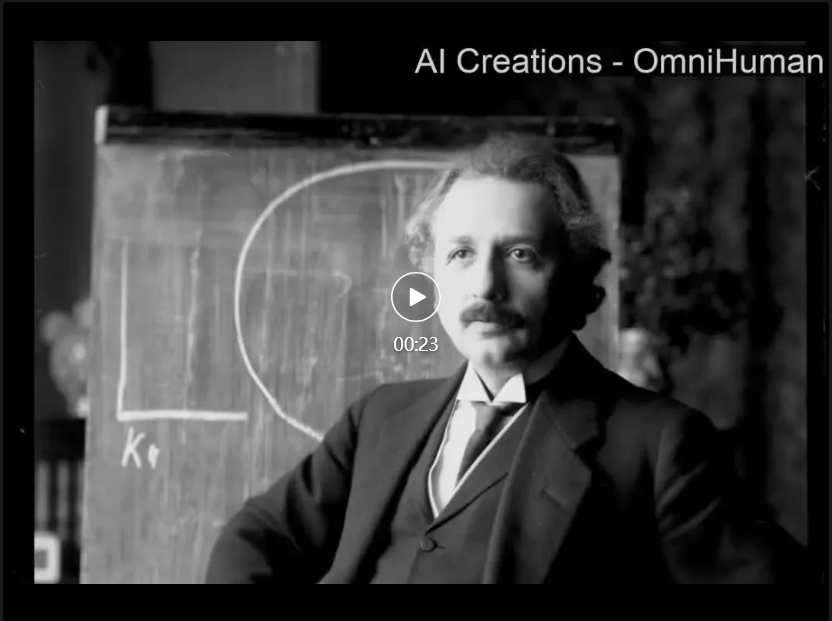 从项目主页上可以看到 OmniHuman 对肖像、半身以及全身这些不同人物占比、不同图片尺寸的输入都可以通过单个模型进行支持,人物可以在视频中生成和音频匹配的动作,包括演讲、唱歌、乐器演奏以及移动。对于人物视频生成中常见的手势崩坏,也相比现有的方法有显著的改善。
从项目主页上可以看到 OmniHuman 对肖像、半身以及全身这些不同人物占比、不同图片尺寸的输入都可以通过单个模型进行支持,人物可以在视频中生成和音频匹配的动作,包括演讲、唱歌、乐器演奏以及移动。对于人物视频生成中常见的手势崩坏,也相比现有的方法有显著的改善。 
 作者也展示模型对非真人图片输入的支持,可以看到对动漫、3D 卡通的支持也很不错,能保持特定风格原有的运动模式。据悉,该技术方案已落地即梦 AI,相关功能将于近期开启测试。
作者也展示模型对非真人图片输入的支持,可以看到对动漫、3D 卡通的支持也很不错,能保持特定风格原有的运动模式。据悉,该技术方案已落地即梦 AI,相关功能将于近期开启测试。 


-
论文项目主页:https://omnihuman-lab.github.io/ -
技术报告:https://arxiv.org/abs/2502.01061