文章来源于互联网:LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
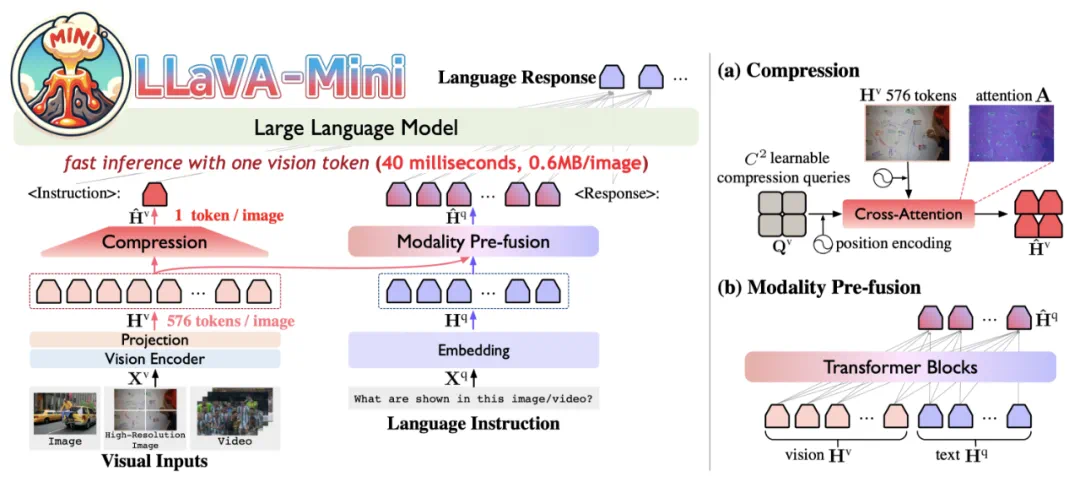
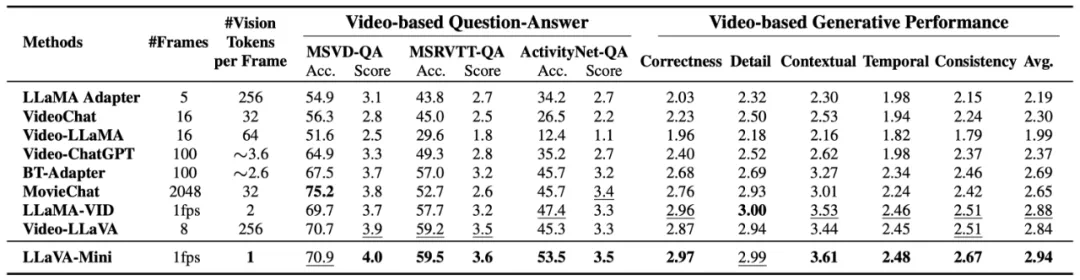
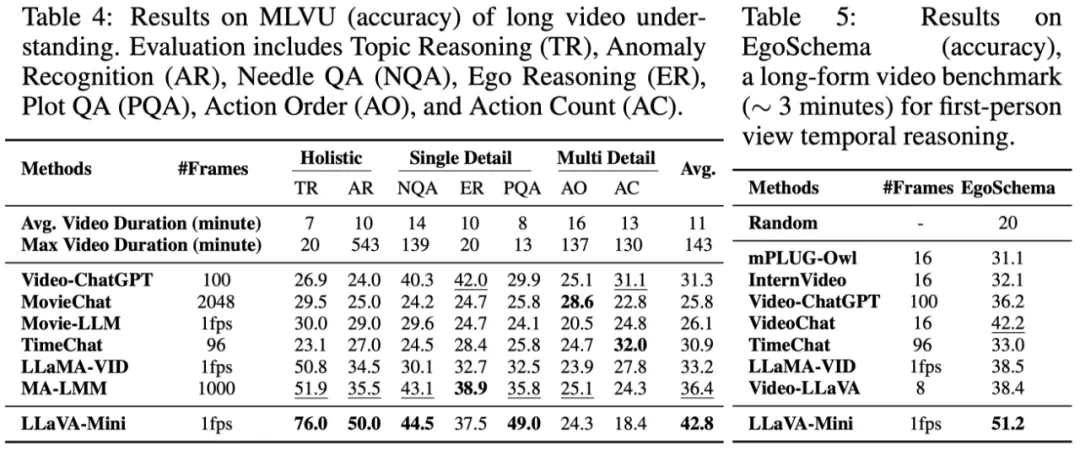
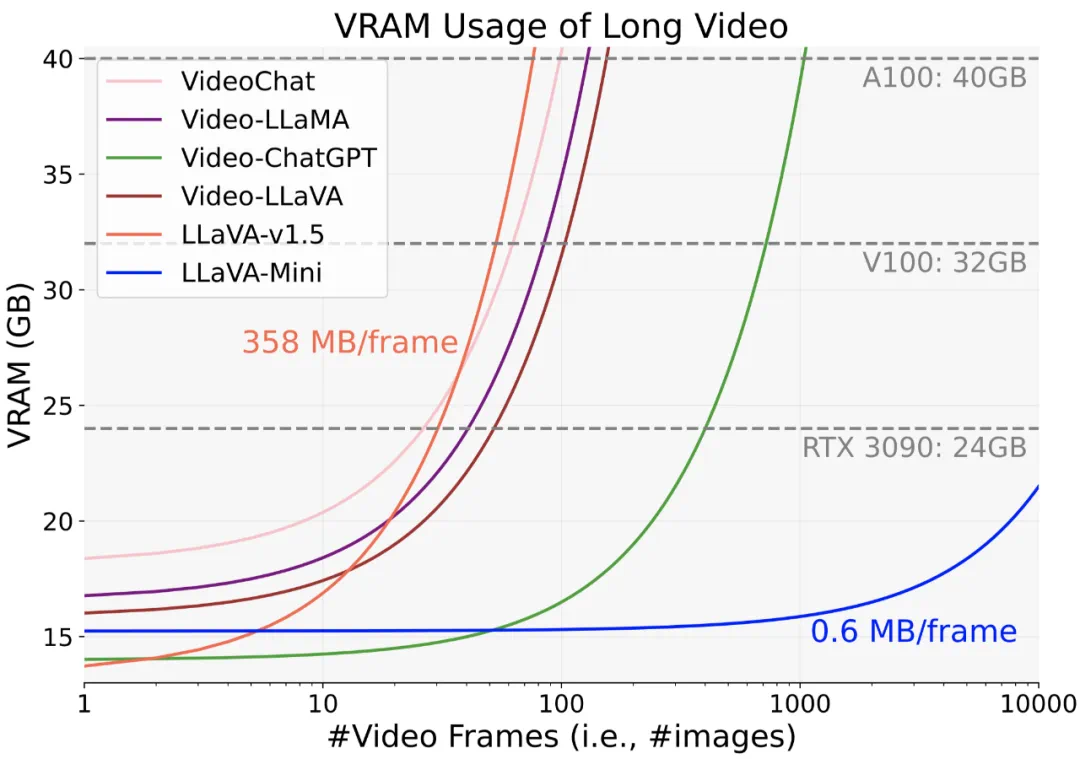
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。然而,庞大的视觉 token(vision token)量显著增加了 LMMs 的计算复杂度和推理延迟,尤其在高分辨率图像或视频处理的场景下,效率问题愈加突出。因此,提高多模态大模型的计算效率成为实现低延时实时交互的核心挑战之一。


-
论文题目:LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token -
论文链接:https://arxiv.org/abs/2501.03895 -
开源代码:https://github.com/ictnlp/LLaVA-Mini -
模型下载:https://huggingface.co/ICTNLP/llava-mini-llama-3.1-8b