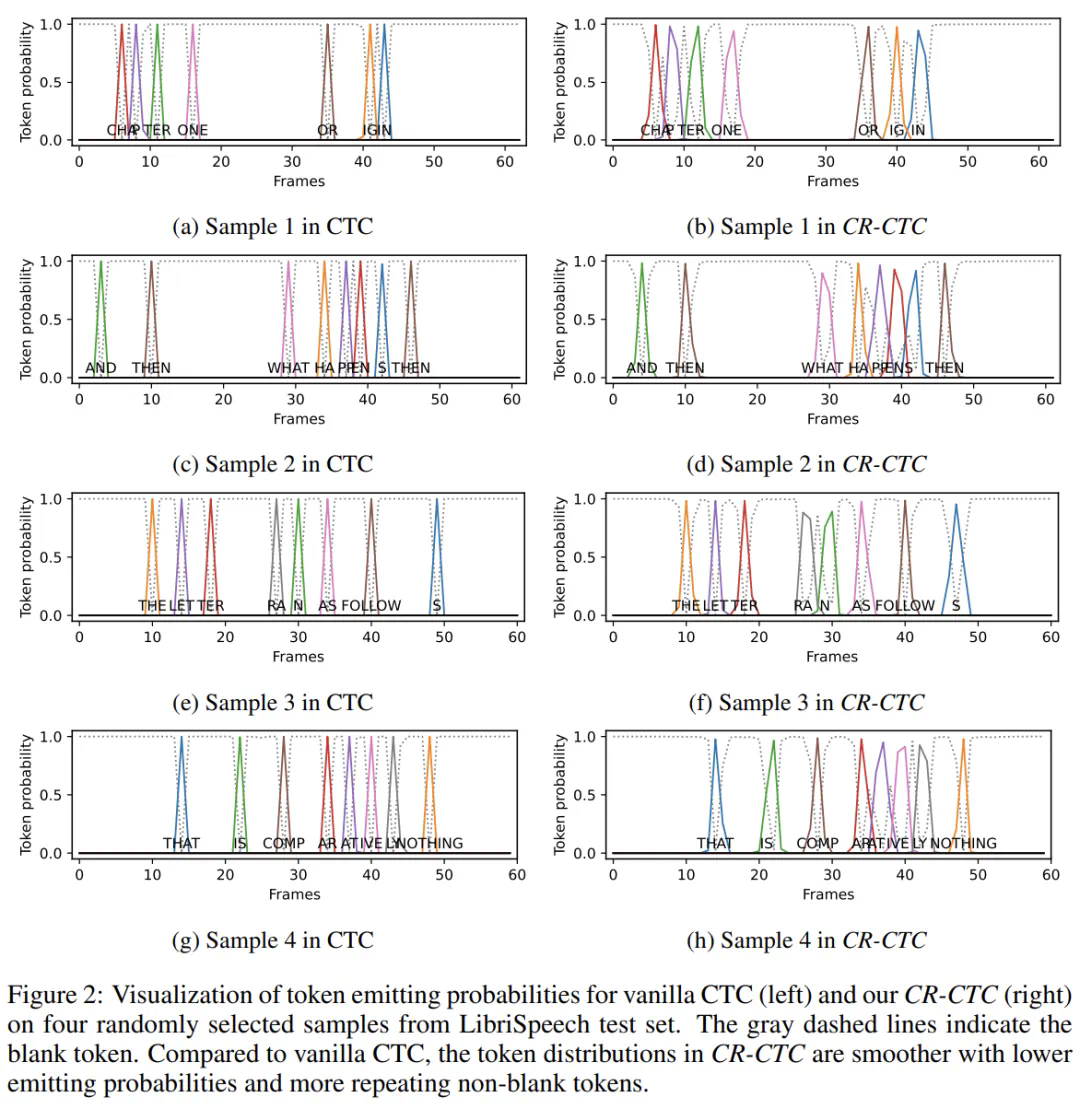
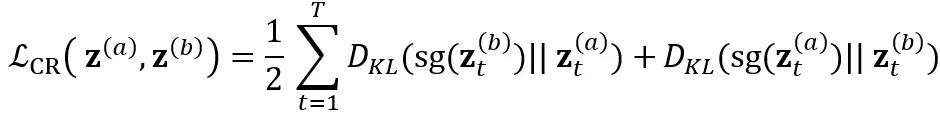文章来源于互联网:ICLR 2025|小米新一代Kaldi语音识别算法CR-CTC,纯CTC性能实现SOTA

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
新一代 Kaldi 团队是由 Kaldi 之父、IEEE fellow、小米集团首席语音科学家 Daniel Povey 领衔的团队,专注于开源语音基础引擎研发,从神经网络声学编码器、损失函数、优化器和解码器等各方面重构语音技术链路,旨在提高智能语音任务的准确率和效率。
目前,新一代 Kaldi 项目 (https://github.com/k2-fsa)主要由四个子项目构成:核心算法库 k2、通用语音数据处理工具包 Lhotse、解决方案集合 Icefall 以及服务端引擎 Sherpa,方便开发者轻松训练、部署自己的智能语音模型。
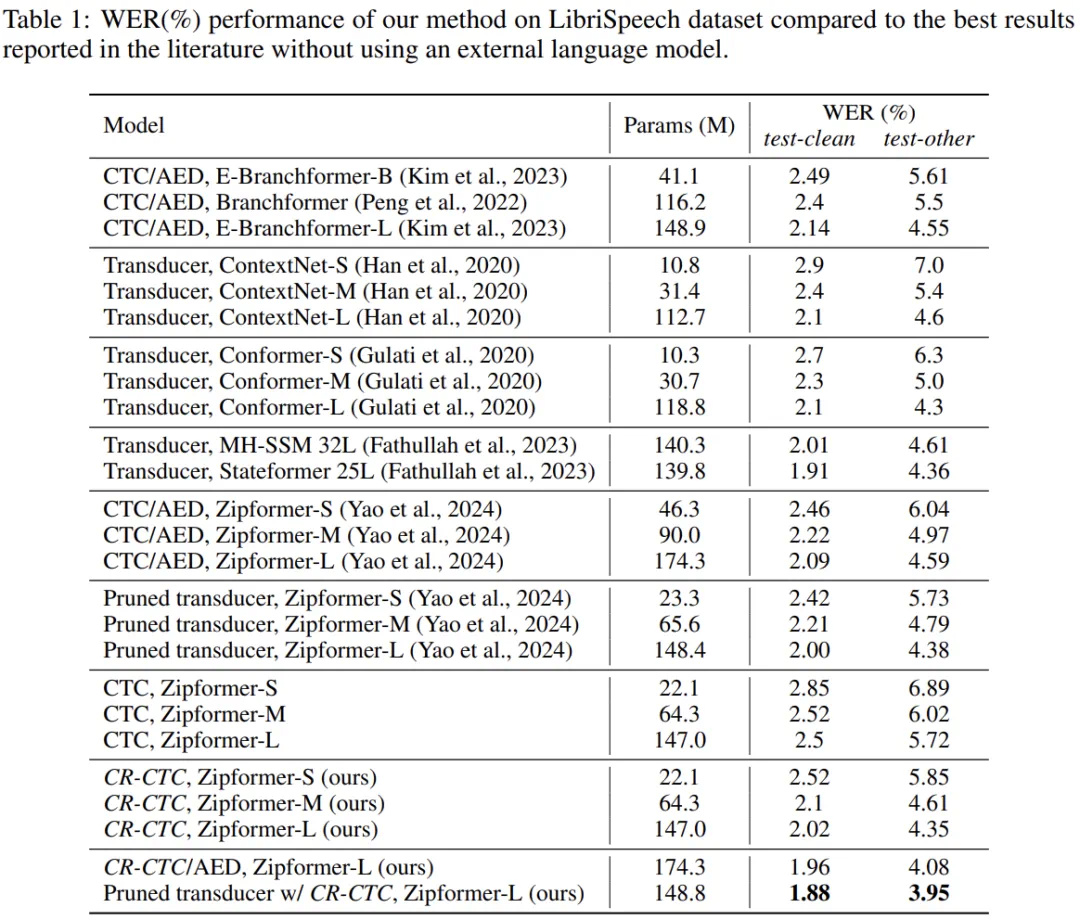
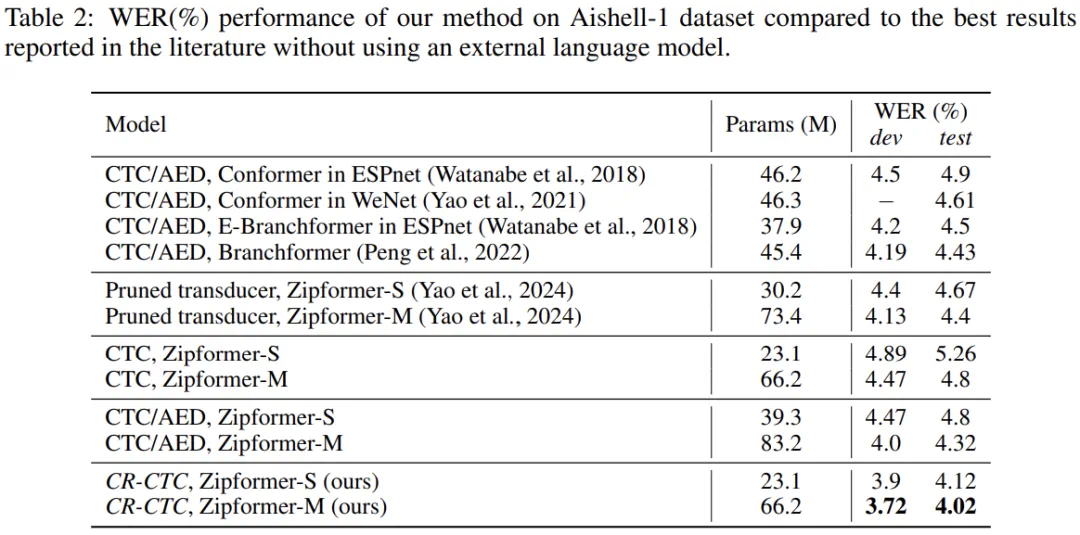
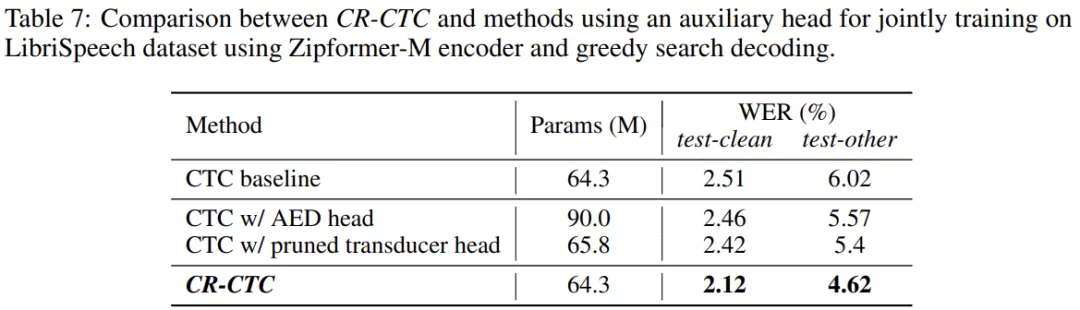
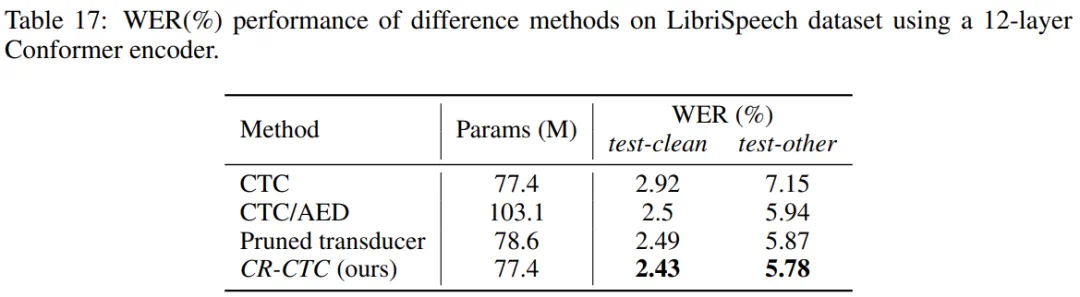
近日,小米集团新一代 Kaldi 团队关于语音识别算法的论文《CR-CTC: Consistency regularization on CTC for improved speech recognition》被 ICLR 2025 接收。

-
论文链接:https://arxiv.org/pdf/2410.05101 -
论文代码:https://github.com/k2-fsa/icefall/pull/1766(已 merge 进 icefall 框架)

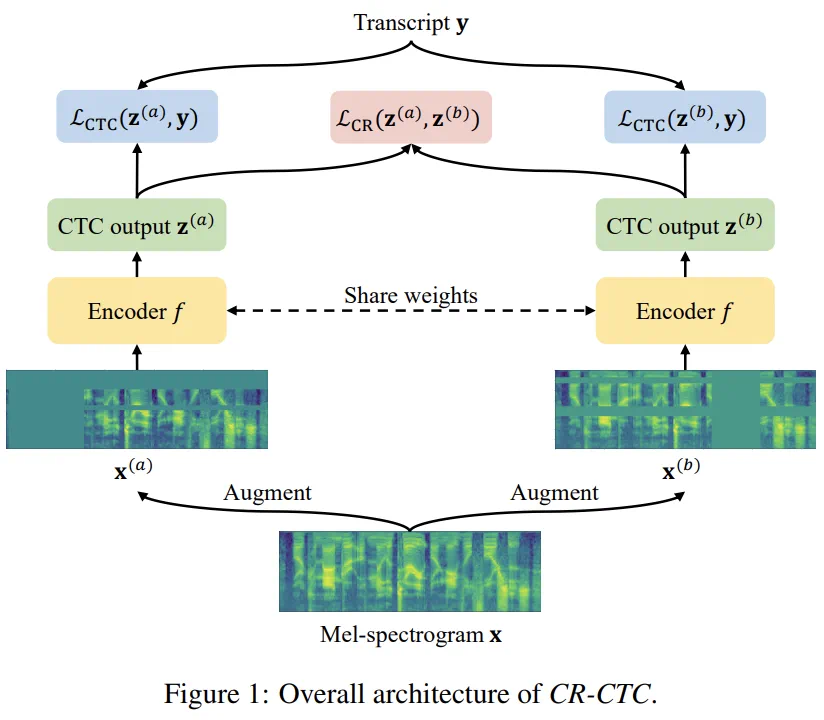
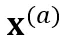 和
和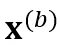 ,分别输入参数共享的 encoder 模型 f,得到对应的两个 CTC 概率分布
,分别输入参数共享的 encoder 模型 f,得到对应的两个 CTC 概率分布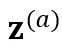 和
和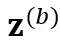 ,除了计算两个 CTC loss
,除了计算两个 CTC loss 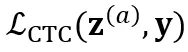 和
和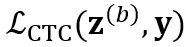 ,还引入 consistency regularization loss 来约束两个分布的一致性:
,还引入 consistency regularization loss 来约束两个分布的一致性: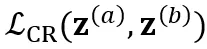 。系统总体 loss 为:
。系统总体 loss 为: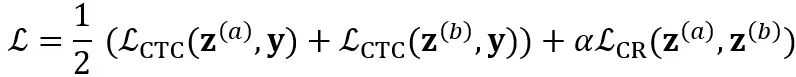
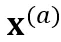 和
和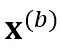 。SpecAugment 包含 time warping、frequency masking 和 time masking。由于 time warping 会显著改变输出的时间戳,因此我们在创建 copy 前先应用 time warping,防止两个分支的输出分布在时间戳上严重不匹配。接着,分别对两个 copy 独立应用 frequency masking 和 time masking,得到了
。SpecAugment 包含 time warping、frequency masking 和 time masking。由于 time warping 会显著改变输出的时间戳,因此我们在创建 copy 前先应用 time warping,防止两个分支的输出分布在时间戳上严重不匹配。接着,分别对两个 copy 独立应用 frequency masking 和 time masking,得到了 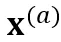 和
和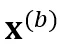 。相较于普通的 ASR 系统,我们特意使用了更大程度的 time masking。
。相较于普通的 ASR 系统,我们特意使用了更大程度的 time masking。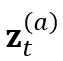 和
和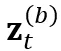 之间的双向 KL 散度:
之间的双向 KL 散度: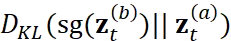 和
和 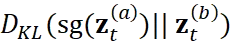 。此处,sg 表示 stop-gradient,防止这一项的梯度影响目标分布。Consistency regularization loss 公式为:
。此处,sg 表示 stop-gradient,防止这一项的梯度影响目标分布。Consistency regularization loss 公式为: