文章来源于互联网:817样本激发7倍推理性能:上交大「少即是多」定律挑战RL Scaling范式
在追求人工智能极限的道路上,”更大即更强” 似乎已成为共识。特别是在数学推理这一被视为 AI 终极挑战的领域,业界普遍认为需要海量数据和复杂的强化学习才能获得突破。然而,来自上海交通大学的最新研究却给出了一个令人震惊的答案:仅需 817 条精心设计的样本,就能让模型在数学竞赛级别的题目上超越当前许多最先进模型。这一发现不仅挑战了传统认知,更揭示了一个可能被我们忽视的事实:大模型的数学能力或许一直都在,关键在于如何唤醒它。

-
论文标题:LIMO: Less is More for Reasoning
-
论文地址:https://arxiv.org/pdf/2502.03387
-
代码地址:https://github.com/GAIR-NLP/LIMO
-
数据集地址:https://huggingface.co/datasets/GAIR/LIMO
-
模型地址:https://huggingface.co/GAIR/LIMO
继 OpenAI 推出 o1 系列、打响推理能力竞赛的第一枪后,DeepSeek-R1 以惊人的数学推理能力震撼业界,引发全球复现狂潮。各大公司和研究机构纷纷遵循同一范式:用更庞大的数据集,结合更复杂的强化学习(RL)算法,试图 “教会” 模型如何推理。
如果把经过充分预训练的大语言模型比作一名天赋异禀的学生,那么主流的 RL Scaling 方法就像是不停地训练、奖惩这位学生,直到他能解出各种复杂数学题。这一策略无疑带来了显著成效 —— 从 Claude 到 GPT-4,从 o1-preview 到 DeepSeek-R1,每一次性能跃升的背后,都是训练数据规模的指数级增长和强化学习算法的持续优化。
然而,在这场看似无休止的数据竞赛中,上海交通大学的研究团队却提出了一个发人深省的问题:如果这位 “学生” 在预训练阶段已掌握了所有必要的知识,我们真的需要庞大数据集来重新训练他吗?还是只需精妙的引导,就能激活他的潜在能力?
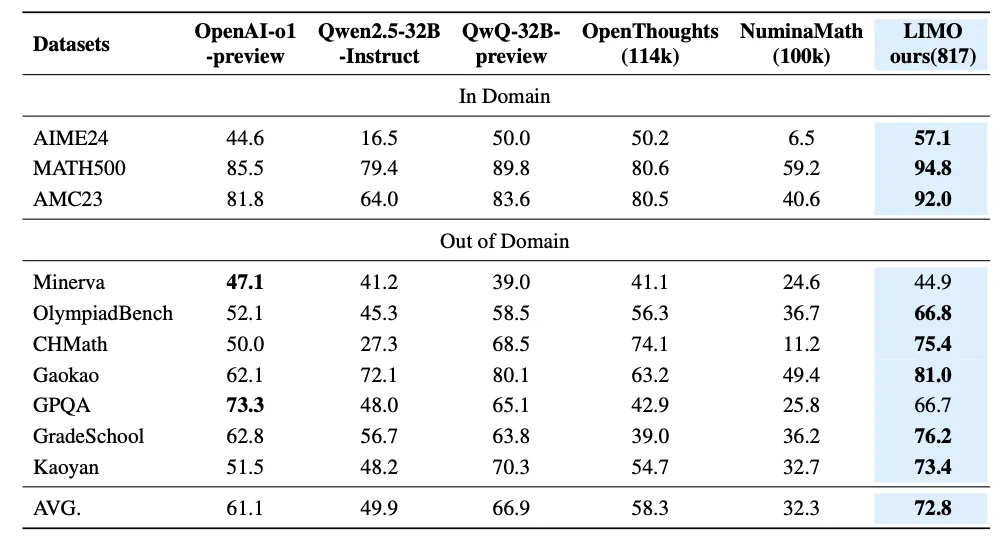
他们的最新研究 LIMO(Less Is More for Reasoning)给出了令人震撼的答案:仅用 817 条精心设计的训练样本,借助简单的监督微调,LIMO 就全面超越了使用十万量级数据训练的主流模型,包括 o1-preview 和 QwQ 等顶级选手。这一 “少即是多” 的现象,不仅挑战了 “更大数据 = 更强推理” 的传统认知,更揭示了一个可能被忽视的事实:在 AI 推理能力的突破中,方向可能比力量更重要。
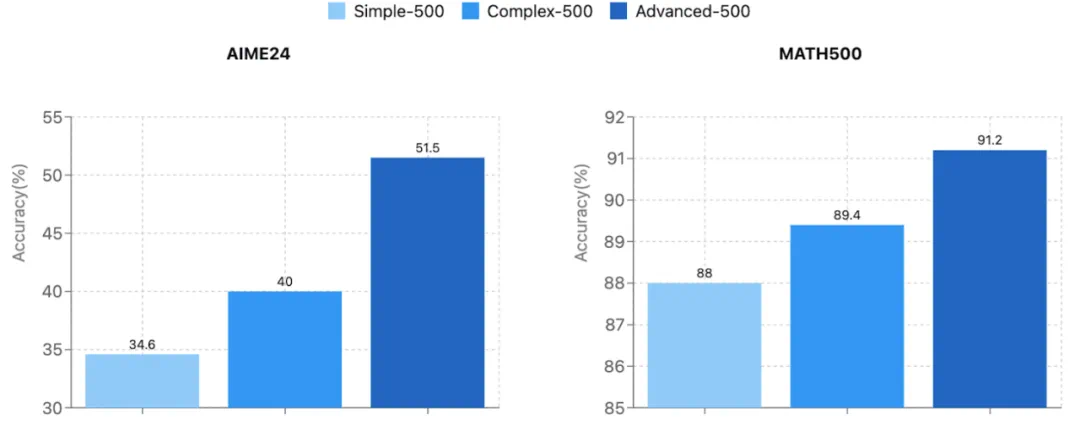
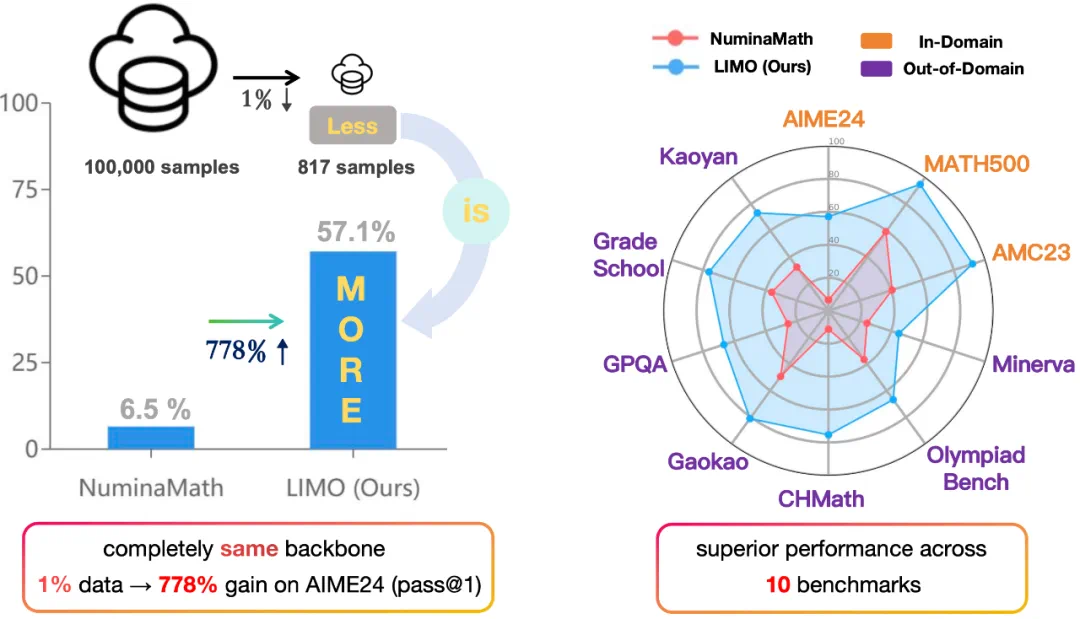
实验结果无可辩驳地印证了这一点。在竞赛级别的美国数学竞赛邀请赛(AIME) 测试中,相比传统方法(以 Numina-Math 为例),LIMO 的准确率从 6.5% 飙升至 57.1%。更令人惊讶的是 LIMO 的泛化能力:在 10 个不同的基准测试上,它实现了 40.5% 的绝对性能提升,超越了使用 100 倍数据训练的模型。这一突破直接挑战了 “监督式微调主要导致记忆而非泛化” 的传统观点,证明了高质量、小规模的数据,远比低效的海量训练更能激发 LLM 的真正推理能力。

-
第一,知识基础革命(Knowledge Foundation Revolution)。近年来,大模型在预训练阶段已纳入海量数学知识。例如,比起全领域训练数据只有 1.8T 的 Llama2,Llama 3 仅在数学推理上的训练数据就高达 3.7 万亿 token,这意味着现代 LLM 早已 “知道” 大量数学知识,关键是如何 “唤醒” 它们。
-
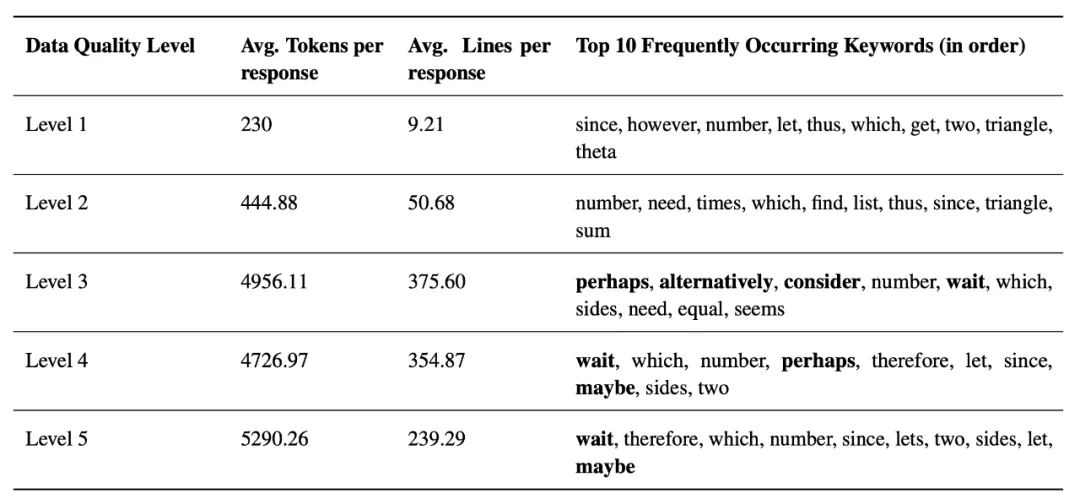
第二,推理计算革命(Inference-time Computation Scaling Revolution)。最新研究表明,推理链(chain-of-thought, CoT)的长度,与模型的推理能力密切相关。与其在训练阶段硬灌大规模监督数据,不如在推理阶段提供更优质的问题和示范,让模型自主展开深入思考。
在知识基础已足够完善的情况下,仅需少量高质量示例,就能通过推理链激活模型的潜在推理能力,而无需海量数据。
强化学习扩展(RL Scaling)
以 OpenAI 的 o1 系列和 DeepSeek-R1 为例,RL Scaling 方法通常试图通过大规模的强化学习训练来增强模型的推理能力。这种方法通常依赖于海量数据及复杂的算法,虽然在某些任务上取得了显著成效,但亦有局限:它将推理能力的提升视为一个需要大量计算资源的“搜索”过程。
LIMO 的新视角
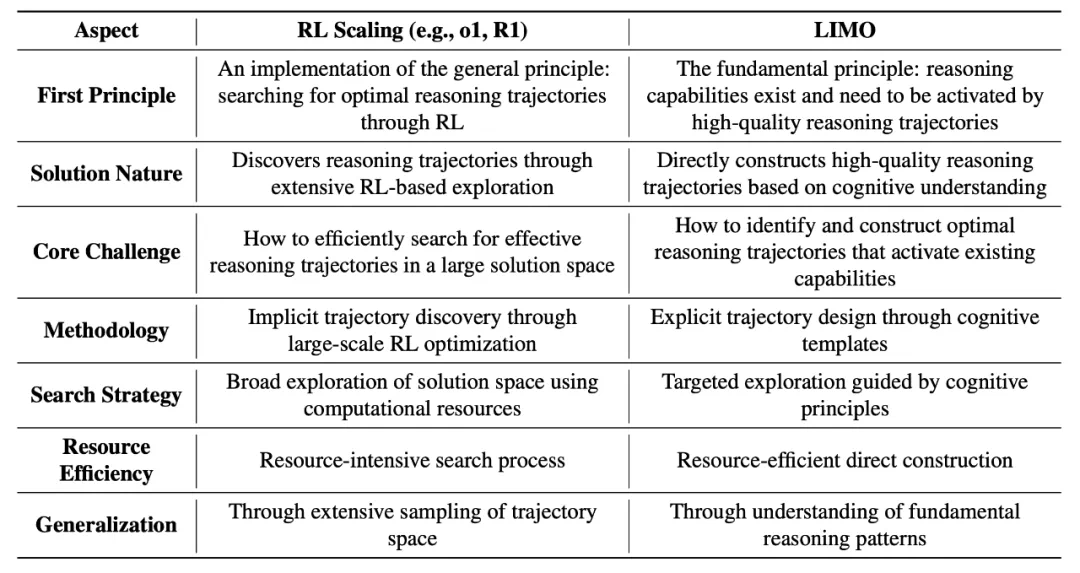
与之相对,LIMO(Less Is More for Reasoning)提出了一个不同的理论框架,认为推理能力潜藏于预训练模型中,关键在于如何通过精确的认知模板来激发这些内在能力。这一转变将研究重点从“训练新能力”转向“激活潜在能力”,强调了方向的重要性。
LIMO 的核心假设是,在知识基础已经足够完善的情况下,利用少量高质量的示例就能够激活模型的潜在推理能力。这一理论不仅重新定义了 RL Scaling 的位置,将其视为寻找最优推理轨迹的一种手段,更为整个领域的研究提供了新的思考框架。
研究意义
在当下,以 DeepSeek-R1 为代表的 RL Scaling 方法逐渐成为主流,LIMO 研究的意义则在于提供了一个更加本质的视角:大模型的推理能力本身是内在存在的,关键挑战在于如何找到最优的激活路径。
这一洞察不仅重新定义了 RL Scaling,将其视为寻找最优推理轨迹的一种实现方式,更重要的是,它引领了一种全新的研究范式——从“训练新能力”转向“激活潜在能力”。这一转变不仅加深了我们对大模型推理能力的理解,也为更高效的能力激活方法提供了明确的方向。
LIMO 和 RL Scaling 的对比,揭示了推理能力提升的不同路径与思路。LIMO 提供了更为根本的理解,指明了未来研究的方向:不再是无止境的数据堆砌,而是更加关注如何有效激活模型本就具备的能力。