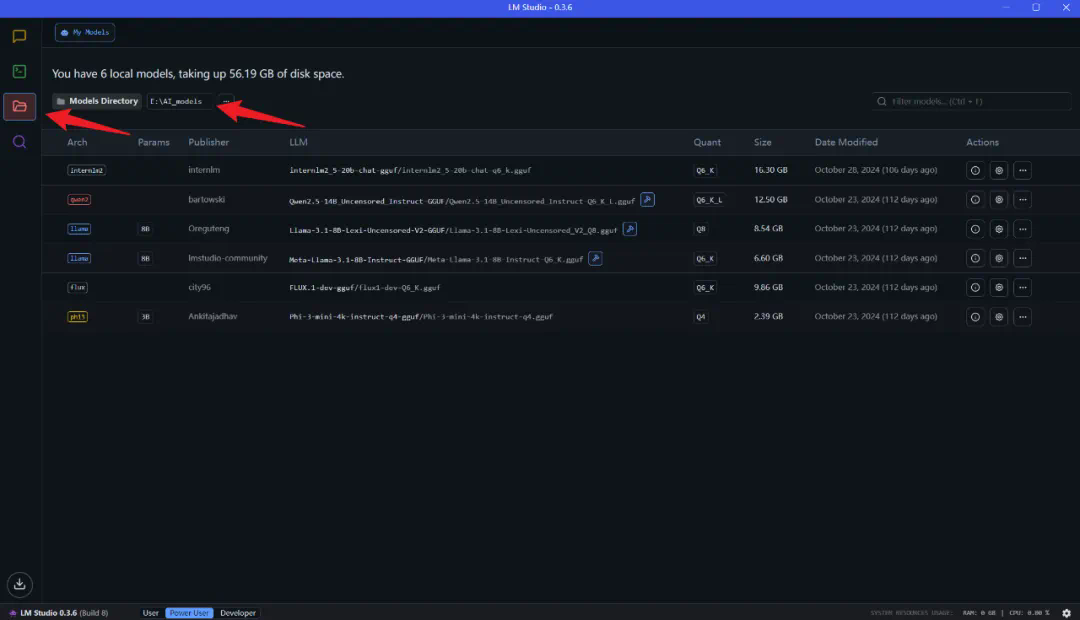
文章来源于互联网:淘宝卖DeepSeek安装包一月赚数十万???我们免费教你本地部署DeepSeek-R1


-
轻量级本地推理:在个人电脑或移动端运行(如 Llama.cpp、Whisper、GGUF 格式模型)。 -
服务器 / 工作站部署:使用高性能 GPU 或 TPU(如英伟达 RTX 4090、A100)运行大模型。 -
私有云 / 内网服务器:在企业内部服务器上部署(如使用 TensorRT、ONNX Runtime、vLLM)。 -
边缘设备:在嵌入式设备或 IoT 设备上运行 AI(如 Jetson Nano、树莓派)。
-
企业内部 AI(如私有聊天机器人、文档分析); -
科研计算(如生物医药、物理仿真); -
离线 AI 功能(如语音识别、OCR、图像处理); -
安全审计 & 监控(如法律、金融合规分析)。
-
数据隐私与安全性:在本地部署 AI 模型时,就无需将自己的关键数据上传到云端,从而可以有效防止数据泄露,这对金融、医疗、法律等行业而言尤为关键。另外,本地部署也能有效符合企业或地区的数据合规要求(如中国的《数据安全法》、欧盟的 GDPR 等)。 -
低延迟 & 高实时性能:由于本地部署时所有计算都发生在本地,无需网络请求,因此推理速度完全取决于用户自己的设备计算性能。但也因此,只要本地设备性能足够,用户就能享受到非常好的实时性能,也因此本地部署非常适合实时性非常关键的应用(如语音识别、自动驾驶、工业检测)。 -
更低的长期成本:本地部署自然就无需 API 订阅费用,可实现一次部署长期使用。同时,如果用户对模型性能要求不高,还能通过部署轻量化模型(如 INT 8 或 4-bit 量化)来控制硬件成本。 -
可以离线使用:无需网络也能用上 AI 模型,适用于边缘计算、离线办公、远程环境等。并且,由于断网也能运行 AI 应用,因此可以保证用户的关键业务不中断。 -
可定制 & 可控性强:可以微调、优化模型,更适配业务需求,举个例子,DeepSeek-R1 就被微调和蒸馏成了许多不同的版本,包括无限制版本 deepseek-r1-abliterated 等等。另外,本地部署不受第三方政策变更影响,可控性强,可避免 API 调价或访问限制。
-
硬件成本高:个人用户的本地设备通常难以运行高参数量的模型,而参数量较低的模型的性能通常又更差,因此这方面有一个需要考虑的权衡。如果用户想要运行高性能模型,那就必须在硬件上投入更多成本。 -
难以处理大规模任务:当用户的任务需要大规模处理数据时,往往需要服务器规模的硬件才能有效完成。 -
有一定的部署门槛:不同于使用云服务 —— 只需打开网页端或配置 API 即可使用,本地部署存在一定的技术门槛。如果用户还有进一步的本地微调需求,部署难度还会更大。不过幸运的是,这个门槛正越来越低。 -
需要一定的维护成本:用户需要投入心力和时间解决因为模型和工具升级带来的环境配置问题。
-
适合本地部署:高隐私、低延迟、长期使用(如企业 AI 助手、法律分析)。 -
不适合本地部署:短期试验、高算力需求、依赖大模型(如 70B+ 参数级别)。

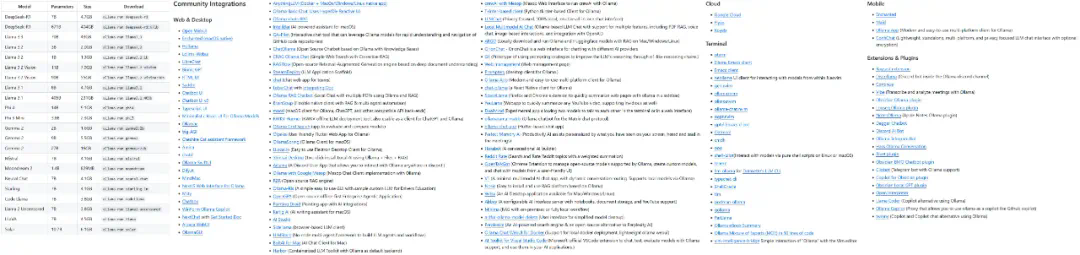
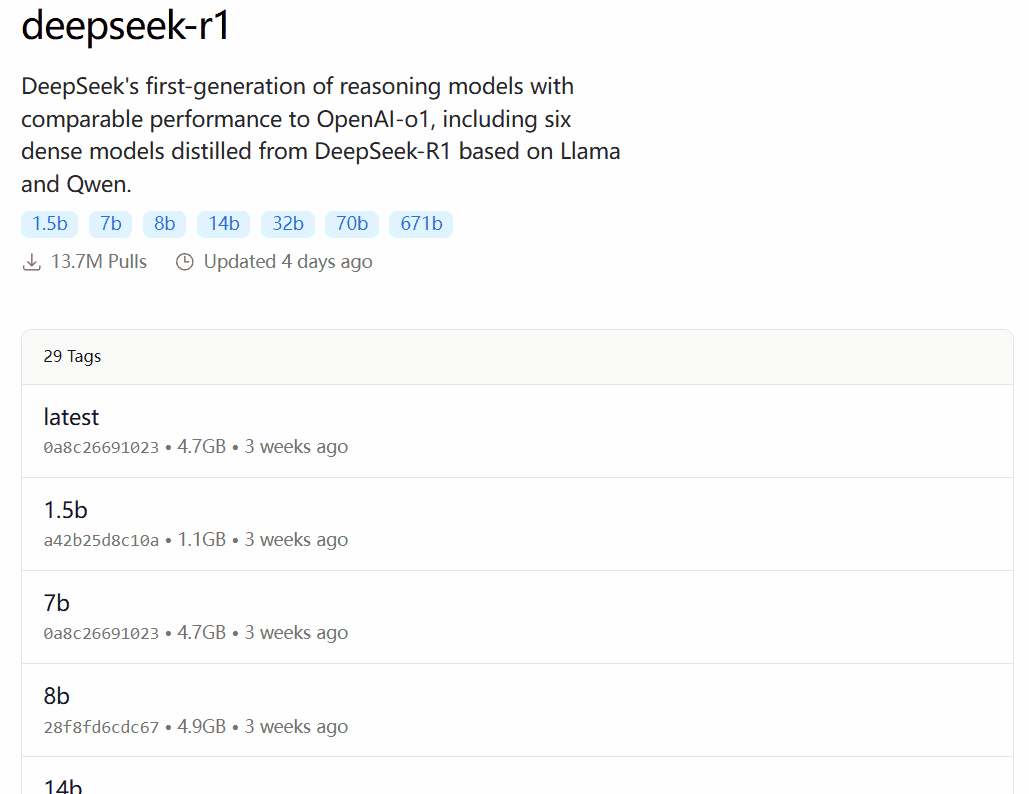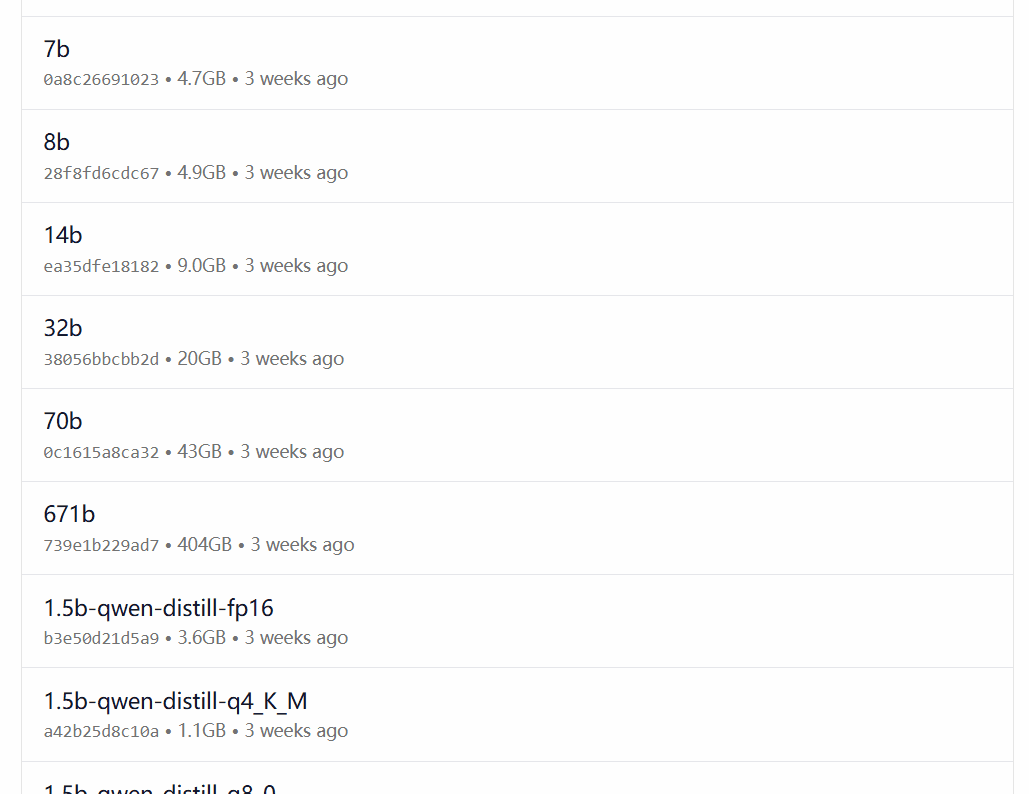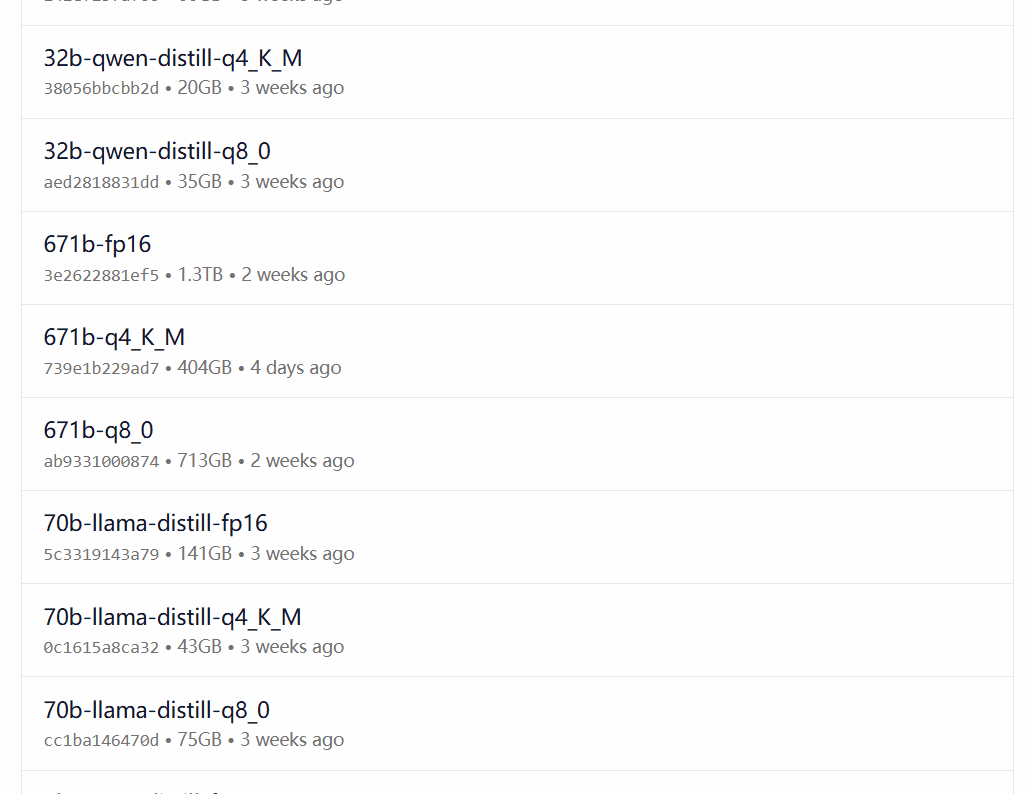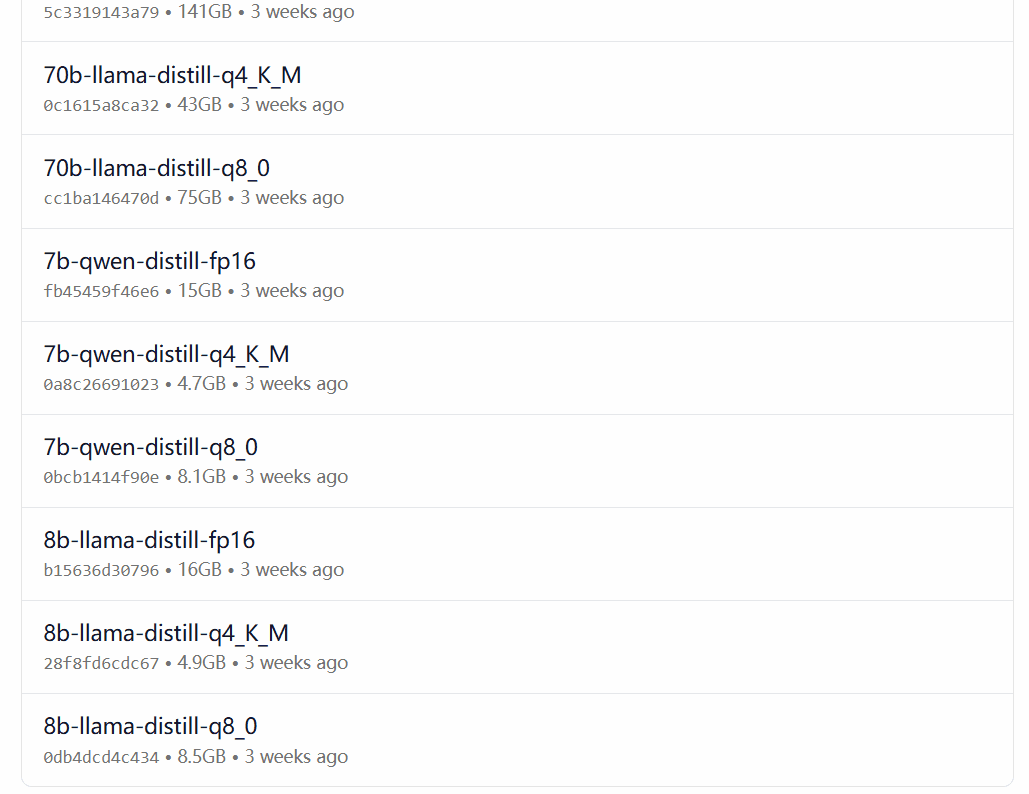
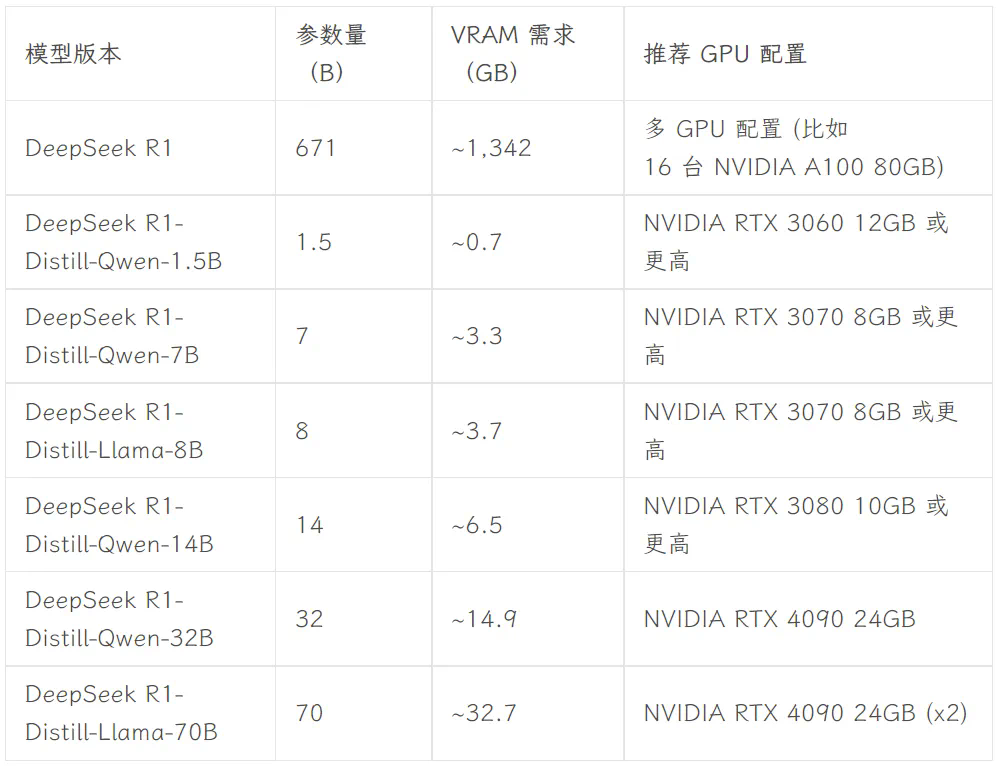
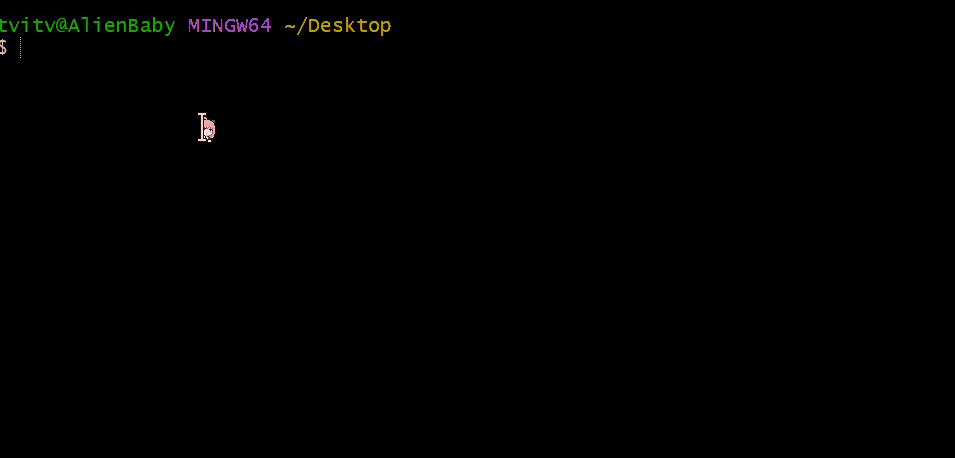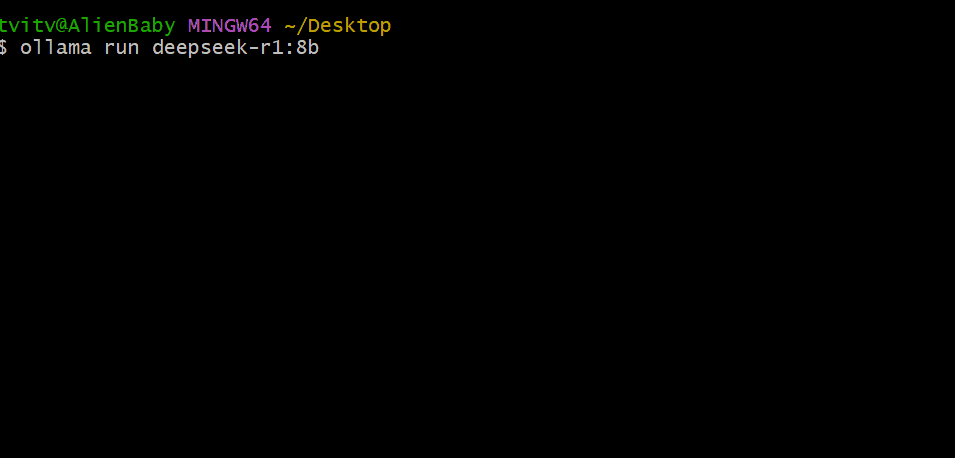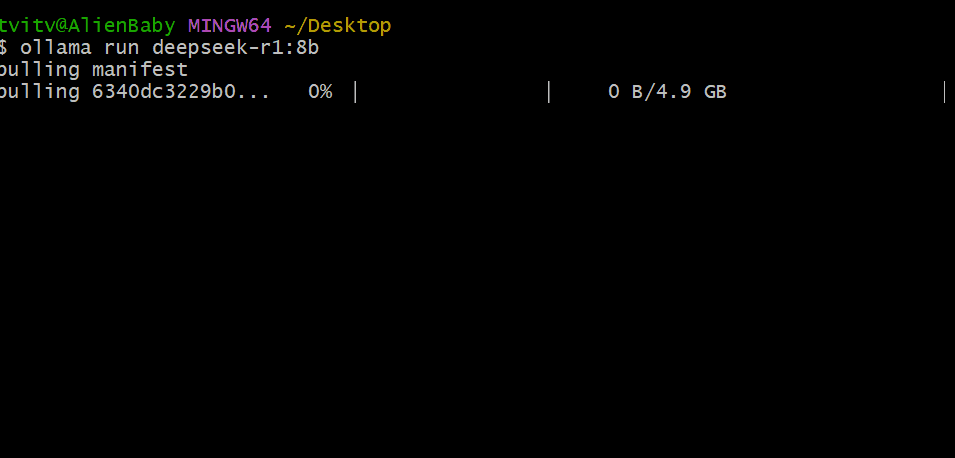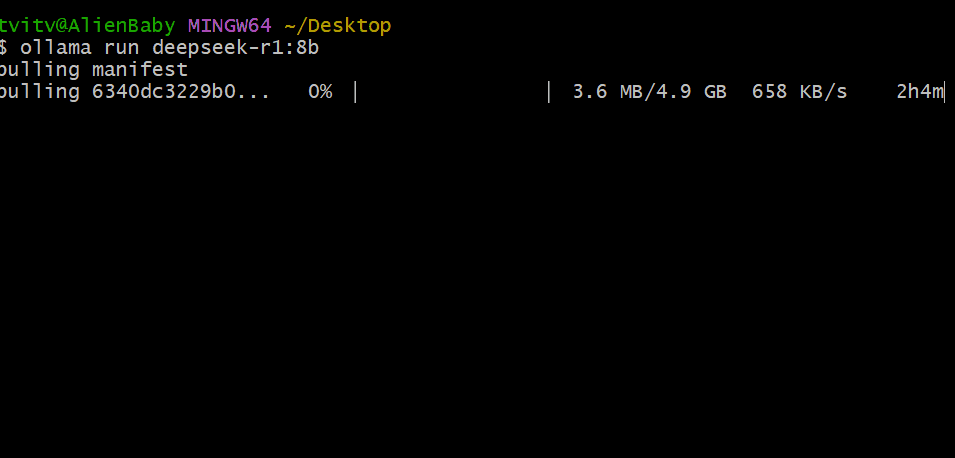
ollama run deepseek-r1:8b

pip install open-webui
open-webui serve