文章来源于互联网:DeepSeek的MLA,任意大模型都能轻松迁移了

复旦 NLP 实验室博士后纪焘是这篇文章的第一作者,研究方向为大模型高效推理、多模态大模型,近期代表工作为首个NoPE外推HeadScale、注意力分块外推LongHeads、多视觉专家大模型MouSi,发表ACL、ICLR、EMNLP等顶会顶刊论文 20 余篇。
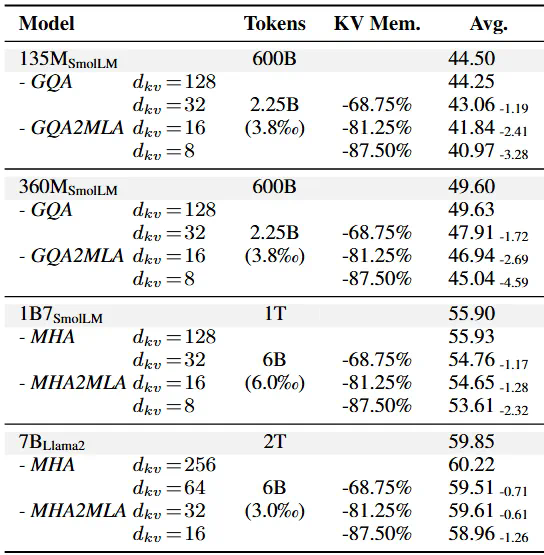
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。
然而,现有主流大模型仍然基于标准注意力架构及其变种(e.g., MHA, GQA, MQA),推理成本相比 MLA 呈现显著劣势。使预训练的任意 LLMs 快速迁移至 MLA 架构而无需从头预训练,这既有重大意义又具有挑战性。
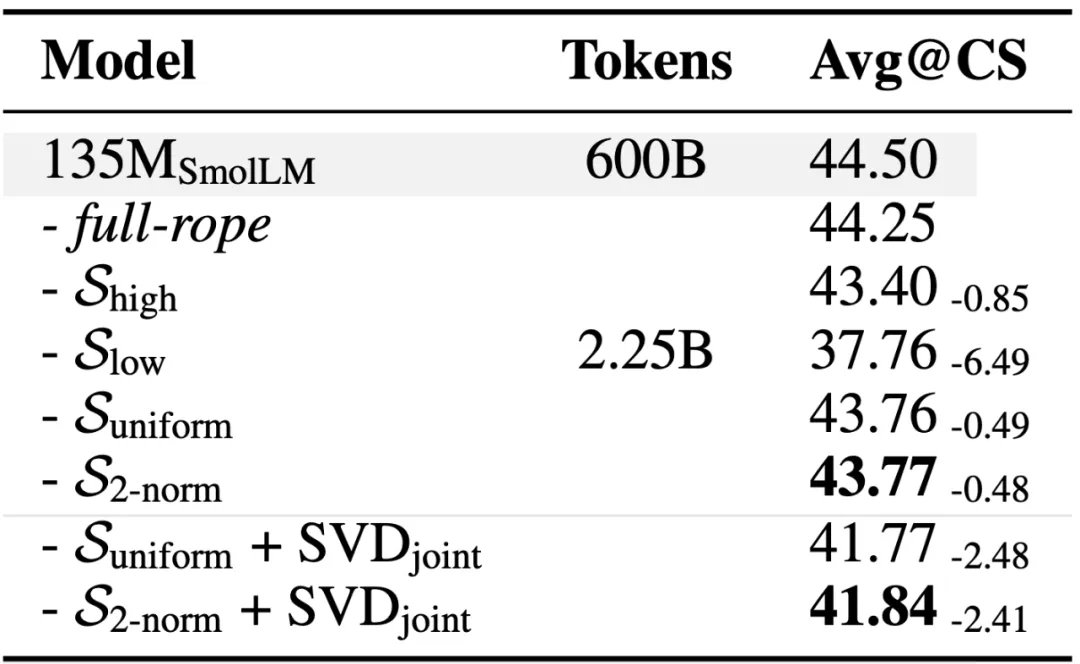
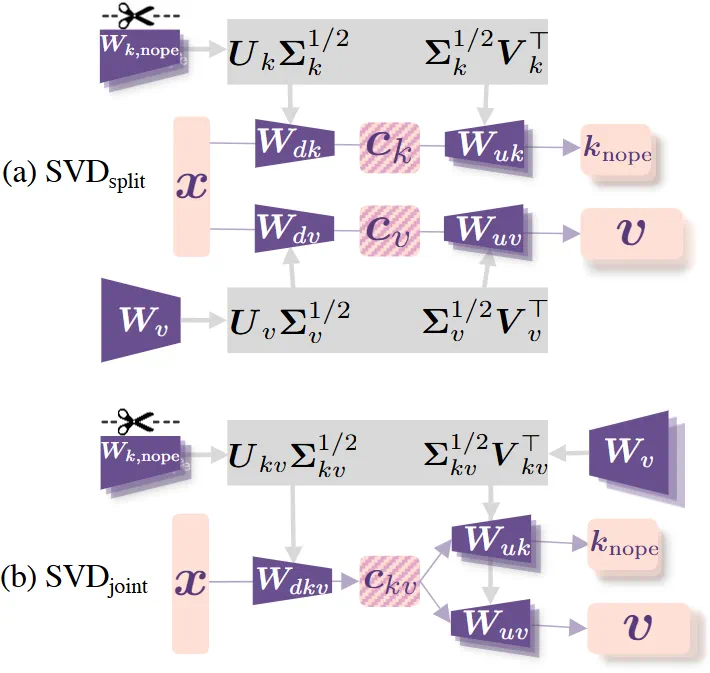
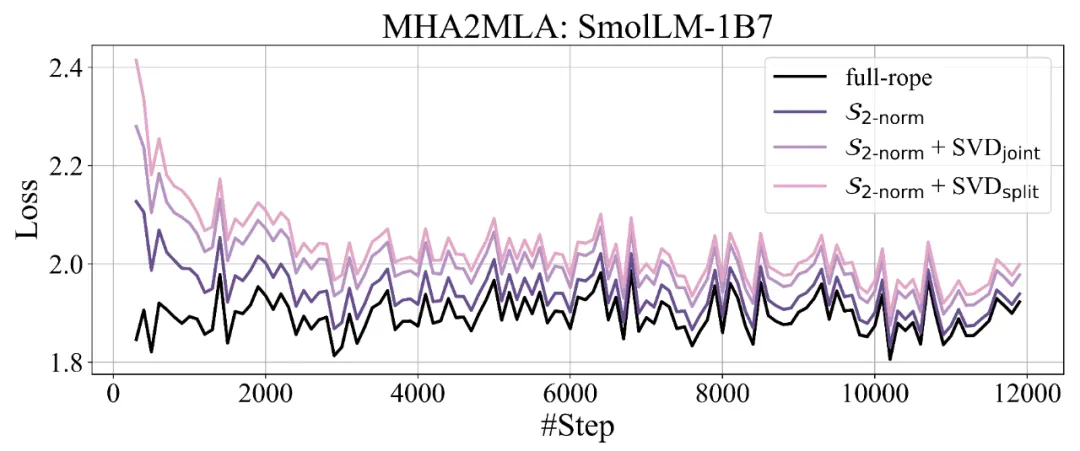
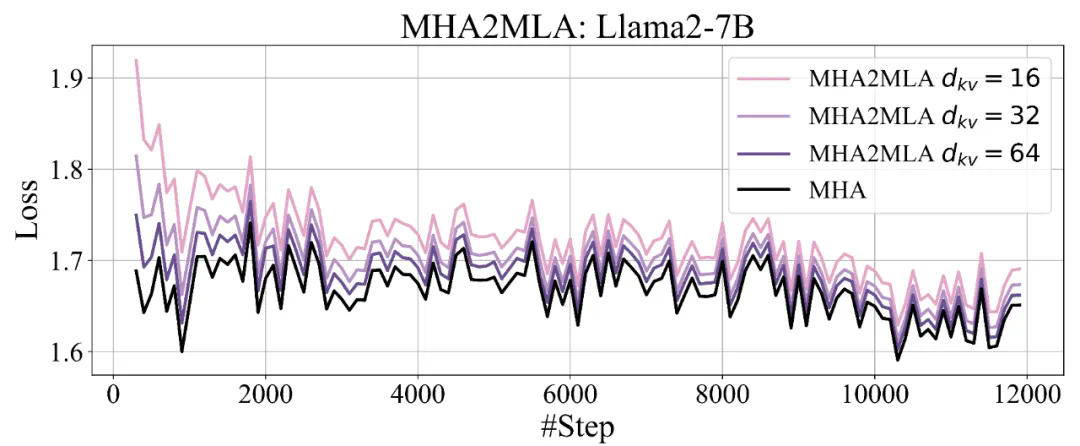
复旦 NLP 实验室、华东师大、上海 AI Lab、海康威视联合提出 MHA2MLA 框架,通过部分 RoPE 保留(Partial-RoPE)和键值联合表示低秩近似(Low-rank Approximation)两个关键步骤,成功将任意 MHA/GQA 架构迁移到 MLA。


-
论文标题:Towards Economical Inference: Enabling DeepSeek’s Multi-Head Latent Attention in Any Transformer-based LLMs -
论文链接:https://arxiv.org/abs/2502.14837 -
开源代码:https://github.com/JT-Ushio/MHA2MLA
-
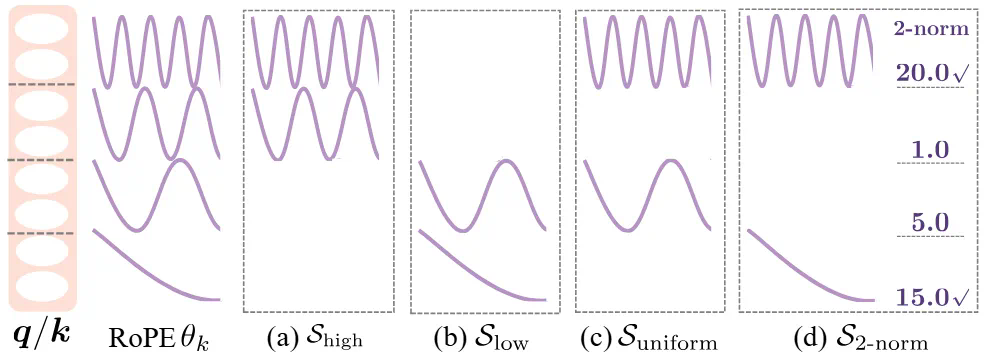
位置编码不同:MHA 采用全维度位置编码(PE),MLA 仅少量维度采用 PE,剩余维度则 PE 无关 -
缓存对象不同:MHA 缓存分离的键向量及值向量,MLA 缓存带 PE 的键向量及 PE 无关的键值联合低维表示向量 -
参数矩阵不同:MHA 包含查询、键、值三个线性变换矩阵,MLA 则更加复杂、多达七个目的不同的线性变换矩阵 -
运算形式不同:MHA 的运算受限于访存瓶颈,MLA 则能通过矩阵吸收等优化实现更高的访存效率



文章来源于互联网:DeepSeek的MLA,任意大模型都能轻松迁移了
