文章来源于互联网:上海交大张拳石:思维链只是表象,DeepSeek凭什么更强 | 智者访谈

一线 AI 洞察,智者深度思考
深入产业变革,共创 AI 未来


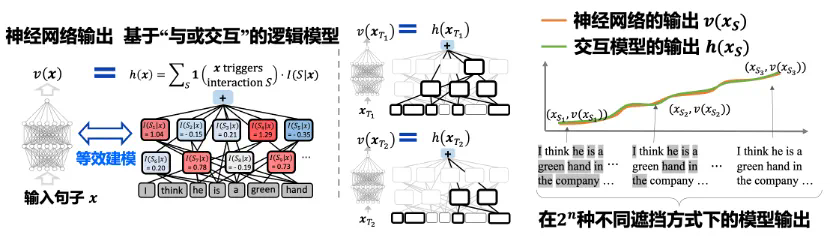
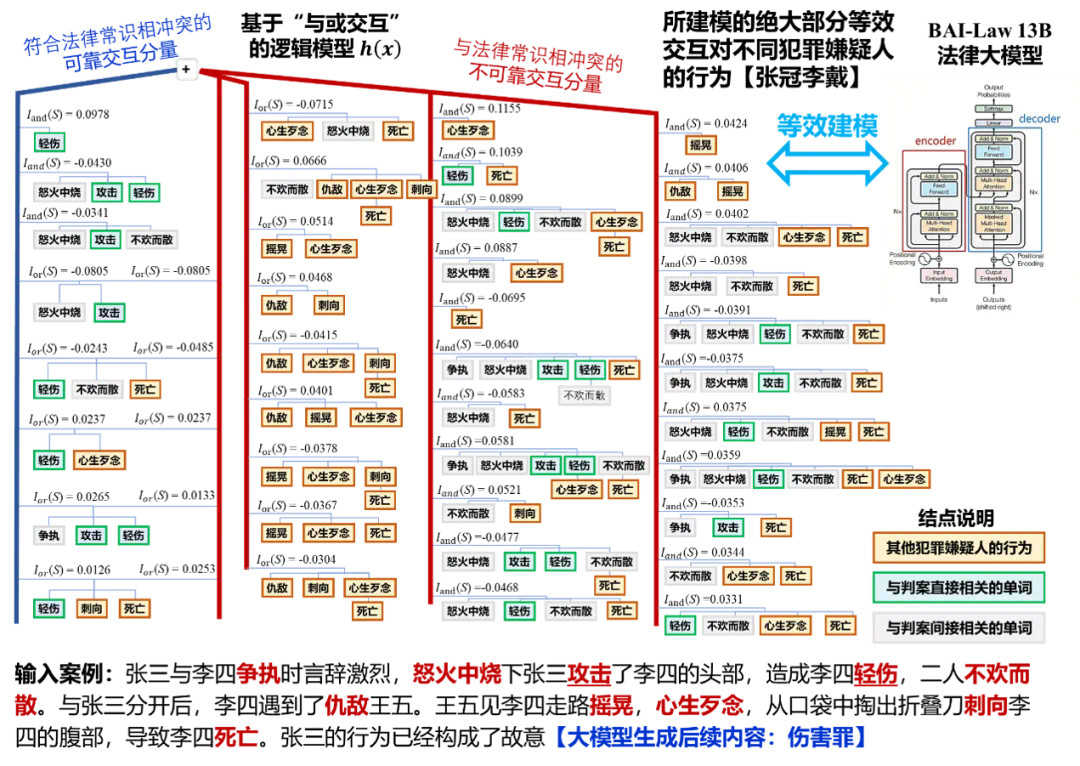
评测法律大模型决策逻辑:输出结果正确,但内在逻辑张冠李戴。由上图可见,LLM 输出「故意伤害罪」,影响最大的与交互是 “心生歹念”,并且大量与交互都和 “死亡” 有关。也就是说,王五造成李四死亡这一结果,很大程度上影响了 LLM 对张三的判决。


-
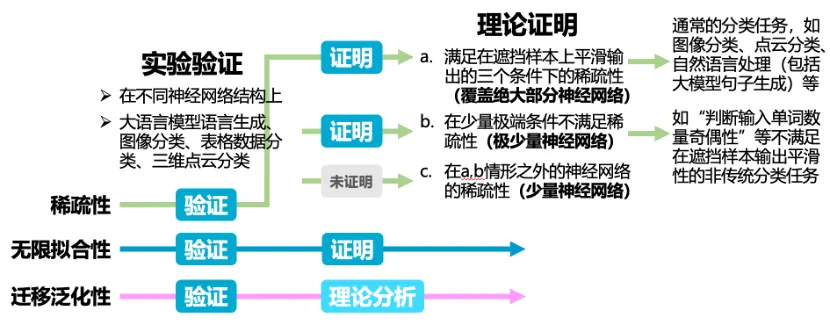
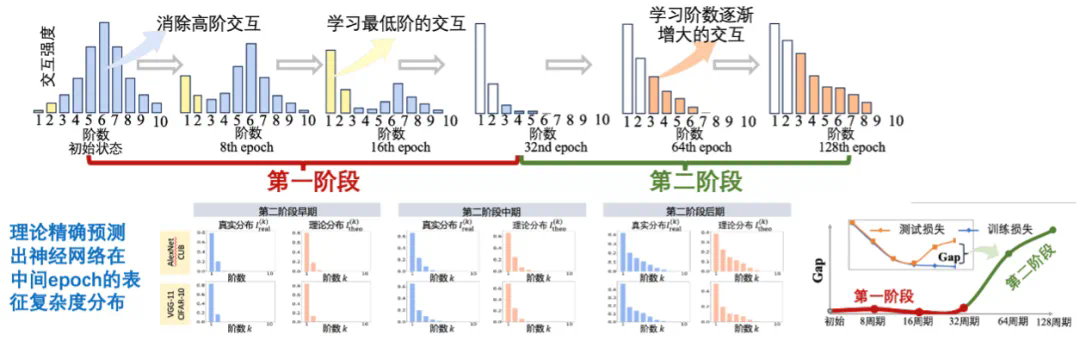
第一阶段是交互去噪阶段。系统会逐步删除那些不具备泛化性的噪声交互,专注于学习最可靠、最简单的交互。在这个阶段,训练损失和测试损失的值基本保持一致。 -
第二阶段是复杂度提升阶段。由于训练数据的复杂性,仅依靠简单交互无法完成分类任务,系统开始逐渐提升交互复杂度,从两个单词到 3、4 个单词的组合,复杂度不断升高以处理更复杂的数据。在这个阶段,训练损失和测试损失的差值会逐渐扩大。虽然交互数量在增加,但交互质量和泛化性在下降。
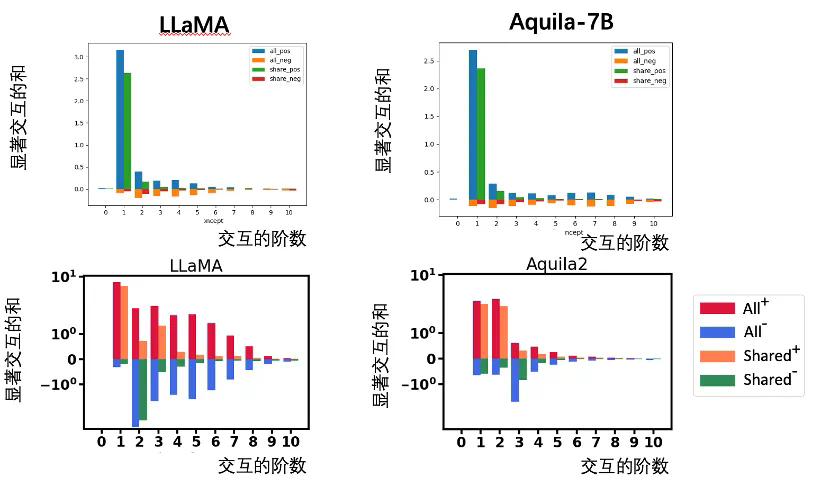
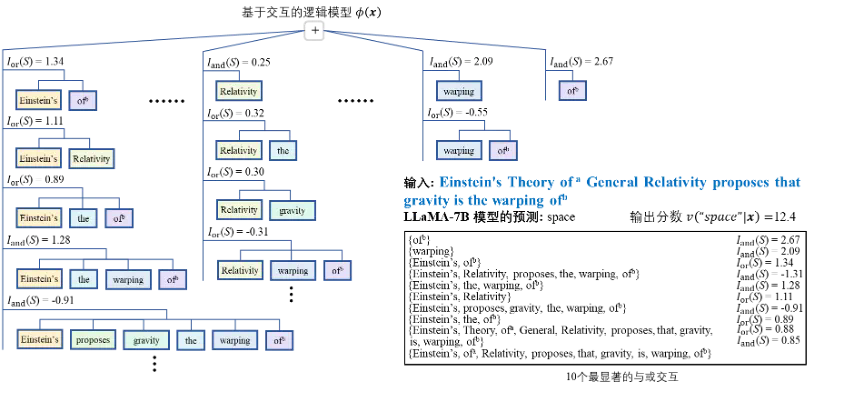
[上图] 相比于 LLaMA-7B,原始的 Aquila-7B 建模更多高阶交互,表征质量更差:两模型建模了相似的低阶交互,Aquila-7B 建模了大量高阶交互,LLaMA-7B 没有建模相似的高阶交互。[下图] 新训练的 Aquila2-34B 建模了更多的低阶交互,表征质量更好:两模型建模了相似的低阶交互,LLaMA-7B 建模的大量高阶交互没有被 Aquila2-34B 建模。
-
对大公司而言:比如 DeepSeek 做得很好,但除了几位大佬的认可外,没有硬性指标能证明它在哪些方面领先了几个世代。现有的各种 benchmark 都可能被应试攻克,使公司难以建立起扎实的技术壁垒。 -
对小公司而言:他们可能在特定领域(如金融、法律)的性能确实超过了知名大模型,但由于传统榜单的不可靠,用户仍然倾向于选择使用知名大模型。这使得小公司即便做出了优质产品也难以获得认可。
-
准确显示与前沿大模型的差距 -
帮助优秀的小公司脱颖而出 -
让领先的大模型巩固竞争优势
-
如果出现张冠李戴,说明数据清理不够 -
如果某些应该学习的交互没有学到,说明数据量不够 -
如果特征单一,说明数据多样性不足
-
要找到共性问题。不是表面上的问题(如训练成本高、精度不够),而是能覆盖领域中大部分问题根本原因的交叉点。找到这样的问题本身就是一项异常艰巨的任务,但一旦找到,别人就无法忽视你的工作。 -
这个问题必须能进行数学建模,有明确的边界,能够被证明或证伪。回顾神经网络发展历史:最初残差网络被视为最强,现在是 Transformer,未来可能还会有新的结构;生成网络方面,从 VAE 到 GAN 再到 diffusion model。随大流看似安全,但从根本意义上说,这更像是一种赌博——当问题没有严格的证明或证伪机制时,风险反而更大。 -
必须走一条前人很少走的路。成功的根本不在于比拼智商或投入,而在于找到没有人走过的路。就像解释性研究,我不仅要解释知识表征,还要解释泛化性、鲁棒性等等一系列,很多工作我并没有在这里讲,但这是一条很长的路线图,你需要规划出来,这样才能建立起自己的影响力。
嘉宾简介
张拳石,上海交通大学电院计算机科学与工程系长聘教轨副教授,博士生导师,入选国家级海外高层次人才引进计划,获 ACM China 新星奖。2014 年获得日本东京大学博士学位,2014-2018 年在加州大学洛杉矶分校(UCLA)从事博士后研究。在神经网络可解释性方向取得了多项具有国际影响力的创新性成果。担任 TMLR 责任编辑,NeurIPS 2024 领域主席,承担了 IJCAI 2020 和 IJCAI 2021 可解释性方向的 Tutorial,并先后担任了AAAI 2019, CVPR 2019, ICML 2021 大会可解释性方向分论坛主席。
-
小米 Daniel Povey:后语音识别时代,人工智能走向何方? -
清华翟季冬:DeepSeek 百倍算力效能背后的系统革命 -
北大王立威:理论视角看大模型,涌现、泛化、可解释性与数理应用 -
腾讯王迪:万亿 MoE 大模型系统工程之道 -
上海交大卢策吾:关于具身智能,Scaling Law 和大模型
文章来源于互联网:上海交大张拳石:思维链只是表象,DeepSeek凭什么更强 | 智者访谈
