跳至内容
让AI知识触手可及
首页
AI知识
AI资讯
AI问答
Search
搜索
登录/注册
首页
»
字节音效生成模型来了,一键生成大片感音效!已上线即梦
文章来源于互联网:
字节音效生成模型来了,一键生成大片感音效!已上线即梦
在 AIGC 持续突破视频生成边界的当下,音效制作仍是制约行业发展的瓶颈。字节跳动豆包大模型语音团队最新提出的 SeedFoley 模型,通过端到端架构实现了视频音效的智能生成,将 AI 视频创作带入「有声时代」。
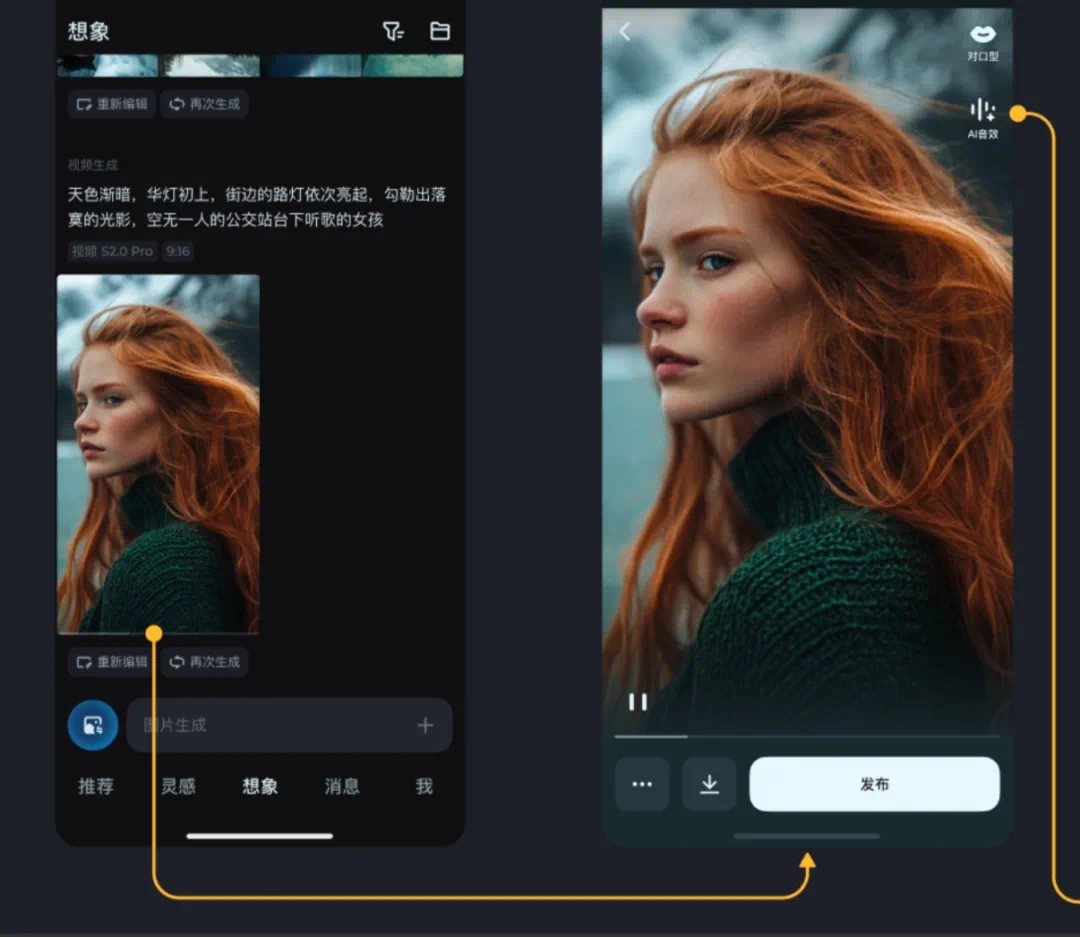
相关功能「AI 音效」已在即梦上线
,用户使用即梦生成视频后,选择「AI 音效」功能,即可生成 3 个专业级音效方案。
App 端
Web 端
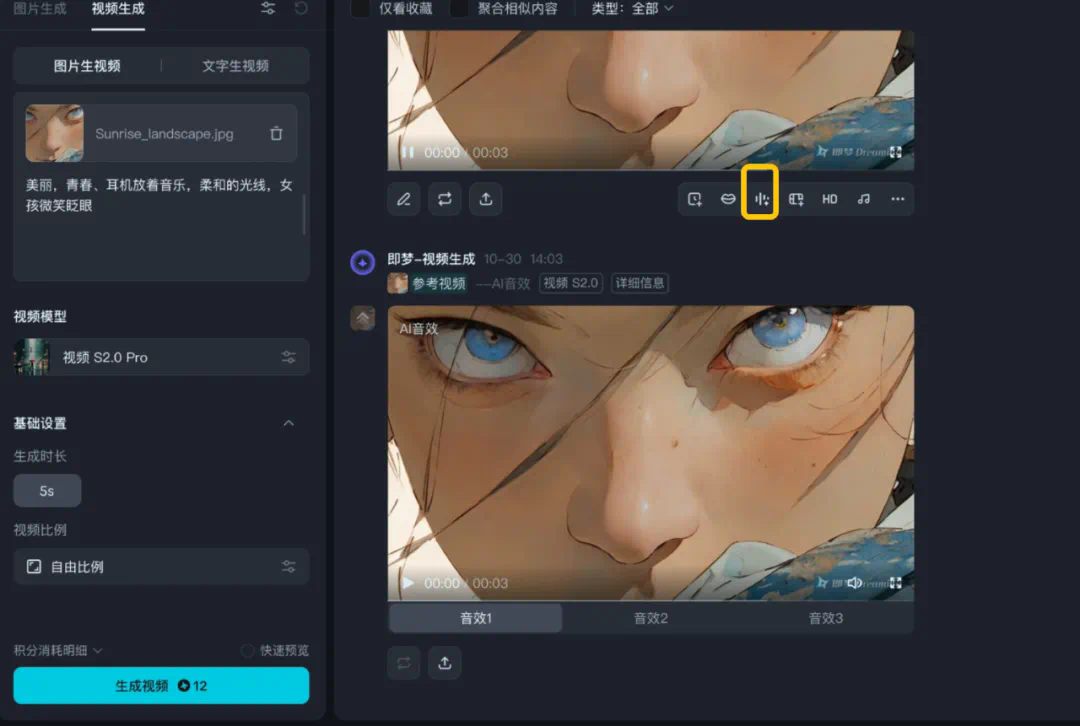
效果展示
先「听」为快,这里展示了一些 SeedFoley 生成的视频音效效果。
技术方案
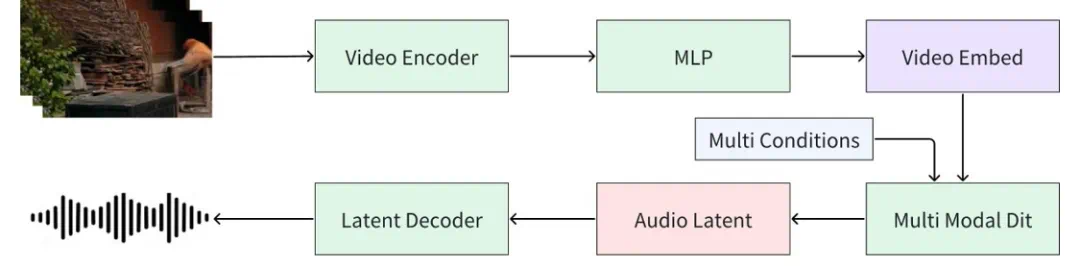
SeedFoley 是一种端到端的视频音效生成架构,通过融合时空视频特征与扩散生成模型,实现了音效和视频的高度同步。首先,用固定的视频帧率对视频序列进行抽帧提取,然后使用一个视频编码器提取视频的表征信息,并通过多层线形变换将视频表征投射到条件空间,在改进的扩散模型框架中构建音效生成路径。
在训练过程,提取语音和音乐相关标签,作为 multi conditions 的形式输入,可以将音效和非音效进行解耦。SeedFoley 能支持可变长度的视频输入,并且在音效准确性,音效同步性和音效匹配度等指标上都取得了领先水平。
图 1:SeedFoley 的模型架构
视频编码器
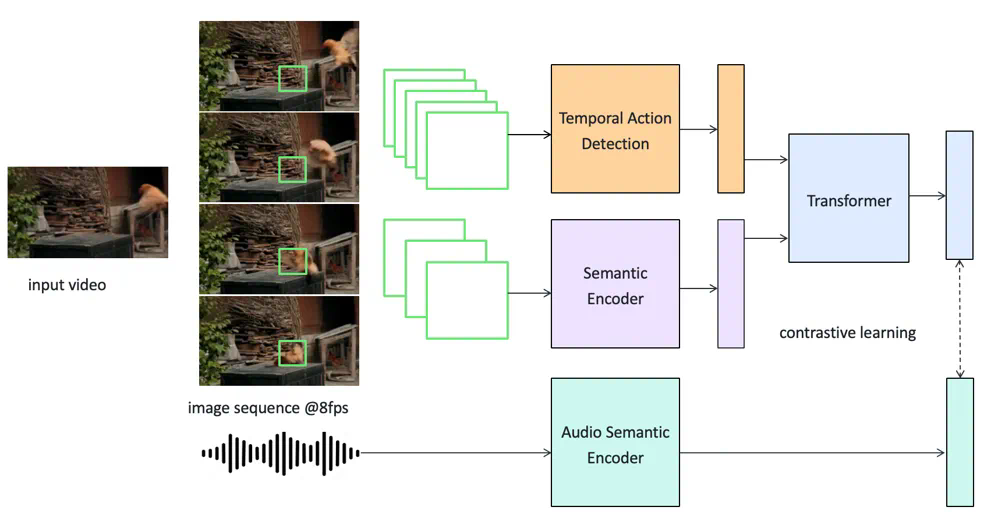
SeedFoley 的视频编码器,采用了快慢特征组合的方式,在高帧率上提取帧间的局部运动信息,在低帧率上提取视频的语义信息。通过将快慢特征组合,既保留了运动特征,有效降低计算成本。通过这种方式,能在低计算资源性实现 8fps 的帧级别视频特征提取,实现精细动作定位。最后利用 Transformer 结构融合快慢特征,实现视频的时空特征提取。在提升训练效果和训练效率上,SeedFoley 通过在一个批次中引入多个困难样本,显著提升了语义对齐效果,同时使用了 sigmoid loss 而非 softmax loss,能在更低的资源上实现媲美大批次训练的效果。
图 2:SeedFoley 的视频编码器
音频表征模型
对于扩散模型而言,通常采用 VAE 生成的潜在表征(latent representation)作为音频特征编码。与基于梅尔频谱(mel-spectrum)的 VAE 模型不同,SeedFoley 采用原始波形(raw waveform)作为输入,经过编码后得到 1D 的表征,比传统 mel-VAE 模型在重构和生成建模上更有优势。这里,音频采用了 32k 的采样率,以确保高频信息的保留。每秒钟的音频提取到 32 个音频潜在表征,可以有效提升音频在时序上的分辨率,提升音效的细腻程度。
SeedFoley 的音频表征模型采用了两阶段联合训练策略:在第一阶段使用掩码策略,将音频表征中的相位信息进行剥离,将去相位后的潜在表征作为扩散模型的优化目标;在第二阶段则使用音频解码器从去相位表征中重建相位信息。这个做法可以有效降低扩散模型对表征的预测难度,最终实现音频潜在表征的高质量生成和还原。
扩散模型
SeedFoley 采用 Diffusion Transformer 框架,通过优化概率路径上的连续映射关系,实现了从高斯噪声分布到目标音频表征空间的概率匹配。相较于传统扩散模型依赖马尔可夫链式采样的特性,SeedFoley 通过构建连续变换路径,有效减少推理步数,降低推理成本。
在训练阶段,将视频特征与音频语义标签分别编码为隐空间向量;通过通道维度拼接(Channel-wise Concatenation)将二者与时间编码(Time Embedding)及噪声信号进行混合,形成联合条件输入。该设计通过显式建模跨模态时序相关性,有效提升了音效和视频画面在时序上的一致性以及内容的理解能力。
在推理阶段,通过调整 CFG 系数可调整视觉信息的控制强度以及生成质量之间的关系。通过迭代式优化噪声分布,将噪声逐步转换为目标数据分布。通过将人声以及音乐标签进行强行设定,可以有效避免音效中夹杂人声或者背景音乐的可能性,提升音效的清晰度和质感。最后将音频表征输入到音频解码中,得到音效音频。
结语
SeedFoley 实现了视频内容与音频生成的深度融合,能够精确提取视频帧级视觉信息,通过分析多帧画面信息,精准识别视频中的发声主体及动作场景。无论是节奏感强烈的音乐瞬间,还是电影中的紧张情节,都能精准卡点,营造出身临其境的逼真体验;另外,SeedFoley 可智能区分动作音效和环境音效,显著提升视频的叙事张力和情感传递效率。
「AI 音效」功能已上线即梦
,用户使用即梦生成视频后,选择「AI 音效」功能,即可生成 3 个专业级音效方案。在 AI 视频,生活 Vlog、短片制作和游戏制作等高频场景中,能有效摆脱 AI 视频的「无声尴尬」,便捷地制作出配有专业音效的高质量视频。
团队介绍
豆包大模型语音团队的使命是利用多模态语音技术丰富交互和创作方式。团队专注于语音和音频、音乐、自然语言理解和多模态深度学习等领域的前沿研究和产品创新。
文章来源于互联网:
字节音效生成模型来了,一键生成大片感音效!已上线即梦
AI 太烧钱!微软选择「倒戈」DeepSeek
27
6 月
2026
Claude Code 修了几个小 bug,却揭开了 Agent 落地的大麻烦
27
6 月
2026
LiblibAI 母公司完成近 3 亿美元融资:AI 应用层开始进入「收入说话」的阶段
27
6 月
2026
超越 SONIC !人形机器人通用小脑迎来 GPT 时刻
27
6 月
2026
7 年 Google 老兵写出爆款工具被开除,转头官方发同款?OpenClaw 之父下场抢人
27
6 月
2026
马斯克悄悄改了战场:Grok Build 0.2.60 剑指 Agent Runtime
27
6 月
2026
这次是阿里!中国的大模型团队快被 Anthropic 告完了
27
6 月
2026
行业首个!大晓「晓途」开启机器狗开放场景7×24小时自主运营新模式
26
6 月
2026
Fable 5 刚被封杀,OpenRouter 用「多模型协作」搞出了「平替天团」
25
6 月
2026
别让 AI 碰生产环境!Reddit 火爆血泪贴,痛诉 AI 如何一刀切断数据库生命线
24
6 月
2026
算电协同进入Agent时代:商汤大装置SenseSynergy获信通院能力认证
18
6 月
2026
独家丨华为天才少年王裕鑫创业,首月完成数千万级首轮融资
18
6 月
2026
CVPR 2026完美落幕!D4RT封神最佳论文、牛津VGG两连冠,中国本科生泰坦显卡逆袭引爆全网
18
6 月
2026
SoulAgent 即将亮相北京智源大会,探索个人智能体在知识服务场景中的应用
18
6 月
2026
从诺奖项目到生成式药物设计,Latent Labs 创始人 Simon Kohl:AI 正在让生物学进入「可编程时代」 | CVPR 2026
18
6 月
2026
全部资讯
最新提问
我要提问
🎉🎉🎉AI问答功能上线喽!!
2024-11-30
Dongming
安装pytorch的时候提示拒绝访问
2024-11-30
7083
已经成功安装pytorch,但是import时提示"找不到指定的模块"
2024-11-30
7083
Pytorch安装后不能使用的问题
2024-11-30
7083
YOLO模型训练时提示报错
2024-11-30
7083
YOLO的安装使用报错问题
2024-11-30
7083
有哪些GPU云环境可以使用
2024-11-27
Dongming
No posts found
公众号
菜单
首页
AI知识
AI资讯
AI问答
滚动至顶部