文章来源于互联网:一行代码、无需训练突破视频生成时长「魔咒」,清华朱军团队开源全新解决方案RIFLEx

自 OpenAI 发布 Sora 以来,视频生成领域迎来爆发式增长,AI 赋能内容创作的时代已然来临。
去年 4 月,生数科技联合清华大学基于团队提出的首个扩散 Transformer 融合架构 U-ViT,发布了首个国产全自研视频大模型 Vidu,打破国外技术垄断,支持一键生成 16 秒高清视频,展现出中国科技企业的创新实力。Vidu 自去年 7 月上线以来,已服务数千万用户,极大促进了视频内容的智能创作。近期,腾讯混元、阿里通义万相等开源视频生成模型相继亮相,可生成 5-6 秒视频,进一步降低了视频创作门槛。
尽管如此,海内外社区仍有不少用户抱怨现有开源模型受限于生成 5-6 秒的短视频,时长不够用。
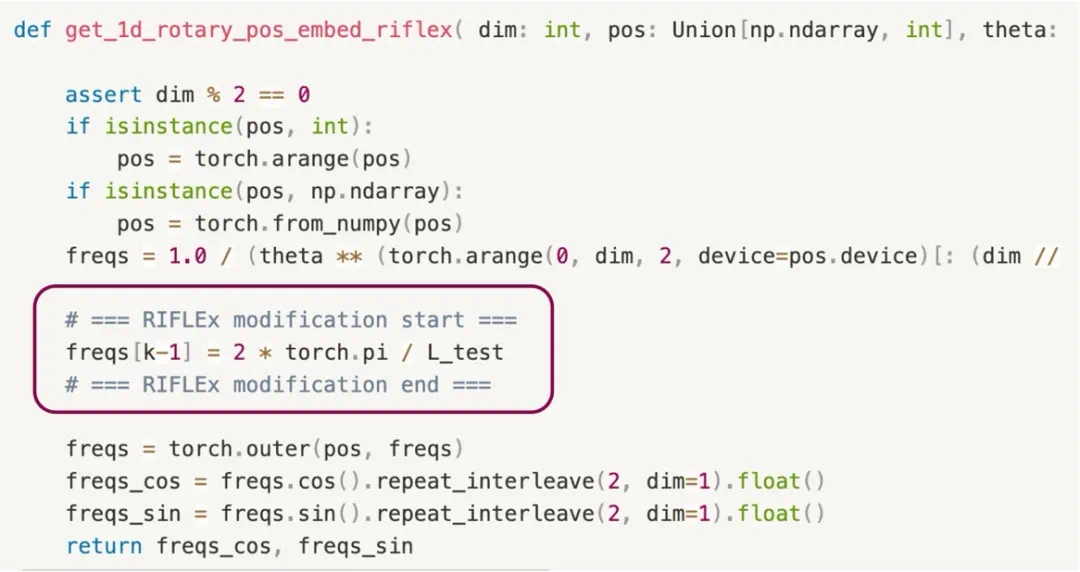
今天,Vidu 团队带来了一个简洁优雅的解决方案 ——RIFLEx。新方案仅需一行代码、无需额外训练即可突破视频生成模型现有长度限制,打破「短视频魔咒」。目前该项目已经开源,体现了团队对开源社区的积极回馈和贡献。

-
项目地址:https://riflex-video.github.io/ -
代码地址: https://github.com/thu-ml/RIFLEx
RIFLEx适用于基于RoPE的各类Video Diffusion Trasnsformer,例如CogvideoX、混元(链接到之前推送)以及最新发布的通义万相(链接到之前的推送)。
下列为开源模型无需任何训练直接时长外推两倍至10s效果:
-
大幅度运动:

-
多人物复杂场景:

-
自然动态流畅:

-
多转场时序一致性保持:

-
3D动画风格:

-
真实人物特写:

-
图像宽度外推两倍:

-
图像高度外推两倍:

-
图像高宽同时外推两倍:

-
视频时空同时外推两倍:
 训练尺寸:480*720*49
训练尺寸:480*720*49 
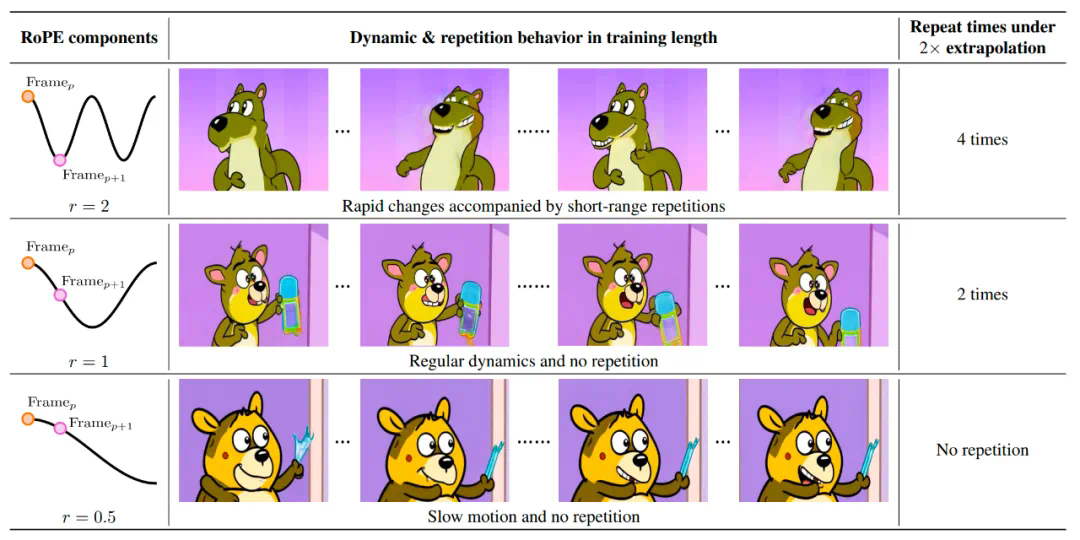
 直接外推导致视频内容重复,红色框表示开始和视频开头重复
直接外推导致视频内容重复,红色框表示开始和视频开头重复