文章来源于互联网:大语言模型变身软体机器人设计「自然选择器」,GPT、Gemini、Grok争做最佳

大型语言模型 (LLM) 在软体机器人设计领域展现出了令人振奋的应用潜力。密歇根大学安娜堡分校的研究团队开发了一个名为「RoboCrafter-QA」的基准测试,用于评估 LLM 在软体机器人设计中的表现,探索了这些模型能否担任机器人设计的「自然选择器」角色。
这项研究为 AI 辅助软体机器人设计开辟了崭新道路,有望实现更自动化、更智能的设计流程。

-
作者: Changhe Chen, Xiaohao Xu, Xiangdong Wang, Xiaonan Huang
-
机构: 密歇根大学安娜堡分校
-
原论文: Large Language Models as Natural Selector for Embodied Soft Robot Design
-
Github:https://github.com/AisenGinn/evogym_data_generation
-
视频:https://youtu.be/bM_Ez7Da4ME
研究背景
软体机器人相比传统刚性机器人具有显著优势,特别是在复杂、非结构化和动态环境中,其固有的柔顺性能够实现更安全、更适应性强的交互。然而,软体机器人设计面临巨大挑战:
-
与刚性机器人明确定义的运动链不同,软体机器人拥有几乎无限的自由度
-
非线性材料特性复杂
-
需要精密协调形态、驱动和控制系统
这些因素使软体机器人设计成为一项高度挑战性的多学科问题,传统上依赖专家直觉、迭代原型设计和计算成本高昂的模拟
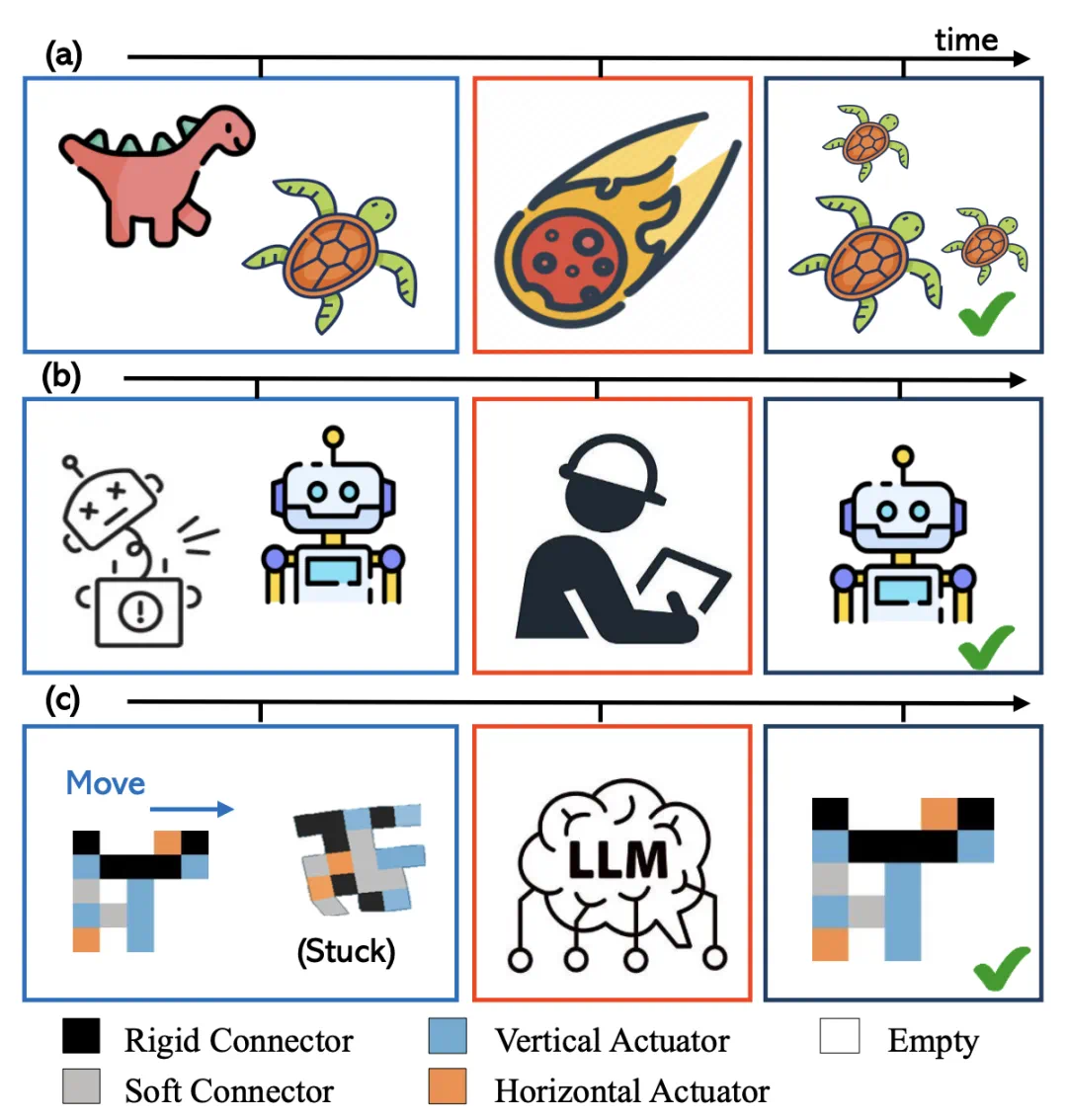
研究创新:从生物进化到 AI 驱动设计
研究团队提出了生物和机器人设计范式的概念性转变:
-
生物进化:通过自然选择压力驱动,但进程缓慢且受限。
-
人类工程设计:由人类直觉和专业知识引导,但仍受人类认知能力限制。
-
AI 驱动设计:LLM 作为「自然选择器」,利用其庞大的知识库评估和指导软体机器人的设计。
RoboCrafter-QA 基准测试
研究团队开发的 RoboCrafter-QA 基准测试专门用于评估多模态 LLM 对软体机器人设计理解的能力。该测试采用问答形式,为 LLM 提供环境描述和任务目标,然后要求模型从两个候选机器人设计中选择性能更佳的一个。
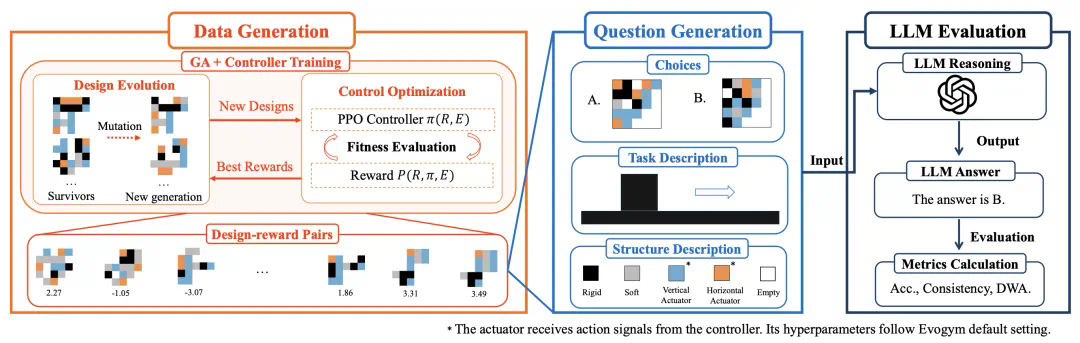
数据生成流程
-
设计空间定义:在 5×5 的基于体素的设计空间中进行机器人形态演化,每个体素代表一种材料类型(空、刚性、软性、水平驱动器或垂直驱动器)。
-
进化过程:从 30 个随机生成的独特机器人设计开始,使用经过 PPO(近端策略优化)训练的控制器评估每个机器人。
-
选择与变异:保留每代中表现最佳的 50% 机器人,其余通过变异产生后代,确保设计多样性。
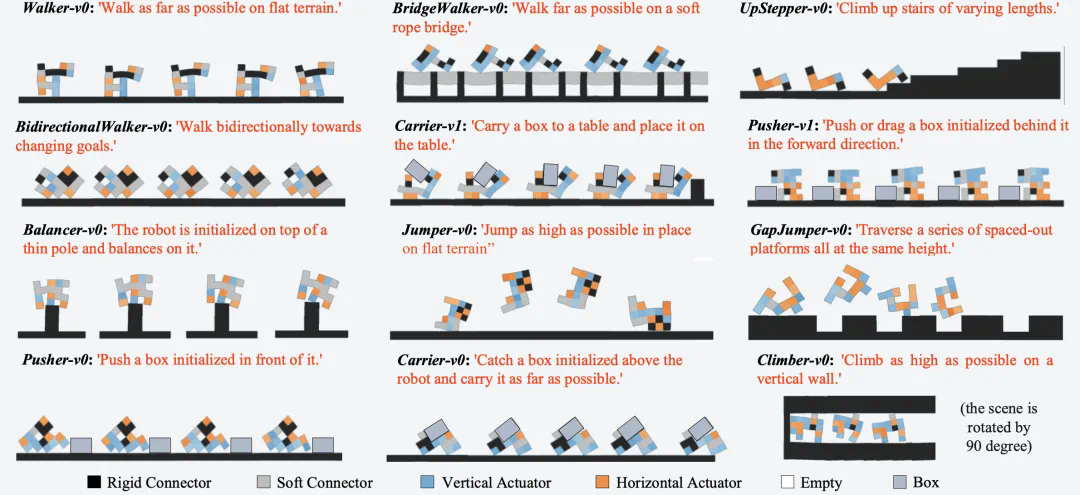
测试任务多样性
基准测试包含 12 种不同的任务环境,涵盖:
-
运动任务(如平地行走、桥梁行走)
-
物体操作(如推动、携带)
-
攀爬与平衡任务
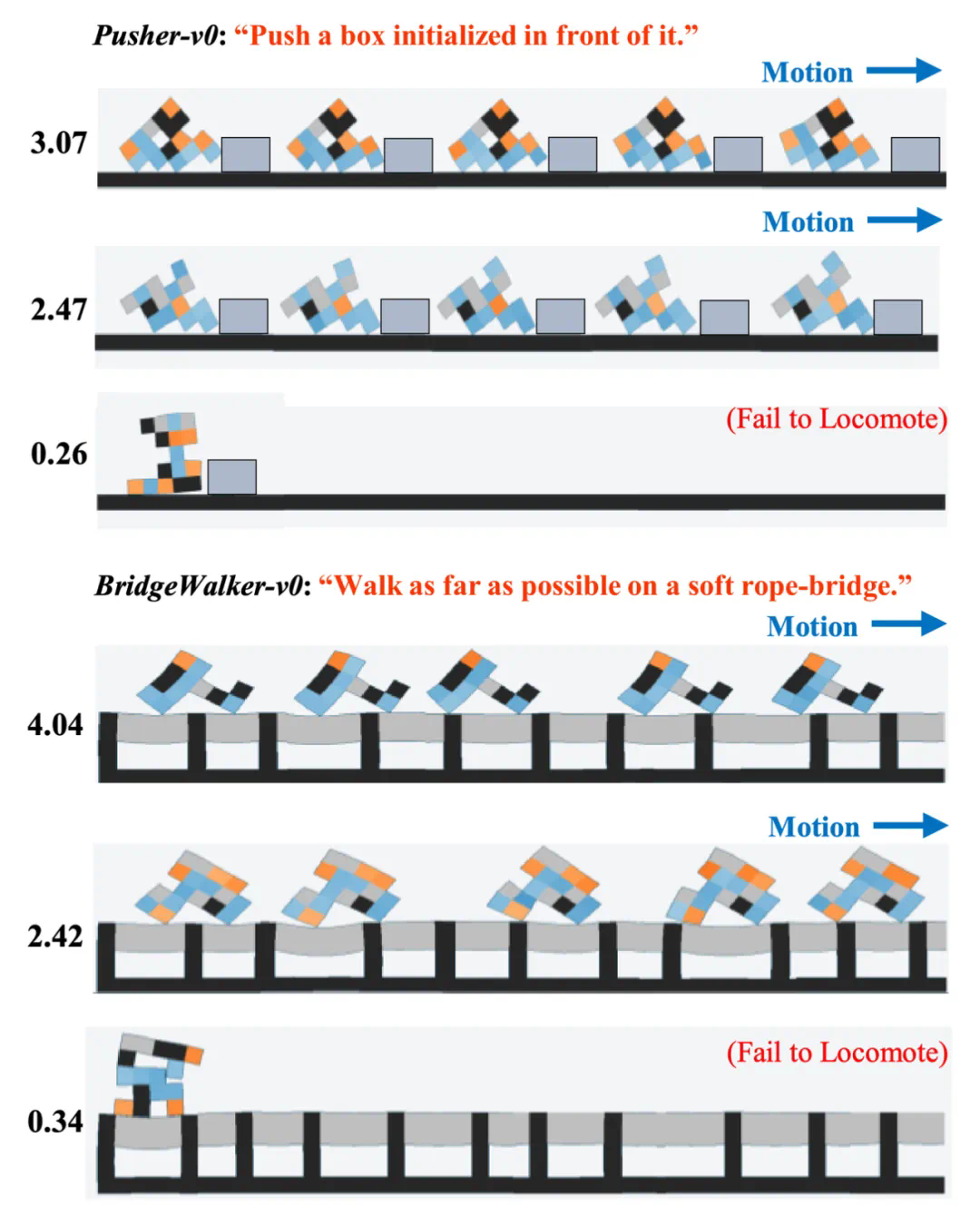
不同结构的机器人的性能差异示意:
问题示例: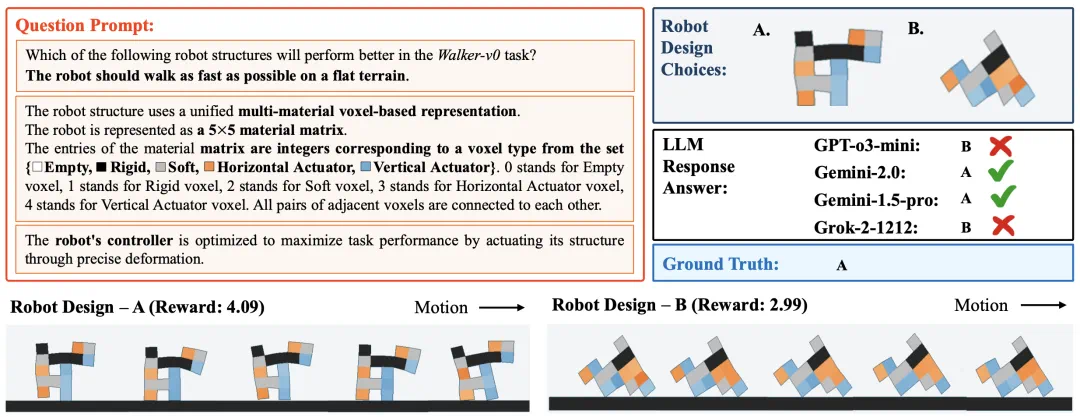
评估指标
-
准确率:模型生成与预期答案匹配的比例
-
一致性:衡量 LLM 响应的可重复性
-
难度加权准确率 (DWA):根据机器人任务性能的细微差异量化模型的判别能力
实验结果
研究团队对四种最先进的大型语言模型进行了测试评估:GPT-o3-mini、Gemini-2.0-flash、Gemini-1.5-Pro 和 Grok-2。
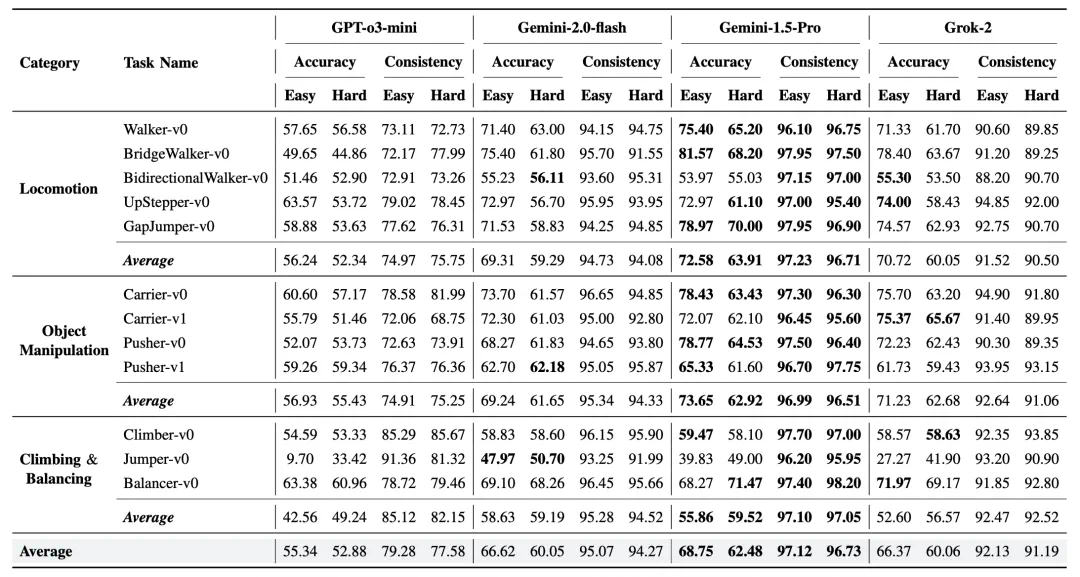
主要发现:
-
模型性能层次:Gemini-1.5-Pro 在简单任务(68.75%)和困难任务(62.48%)中均表现最佳,其次是 Gemini-2.0-flash 和 Grok-2(准确率约 66%),而 GPT-o3-mini 表现最弱。
-
任务难度敏感性:所有模型在更复杂的任务中准确率均有下降,特别是当需要区分细微性能差异的设计时。例如,Gemini-1.5-Pro 在 Walker-v0 任务中,简单级别准确率为 75.40%,困难级别则降至 65.20%。
-
模型在特定环境中的弱点:在跳跃和双向行走等任务中,所有模型均表现出明显弱点,这可能与这些任务需要精确时序控制或处理双向决策相关。
性能分析:奖励差异水平分析
为评估 LLM 在不同难度水平下选择更优设计的能力,研究团队采用了难度加权准确率 (DWA) 指标。该指标特别关注模型在区分细微性能差异设计时的能力,对难度更高的问题(奖励差异更小)赋予更高权重。
不同 LLM 的全局 DWA 指标:

研究结果显示,Gemini-1.5-Pro 在全球平均 DWA 方面表现最佳,达到 63.72%,这表明它在 RoboCrafter-QA 基准测试中具有略微优越的体现设计推理能力。
研究团队还可视化了不同奖励差异水平下的错误分布情况,发现 LLM 的大部分错误出现在 0.8-1.0 的高难度区间,这进一步突显了当前模型在进行细粒度设计区分方面的局限性。
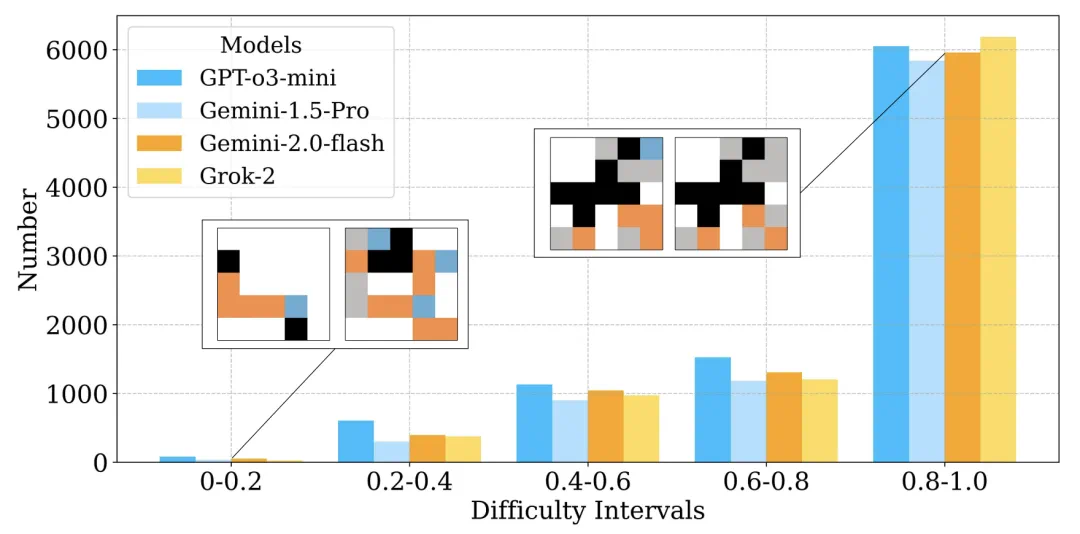
提示设计消融研究
为确定影响 LLM 做出正确选择的关键因素,研究团队针对提示设计进行了消融研究,重点关注任务描述和驱动器描述对模型性能的影响。研究还进行了一项实验,修改提示指令,要求 LLM 选择表现较差的设计而非较好的设计,以进一步分析 LLM 决策过程的稳健性。
提示设计消融研究结果:

消融研究结果揭示了任务描述和驱动器描述在促使语言模型选择最优设计中的关键作用:
-
任务描述的重要性:模糊任务描述 (NoEnv) 显著降低了所有模型的性能,例如 GPT-o3-mini 的准确率从 55.34% 降至 52.08%,Gemini-1.5-pro 从 69.75% 降至 62.50%,这强调了任务描述在引导 LLM 决策过程中的重要性。
-
驱动器描述的影响有限:忽略驱动器描述 (NoAct) 对性能影响较小,性能保持稳定或略有变化。这可能表明在缺乏驱动器信息的情况下,LLM 会假设驱动器能够最大化设计的奖励。
-
选择较差设计的挑战:当指示模型选择较差的设计时,模型表现出比完整信息提示更低的准确率(例如,Gemini-2.0-flash 从 66.62% 降至 58.45%),这表明它们在识别劣质设计方面不太擅长,可能是由于训练偏向于选择更好的设计所致。
这些发现强调了在设计选择任务中,为最大化 LLM 性能提供全面任务描述的必要性。与此同时,研究也表明当前模型在理解设计权衡和进行反直觉选择(如选择较差设计)方面仍存在局限性,这可能需要通过更具针对性的训练或提示策略来解决。
总结与启示
通过对奖励差异水平的性能分析和提示设计消融研究,我们可以看出:
-
当前最先进的 LLM 在区分明显不同的设计时表现良好,但在处理细微性能差异时仍面临挑战。
-
提供清晰、全面的任务描述对于 LLM 做出正确设计选择至关重要。
-
模型表现出偏向选择更优设计的趋势,这与其预训练方式可能有关。
这些发现为利用 LLM 进行软体机器人设计提供了重要指导,同时也揭示了未来改进方向:可能需要开发针对体现设计的特定训练策略,或构建更复杂的提示框架,以提高模型在处理细微设计权衡时的性能。
实用价值:LLM 辅助机器人设计初始化
除了评估模型选择能力外,研究还探索了 LLM 在设计初始化中的应用。通过提供参考环境中的高奖励和低奖励设计实例,研究测试了 LLM 是否能为新环境生成可行的初始设计。
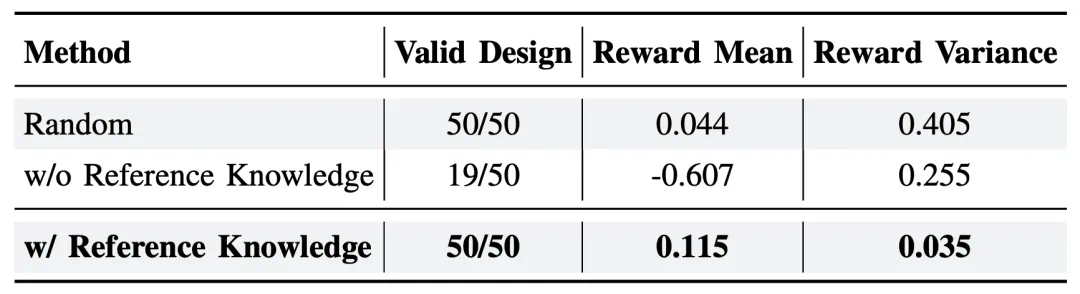
实验结果表明:
-
具有参考知识的 LLM 生成的设计全部有效,平均奖励值达 0.115,方差仅为 0.035。
-
无参考知识的设计中仅 38% 有效,平均奖励为 – 0.607。
-
随机基线虽然产生了 100% 有效设计,但平均奖励较低(0.044),方差高(0.405)
这表明 LLM 能够有效地迁移知识,在零样本设计生成中表现出色。
研究结论与展望
RoboCrafter-QA 基准测试为评估多模态 LLM 在软体机器人设计中的表现提供了宝贵工具。研究发现,虽然当前模型在简单设计选择上表现良好,但在处理细微权衡和复杂环境时仍面临挑战。
未来研究方向:
-
探索 LLM 驱动的控制策略优化
-
扩展设计空间复杂性
-
研究仿真到现实的迁移,包括材料特性和控制器可迁移性
-
整合多模态提示(视觉、触觉)增强 LLM 的设计理解
