文章来源于互联网:MoCha:开启自动化多轮对话电影生成新时代

本文由加拿大滑铁卢大学魏聪、陈文虎教授团队与 Meta GenAI 共同完成。第一作者魏聪为加拿大滑铁卢大学计算机科学系二年级博士生,导师为陈文虎教授,陈文虎教授为通讯作者。
近年来,视频生成技术在动作真实性方面取得了显著进展,但在角色驱动的叙事生成这一关键任务上仍存在不足,限制了其在自动化影视制作与动画创作中的应用潜力。现有方法多聚焦于Talking Head 场景,仅生成面部区域,且高度依赖辅助条件(如首帧图像或精确关键点),导致生成内容在动作幅度与连贯性方面受限,难以展现自然流畅的全身动态与丰富的对话场景。此外,已有方法通常仅支持单角色说话,无法满足多角色对话与交互的生成需求。
为此,研究团队提出了 MoCha,首个面向Talking Characters任务的视频生成方法,致力于仅基于语音(Speech)与文本 (text) 输入,直接生成完整角色的对话视频,无需依赖任何辅助信号,突破了现有技术仅限于面部区域生成(Talking Head)及动作受限的局限,为自动化叙事视频生成提供了全新解决方案。
该方法面向角色近景至中景(close shot to medium shot)的全身区域,支持一个或多个人物在多轮对话场景中的动态交互。为实现语音与视频内容的精准同步,MoCha 设计了Speech-Video Window Attention机制,有效对齐语音与视频的时序特征,确保角色口型与身体动作的一致性。同时,针对大规模语音标注视频数据稀缺的问题,研究团队提出了联合训练策略,充分利用语音标注与文本标注的视频数据,显著提升了模型在多样角色动作与对话内容下的泛化能力。此外,团队创新性地设计了结构化提示模板,引入角色标签,使 MoCha 首次实现了多角色、多轮对话的生成,能够驱动 AI 角色在上下文连贯的场景中展开具备电影叙事性的对话。通过大量定性与定量实验,包括用户偏好调研与基准对比,研究团队验证了 MoCha 在真实感、表现力、可控性与泛化性方面的领先性能,为 AI 驱动的电影叙事生成树立了新标杆。

-
论文链接:https://arxiv.org/pdf/2503.23307
-
Hugging face 论文地址:https://huggingface.co/papers/2503.23307
-
项目地址:https://congwei1230.github.io/MoCha/
目前,该研究在 X 平台上引起了广泛的关注与讨论,相关热帖已经有一百多万的浏览量。
性能展示
MoCha 能够实现基于角色对话驱动的叙事视频生成。以下为研究团队基于 MoCha 生成的视频样例,并通过简单剪辑制作成宣传视频,以展示未来自动化电影生成的可行性与潜力。
MoCha 能够生成 高度准确的唇动同步效果,展现出精细的语音 – 视频对齐能力。
情绪可控性:MoCha能够根据输入文本灵活控制角色情绪,自动生成符合语境的角色表情与情绪动作,同时保证 唇动同步 与 面部表情与上下文的一致性。
动作可控性:MoCha支持通过文本提示灵活控制角色动作,生成符合语境的动态表现,同时确保 唇动同步 与 面部表情与上下文的协调性。
Zero-shot中文对话生成(无间道台词):尽管MoCha未在中文语音数据上进行训练,模型仍展现出良好的跨语言泛化能力,能够生成同步较为自然的中文对话视频。
多角色对话生成:MoCha支持多角色对话生成,能够在单角色发言时,保证所角色的动作与表现合理连贯,整体对话场景保持视觉一致性与叙事连贯性。
多角色多轮对话生成:MoCha支持多角色、多轮对话(Turn-based Dialog)生成,能够实现镜头切换与多角色动态对话的自然衔接,突破现有方法仅支持单角色发言的局限,生成具有镜头语言与剧情连贯性的复杂对话视频。
核心方法
下图展示了 MoCha 的整体框架。
端到端训练,无需辅助条件:与现有方法(如 EMO、OmniHuman-1、SONIC、Echomimicv2、Loopy 和 Hallo3)不同,这些方法通常依赖参考图像、骨骼姿态或关键点等外部控制信号,MoCha实现了 完全基于语音与文本的端到端训练,无需任何辅助条件。这一设计有效简化了模型架构,同时显著提升了动作多样性与泛化能力。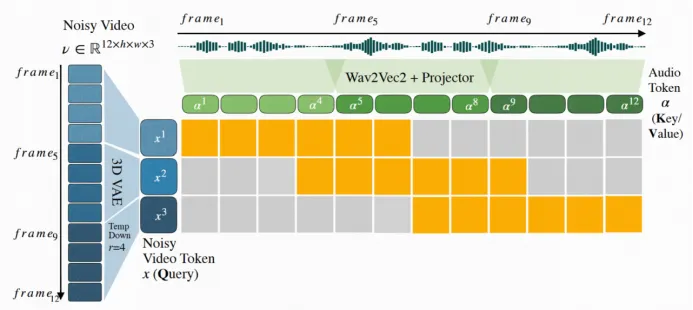
Speech-Video Window Attention 机制:研究团队提出了一种创新性的注意力机制 —— Speech-Video Window Attention,通过局部时间条件建模有效对齐语音与视频输入。 该设计显著提升了唇动同步准确率与语音 – 视频对齐效果。
联合语音 – 文本训练策略:针对大规模语音标注视频数据稀缺的问题,研究团队提出了联合训练框架,充分利用语音标注与文本标注的视频数据进行协同训练。该策略有效提升了模型在多样化角色动作下的泛化能力,同时实现了基于自然语言提示的通用可控性,支持在无需辅助信号的前提下,对角色的表情、动作、交互以及场景环境等进行细粒度控制。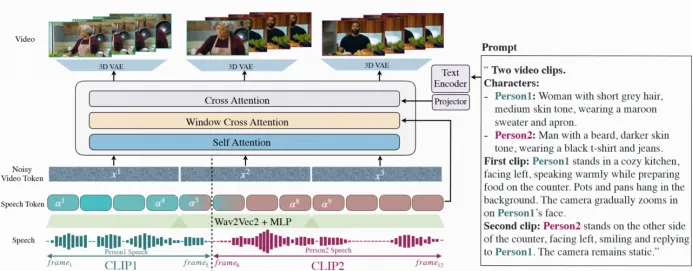
多角色对话生成与角色标签设计:MoCha首次实现了多角色动态对话生成,突破了现有方法仅支持单角色的限制,能够生成连贯、具备镜头切换与剧情连贯性的多轮对话视频。为此,研究团队设计了结构化提示模板,明确指定对话片段数量,并引入角色描述与标签,通过角色标签简化提示,同时保证对话清晰可控。MoCha利用 视频 Token 的自注意力机制,有效保持角色身份与场景环境的一致性,同时通过语音条件信号自动引导模型在多角色对话中的镜头切换与发言时机。
总结
总体而言,本研究首次系统性地提出了Talking Characters 生成任务,突破传统Talking Head合成方法的局限,实现了面向完整角色、支持多角色动态对话的视频生成,仅需语音与文本输入即可驱动角色动画。为解决这一挑战性任务,研究团队提出了MoCha框架,并在其中引入了多项关键创新,包括:用于精确音视频对齐的Speech-Video Window Attention机制,以及结合语音标注与文本标注数据的联合训练策略,有效提升模型的泛化能力。此外,团队设计了结构化提示模板,实现了多角色、多轮对话的自动生成,具备上下文感知能力,为可扩展的电影级 AI 叙事生成奠定了基础。通过系统的实验评估与用户偏好研究,研究团队验证了 MoCha 在真实感、表现力与可控性等方面的优越性能,为未来生成式角色动画领域的研究与应用提供了坚实基础。
文章来源于互联网:MoCha:开启自动化多轮对话电影生成新时代

