
作者丨郑佳美
编辑丨马晓宁
在自动驾驶进入大模型时代之后,行业正在从传统的“感知、预测、规划、控制”模块化流水线,逐步转向端到端智能系统。
过去,VA 模型能够直接从视觉输入生成驾驶轨迹,在规划精度和实时性上表现突出,但它们更多依赖隐式视觉特征,很难清楚解释“为什么这样开”,也难以处理那些需要语义理解和常识推理的长尾场景。
比如车辆行驶在狭窄居民区道路上,两侧停满车辆,前方可能有行人突然从车缝中出现;又比如在无保护左转路口,系统不仅要判断对向来车速度,还要理解让行关系和潜在风险;再比如施工区域、临停车辆、单纯依靠视觉到轨迹的映射往往不够,自动驾驶系统还需要像人类司机一样理解场景含义,再把理解转化为可执行的连续控制动作。
在这种背景下,VLA 被认为是更接近“会理解、会解释、会行动”的自动驾驶方向,但此前很多 VLA 方法又面临一个现实问题:语言能力引入后,规划精度、动作连续性和推理速度往往难以同时保证。
正是在这种行业矛盾下,香港中文大学 MMLab、理想汽车和清华大学的联合研究团队提出了《MindVLA-U1: VLA Beats VA with Unified Streaming Architecture for Autonomous Driving》这项研究。
研究试图回答一个关键问题:自动驾驶中的语言理解,究竟能不能真正帮助动作规划,而不是只作为解释文本存在。围绕这一问题,研究团队没有简单地扩大模型规模,而是从架构接口入手,把视觉、语言、车辆状态、历史记忆和动作生成统一到同一个 VLM backbone 中,让模型既能理解道路场景,也能直接生成连续驾驶轨迹。
更重要的是,研究通过 Intent-CFG 让语言侧预测出的驾驶意图参与轨迹生成,通过 streaming memory 让模型像真实车辆一样逐帧处理连续视频流,并通过快 / 慢推理路径在实时控制和语义推理之间切换。
也就是说,当道路场景简单时,系统可以快速给出动作;当场景复杂、风险较高或需要解释时,系统可以保留语言推理能力,再生成更有语义依据的驾驶轨迹。这使得研究不只是一次模型指标提升,更是在探索自动驾驶从“看见后执行”走向“理解后行动”的一种新架构路线。

论文地址:https://arxiv.org/pdf/2605.12624

01
当 VLA 开始超过 VA
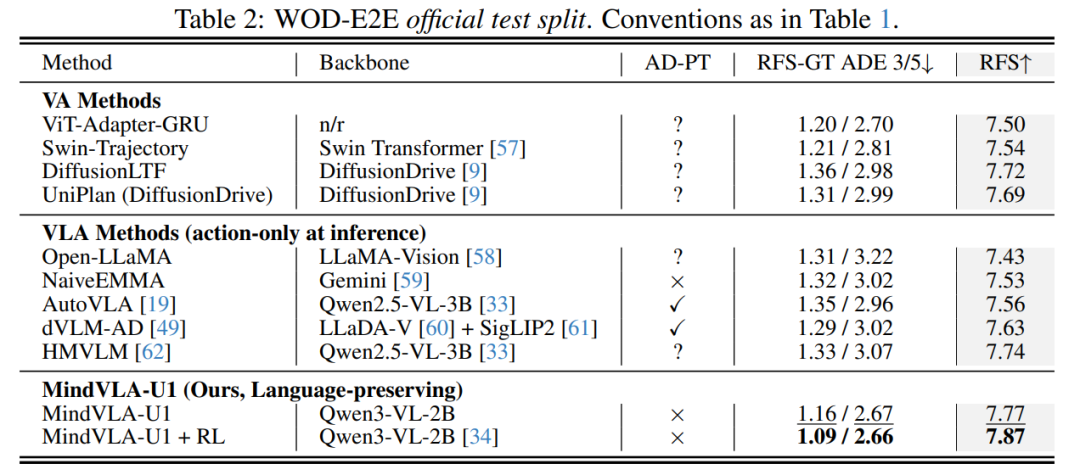
实验结果显示,MindVLA-U1 在 WOD-E2E 自动驾驶 benchmark 上取得了较强的整体规划效果,尤其是在加入 RL 后,验证集 RFS 达到 8.20,而人类驾驶参考轨迹的 RFS 是 8.13,说明模型在开放环评测中生成的轨迹质量已经超过人类驾驶参考,体现出研究团队提出的统一 VLA 架构在轨迹规划上的优势。雷峰网(公众号:雷峰网)
在官方测试集中,MindVLA-U1 + RL 的 RFS 达到 7.87,取得最高表现,同时 RFS-GT ADE 达到 1.09 / 2.66 m,轨迹误差低于多数已有 VA 和 VLA 方法,说明这种方法并不是只在验证集上有效,在隐藏测试集上也具有较好的泛化能力。
语言对动作的影响也得到了实验验证,普通 MindVLA-U1 的 RFS 是 7.83,加入 NTP 预测 intent 后,RFS 提升到 7.92,说明语言侧预测出的驾驶意图可以通过 Intent-CFG 引导连续轨迹生成,使语言信息真正进入动作生成过程,而不是只作为解释或附加输出存在。雷峰网
流式记忆模块同样表现出明显作用,chunk-wise 单帧训练的 RFS 是 7.69,streaming training 提升到 7.73,streaming + memory 进一步提升到 7.83,说明仅仅按帧进行流式训练还不够,加入历史记忆后,模型能够更好利用时间上下文,从而改善连续驾驶场景中的长期规划效果,同时长时间轨迹预测中的 ADE 也整体下降,例如 25 s 序列 ADE 从 1.54 降到 1.50。
快 / 慢路径实验说明,慢路径可以保留语言推理能力,更适合复杂场景或安全敏感场景,快路径则跳过语言生成,直接进行动作规划,在保持较好规划质量的同时让推理速度接近 VA 方法,表明 VLA 模型不一定只能“慢而重”,也可以通过不同推理模式在语义理解和实时控制之间切换。
模型规模实验进一步说明,性能提升并不只依赖更大的 VLM backbone,不同尺寸下结果并不是越大越好,其中 2B 左右表现较好,9B 模型在默认训练设置下没有明显优势,延长训练后 9B 有一定恢复,说明当前瓶颈不只是模型大小,还包括训练数据规模、训练时长、动作接口设计和任务适配方式等因素。
总体来看,研究结果表明,MindVLA-U1 的优势来自多个部分共同作用,包括统一的视觉语言动作 backbone、连续动作生成方式、Intent-CFG 语言到动作桥接、流式记忆机制、快 / 慢推理路径以及 RL 后训练,这些设计共同改善了 VLA 在自动驾驶轨迹规划中的精度、泛化能力、实时性和语义可控性。

02
让模型像真实车辆一样连续感知
实验经过方面,研究基于 WOD-E2E 数据集展开,数据来自真实自动驾驶场景,每段驾驶片段约 20 秒,并且包含多摄像头 360° 视觉输入,因此能够覆盖车辆周围不同方向的环境信息。
由于数据集中包含较多长尾场景,研究团队可以用它测试模型在复杂驾驶情况中的轨迹规划能力,而不是只验证模型在普通、规则、容易预测场景中的表现。
主要评测内容集中在两个方面,一方面评测模型预测轨迹的质量,使用 RFS 衡量预测轨迹是否符合人类评审偏好,使用 ADE 衡量预测轨迹和参考轨迹之间的距离误差,另一方面也评估语言输出质量,例如 VQA 的 BLEU 和 ROUGE,用来判断模型在保留驾驶规划能力的同时,是否还能维持语言理解和回答能力。
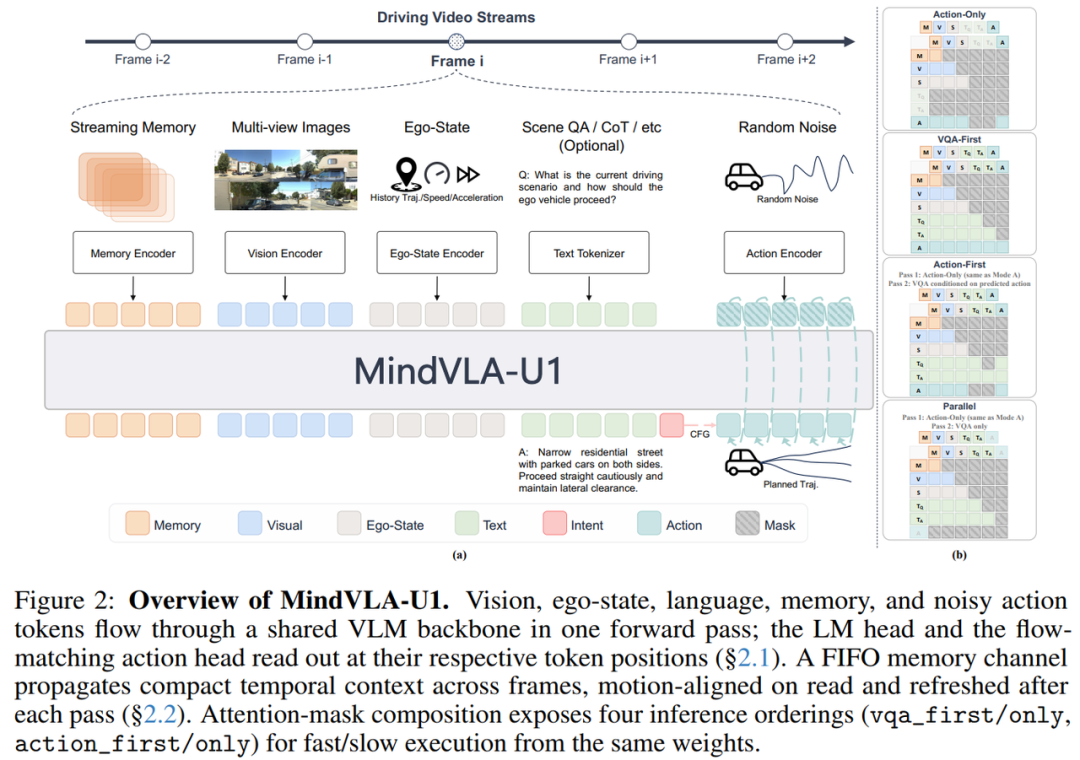
模型输入包括当前多视角图像、车辆自身历史状态、文本问题或语言提示、历史 streaming memory,以及带噪声的动作 token,这些信息共同进入模型,使模型既能看到当前道路环境,又能利用车辆历史运动状态和之前帧中保留下来的时序信息。
模型输出包括语言回答和连续驾驶轨迹,二者由同一个共享 backbone 完成,不是先用一个模块做语言理解,再交给另一个独立模块规划动作,也不是把动作表示成离散坐标 token,而是直接生成连续轨迹,这样可以减少离散化带来的精度损失。
统一 backbone 设计中,视觉、语言、车辆状态、记忆、动作 token 会一起进入 VLM backbone,语言通过自回归方式生成,动作通过 flow-matching 方式生成,两类任务共享模型表示,使语义理解和动作规划能在同一模型内部结合。
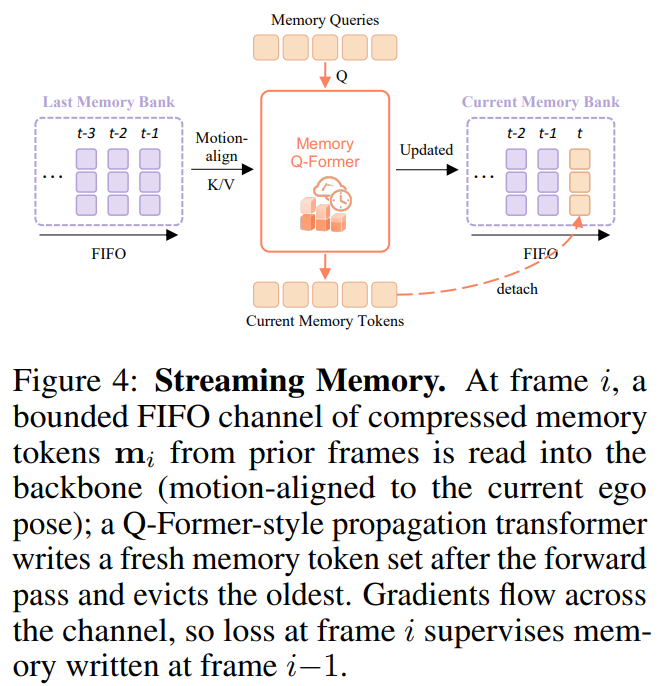
流式记忆设计中,模型不是一次性输入固定长度视频片段,而是每次只处理当前帧,历史信息通过 FIFO memory 保存,memory 会随着车辆运动进行对齐,每一帧处理后,模型还会写入新的 memory,从而让历史上下文在连续驾驶过程中不断传递,这种方式更接近真实自动驾驶中的连续视频流,也减少了重复处理多帧视频带来的计算负担。
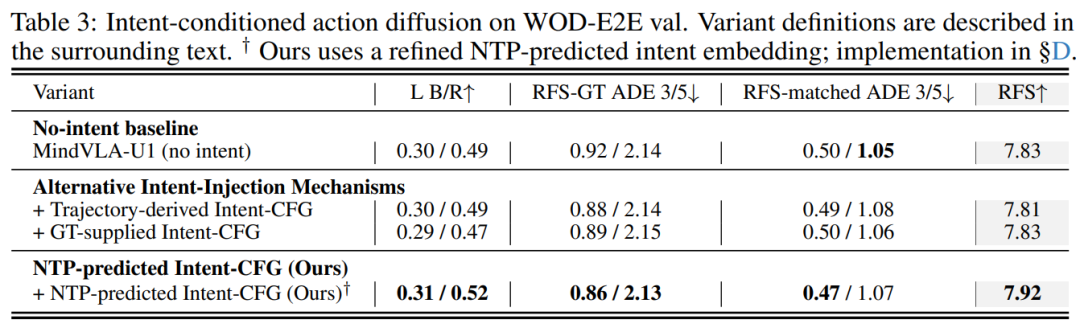
Intent-CFG 设计中,模型先预测当前驾驶意图,例如直行、左转、右转等,再把这个 intent 作为条件,引导动作扩散过程,并通过 CFG 让 intent 对轨迹生成产生影响。
实验还对比了无 intent、轨迹派生 intent、GT intent 和模型预测 intent,结果显示模型预测 intent 的效果最好,说明由语言侧预测出的驾驶意图更能帮助模型生成合理轨迹。

快/慢推理设计中,vqa_first 表示先语言推理再动作规划,action_first 表示先动作规划再生成语言解释,action_only 表示只生成动作不生成语言,不同模式共享同一套模型权重,因此部署时可以根据场景复杂度选择推理方式,简单场景中使用更快的动作路径,复杂或安全敏感场景中保留语言推理能力。
最后,在监督训练后,研究人员进一步使用 RL 优化模型,奖励信号主要来自 RFS,使模型生成的轨迹更符合人类评审偏好,并最终取得验证集和测试集上的最好结果。


03
自动驾驶 VLA 接口的重构
实验意义在于重新解释 VLA 过去落后 VA 的原因,研究团队认为,VLA 过去规划效果差,并不是因为语言天然会伤害控制能力,而是因为接口设计不合理,例如一些方法把本来需要保持高精度的连续轨迹离散成语言 token,导致动作表达受到 token 精度限制,也有一些方法把语言模块和动作模块分离得太远,使语言理解结果难以真正影响轨迹规划,还有一些方法在时间建模上依赖固定视频 chunk,容易造成计算冗余和片段边界不连续。
基于这种判断,MindVLA-U1 证明 VLA 可以同时兼顾理解和控制,模型既保留语言理解能力,又保留连续动作生成能力,不需要为了获得语言接口而牺牲轨迹精度,也不需要在推理时把语言模块完全丢掉。
更重要的是,研究让语言真正进入驾驶决策过程,过去很多 VLA 虽然拥有语言头,但语言并没有明确影响动作,更多只是作为解释或辅助输出存在,而 MindVLA-U1 通过 Intent-CFG 建立了语言到动作的可测量路径,使驾驶意图不只是对结果的说明,而是能够改变轨迹生成方向,从而让语言侧理解对连续控制产生实际作用。
研究也更适合真实自动驾驶部署,因为真实驾驶是连续视频流,而不是固定长度片段,streaming memory 能让模型按帧处理场景,同时保留历史上下文,并减少重复处理多帧视频带来的计算浪费,使模型更接近真实车辆持续感知和持续规划的工作方式。
快/慢系统统一方案也是重要意义之一,简单场景可以走 action_only 快路径,直接生成动作以满足实时控制需求,复杂场景可以走带语言推理的慢路径,让模型在安全敏感或语义复杂情境中进行更充分分析,一个模型即可覆盖不同计算需求,有助于实际部署中平衡实时性和安全性。
整体来看,研究推动了自动驾驶 VLA 架构发展,其重点不是单个模块改进,而是统一语言、视觉、记忆、动作的整体接口,为后续自动驾驶模型设计提供了参考价值。
同时,研究也留下进一步探索空间,当前主要是开放环评测,还没有充分验证闭环驾驶表现,目前只使用了较简单的 3 类 intent,MindLabel 中更丰富的 20 类 intent、轨迹评价 QA、CoT rationale 还没有充分利用,后续仍可以继续提升长尾场景处理能力、多模态动作选择能力和闭环安全性。

04
MindVLA-U1 背后的研究者
这篇论文的通讯作者为李鸿升,香港中文大学电子工程系 Multimedia Laboratory 副教授,同时兼任香港中文大学计算机科学与工程系副教授,并将于 2026 年 8 月 1 日起晋升为正教授。
他于 2006 年获得华东理工大学自动化专业工学学士学位,2006 年至 2007 年在上海交通大学模式识别与智能系统方向学习,随后进入美国 Lehigh University 攻读博士,并于 2012 年获得计算机科学博士学位。
职业经历上,他曾在电子科技大学电子科学学院担任副教授,之后在香港中文大学电子工程系先后担任博士后、研究助理教授和助理教授,并自 2022 年 7 月起担任副教授。研究方向上,他长期关注计算机视觉、医学影像、深度学习、多模态学习、生成模型、具身智能和机器人操作等领域。
学术成果方面,他在 CVPR、ICCV、NeurIPS、ICML、ACL、EMNLP、AAAI 等顶级会议持续发表成果,2025 年有 13 篇成果被 NeurIPS 接收、3 篇被 EMNLP 主会接收、7 篇被 ICCV 接收、4 篇被 ACL 接收、3 篇被 ICML 接收、11 篇被 CVPR 接收,2026 年有 3 篇成果被 ACL 接收,并有 27 篇成果被 ICML、CVPR、ICLR、AAAI 接收。
他还曾获得过 2025 年香港中文大学 Research Excellence Award、2021 年香港中文大学 Young Researcher Award、2020 年 IEEE Circuits and System Society Outstanding Young Author Award,并在 2022 年、2023 年、2024 年获得 AI 2000 计算机视觉领域最具影响力学者荣誉提名,2022 年至 2025 年入选斯坦福大学全球前 2% 顶尖科学家榜单。
除此之外,他的团队曾获得 ActivityNet Challenge 2020 时空动作定位 AVA 赛道冠军、ImageNet Video Object Detection Challenge 2015 冠军,以及 ImageNet Video Object Detection / Tracking Challenge 2016 冠军,近年研究覆盖网页生成评测、移动 GUI 智能体、多模态数学推理、图像生成、视觉生成编辑、自动驾驶场景生成和具身智能等方向。

参考链接 :https://www.ee.cuhk.edu.hk/~hsli/
另一位通讯作者为朱本金(Benjin Zhu),目前是理想汽车的研究科学家,同时在清华大学从事博士后研究,合作导师为代季峰教授。
他于 2025 年在香港中文大学电子工程系获得博士学位,博士期间隶属于 Multimedia Lab,导师为李鸿升教授和王晓刚教授,并于 2018 年在华南理工大学获得软件工程学士学位。
职业经历方面,他曾于 2019 年 1 月至 2021 年 5 月在旷视研究院担任研究员,研究方向包括端到端目标检测、无监督 / 自监督学习和研究基础设施,2025 年 5 月起在理想汽车担任高级研究工程师,主要关注世界模型、视觉语言动作模型和强化学习。
他聚焦视觉语言动作模型、扩散模型、世界模型和 AI 基础设施。学术成果方面,他参与了多项计算机视觉、三维感知和自动驾驶相关研究,成果曾被 ICCV、ECCV、CVPR 等国际顶级会议接收。
除此之外,他还曾获得 WAD CVPR 2019 首届 nuScenes 3D 目标检测挑战赛冠军,并对多个开源计算机视觉框架作出重要贡献,相关框架覆盖三维检测、视觉任务实验管理和通用深度学习研究基础设施。

参考链接:https://benjin.me/
这次去 CVPR 现场,一定不要错过
【认识大牛+赚外快】的机会
需要你做什么:把你最关注的10个大会报告,每页PPT都拍下来
你能获得什么?
认识大牛:你将可以进入CVPR名师博士社群;
钱多活少:提供丰厚奖金,任务量精简;
听会自由:你的行程你做主,顺手就把外快赚。拍下你最感兴趣的10个报告PPT即可。
如果你即将前往CVPR,想边听会边赚钱,还能顺便为AI学术社区做贡献、认识更多大牛,欢迎联系我们:[添加微信号:MS_Yahei]
【限额5位,先到先得】

雷峰网原创文章,未经授权禁止转载。详情见转载须知。

