前言
在上一章【课程总结】day19(下):Transformer架构及注意力机制了解总结中,我们对Transformer架构以及注意力机制有了初步了解,本章将结合《The Annotated Transformer》的资料以及Transfomer_demo的示例代码,对Transformer的架构进行深入理解。
资料
Transformer_demo是一个使用Transformer架构进行翻译的示例代码,该工程与【课程总结】Day18:Seq2Seq的深入了解中的Seq2Seq实现非常类似,可以方便我们通过单步调试的方式,动态地了解Transformer架构。
其他资料:《The Annotated Transformer》
- 博客地址:https://nlp.seas.harvard.edu/2018/04/03/attention.html
- Github仓库地址:https://github.com/harvardnlp/annotated-transformer
整体框架
![]()
代码分析理解
初始化流程
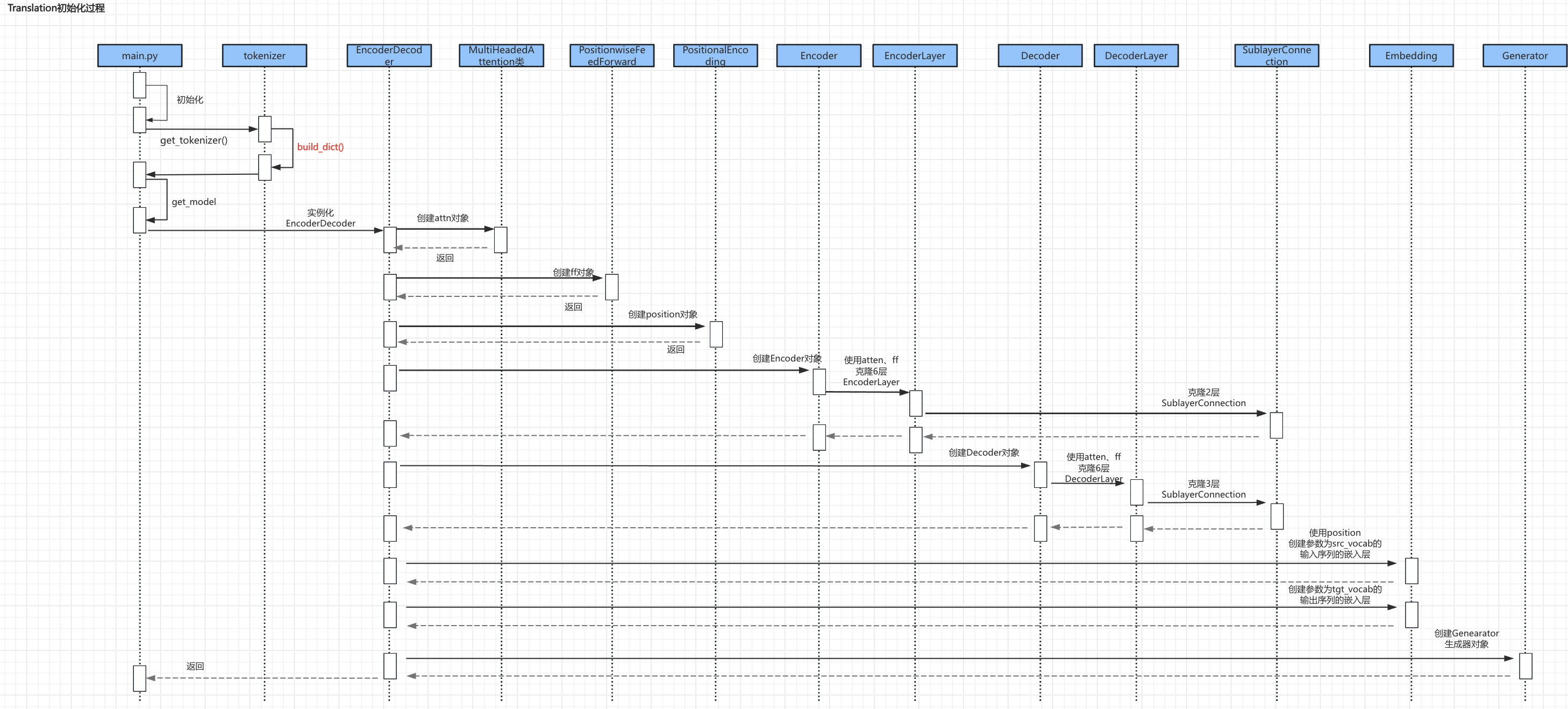
Transformer_demo的启动流程中:
- 第一步,在
main.py中进行Translation()初始化; - 第二步,调用分词器
tokenizer提供的接口get_tokenizer()进行字典的创建;(这部分逻辑实现与【课程总结】Day18:Seq2Seq的深入了解一致,所以这里不再赘述) - 第三步,调用
get_model()创建Transformer模型; - 第四步,创建过程中,主要逻辑为:实例化创建
Encoder对象和Decoder对象。(实例化之前,提前准备了多头注意力对象attn、前馈网络对象ff以及位置编码对象position) - 第五步,最后创建生成器
Genearator对象。
对应源码:
def get_model(src_vocab,
tgt_vocab,
N=6,
d_model=512,
d_ff=2048,
h=8,
dropout=0.1):
"""
构建transformer模型
src_vocab: 源语言词典大小
tgt_vocab: 目标语言词典大小
N: 编码解码层数
d_model: 模型维度
d_ff: 前向传播层维度
h: 多头注意力的头数
dropout: 随机失活概率
"""
# 深拷贝函数
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab),
)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return modelEncoderDecoder 创建过程
首先,我们从EncoderDecoder类分析代码:
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
# (下面代码暂略)代码理解:
- Transformer架构总体由一个
EncoderDecoder类构成。 EncoderDecoder类的成员变量包含五部分:encoder:编码器,负责将输入序列编码为固定长度的向量。decoder:解码器,负责将编码后的向量解码为输出序列。src_embed:输入序列的嵌入层,将输入序列转换为固定维度的向量。tgt_embed:输出序列的嵌入层,将输出序列转换为固定维度的向量。generator:生成器,将解码后的向量转换为输出序列。
Encoder 创建过程
查看 Encoder 类的结构,源码如下:
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
# (下面代码暂略)代码理解:
Encoder类的初始化函数中,分别创建了self.layers和self.norm。self.layers的创建方式是使用clones函数进行deepcopy的批量化创建clones函数可以创建指定数量的相同对象的列表。(Transformer的多层网络能力即由该函数体现)self.layers创建并实例化的layer对象,其类型为EncoderLayer。Encoder的前向传播forward函数中,会依次给每个EncoderLayer对象传入mask以便进行pad掩码操作。
self.norm对应是LayerNorm类,该类用于对输入序列进行归一化处理。
EncoderLayer 创建过程
因为 Encoder 类是由多个 EncoderLayer构成,所以接着了解EncoderLayer类。
源码如下:
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
# (下面代码暂略)代码解析:
EncoderLayer类中包含4个成员变量:self_attn:自注意力机制,用于对输入序列进行自注意力,该成员变量创建时会通过公共函数attension函数创建,并作为参数传入给self_attn成员变量。feed_forward:前馈网络,对应PositionwiseFeedForward类的对象。sublayer:包含两个SublayerConnection类的对象(对应图示中的Add&Norm),其作用是对输入序列进行归一化处理。size:输入序列的维度大小。
Decoder 创建过程
查看 Decoder 的实现,源码如下:
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
# (下面代码暂略)代码理解:
Decoder类的初始化函数中与Encoder类类似,创建了self.layers和self.norm。
DecoderLayer 创建过程
Decoder 也是由多个DecoderLayer组成,所以查看DecoderLayer的实现。
源码如下:
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
# (下面代码暂略)代码理解:(如下图所示)
Decoder相比Encoder:- 多了1个多头注意力模块,对应代码中的
src_attn。 - 多了1个Add&Norm模块,对应代码中的
sublayer的创建个数为3。

- 多了1个多头注意力模块,对应代码中的
MultiHeadedAttention 创建过程
由于Encoder和Decoder中都使用了多头注意力对象,因此查看其源码如下:
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
# (下面代码暂略)代码理解:
多头注意力对象的构造函数中,主要包含如下参数:
- h:注意力头的数量。
- d_model:模型的维度(即输入和输出的特征维度)。
- dropout:丢弃率,用于防止过拟合。
- attn:注意力对象,用于计算注意力分数。
其中atten在构造函数中为None,在前向forward函数中会调用attension函数进行实例化对象创建,该部分内容我们放在训练过程中梳理理解。
PositionwiseFeedForward 创建过程
PositionwiseFeedForward对应Transformer模型中的Feed Forward部分,其实现比较简单,源码如下:
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))代码解析:
Feed Forward功能比较简单,其组成就是两层全连接w_1和w_2,最后通过dropout进行随机丢弃以提升泛化能力。
内容小结
- 首先,代码中在
get_model()函数中调用EncoderDecoder初始化方法,构建Transformer模型。 - 其次,
Transformer模型由Encoder和Decoder组成,Encoder和Decoder都由多个EncoderLayer和DecoderLayer组成。 - 然后,
EncoderLayer和DecoderLayer都由MultiHeadedAttention和PositionwiseFeedForward组成。
参考资料
欢迎关注公众号以获得最新的文章和新闻



