前言
在上一章【课程总结】day19(下):Transformer源码深入理解总结中,我们对Transformer架构以及初始化部分做了梳理,本章我们将对Transformer训练过程进行代码分析理解。
训练流程
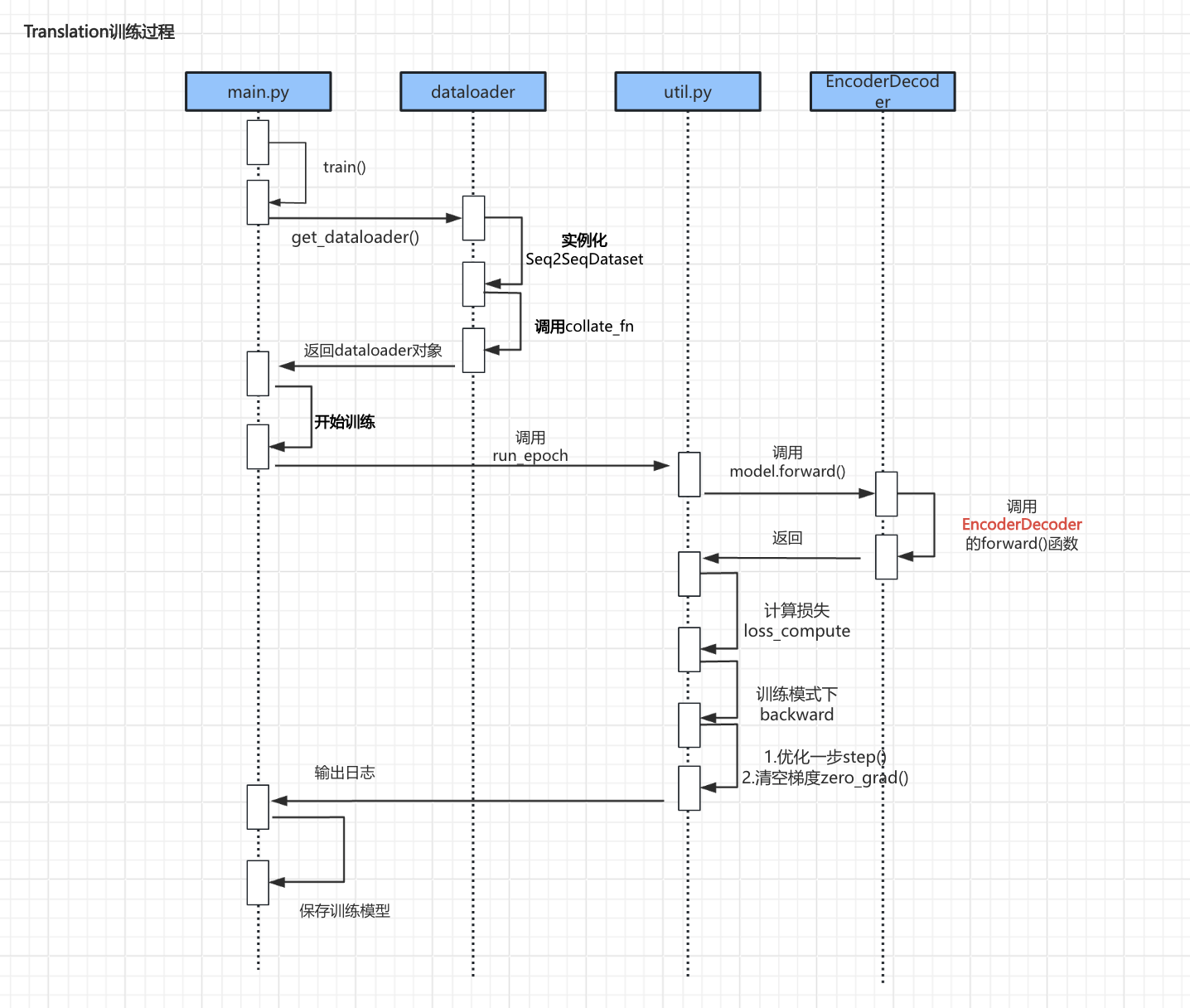
- 训练过程主要由四个主要部分组成:
- 第一部分:加载数据集。通过get_dataloader()加载数据集,这一过程与Seq2Seq类似,这里不再赘述。
- 第二部分:数据对齐。调用collate_fn()函数,对数据集整理并对齐。
- 第三部分:开始训练。调用run_epoch()函数,循环遍历dataloader中的数据集并进行训练。
- 第四部分:前向传播。在训练过程中,调用EncoderDecoder的forward()函数进行前向传播。
代码分析理解
数据对齐 collate_fn()
源码如下:
def collate_fn(batch, tokenizer):
input_sentences, input_sentence_lens, output_sentences, output_sentence_lens = zip(
*batch
)
# 转索引【按本批量最大长度来填充】
input_sentence_len = max(input_sentence_lens)
input_idxes = []
for input_sentence in input_sentences:
input_idxes.append(tokenizer.encode_input(input_sentence, input_sentence_len))
# 转索引【按本批量最大长度来填充】
output_sentence_len = max(output_sentence_lens)
output_idxes = []
for output_sentence in output_sentences:
output_idxes.append(
tokenizer.encode_output(output_sentence, output_sentence_len)
)
# 转张量 [batch_size, seq_len] src
input_idxes = torch.LongTensor(input_idxes)
# src_mask [batch_size, 1, seq_len]
input_mask = (input_idxes != tokenizer.input_word2idx.get("<PAD>")).unsqueeze(-2)
# tgt [batch_size, seq_len]
output_idxes = torch.LongTensor(output_idxes)
# tgt [batch_size, seq_len - 1] 去掉最后一个
output_idxes_in = output_idxes[:, :-1]
# tgt_y [batch_size, seq_len - 1] 去掉开头 的 SOS
output_idxes_out = output_idxes[:, 1:]
# tgt_mask [batch_size, seq_len-1, seq_len-1]
output_mask = tokenizer.make_std_mask(output_idxes_in, tokenizer.output_word2idx.get("<PAD>"))
# 记录生成的有效字符
ntokens = (output_idxes_out != tokenizer.output_word2idx.get("<PAD>")).data.sum()
# src, src_mask, tgt, tgt_mask, tgt_y, ntokens
return input_idxes, input_mask, output_idxes_in, output_mask, output_idxes_out, ntokens代码理解:
第一步:提取输入数据、输入数据长度、输出数据、输出数据长度
input_sentences, input_sentence_lens, output_sentences, output_sentence_lens = zip(
*batch
)batch:一个包含多个样本的列表;zip(*batch):将batch中的每个样本解包,分别提取出输入句子、输入句子长度、输出句子和输出句子长度。
示例理解:
input_sentences: output_sentences:
['I', 'm', 'sick', '.'] ['我', '病' , '了', '。']
['I', 'm', 'tall', '.'] ['我', '个子' , '高', '。']
['Leave', 'me', '.'] ['让', '我', '一个人', '呆','会', '儿','。']
input_sentence_lens: output_sentence_lens:
[4, 4, 3] [4, 4, 7]
第二步:对数据进行填充
# 输入的最大长度为4,所以input_idxes填充为
['I', 'm', 'sick', '.']
['I', 'm', 'tall', '.']
['Leave', 'me', '.', '<PAD>']
# 输出的最大长度为7,所以output_idxes填充为
['<SOS>', '我', '病' , '了', '。', '<EOS>', '<PAD>', '<PAD>', '<PAD>']
['<SOS>', '我', '个子' , '高', '。', '<EOS>', '<PAD>', '<PAD>', '<PAD>']
['<SOS>', '让', '我', '一个人', '呆', '会', '儿', '。', '<EOS>']第三步:生成input的mask
input_mask = (input_idxes != tokenizer.input_word2idx.get("<PAD>")).unsqueeze(-2)- 输入位置不为
<PAD>的位置,值为1,否则为0,从而形成mask。
第四步:生成错位的output
# tgt [batch_size, seq_len - 1] 去掉最后一个
output_idxes_in = output_idxes[:, :-1]
# 例如:['<SOS>', '让', '我', '一个人', '呆', '会', '儿', '。']
# tgt_y [batch_size, seq_len - 1] 去掉开头 的 SOS
output_idxes_out = output_idxes[:, 1:]
# 例如:['让', '我', '一个人', '呆', '会', '儿', '。', '<EOS>']第五步:生成output的mask
output_mask = tokenizer.make_std_mask(output_idxes_in, tokenizer.output_word2idx.get("<PAD>")) def make_std_mask(cls, tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & Tokenizer.subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data)
return tgt_mask代码理解:
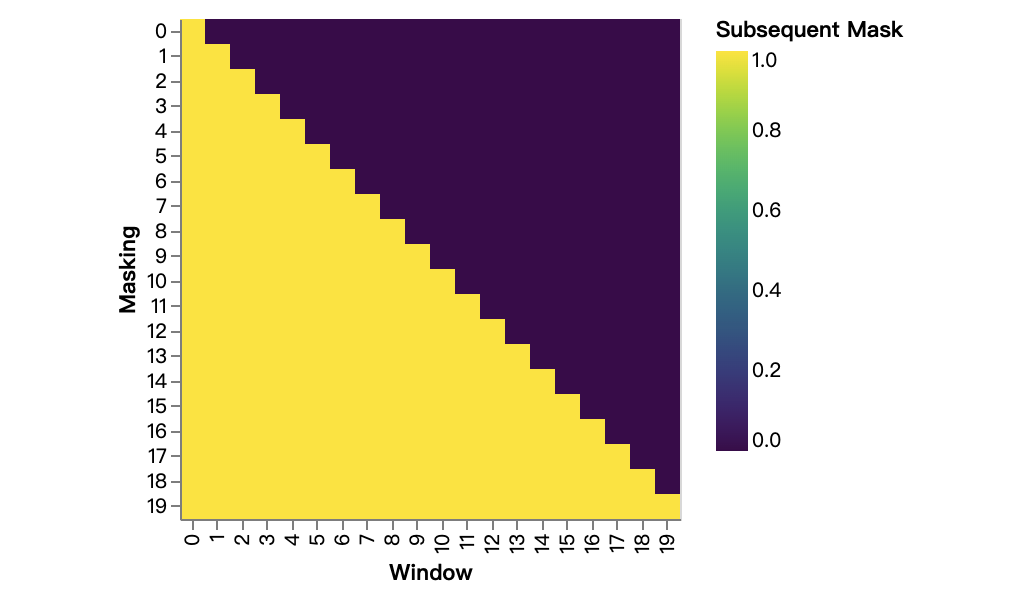
- 因为decoder的掩码多头注意力(mask MultiHeadAttention),既要屏蔽无效的PAD,同时还要屏蔽未来词。
- 所以tgt_mask是由
tgt_mask & Tokenizer.subsequent_mask两部分按位与运算,即两者都为1才是有效的,如果有一个为0,则对应数据被遮挡。 Tokenizer.subsequent_mask是生成一个三角矩阵,如下图:
开始训练 run_epoch()
def run_epoch(
data_iter,
model,
loss_compute,
optimizer,
scheduler,
mode="train",
accum_iter=1,
train_state=TrainState(),
device="cpu"
):
"""
Train a single epoch
"""
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
n_accum = 0
for i, (src, src_mask, tgt, tgt_mask, tgt_y, ntokens) in enumerate(data_iter):
#
src = src.to(device=device)
tgt = tgt.to(device=device)
tgt_y = tgt_y.to(device=device)
# src = src.to(device=device)
out = model.forward(src, tgt, src_mask, tgt_mask)
loss, loss_node = loss_compute(out, tgt_y, ntokens)
# loss_node = loss_node / accum_iter
if mode == "train" or mode == "train+log":
loss_node.backward()
train_state.step += 1
train_state.samples += src.shape[0]
train_state.tokens += ntokens
if i % accum_iter == 0:
optimizer.step()
optimizer.zero_grad(set_to_none=True)
n_accum += 1
train_state.accum_step += 1
scheduler.step()
total_loss += loss
total_tokens += ntokens
tokens += ntokens
if i % 40 == 1 and (mode == "train" or mode == "train+log"):
lr = optimizer.param_groups[0]["lr"]
elapsed = time.time() - start
print(
(
"Epoch Step: %6d | Accumulation Step: %3d | Loss: %6.2f "
+ "| Tokens / Sec: %7.1f | Learning Rate: %6.1e"
)
% (i, n_accum, loss / ntokens, tokens / elapsed, lr)
)
start = time.time()
tokens = 0
del loss
del loss_node
return total_loss / total_tokens, train_state代码理解:
- 从
data_iter中循环获取源数据、目标数据及其掩码。src:输入侧数据,例如: "Hello, how are you?" 对应的是 [101, 7592, 2024, 2017, 2011, 102]。src_mask:输入侧的掩码,对应padding mask。tgt:输出侧输入数据,即通过上文输入数据预测的下文数据。tgt_mask:输出侧的掩码,包含padding mask和subsequence mask两种作用。tgt_y:目标标签,用于计算损失的真实输出序列。ntokens:当前批次中的有效token数量。
EncoderDecoder的forward()函数
该部分对应训练过程中时序图的EncoderDecoder.forward()函数,由于该函数调用深度较多,所以采用函数调用栈形式梳理其过程。
EncoderDecoder.forward()
│
├── self.encode()
│ ├── embeddings.forward() # 对应input Embedding
│ ├── Positional.forward() # 对应position Encoding
│ └── 进行 Encoder.layers 循环遍历 # N 层循环遍历,代码中N=6
│ └── EncoderLayer.forward()
│ ├── self.sublayer[0] # 第一层多头注意力处理部分
│ │ ├── SublayerConnection.forward()
│ │ │ ├── LayerNorm.forward() # 对应Add&Norm
│ │ └── MultiHeadedAttention.forward() # 对应Multi-Head Attention
│ └── self.sublayer[1] # 第二层Feed Forward处理部分
│ ├── SublayerConnection.forward()
│ │ ├── LayerNorm.forward() # 对应Add&Norm
│ └── PositionwiseFeedForward.forward() # 对应Feed Forward
│
├── self.decoder()
│ ├── embeddings.forward() # 对应output Embedding
│ ├── Positional.forward() # 对应position Encoding
│ └── 进行 Decoder.layers 循环遍历 # N 层循环遍历,代码中N=6
│ └── DecoderLayer.forward()
│ ├── self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
│ │ ├── SublayerConnection.forward()
│ │ │ ├── LayerNorm.forward()
│ │ └── MultiHeadedAttention.forward() # 对应多头掩码处理部分
│ ├── self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
│ │ ├── SublayerConnection.forward()
│ │ │ ├── LayerNorm.forward()
│ │ └── MultiHeadedAttention.forward() # 融合注意力处理部分
│ └── self.sublayer[2](x, self.feed_forward)
│ ├── SublayerConnection.forward()
│ │ ├── LayerNorm.forward()
│ └── PositionwiseFeedForward.forward() # 对应Feed Forward
- 对照【课程总结】day19(中):Transformer架构及注意力机制了解中的宏观流程,上述代码调用栈与架构图一一对应。
- 第一步:输入侧input数据首先经过
embeddings.forward()和Positional.forward()处理。 - 第二步:在Encoder中通过N层EncoderLayer进行遍历,其中
self.sublayer[0]对应输入的多头注意力方框部分,self.sublayer[1]对应前馈网络。 - 第三步:输出侧output的上文数据通用经过
embeddings.forward()和Positional.forward()处理。 - 第四步:在Decoder中通过N层DecoderLayer进行遍历,其中
self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))对应输出的上文多头注意力方框部分self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))对应融合注意力方框部分
接下来,我们按顺序依次查看对应函数的实现过程。
embeddings.forward()
class Embeddings(nn.Module):
# 初始化部分在启动流程已介绍,此处省略
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)- 作用:Embeddings模块用于将输入的整数序列转换为对应的词向量。
- 构成:在Transformer中,Embeddings模块由两个线性层组成:
- 第一个线性层将整数序列转换为词向量
- 第二个线性层将词向量转换为d_model维度的向量。
Positional Encoding
由于时序数据要进行并行计算的的问题(详细背景不再赘述,具体内容可见【课程总结】day19(下):Transformer架构及注意力机制了解),所以在Transformer架构中,需要为序列中的每个词添加一个位置编码。
源码如下:
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)以上代码中最为重要的部分为:计算编码部分
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)第一步:创建位置编码矩阵
pe = torch.zeros(max_len, d_model):创建一个形状为 (max_len, d_model) 的全零张量,用于存储位置编码。position = torch.arange(0, max_len).unsqueeze(1):生成一个从 0 到max_len-1的张量,并在第二个维度上增加一个维度,使其形状为(max_len, 1)。
第二步:计算分母项
计算公式:
\text{div\_term} = \exp\left(\text{arange}(0, d\_model, 2) \times -\frac{\log(10000)}{d\_model}\right)- d_model:模型的维度,表示每个词的嵌入向量的大小。
第三步:使用正弦和余弦函数
pe[:, 0::2] = torch.sin(position * div_term):对偶数索引的维度使用正弦函数计算位置编码。pe[:, 1::2] = torch.cos(position * div_term):对奇数索引的维度使用余弦函数计算位置编码。
第四步:将位置编码添加到词嵌入中
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
x + self.pe[:, : x.size(1)].requires_grad_(False):将位置编码加到输入 x 上,提供位置信息。requires_grad_(False)确保位置编码在反向传播中不会被更新。
Encoder
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
代码解析:
forward函数中:- self.sublayer[0]代表两个
SublayerConnection实例的列表第一个子层,即自注意力机制的连接。 lambda x: self.self_attn(x, x, x, mask)是一个匿名函数,它接收输入x并执行self.self_attn(x, x, x, mask)自注意力计算.self.self_attn(x, x, x, mask)表示使用输入x作为查询(Q)、键(K)和值(V),同时传入mask。- 然后,SublayerConnection 将处理这个输出,通常包括残差连接和层归一化。
- self.sublayer[0]代表两个
attention函数
在了解多头注意力MultiHeadedAttention.forward()函数之前,我们首先梳理注意力机制attention的计算逻辑。
源码如下:
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
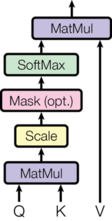
return torch.matmul(p_attn, value), p_attn- 作用:
attention函数用于计算“缩放点积注意力”(Scaled Dot Product Attention) - 计算过程:(博客中的示意图如下)
第一步:计算维度
d_k = query.size(-1)- 作用:获取查询向量的最后一个维度大小 d_k,用于后续的缩放。
- 理解示例:
# 假设query内容为:
query = torch.tensor([
[1.0, 0.0],
[0.0, 1.0]])
# shape: (2, 2)
d_k = query.size(-1)
# d_k = 2第二步:计算注意力得分
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)- 作用:计算查询与键的点积,并进行缩放。
key.transpose(-2, -1)将键的最后两个维度交换,以便进行矩阵乘法。 - 理解示例:
# 假设query内容为:
query = torch.tensor([
[1.0, 0.0],
[0.0, 1.0]])
# 假设key内容为:
key = torch.tensor([
[1.0, 0.0],
[0.0, 1.0],
[0.5, 0.5]])
# shape: (3, 2)
# 转置:key.transpose(-2, -1)表示转置张量,-1代表最后一个维度,-2代表倒数第二个维度
# 转置后结果:
# tensor([[1.0, 0.0, 0.5],
# [0.0, 1.0, 0.5]])
# 点积计算:
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 点积计算结果:
# scores = [
# [1.0, 0.0, 0.5],
# [0.0, 1.0, 0.5]]
# shape: (2, 3)第三步:应用遮蔽
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)- 作用:如果提供了遮蔽矩阵,将得分中相应位置的值设置为 -1e9,这样在 softmax 计算时会被忽略。
- 理解示例:
# scores = [
# [1.0, 0.0, 0.5],
# [0.0, 1.0, 0.5]]
# 遮蔽矩阵
mask = torch.tensor([
[1, 1, 0],
[1, 1, 1]])
scores = scores.masked_fill(mask == 0, -1e9)
# 遮蔽计算后结果:
# scores = [
# [1.0, 0.0, -1e9],
# [0.0, 1.0, 0.5]]
第四步:计算注意力权重
- 作用:对得分应用 softmax 函数,得到注意力权重 p_attn
- 理解示例:
# 上一步结果为:
# scores = [
# [1.0, 0.0, -1e9],
# [0.0, 1.0, 0.5]]
p_attn = scores.softmax(dim=-1)
# 计算结果:
# p_attn = [
# [0.7311, 0.2689, 0.0000],
# [0.2689, 0.7311, 0.0000]]
第五步:应用dropout
- 作用:如果提供了 dropout 层,则使用 dropout 层进行随机丢弃一部分神经元。
- 理解示例:
# 假设 dropout 概率为 0.5
# p_attn 可能变为 [
# [0.0, 0.0, 0.0],
# [0.2689, 0.7311, 0.0]]
# 形状仍为 (2, 3)关于dropout层的作用,可以查看【课程总结】Day10:卷积网络的基本构成回顾
第六步:计算输出
- 作用:将注意力权重与值向量相乘,得到最终的输出,同时返回注意力权重 p_attn。
- 理解示例:
# 假设value内容为
value = torch.tensor([
[10.0, 20.0],
[30.0, 40.0],
[50.0, 60.0]])
# shape: (3, 2)
# 假设上一步p_attn内容为
# [0.0, 0.0, 0.0],
# [0.2689, 0.7311, 0.0]]
output = torch.matmul(p_attn, value)
# 点积计算结果:
# output = [
# [0.0 * 10 + 0.0 * 30 + 0.0 * 50,
# 0.0 * 20 + 0.0 * 40 + 0.0 * 60],
# [0.2689 * 10 + 0.7311 * 30 + 0.0 * 50,
# 0.2689 * 20 + 0.7311 * 40 + 0.0 * 60]]
# output = [[0.0, 0.0], [21.05, 31.05]]MultiHeadedAttention.forward()
class MultiHeadedAttention(nn.Module):
# 初始化部分在启动流程已介绍,此处省略
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)代码理解:
第一步:接受参数
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
query、key、value:对应输入的查询(Q)、键(K)和值(V)张量mask:可选的遮蔽张量,用于在计算注意力时忽略某些位置。
第二步:线性变换和重塑
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]query,key,value接受列表,分别对应输入的查询(Q)、键(K)和值(V)张量。- […]中内容为推导式
- 首先,查看
for lin, x in zip(self.linears, (query, key, value)),其作用是:依次遍历self.linears和(query, key, value)列表,将每个元素分别传入lin函数中。 - 然后,通过
lin(x)对输入进行线性变换,并使用view()函数重塑张量的形状,重塑结果为(nbatches, -1, h, d_k) - 然后,通过
transpose(1, 2)将维度调整为(nbatches, h, seq_length, d_k)
- 首先,查看
第三步:应用注意力机制
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)- 应用之前已经分析过的attension函数进行注意力计算。
- 返回的
x是注意力的输出,而self.attn是注意力权重。
第四步:连接和最终线性变换
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)
- 使用
transpose(1, 2)将输出的维度调整为(nbatches, seq_length, h)。 - 使用
contiguous()确保数据在内存中是连续的(对于后续的 view 操作是必要的)。 - 重塑为
(nbatches, -1, h * d_k),将所有头的输出连接在一起。 - 最后,通过最后一个线性层
self.linears将输出变换为 d_model 维度。 - del 语句用于删除中间变量,以减少内存占用。
Decoder
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)代码理解:
Decoder类的前向传播forward函数中,会通过x = layer(x, memory, src_mask, tgt_mask)传递给每个DecoderLayer对象x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))对应掩码多头注意力处理部分。x = self.sublayer[1](x, lambda x: self.src_attn(x, memory, memory, src_mask))对应融合注意力处理部分。
至此,整体训练流程已经梳理完成。
数据形状梳理
由于shape形状(俗称对口型)在Transformer模型实现中极为重要,同时也便于我们理解整个Transformer的实现过程,所以我们对整体流程中的关键形状做一次梳理盘点。
1. 初始输入 src、src_mask、tgt、tgt_mask、tgt_y
for i, (src, src_mask, tgt, tgt_mask, tgt_y, ntokens) in enumerate(data_iter):
# src的形状: [1024, 24]
# src_mask的形状: [1024, 1, 24]
# tgt的形状: [1024, 22]
# tgt_mask的形状: [1024, 22, 22]
# tgt_y的形状: [1024, 22]
# 以下代码省略...说明:
src的形状:(batch_size,seq_len) – [1024, 24]
1024:一次处理的样本数量,例如:1024句话。24:输入序列的长度,例如:最长的长度为24个词。
src_mask的形状:(batch_size, 1, seq_len) – [1024, 1, 24]
src_mask是输入序列的掩码,用于指示哪些位置是有效的,哪些是填充(padding)位置。- 其形状与
src类似,只不过中间多了1个维度,通常表示头数。
tgt的形状:(batch_size,target_seq_len) – [1024, 22]
tgt表示目标序列(输出序列),即模型在训练过程中要生成的序列。22:目标序列的长度。
tgt_mask的形状:(batch_size, target_seq_len, target_seq_len) – [1024, 22, 22]
tgt_mask是目标序列的掩码,用于控制自回归生成过程中的注意力机制。22, 22形成一个二维掩码矩阵,用于指示在计算注意力时哪些位置可以被关注(有效位置)和哪些位置需要被遮蔽(无效位置)。
2. 经过嵌入层 (Embeddings)
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
# x的形状:[1024, 24]
# lut(x)的形状:[1024, 24, 512]说明:
lut(x) 的形状:(batch_size, seq_len, d_model) – [1024, 24, 512]
d_model:嵌入向量的维度,例如:1024句话,每句话24个词,每个词有512个特征。
3. 位置编码 (PositionalEncoding)
def forward(self, x):
x = x + self.pe[:, : x.size(1), :].requires_grad_(False)
return self.dropout(x)
# x的形状:[1024, 24, 512]
# pe的形状:[1, 5000, 512]
# return:[1024, 24, 512]说明:
- pe的形状:
(1, 5000, 512),代表位置编码的形状,其中5000是位置编码的维度,512是嵌入向量的维度。 self.pe[:, : x.size(1), :],代表取出位置编码矩阵的前x.size(1)个位置,即24个位置。- 经过上述预算,形状仍然为
[1024, 24, 512]。
4. 编码器层(Encoder)
4.1 Add&Norm
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
# x的形状:[1024, 24, 512]
# mean的形状:[1024, 24, 1]
# std的形状:[1024, 24, 1]说明:
mean和std在求均值和标准差时,是对dim=512的维度求均值和标准差。
4.1 自注意力机制(MultiHeadedAttention)
def forward(self, query, key, value, mask=None):
# (相关代码已省略)
# query,key,value的形状:[1024, 24, 512]
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# query, key, value的形状:[1024, 8, 24, 64]
# (相关代码已省略)说明:
query、key、value的形状:[1024, 8, 24, 64]- 经过分头和线性转换,
query、key、value的形状从[1024, 24, 512]变为[1024, 8, 24, 64]。 [1024, 8, 24, 64]表示1024句话,8个头,每个头都是24个词,每个词64个特征。
def attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1)
# key的形状:[1024, 8, 24, 64]
# mask的形状:[1024, 1, 1, 24]
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# key.transpose(-2, -1) 的形状:[1024, 8, 64, 24]
# scores的形状:[1024, 8, 24, 24]
if mask is not None:
mask = mask.to(device=device)
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
# p_attn的形状:[1024, 8, 24, 24]
if dropout is not None:
p_attn = dropout(p_attn)
# value的形状:[1024, 8, 24, 64]
return torch.matmul(p_attn, value), p_attn
# 返回:[1024, 8, 24, 64]说明:
key.transpose(-2, -1):将key的最后两个维度交换,形状变为[1024, 8, 64, 24]scores的形状是[1024, 8, 24, 24],表示每个 query 与所有 key 的相似度得分。p_attn的形状是[1024, 8, 24, 24],表示每个 query 对所有 key 的注意力权重。value的形状为[1024, 8, 24, 64],即1024句话,8个头,每个头都是24个词,每个词64个特征。- 返回的加权值和注意力权重的形状分别为
[1024, 8, 24, 64]和[1024, 8, 24, 24]。
# x的形状:[1024, 8, 24, 64]
# x.transpose(1, 2)的形状: [1024, 24, 8, 64]
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
# x的形状:[1024, 24, 512]说明:
x.transpose(1, 2)将[1024, 8, 24, 64]转置为[1024, 24, 8, 64]x.contiguous().view(nbatches, -1, self.h * self.d_k)将多头重塑为[1024, 24, 512]
5. 解码器层(Decoder)
class DecoderLayer(nn.Module):
# (相关代码已省略)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
# x的形状:[1024, 22, 512]
# memory的形状:[1024, 24, 512]
# src_mask的形状:[1024, 1, 24]
# tgt的形状:[1024, 22]
# tgt_mask的形状:[1024, 22, 22]说明:
x对应的是输出侧的上文,即self.tgt_embed(tgt),也就是在初始化时tgt经过embed,由形状[1024, 22]变为[1024, 22, 512]x的形状是[1024, 22, 512]。memory对应的是编码器的输出,即self.encode(src, src_mask),所以其形状为[1024, 24, 512]。src_mask对应的是编码器的掩码,在1.初始化中传入的形状为[1024, 1, 24]。tgt_mask对应的是解码器的掩码,是作用于x的,所以其形状为[1024, 22, 22]。
5.1 目标嵌入(Embeddings)
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
# x的形状:[1024, 22]
# lut(x)的形状:[1024, 22, 512]5.2 位置编码(PositionalEncoding)
def forward(self, x):
x = x + self.pe[:, : x.size(1), :].requires_grad_(False)
return self.dropout(x)
# x的形状:[1024, 22, 512]
# pe的形状:[1, 5000, 512]
# return:[1024, 22, 512]5.3 自注意力机制(Masked MultiHeadedAttention)
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))说明:
tgt_mask对应的是输出侧上文的mask,形状是[1024, 22, 22],对应mask类型为subsquence mask和padding mask。- 备注:因为输出侧是一个一个词自回归生成的,所以还没有生成的词(即未来词)要通过subsquence mask进行掩码。
mask的类型以及作用,可以查看【课程总结】day19(中):Transformer架构及注意力机制了解进行回顾。
5.4 融合注意力机制(MultiHeadedAttention)
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
# x的形状:[1024, 22, 512]
# m的形状:[1024, 24, 512]
# src_mask的形状:[1024, 1, 24]说明:
x对应经过自注意力处理的输出侧上文内容,其含义表示是Q(查询部分),形状为[1024, 22, 512]m对应输入侧上文内容,其含义表示是K(键部分)和V(值部分),形状为[1024, 24, 512]
备注:在注意力计算中,
Q、K和V的长度不同时,可以进行注意力计算。
例如:Q的长度为 22 个词,K和V的长度为 24 个词。Q与K进行点积计算、掩码及softmax后,得到形状为 [22, 24] 的注意力权重矩阵。- 最后,使用上述权重对
V进行加权求和,得到与Q的长度相同的结果,即 22。
6. 计算损失
loss, loss_node = loss_compute(out, tgt_y, ntokens)
# out的形状:[1024, 22, 512]
# tgt_y的形状:[1024, 22]class SimpleLossCompute(object):
# 此处代码已省略
def __call__(self, x, y, norm):
x = self.generator(x)
sloss = (
self.criterion(
x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1))
/ norm
)
return sloss.data * norm, sloss
# x的形状:[1024, 22, 512]
# self.generator后的形状:[1024, 22, 12547]
# x.size(-1)表示取x张量的最后一维的大小,对应12547
# 原始张量x的总元素个数是1024×22×12547,新张量的形状是[a, 12547]
# a=(1024×22×12547)/12547 = 1024×22 = 22528
# x.contiguous().view(-1, x.size(-1))的形状:[22528, 12547]
# y.contiguous().view(-1)的形状:[22528]说明:
self.generator的形状是[batch_size, seq_len, vocab_size]–[1024, 22, 12547]。1024:批量大小,即1024句话。22:序列长度,即22个词。12547:词表大小,即12547个词。
x.contiguous().view(-1, x.size(-1))将输出张量 x 重新形状为[batch_size * seq_len, vocab_size]以便计算损失。y.contiguous().view(-1)将真实标签y重新形状为一维张量[batch_size * seq_len]- 最后,使用损失函数
criterion计算损失,并除以norm进行归一化。
内容小结
- 训练过程的代码主要由四部分内容组成:
- 第一部分:加载数据集。通过
get_dataloader()加载数据集,这一过程与Seq2Seq类似。 - 第二部分:数据对齐。调用collate_fn()函数,对数据集整理并对齐。
- 第三部分:开始训练。这一部分通过
run_epoch()函数,循环遍历dataloader中的数据集并进行训练。 - 第四部分:前向传播。在训练过程中,调用EncoderDecoder的forward()函数进行前向传播。
- 第一部分:加载数据集。通过
- 数据对齐的过程中核心的逻辑有三个:
- 通过获取批量的输入数据的最大长度,对每一条数据补齐PAD。
- 通过对比是否为PAD计算得到input_mask,用于对PAD进行掩码。
- output因为在自回归的时候需要错位,所以out_idxes_in会去掉最后一位,out_idxex_out会去掉开头的SOS
- decoder的多头注意力需要padding mask和subsequent mask,所以其是通过
tgt_mask & Tokenizer.subsequent_mask按位与运算实现。
- 多头注意力计算过程大致由以下几步构成:
- 第一步:接受参数:接受输入的查询(Q)、键(K)和值(V)张量
- 第二步:线性变换:通过三个线性变换,分别将查询、键和值映射到不同的维度。
- 第三步:应用注意力attension函数,该函数包括以下步骤:
- 计算维度:获取查询向量的最后一个维度大小 d_k,用于后续的缩放。
- 计算注意力得分:计算查询向量与键向量的点积,并进行缩放。
- 应用遮蔽:如果提供了遮蔽矩阵,将得分中相应位置的值设置为 -1e9,这样在 softmax 计算时会被忽略。
- 计算注意力权重:对得分应用 softmax 函数,得到注意力权重 p_attn。
- 计算输出:将注意力权重与值向量相乘,得到最终的输出。
- 第四步:连接和最终线性变换:将注意力的输出进行连接,并使用一个线性层进行最终的线性变换。
参考资料
欢迎关注公众号以获得最新的文章和新闻



