
前言
在上一章【课程总结】day25:大模型应用之Prompt的初步了解的学习中,我们了解了大模型上层开发中Prompt的基本流程。本章,我们将对Prompt进行扩展学习,包括:piplineprompt、MessagePlaceholder消息占位符、CommaSeparatedListOutputParser输出解析器、DatetimeOutputParser日期输出解析器、EnumOutputParser枚举输出解析器、StructuredOutputParser结构化输出解析器、PydanticOutputParserPydantic输出解析器等。
LangChain框架构成

LangChain的架构图一直在更新,上述为 v1.0 的架构图
地址:https://python.langchain.com/v0.1/docs/get_started/introduction/
LangChain 的整体架构主要由以下几个组件构成:LangSmith、LangServe、Templates、LangChain-Community 和 LangChain-Core。
-
LangChain-Core
简介:LangChain-Core是LangChain的核心库,提供了基本的功能和模块,支持构建和管理链式应用程序。
组件:包括用于处理文本、数据、模型调用等的基本工具和接口。
作用:通过LangChain-Core,开发者可以轻松集成不同的语言模型以创建对话系统。 -
LangChain-Community
简介:LangChain-Community是一个社区驱动的部分,包含来自开发者和用户的贡献和扩展。
组件:包含来自开发者和用户的社区贡献模块、插件库、讨论论坛等一套生态系统。
作用:通过使用LangChain-community中的 插件库(例如:Tongyi),可以快速连接对应的大模型(例如:阿里的通义千问大模型)。 -
Templates
简介:Templates提供了一系列预定义的模板和示例,帮助开发者快速构建常见的应用场景。
组件:示例模板库、用例指南、快速启动工具。
作用:通过使用Templates,开发者可以轻松创建FAQ系统,而无需从头开始编写代码。 -
LangServe
简介:LangServe是一个服务框架,用于将LangChain应用部署为可访问的 API。
组件:API 构建工具、部署管理模块、请求处理接口。
用途:通过使用LangServe,用户可以将聊天机器人应用快速部署为可访问的 API,方便其他系统集成。 -
LangSmith
功能:LangSmith是一个工具,旨在帮助开发者在构建和调试LangChain应用时进行更好的管理和监控。
组件:可视化监控界面、调试工具、性能分析仪。
功能:通过使用LangSmith,开发者可以实时监控应用的运行状态,快速识别并解决问题。
LangChain 的整体架构可以视为一个模块化的系统,各个组件相互协作,形成了一个强大的链式应用开发平台。通过 LangChain-Core 提供的基础功能,结合 LangSmith 的管理工具、LangServe 的部署能力、Templates 的快速开发支持以及 LangChain-Community 的丰富资源,开发者能够高效地构建和发布基于语言模型的应用。
在LangChain的官网,可以找到对应API文档连接,其中详细介绍了各个模块的API使用说明。
地址:https://api.python.langchain.com/en/latest/langchain_api_reference.html
LangChain-Community
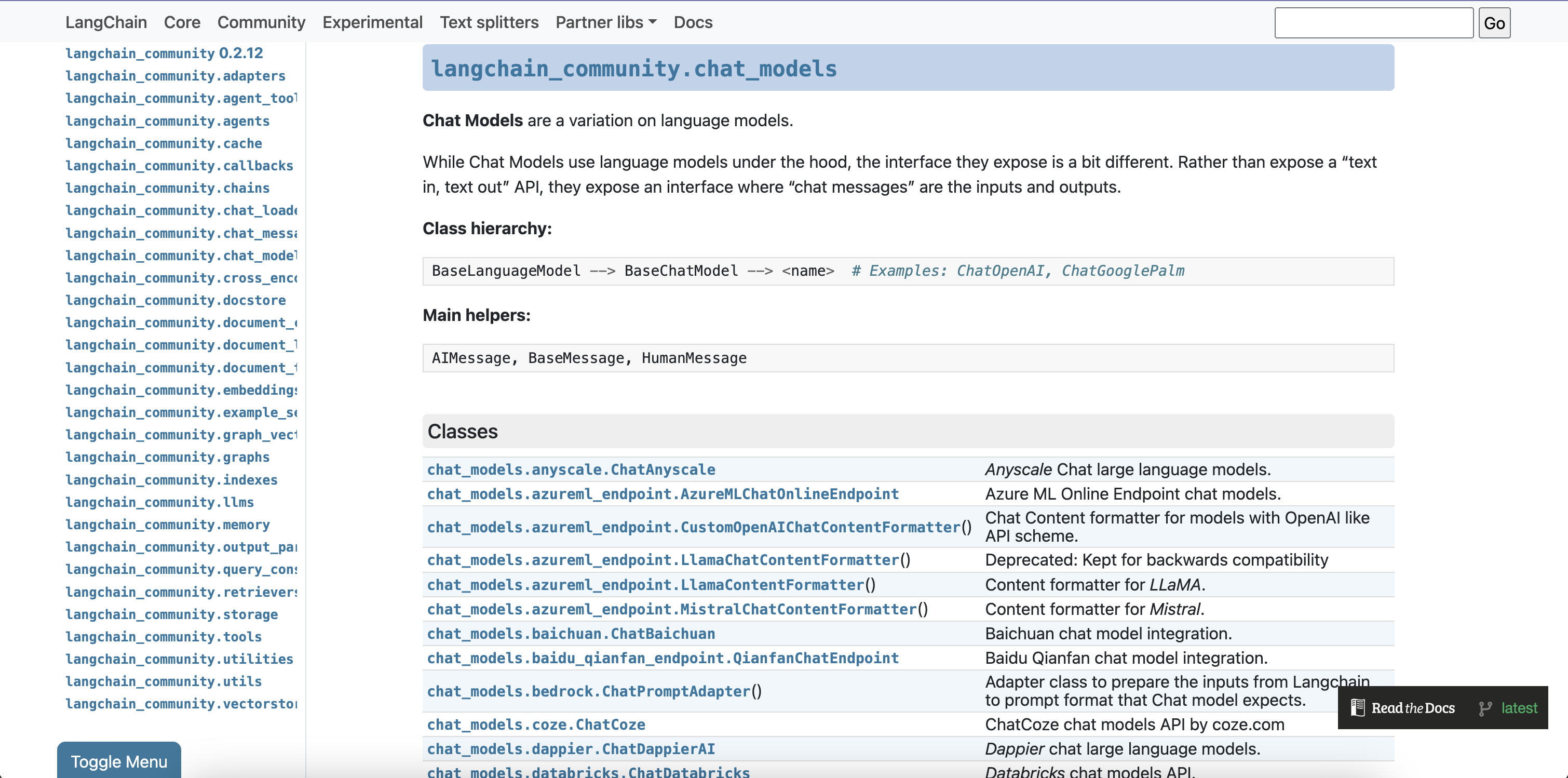
在LangChain-Community中,提供了大量的第三方大模型连接方法,例如:
chat_models.azureml_endpoint.CustomOpenAIChatContentFormatter:OpenAI API 格式化器,用于处理与 OpenAI 类似的聊天模型内容。chat_models.baichuan.ChatBaichuan:百川大模型的整合包,可以连接百川大模型。chat_models.baidu_qianfan_endpoint.QianfanChatEndpoint:百度 Qianfan 聊天模型的整合包,可以接入百度的聊天服务。chat_models.google_palm.ChatGooglePalm:Google PaLM 聊天模型的 API,可以访问 Google 提供的聊天服务。chat_models.hunyuan.ChatHunyuan:腾讯 Hunyuan 聊天模型的 API,可以接入腾讯的聊天服务。chat_models.ollama.ChatOllama:Ollama 本地运行的大语言模型,可以在本地进行聊天。chat_models.pai_eas_endpoint.PaiEasChatEndpoint:阿里云 PAI-EAS 聊天模型的 API,可以接入阿里云的聊天服务。chat_models.tongyi.ChatTongyi:阿里巴巴 Tongyi Qwen 聊天模型的整合包,可以接入阿里巴巴的聊天服务。
务。chat_models.zhipuai.ChatZhipuAI:ZhipuAI 聊天模型的整合包,可以接入 ZhipuAI 提供的聊天服务。
连接第三方大模型
在【课程总结】day25:大模型应用之Prompt的初步了解,我们已尝试连接过阿里云的通义千问大模型。本次,我们尝试连接百度的文心一言大模型。
第一步:访问百度千帆大模型官网注册/登录账号,
第二步:在应用接入->创建应用->输入应用名称和应用描述->点击创建应用
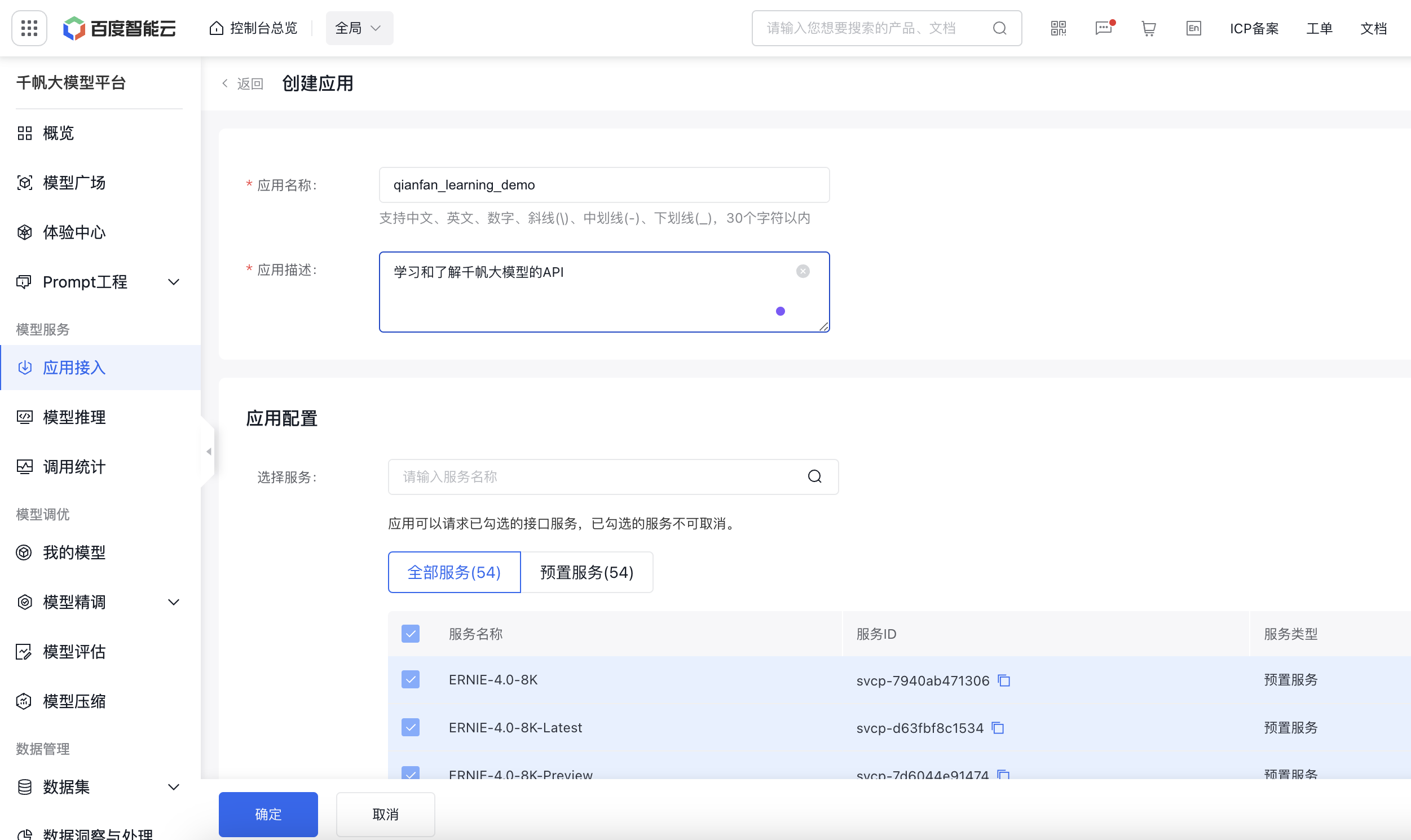
第三步:在计费管理->选择开通付费->完成个人认证->开通免费服务(千帆有一些服务是免费的,试用期间可以选择这些免费服务)
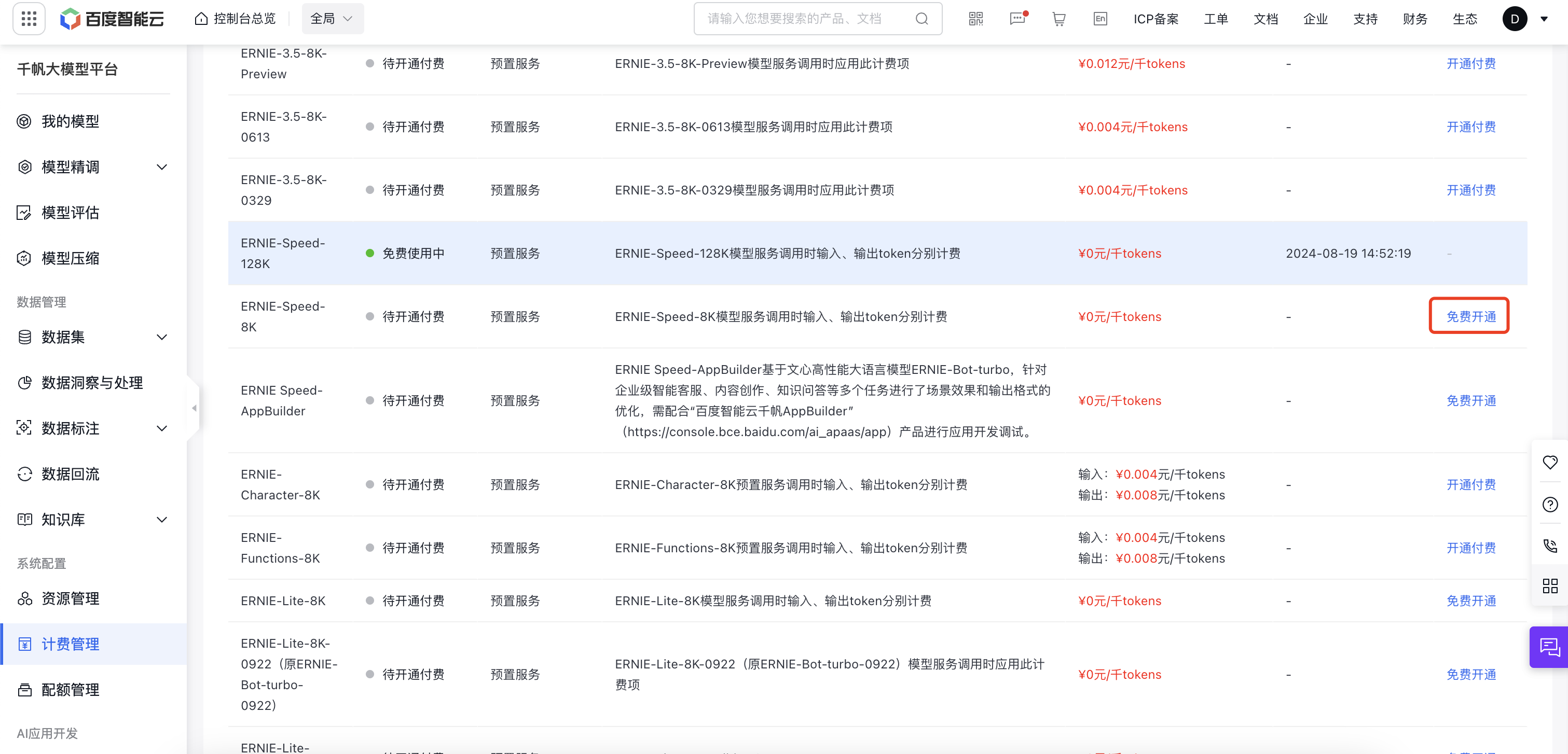
第四步:复制应用的API KEY 和 Secret KEY内容,保存到文件.ernie中,文件格式为:
QIANFAN_AK="zbxxxx"
QIANFAN_SK="cSRxxxx"关于API KEY的格式,在Baidu Qianfa API文档中有说明。
第五步:安装qianfan组件
pip install qianfan第六步:实现聊天模型的代码
from dotenv import load_dotenv
# LLM 大语言模型(单轮对话版)
from langchain_community.llms import QianfanLLMEndpoint
# Chat 聊天版大模型(支持多轮对话)
from langchain_community.chat_models import QianfanChatEndpoint
# Embeddings 嵌入模型
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
# 加载千帆大模型的APK-KEY
load_dotenv(dotenv_path=".ernie")
# 连接大模型
llm = QianfanLLMEndpoint(model="ERNIE-Bot-turbo",
temperature=0.1,
top_p=0.2)
chat = QianfanChatEndpoint(model='ERNIE-Lite-8K', top_p=0.2, temperature=0.1)
embed = QianfanEmbeddingsEndpoint(model='bge-large-zh')
llm.invoke("你是谁?")
chat.invoke("你是谁?")
result = embed.embed_query("你好")注意:
- 如果导入langchain_community失败,请记得
pip install langchain-community。- 如果连接失败提示error code: 17,请检查对应model id在计费管理中是否已开通服务。
至此,使用LangChain-Community连接百度千帆大模型已成功连接。接下来,我们熟悉LangChain的另外一个模块LangChain-Core。
LangChain-Core
Prompt基础用法回顾
在【课程总结】day25:大模型应用之Prompt的初步了解中,我们以及了解Prompt的基础使用用法:
# 连接模型
chat = ChatTongyi(model='qwen-plus',
top_p=0.9,
temperature=0.9)
# 构建Prompt模板
sys_msg = SystemMessagePromptTemplate.from_template(template="这是一个创意文案生成专家。")
user_msg = HumanMessagePromptTemplate.from_template(template="""
用户将输入几个产品的关键字,请根据关键词生成一段适合老年市场的文案,要求:成熟,稳重,符合老年市场的风格。
用户输入为:{ad_words}。
营销文案为:
""")
messages = [sys_msg, user_msg]
prompt = ChatPromptTemplate.from_messages(messages=messages)
# 使用管道符 | 连接多个模型,构建chain链
chain = prompt | chat | StrOutputParser()
chain.invoke(input={"ad_words": "助听器,清晰,方便,便宜,聆听世界。"})-
第一步:创建
SystemMessagePromptTemplate的内容,例如:"这是一个创意文案生成专家。" -
第二步:创建
HumanMessagePromptTemplate的内容,例如:"用户将输入几个产品的关键字,请根据关键词生成一段适合老年市场的文案,要求:成熟,稳重,符合老年市场的风格。" -
第三步:使用
ChatPromptTemplate将系统消息和用户消息进行拼接,得到最终的Prompt模板。Prompt的核心用户发:参数化
- 上例中的
ad_words即为参数化的内容,可以通过用户输入来填充。 - 下面示例中Prompt也是可以带多个参数的。
prompt = PromptTemplate.from_template(template="请列出{num}种{location}美食!")num和location可以作为参数,在后续的chain.invoke调用时传入
- 上例中的
-
第四步:使用管道符|,将
prompt、chat模型和输出解析器连接起来,构建chain链。 -
第五步:调用
chain的invoke方法,传入对应的变量数据,最终调用大模型得到结果。
Prompt进阶用法
prompt.partial用法
使用场景
prompt.partial 是一种用于构建和管理提示(prompt)的方法,尤其在与语言模型交互时,可以帮助用户动态生成和调整提示内容。
使用方法
# 构建Prompt
prompt = PromptTemplate.from_template(template="请讲{num}个关于{item}的冷笑话!")
# 使用partial方法动态插入参数
prompt = prompt.partial(item="汽车")
chain = prompt | llm
chain.invoke(input=dict(num=5))运行结果:
# '1. 为什么汽车总是对加油站特别忠诚?因为它们知道,没有“油”朋友,就走不了多远!\n\n
# 2. 两辆车在红绿灯前相遇,一辆车对另一辆说:“嘿,你的尾气好重啊!”另一辆回答:“抱歉,我刚吃完了一家油炸圈饼店。”\n\n
# 3. 知道汽车最怕什么科目吗?——不是物理,是“停车”考试!\n\n
# 4. 有一天,一辆车走进了酒吧,吧台服务员问:“你为什么看起来这么累?”车回答:“哎,一整天都在跑圈子,还老是被导航误导。”\n\n
# 5. 为什么智能汽车永远不会感到孤独?因为它们总是在和“车联网”聊天!'FewShotPromptTemplate用法
使用场景
FewShotPromptTemplate 是一种用于构建提示的模板,特别适用于少量示例学习(Few-Shot Learning)场景。它允许用户在提示中包含几个示例,以帮助模型更好地理解任务和预期输出。
使用方法
from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import FewShotPromptTemplate
# 定义一个样例的模板
example_prompt = PromptTemplate.from_template(template="输入:{in}\n输出:{out}")
# 定义样例
examples = [
{"in": "深圳", "out":"华南"},
{"in": "阳泉", "out":"华北"},
{"in": "锦州", "out":"东北"},
{"in": "酒泉", "out":"西北"}
]
# 构建 FewShotPromptTemplate
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_prompt,
examples=examples,
prefix='请学习我给定的样例,并据此回答我提出的问题:\n"""',
suffix='"""\n输入:{input}\n输出:')
chain = few_shot_prompt | llm
chain.invoke(input={"input": "绍兴"})
运行结果:
# '华东'PipelinePromptTemplate用法
使用场景
PipelinePrompt 是一种用于构建复杂提示的工具,允许将多个步骤或组件组合在一起,以实现更复杂的任务。它特别适用于需要多个阶段处理的场景,比如数据预处理、模型推理和后处理。
使用方法
from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import PipelinePromptTemplate
# 定义一个完整的模板
full_template = '''
{expect}
{example}
{question}
'''
full_prompt = PromptTemplate.from_template(template=full_template)
# 定义expect部分
expect_prompt = PromptTemplate.from_template(template='请学习我给定的样例,并据此回答我提出的问题:\n"""')
# 定义example样例部分
example_prompt = PromptTemplate.from_template(template="""
输入:深圳
输出:华南
输入:阳泉
输出:华北
输入:锦州
输出:东北
输入:酒泉
输出:西北
""")
# 定义question部分
question_prompt = PromptTemplate.from_template(template='"""\n输入:{in}\n输出:')
# 使用pipline将多个prompt组合在一起
pipeline_prompts = [("expect", expect_prompt),
("example", example_prompt),
("question", question_prompt)]
# 构建Prompt
prompt = PipelinePromptTemplate(final_prompt=full_prompt,
pipeline_prompts=pipeline_prompts)
chain = prompt | llm
chain.invoke(input={"in": "三亚"})运行结果:
# '华南'FewShotChatMessagePromptTemplate的使用
使用场景
FewShotChatMessagePromptTemplate 是一种Chat交互中,用于少样本学习(Few-Shot Learning)场景的提示模板,适用于需要提供示例以帮助模型理解任务的情况。
使用方法
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import FewShotChatMessagePromptTemplate
# 定义样例(样例实际是加法案例)
examples = [
{"in": "1 * 1", "out": "2"},
{"in": "2 * 3", "out": "5"},
{"in": "5 * 4", "out": "9"},
{"in": "7 * 2", "out": "9"},
{"in": "4 * 2", "out": "6"},
{"in": "3 * 2", "out": "5"}
]
# 定义样例的prompt
example_prompt = ChatPromptTemplate.from_messages(
messages=[
("human", "{in}"),
("ai", "{out}")
]
)
# 构建FewShotChatMessagePromptTemplate
few_shot_prompt = FewShotChatMessagePromptTemplate(examples=examples,
example_prompt=example_prompt)
# 定义最终的prompt
final_prompt = ChatPromptTemplate.from_messages(
[
('system', '请学习我给定的样例,并据此回答我提出的问题:\n"""'),
few_shot_prompt,
('human', '"""\n{input}'),
]
)
chain = final_prompt | chat
chain.invoke(input={"input":"4 * 5"})运行结果:
# AIMessage(content='11',
# response_metadata={'model_name': 'qwen-max', 'finish_reason': 'stop', 'request_id': '270e47c6-270c-91e3-8de5-035e55719423',
# 'token_usage': {'input_tokens': 124, 'output_tokens': 2, 'total_tokens': 126}}, id='run-39d1e6ce-2679-40b7-968b-92f67d645c72-0')相比 FewShotPromptTemplate 的区别
FewShotPromptTemplate 和 FewShotChatMessagePromptTemplate 都是用于少样本学习(Few-Shot Learning)的提示模板。
适用场景:
- FewShotPromptTemplate:通常用于更通用的文本生成任务,适合处理传统的文本输入和输出,不限于对话场景。
- FewShotChatMessagePromptTemplate:专门设计用于聊天和对话系统,适合处理人类与AI之间的交互。
消息结构:
- FewShotPromptTemplate:通常不区分消息的角色,可能只关注输入文本和期望的输出。
- FewShotChatMessagePromptTemplate:明确区分人类消息(如用户输入)和AI消息(如模型响应),更符合对话的结构。
示例格式:
- FewShotPromptTemplate:示例通常是输入-输出对,格式较为灵活。
- FewShotChatMessagePromptTemplate:示例以消息对的形式组织,强调对话的自然流畅性。
MessagePlaceholder(消息占位符)用法
使用场景
MessagePlaceholder(消息占位符)是一种用于在对话系统或聊天机器人中动态插入消息内容的工具。它允许开发者在构建提示时预留位置,以便在运行时填充具体的消息内容。
使用方法
from utils import get_qwen_models
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import SystemMessagePromptTemplate
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.messages import SystemMessage
from langchain_core.messages import HumanMessage
from langchain_core.messages import AIMessage
llm, chat, embed = get_qwen_models()
# 定义总结消息的模板
messages = [
SystemMessagePromptTemplate.from_template(template="你是一个文本摘要机器人,请使用不超过{num}个字的篇幅来总结以下的对话!"),
# 消息占位符,用于动态插入上下文对话
MessagesPlaceholder(variable_name="context"),
HumanMessagePromptTemplate.from_template(template="###请开始总结上面的对话")
]
# 构建Prompt
prompt = ChatPromptTemplate.from_messages(messages=messages)
user_msg = HumanMessage(content="如何学会开车?")
# 使用聊天模型生成AI的响应
ai_msg= chat.invoke(input=[user_msg])
print(ai_msg.content)
# 将用户消息和AI消息组合成一个消息列表
msgs = [user_msg, ai_msg]
# 构建链
chain = prompt | chat
# 调用链,传入参数num和上下文消息,生成总结
result = chain.invoke(input={"num": 100, "context": [user_msg, ai_msg]})
print(result.content)
运行结果:
# ai_msg.content:
# 学习开车需要耐心、细心和系统的学习方法,以下是一些基本步骤和建议,帮助你开始学习过程:
# 1. **理论学习**:
# - **了解交通规则**:首先,熟悉当地的交通法规,可以通过阅读驾驶手册或参加在线课程来完成。了解交通标志、信号、驾驶礼仪和安全知识。
# - **学习汽车基础知识**:了解汽车的基本构造和各个部件的功能,比如方向盘、刹车、油门、离合器(手动挡车辆)、档位、后视镜等。
# 2. **模拟练习**:
# - 在正式上路之前,可以使用驾驶模拟软件进行初步练习,这有助于你熟悉驾驶操作和应对各种道路情况的反应。
# 3. **找一位好教练**:
# - 选择一位有经验、耐心且持有合法教练资格的驾驶教练。专业的指导能帮助你更快掌握技巧,同时保证学习过程中的安全。
# 4. **实际操作练习**:
# - **基础操作**:在空旷的停车场或驾校练习场开始,学习如何启动、加速、减速、停车、转弯以及倒车等基本操作。
# - **逐渐进阶**:随着技能的提升,可以在教练的陪同下尝试更复杂的路况,如城市道路、高速公路、夜间驾驶等。
# - **应急处理**:学习如何处理突发状况,如紧急刹车、避让障碍物等。
# 5. **持续练习与反馈**:
# - 练习是关键。尽量多安排练习时间,每次练习后回顾并总结经验教训。
# - 主动寻求教练或有经验的驾驶员的反馈,了解自己的不足并加以改进。
# 6. **心理准备**:
# - 建立自信,但也要保持谦虚和谨慎。开车时保持冷静,不要慌张。
# - 学会压力管理,遇到困难时深呼吸,保持冷静分析问题。
# ...
# - 当你觉得准备充分后,可以报名参加驾驶理论考试和实践考试。通过考试后,你将获得驾照,成为合法的驾驶员。
# result.content:
# 学习开车需循序渐进:先理论学习交通规则与汽车基础;再利用模拟软件预练。
# 接着,找专业教练进行实操,从空旷区域的基础操作到复杂路况演练,重视应急处理能力培养。
# 过程中,持续练习,积极求反馈,保持心态平和,最终通过考试,安全驾驶,养成良好习惯。
OutputParser输出解析器进阶用法
CommaSeparatedListOutputParser的使用
使用场景
CommaSeparatedListOutputParser 的使用场景主要集中在需要将文本输出解析为逗号分隔列表的任务。
使用方法
通过output_parser.get_format_instructions()在Prompt的拼接,可以让返回的结果形成指定格式。
from dotenv import load_dotenv
from utils import get_ernie_models
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
# 连接大模型
llm, chat, embed = get_ernie_models()
# 构建Prompt
prompt = PromptTemplate.from_template(template="请列出{num}种{location}美食!使用中文输出!\n{output_parser}",
partial_variables={"output_parser": output_parser.get_format_instructions()})
chain = prompt | llm
result = chain.invoke(input=dict(num=5, location="山西"))
result = output_parser.parse(result)
print(result)
说明:
output_parser.get_format_instructions()的内容对应是:Your response should be a list of comma separated values, eg: `foo, bar, baz` or `foo,bar,baz`运行结果:
# ['山西美食有:\n\n1. 刀削面\n2. 山西过油肉\n3. 浑源凉粉\n4. 晋中蘸片子\n5. 老陈醋溜白菜']因为上述返回的结果并不是以英文,分割,所以我们可以将output_parser.get_format_instructions()改为自定义PromptTemplate,例如:
prompt = PromptTemplate.from_template(template="请列出{num}种{location}美食名称!\n请使用中文输出名称,输出的结果必须是用英文逗号分开的一系列的值,比如: `苹果, 桃, 梨` 或者 `苹果,桃,梨`")
# 运行结果:
# ['刀削面', '羊杂割', '过油肉', '郝刚刚羊汤', '平遥牛肉']可以看到output_parser.parse可以将返回结果从'刀削面, 羊杂割, 过油肉, 郝刚刚羊汤, 平遥牛肉'变为列表['刀削面', '羊杂割', '过油肉', '郝刚刚羊汤', '平遥牛肉']。
DatetimeOutputParser的使用
使用场景
DatetimeOutputParser 是一种专门用于解析日期和时间格式的工具,适用于需要处理和提取日期时间信息的场景。
使用方法
from langchain_core.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
parser = DatetimeOutputParser(format='%Y-%m-%d %H:%M:%S')
prompt = PromptTemplate.from_template(template="{question}\n{format}",
partial_variables={"format": parser.get_format_instructions()})
print(parser.get_format_instructions())
chain = prompt | llm
result = chain.invoke(input={"question": "新中国成立是什么时间?"})
result运行结果:
# Write a datetime string that matches the following pattern: '%Y-%m-%d %H:%M:%S'.
# Examples: 0761-02-07 22:24:48, 0645-12-11 13:40:32, 1559-09-11 04:44:28
# Return ONLY this string, no other words!
# '1949-10-01 00:00:00'EnumOutputParser的使用
使用场景
EnumOutputParser 是一种用于解析枚举类型输出的工具,适用于需要从模型生成的文本中提取特定枚举值的场景。
使用方法
from langchain.output_parsers import EnumOutputParser
from enum import Enum
class Color(Enum):
BLUE = "blue"
RED = "red"
GREEN = "green"
parser = EnumOutputParser(enum=Color)
prompt = PromptTemplate.from_template(template="{item}是什么颜色的?\n{format}!Return ONLY your option, no other words!",
partial_variables={"format": parser.get_format_instructions()})
print(parser.get_format_instructions())
chain = prompt | llm
result= chain.invoke(input={"item":"中国国旗"})
print(result)运行结果:
# Select one of the following options: blue, red, green
# redStructuredOutputParser的使用
使用场景
StructuredOutputParser 是一个强大的工具,适用于多种需要将文本输出转换为结构化格式的场景。
使用方法
from langchain.output_parsers import StructuredOutputParser
from langchain_core.prompts import PromptTemplate
from langchain.output_parsers import ResponseSchema
response_schemas = [
ResponseSchema(name="country", description="国家"),
ResponseSchema(name="population", description="这个国家对应的人口数量")
]
parser = StructuredOutputParser(response_schemas=response_schemas)
format = '''输出必须是JSON对象列表,格式请参考如下示例:
[{
"Country": string // 国家
"GDP": string // 这个国家对应的人口数量
}]
请注意:输出结果要符合JSON格式,不要带有```json等字段。内容请用中文!
'''
prompt = PromptTemplate.from_template(template="请列出世界上GPD排名前{num}的国家及其GDP。\n{format}",
partial_variables={"format": format})
chain = prompt | llm
result = chain.invoke(input=dict(num=5))
import json
json.loads(s=result)运行结果:
# [{'Country': '美国', 'GDP': '21.44万亿美元'},
# {'Country': '中国', 'GDP': '14.14万亿美元'},
# {'Country': '日本', 'GDP': '5.15万亿美元'},
# {'Country': '德国', 'GDP': '4.17万亿美元'},
# {'Country': '印度', 'GDP': '3.05万亿美元'}]PydanticOutputParser的使用
使用场景
PydanticOutputParser 是一种类似于Javascript中的 TypeScript,用于解析和验证输出数据的工具,可以对动态语言中的数据类型,进行约束;增强代码的鲁棒性,把问题发现在开发阶段,而不是在运行阶段。
使用方法
from langchain.output_parsers import PydanticOutputParser
from langchain.pydantic_v1 import BaseModel, Field
import json
# 把属性定义为类变量
class ResultEntity(BaseModel):
"""
自定义结果输出
"""
country: str | list = Field(description="这个国家的名字")
population: str | list = Field(description=" 这个国家对应的人口")
parser = PydanticOutputParser(pydantic_object=ResultEntity)
print(parser.get_format_instructions())
format_instructions = parser.get_format_instructions()
prompt = PromptTemplate.from_template(template="请列出世界上人口数量排名前5的国家及其人口。\n{format}",
partial_variables={"format": format_instructions})
chain = prompt | llm
result = chain.invoke(input={})
result
# 去掉 ```json``` 和 ``` 标记
cleaned_result = result.strip('```json\n').strip('```')
parsed_result = json.loads(cleaned_result)
# 打印解析后的结果
print(parsed_result)运行结果:
{'country': ['China', 'India', 'United States', 'Indonesia', 'Pakistan'],
'population': ['1,439,323,776', '1,380,004,385', '331,002,651', '273,523,615', '220,892,340']}内容小结
LangChain的整体架构由LangSmith、LangServe、Templates、LangChain-Community和LangChain-Core构成。LangChain-Core是LangChain的核心库,提供了基本的功能和模块,支持构建和管理链式应用程序。LangChain-Community是一个社区驱动的部分。通过使用LangChain-community中的 插件库(例如:Tongyi),可以快速连接对应的大模型(例如:阿里的通义千问大模型)。LangServe是一个服务框架,用于将LangChain应用部署为可访问的 API。LangSmith是一个工具,旨在帮助开发者在构建和调试LangChain应用时进行更好的管理和监控。FewShotPromptTemplate允许用户在提示中包含几个示例,以帮助模型更好地理解任务和预期输出。PipelinePrompt允许将多个步骤或组件组合在一起,以实现更复杂的任务。MessagePlaceholder(消息占位符)允许开发者在构建提示时预留位置,以便在运行时填充具体的消息内容。CommaSeparatedListOutputParser可以将文本输出解析为逗号分隔列表的任务,有时不灵的时候可能需要我们重写提示内容。StructuredOutputParser可以将数据按照指定格式输出,特别是在Json格式中,可以更方便的解析数据。
参考资料
暂无
欢迎关注公众号以获得最新的文章和新闻




