
前言
在上一章,我们主要了解了什么是LangChain以及基本的部署方式,本章将结合LangChain框架,了解大模型的应用方式:即Prompt。
大模型的应用方式
大模型的应用,一般有两种方式:
方式一:作为工具使用
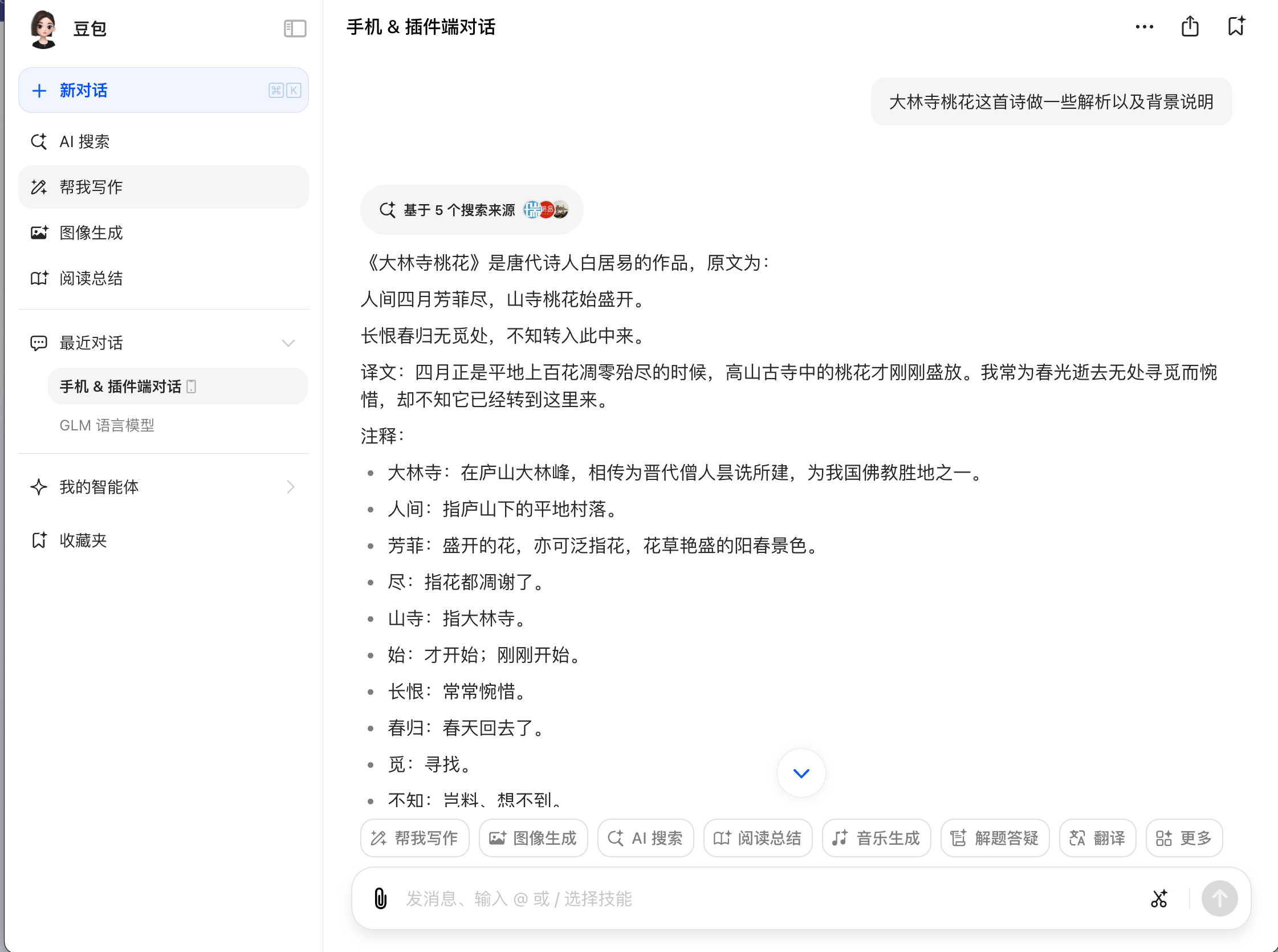
说明:
- 使用方式:
- 访问对应的大模型产品网址,
- 在输入框中输入关键字/文字进行提问,然后得到结果。
- 代表产品:豆包、文心一言等等。
更多此类产品可以查看网站中的AI导航,这里我梳理了国内外各类大模型产品。
方式二:大模型的二次开发

说明:
- 使用方式:
- 基于自研的或者第三方的大模型
- 使用LangChain框架进行Prompt的构建
- 调用大模型的API接口进行二次开发
- 代表产品:阿里云百炼、百度云千帆等等。
大模型应用的本质
本章,我们将重点了解第二种大模型的应用方式,首先我们需要简单回顾下大模型的训练方式以便了解Prompt。
大模型训练的回顾
在【课程总结】day24(上):大模型三阶段训练方法(LLaMa Factory)中,我们了解到:
- 大模型的训练有三个阶段:
预训练(PT)、监督微调(SFT)、偏好纠正(RLHF)。 预训练是大模型修炼内功的过程;监督微调是大模型修炼招式的过程,大量的问题解决能力是在这个阶段训练得到的。监督微调训练时是通过下面格式的数据进行训练:[ { "instruction": "human instruction (required)", "input": "human input (optional)", "output": "model response (required)", "system": "system prompt (optional)", "history": [ ["human instruction in the first round (optional)", "model response in the first round (optional)"], ["human instruction in the second round (optional)", "model response in the second round (optional)"] ] } ]其中:
system:系统的指令 user:用户指令和用户输入
由此,大模型的训练和应用的本质是:
- 训练:通过
system、user、tool(一种工具描述)不同的指令组合和海量数据,让大模型学习知识,由此形成泛化能力,进而能力涌现可以做更多的事情。 - 应用:通过Prompt(不同的提问方法(指令)),引出大模型不同的能力,让大模型做不同的事情。
具体应用方式
大模型的二次开发具体方式有两个方式:一种是使用大模型最为基础的底层API方式调用,另外一种是使用LangChain框架进行Prompt的构建调用。
使用底层API方式应用
# 导入依赖组件
from modelscope import AutoModelForCausalLM
from modelscope import AutoTokenizer
# 判断设备
device = "cuda" # the device to load the model onto
# 模型ID,对应git clone的模型文件夹名称
model_id = "qwen2-7b-instruct"
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto"
)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 准备提示词
messages = [
{"role": "system", "content": """
你是一个创意文案生成专家。
"""},
{"role": "user", "content": """
用户将输入几个产品的关键字,请根据关键词生成一段适合老年市场的文案,要求:成熟,稳重,符合老年市场的风格。
用户输入为:助听器,清晰,方便,便宜,聆听世界。
营销文案为:
"""}
]
# 应用聊天模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 输入内容转ID
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 模型预测
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
# 删除问句信息
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 翻译答案
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出结果
print(response)这种方式的调用过程主要是:
- 引入依赖组件
- 加载模型
- 加载分词器
- 准备提示词
- 应用聊天模板
- 输入内容转ID
- 模型预测
- 删除问句信息
- 翻译答案
- 输出结果
模型下载、部署等更多的信息在【课程总结】day22:大模型体验之Qwen2模型有说明,本章不再赘述。
上述应用步骤中,5~10步骤都是固定的且比较繁琐,所以可以使用LangChain框架进行简化。
使用LangChain框架
接入大模型
第一步:安装LangChain框架
pip install langchain-community第二步:访问阿里云百炼官网,注册/登录账号
第三步:在模型广场->查看我的API-KEY->创建API-KEY,然后根据提示创建API-KEY
第四步:选择模型
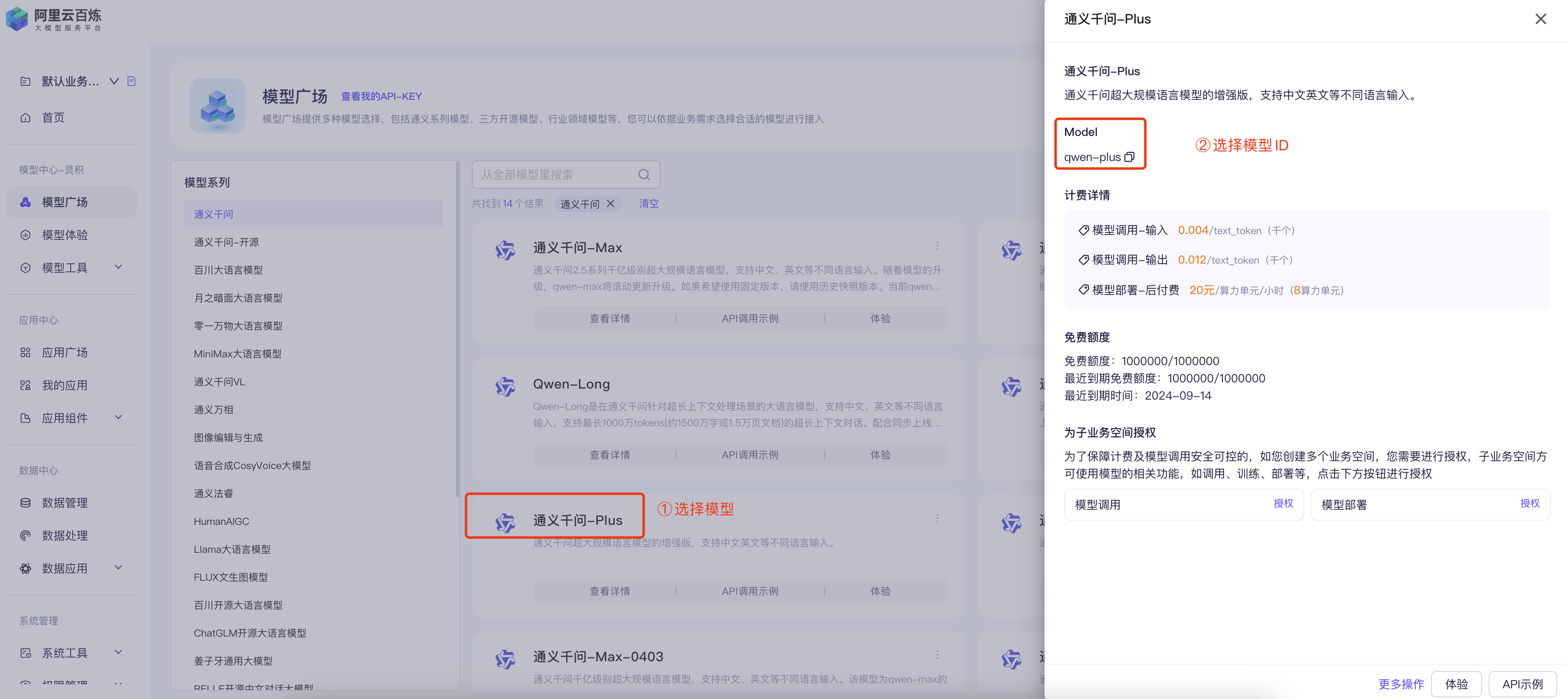
第五步:在Jupyter Notebook中创建调用代码
# 引入第三方大模型
from langchain_community.chat_models import ChatTongyi
chat = ChatTongyi(model='qwen-plus',
top_p=0.9,
temperature=0.9,
api_key='sk-xxxxxxxxxxxxx')
chat.invoke('你是谁?')
说明:
api_key:对应第三步创建的API-KEYmodel:对应第四步选择的模型ID
测试基本调用
from langchain_core.messages import SystemMessage
from langchain_core.messages import HumanMessage
from langchain_core.messages import ChatMessage
sys_msg = SystemMessage(content="你是一个创意文案生成专家。")
user_msg = HumanMessage(content="""
用户将输入几个产品的关键字,请根据关键词生成一段适合老年市场的文案,要求:成熟,稳重,符合老年市场的风格。
用户输入为:助听器,清晰,方便,便宜,聆听世界。
营销文案为:
""")
message = [sys_msg, user_msg]
# 调用模型输出结果
result = chat.invoke(input=message)
result.content运行结果:

使用chain优化调用
from langchain_core.prompts import SystemMessagePromptTemplate
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
# 构建Prompt模板
sys_msg = SystemMessagePromptTemplate.from_template(template="这是一个创意文案生成专家。")
user_msg = HumanMessagePromptTemplate.from_template(template="""
用户将输入几个产品的关键字,请根据关键词生成一段适合老年市场的文案,要求:成熟,稳重,符合老年市场的风格。
用户输入为:{ad_words}。
营销文案为:
""")
messages = [sys_msg, user_msg]
prompt = ChatPromptTemplate.from_messages(messages=messages)
# 结果解析
from langchain_core.output_parsers import StrOutputParser
# 使用管道符 | 构建chain链
chain = prompt | chat | StrOutputParser()
chain.invoke(input={"ad_words": "助听器,清晰,方便,便宜,聆听世界。"})
运行结果:
# '在人生的每一个精彩瞬间,聆听世界的美好是不可或缺的。选择我们的助听器,带给您的是超乎想象的清晰音质,让每一次对话都如同面对面般亲切自然。
# 轻巧便捷的设计,让您几乎忘记它的存在,只专注于享受生活的每一个珍贵时刻。更重要的是,我们深知性价比对每一位用户的重要性,
# 因此,在保证卓越品质的同时,我们也努力做到了价格上的亲民。让“听见”变成“听清”,让沟通不再有障碍,开启您的精彩人生新篇章。'通过构建chain链,可以简化调用过程,运行结果与上面基本调用结果一致。
优化代码(明文转暗文)
第一步:安装 python-dotenv 组件
pip install python-dotenv第二步:创建.qwen_key文件,将密钥写入文件中
DASHSCOPE_API_KEY = sk-xxxxxxx第三步:导入dotenv模块并加载.qwen_key文件
from dotenv import load_dotenv
load_dotenv(dotenv_path='.qwen_key')
第四步:去掉密钥的明文
chat = ChatTongyi(model='qwen-plus',
top_p=0.9,
temperature=0.9)至此,代码优化完毕。
完整的代码如下:
from langchain_core.prompts import SystemMessagePromptTemplate
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 导入dotenv模块
from dotenv import load_dotenv
# 引入第三方大模型
from langchain_community.chat_models import ChatTongyi
# 加载.qwen_key文件
load_dotenv(dotenv_path='.qwen_key')
# 连接模型
chat = ChatTongyi(model='qwen-plus',
top_p=0.9,
temperature=0.9)
# 构建Prompt模板
sys_msg = SystemMessagePromptTemplate.from_template(template="这是一个创意文案生成专家。")
user_msg = HumanMessagePromptTemplate.from_template(template="""
用户将输入几个产品的关键字,请根据关键词生成一段适合老年市场的文案,要求:成熟,稳重,符合老年市场的风格。
用户输入为:{ad_words}。
营销文案为:
""")
messages = [sys_msg, user_msg]
prompt = ChatPromptTemplate.from_messages(messages=messages)
# 使用管道符 | 连接多个模型,构建chain链
chain = prompt | chat | StrOutputParser()
chain.invoke(input={"ad_words": "助听器,清晰,方便,便宜,聆听世界。"})使用LangServe部署
LangServe是LangChain官方提供的一个在线工具,可以快速构建LangChain应用,并且可以部署到自己的服务器上。
第一步:安装LangServe组件
pip install "langserve[all]"
pip install "langserve[client]"是安装客户端
pip install "langserve[server]"是安装服务端
第二步:安装 LangChain CLI
pip install langchain-cli第三步:创建LangServe应用
在命令行下切换到我们想创建文件夹的目录,例如:G:\
langchain app new --non-interactive word_generationword_generation为应用名称,可以根据自己的需求取名
运行结果:
第四步:添加util.py和.qwen_key文件,目录如下:
word_generation \
|- app \
|- util.py
|- server.py
|- conf \
|- .qwen_key第五步:实现util.py文件
from dotenv import load_dotenv
load_dotenv(dotenv_path="./conf/.qwen_key")
def get_qwen_models():
# llm 大模型
from langchain_community.llms.tongyi import Tongyi
llm = Tongyi(model="qwen-max", temperature=0.1, top_p=0.7, max_tokens=1024)
# chat 大模型
from langchain_community.chat_models import ChatTongyi
chat = ChatTongyi(model="qwen-max", temperature=0.1, top_p=0.7, max_tokens=1024)
# embedding 大模型
from langchain_community.embeddings import DashScopeEmbeddings
embed = DashScopeEmbeddings(model="text-embedding-v3")
return llm, chat, embed
说明:
- 该文件用于将模型的秘钥加载、模型的链接封装为get_qwen_models函数,方便主函数调用。
第六步:实现server.py文件
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
from langserve import add_routes
from util import get_qwen_models
from langchain_core.prompts import SystemMessagePromptTemplate
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from fastapi.middleware.cors import CORSMiddleware
llm, chat, embed = get_qwen_models()
# 创建 FastAPI 应用
app = FastAPI(
title="Qwen API",
version="0.1",
description="Qwen API",
)
# 添加 CORS 中间件
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许所有的来源
allow_credentials=True,
allow_methods=["*"], # 允许的HTTP方法
allow_headers=["*"], # 允许的请求头
)
# 如果访问根目录,重定向到/docs
@app.get("/")
async def redirect_root_to_docs():
return RedirectResponse("/docs")
# 构建Prompt模板
sys_msg = SystemMessagePromptTemplate.from_template(template="这是一个创意文案生成专家。")
user_msg = HumanMessagePromptTemplate.from_template(template="""
用户将输入几个产品的关键字,请根据关键词生成一段适合老年市场的文案,要求:成熟,稳重,符合老年市场的风格。
用户输入为:{ad_words}。
营销文案为:
""")
messages = [sys_msg, user_msg]
prompt = ChatPromptTemplate.from_messages(messages=messages)
# 添加路由
add_routes(
app,
prompt | llm | StrOutputParser(),
path="/gen",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
说明:
- 以上代码的功能是使用FastAPI框架
- 核心部分是add_routes函数,该函数用来添加路由,即当用户访问
/gen路径后,会执行prompt | llm | StrOutputParser()
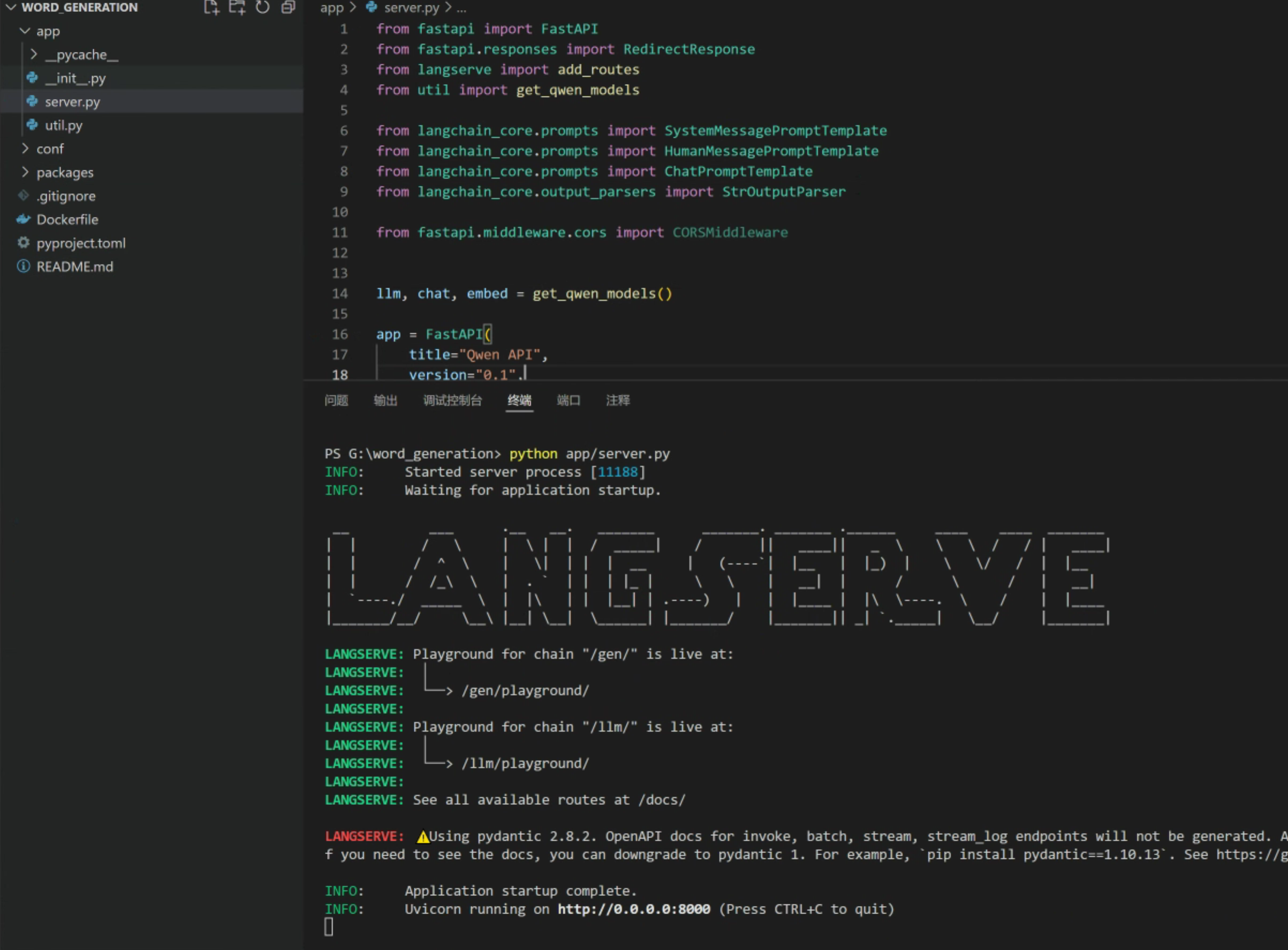
第七步:启动server.py
在工程的根目录下,使用如下命令启动服务
python app/server.py运行结果:
验证服务的API
Langserve预置了可以查看API效果的playground页面
http://localhost:8000/gen/playground/
运行效果:

使用Docker部署到云服务器
在上述步骤中,使用LangChain-CLI创建LangServe应用时,LangChain CLI会自动创建一个Dockerfile文件,该文件声明了一些基础的环境安装,我们需要根据业务实际情况补充相关内容。
第一步:修改Dockerfile文件
# 创建基于Python 3.11 的基础镜像
FROM python:3.11-slim
# 设置 pip 的国内源和超时时间
ENV PIP_DEFAULT_TIMEOUT=600
RUN pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 设置工作目录
WORKDIR /code
# 拷贝依赖文件
COPY ./requirements.txt ./
# 使用 pip 安装依赖
RUN pip install --no-cache-dir -r requirements.txt
# 拷贝应用代码
COPY ./app ./app
COPY ./conf ./conf
# 暴露端口
EXPOSE 8080
# 启动应用
CMD exec uvicorn app.server:app --host 0.0.0.0 --port 8080
说明:
- 由于我们的工程目录增加了conf目录,所以在Dockerfile中添加了COPY ./conf ./conf
- 由于我们的代码中依赖dotenv、langchain-community、dashscope,所以需要在工程目录中添加安装依赖文件requirements.txt,文件内容为:
pydantic==2.7.4 python-dotenv langserve langchain-community dashscope uvicorn sse_starlette
第二步:登录云服务器(前提是有一个自己的云服务器)
本次示例,我使用的是腾讯云上注册的云服务器。
第三步:将工程目录打包成.zip上传云服务器
第四步:解压工程目录
unzip word_generation.zip -d .第五步:命令行切换至项目根目录下,运行Docker打包镜像命令
# 切换到word_generation目录下
cd word_generation
# 运行Docker打包镜像命令
docker build -t word_generation .word_generation是可以自己定义的Docker镜像服务名称。.代表对当前目录进行打包
运行结果:
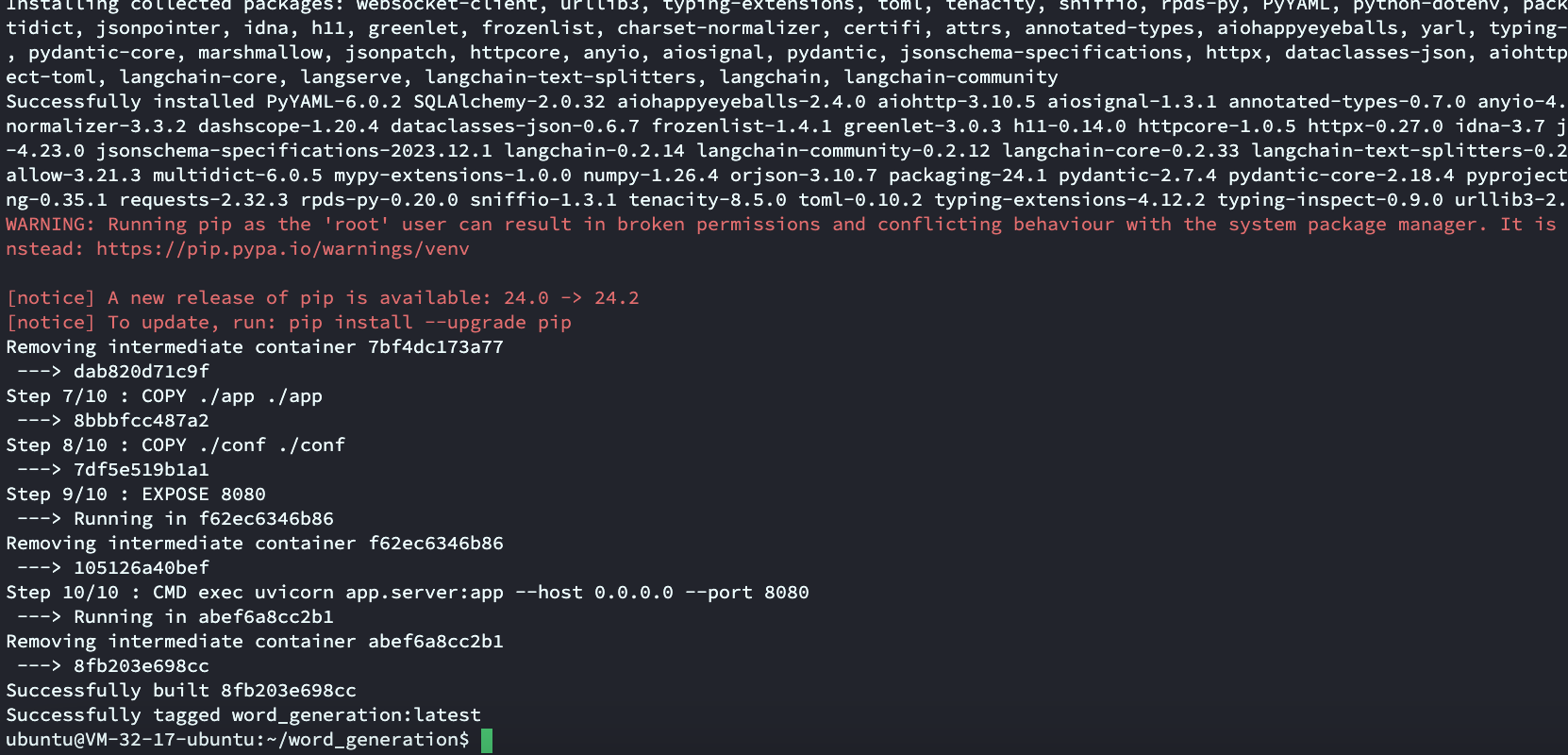
因为目前Docker源都被Ban了,所以记得更换Docker的镜像拉取源地址,具体方法:Docker更换镜像源教程
第六步:启动Docker容器
docker run -d --name my_word_generation_container -p 8001:8080 word_generation运行结果:

说明:
--name my_word_generation_container:将容器命名为my_word_generation_container,方便后续容器管理。-d:表示以分离模式运行容器。-p 8001:8080:将主机的8001端口映射到容器的8080端口。
LangServe官方文档提到可以一键部署至Google云计算服务器或者AWS云计算服务器,相关方法请见:https://zhuanlan.zhihu.com/p/696409416
测试API接口
根据LangServe提供的API示例,我们以下代码测试API接口
import requests
# 注意请求路径:常规路径后面添加一个 invoke
url = " http://119.45.220.104:8001/gen/invoke"
data = {"ad_words": "助听器"}
# 注意传参格式:外面包一层 input
response = requests.post(url=url, json={"input": data})
print(response.json()["output"])运行结果:

内容小结
- 大模型的训练和应用的本质是:
- 训练:通过
system、user、tool(一种工具描述)不同的指令组合和海量数据,让大模型学习知识,由此形成泛化能力,进而能力涌现可以做更多的事情。 - 应用:通过Prompt(不同的提问方法(指令)),引出大模型不同的能力,让大模型做不同的事情。
- 训练:通过
- 基于大模型的应用本质,可以构建Prompt指令,通过LangChain调用第三方大模型或者自建大模型。
- 使用LangChain框架大致步骤:
- 安装LangChain框架(如果连接第三方大模型,需要安装langchain-community组件)
- 申请并获取API-KEY(第三方大模型必需,API-KEY最好使用dotenv保存到文件中避免代码明文硬编码)
- 构建Prompt模板,对于可变内容使用
模板变量替代 - 使用管道符
|构建chain链,进而调用大模型
参考资料
欢迎关注公众号以获得最新的文章和新闻




