
前言
随着AI的火热,与之配套的产品生态也越来越丰富,既有类似文心一言、豆包的AI类产品,也有阿里云、魔塔社区、百度千帆大模型平台等等一众AI辅助类开发平台或产品。
然而纵观各产品的使用说明文档,以使用者角度的文档教程较为欠缺,因此笔者立个小目标:完成100款AI类产品的使用体验并形成总结。
因为近期的结业项目需要使用AI类辅助开发平台进行大模型微调,所以本章我将试用的产品是:趋动云平台。
产品简介
介绍:趋动云平台是一款一站式全流程人工智能平台。
平台打通模型开发与训练,原生支持多机多卡训练环境,优化 AI 场景下 IO 吞吐、持久化、结构化维护模型生产信息,优化数据资源共享路径,最终提高平台整体资源利用率,消除信息孤岛,大幅提高 AI 算法工程师工作效率,使其聚焦于算法与模型开发的核心工作,利用有限的资源更快挖掘商业价值与远见洞察。
以上内容来源于趋动云平台官网
网址:https://www.virtaicloud.com/
经过试用,笔者简而言之概括其功能是:
- 支持在线JupyterLab的开发交互模式
- 支持Dockerfile的编写并构建自己自定义的镜像
- 支持数据集的社区化管理,除了基本的上传、下载数据集之外,也可以分享数据集
- 支持离线训练
体验目标
参照过往的经验,训练一个医疗大模型
试用结论
好的方面:
- 趋动云的离线任务比较方便,将训练过程配置好之后,可以交给平台自动执行,无需人工一直值守;训练结束后(或者超过设定的超时时间)可以自动关闭服务,节省算力。
- 趋动云的整体交互界面较为友好,略微花点时间即可明白对应的功能。
不足之处:
- 数据集以及模型的管理方式较为繁琐,特别是对于使用第三方开源数据集或模型的情况,需要下载之后再上传,无法支持直接在服务端直接下载的方式,建议官方进行优化。
- 构建自定义镜像时,对于空间大小的限制太小(超过10G就会失败),对于一般情况下部署LLaMa Factory模型就会接近10G。
注:本次试用体验仅作为用户进行基本流程的试用,所体验的功能有限,以上试用结论仅为个人评估结果,如有不妥之处,还请体谅。
试用过程
前置准备工作
- 注册一个趋动云账号
训练过程
根据以往的经验,我们训练一个大模型的大致步骤有:
- 准备机器环境:登录一个支持GPU机器的平台
- 准备基础环境:安装基本的环境,包括PyTorch、Python、CUDA、Jupyter等
- 准备训练框架:下载训练框架LlaMa Factory
- 准备训练模型:下载基座大模型
- 准备数据集:上传数据集
- 训练参数配置:使用WebUI界面进行训练参数的配置
- 训练&验证&获取模型:执行配置好的训练,训练完毕后进行验证并获取模型
接下来,我将类比上述的训练过程,使用趋动云进行整体流程操作。
准备机器环境&准备基础环境&准备训练框架
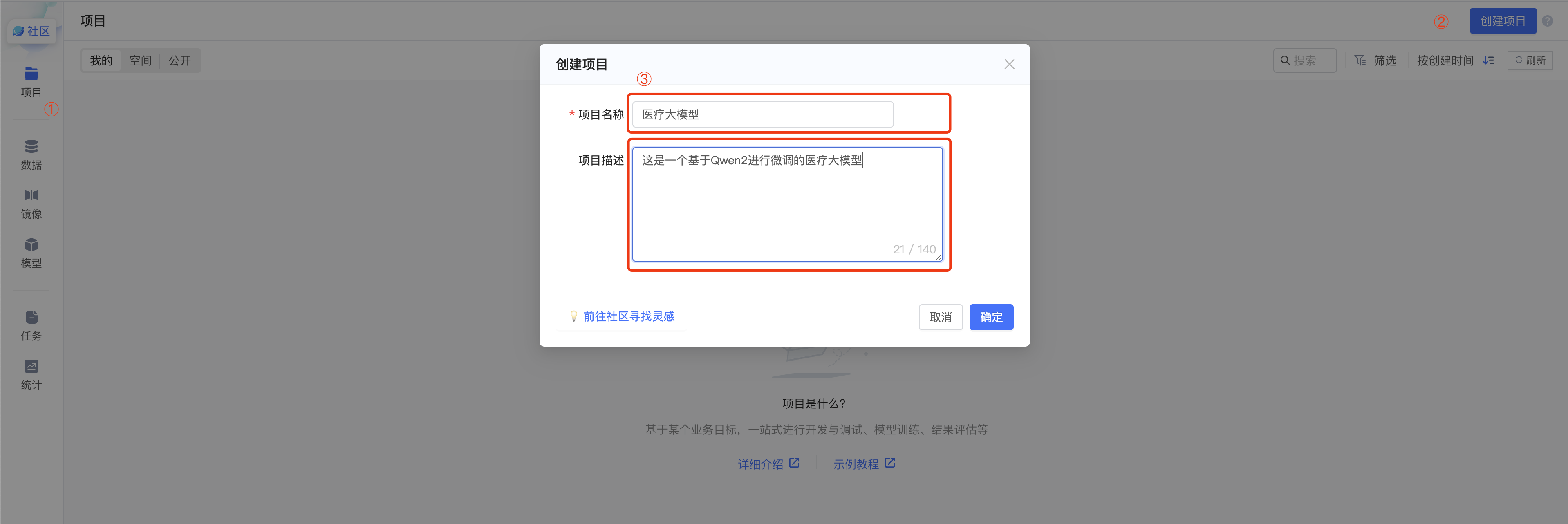
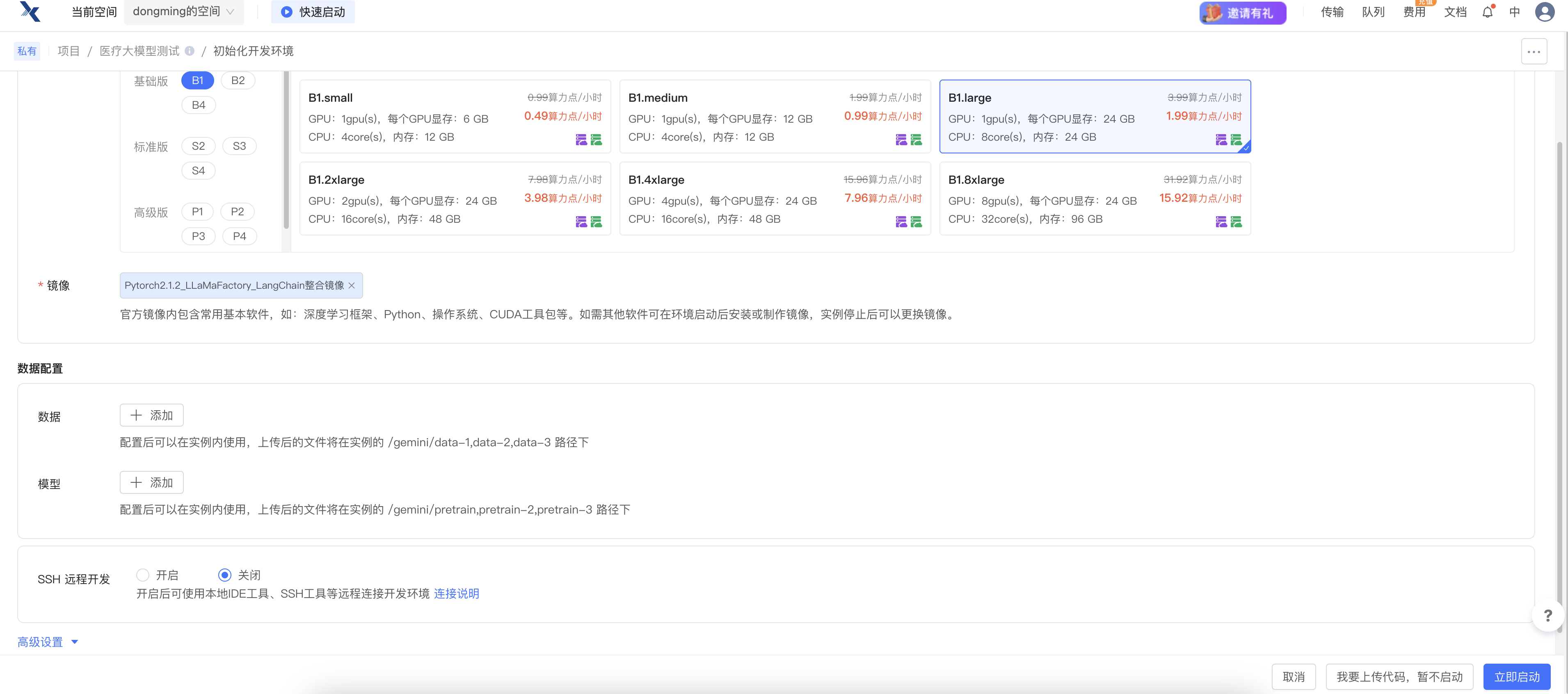
第一步:登录趋动云平台,在左侧项目创建对应的项目
第二步:在初始化开发环境选择硬件环境
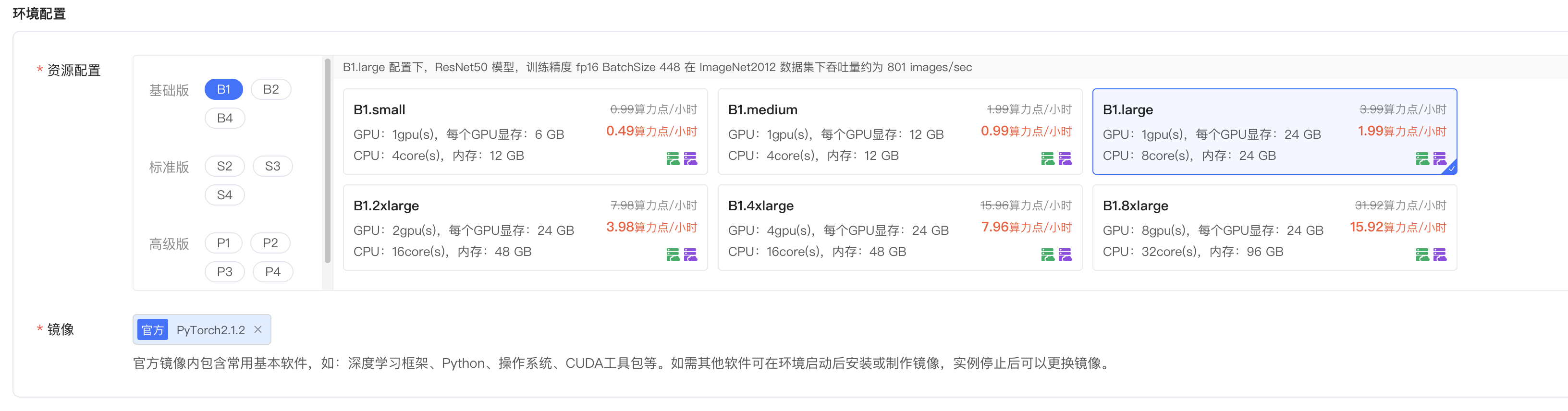
- 因为要跑Qwen2-7B模型,所以此处我选择了
B1.large。
第三步:选择镜像
镜像这里有两种方式:选择 官网已有的镜像 或者 自己构建一个镜像。
第一种较为简单,在镜像列表选择对应镜像即可,本次不再赘述。
LLaMa Factory的官网的Requirement中建议:
- python:3.11
- pytorch: 2.4.0
- CUDA: 12.2
所以,建议镜像选择 PyTorch2.1.2 这个版本
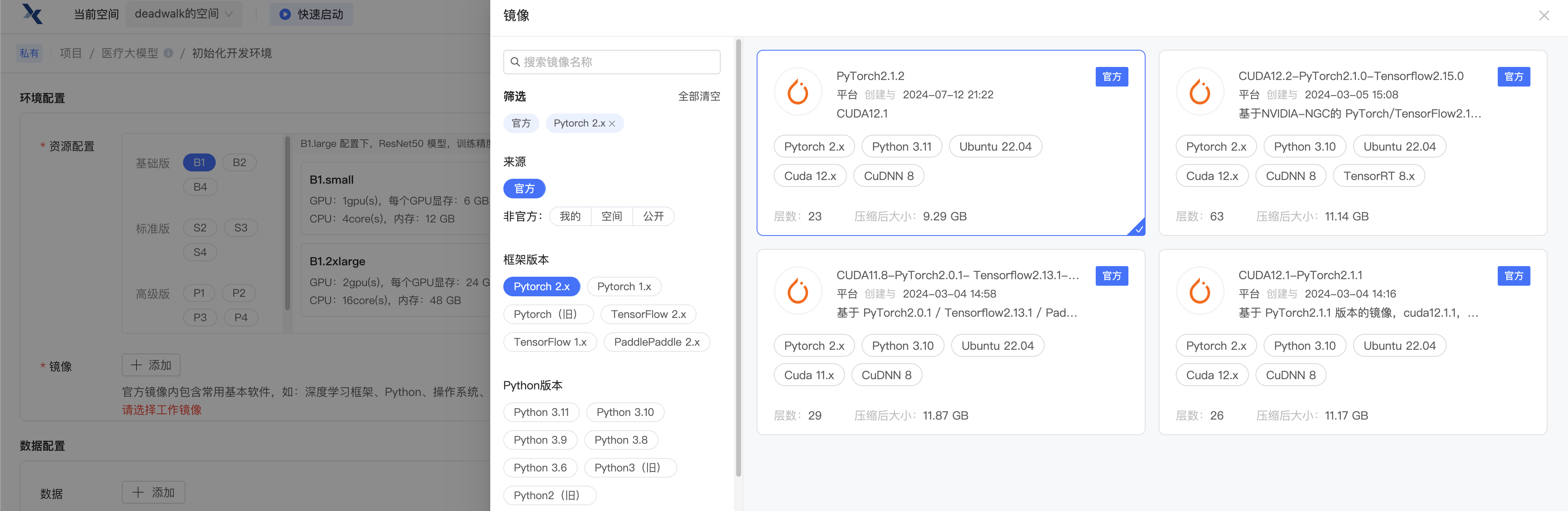
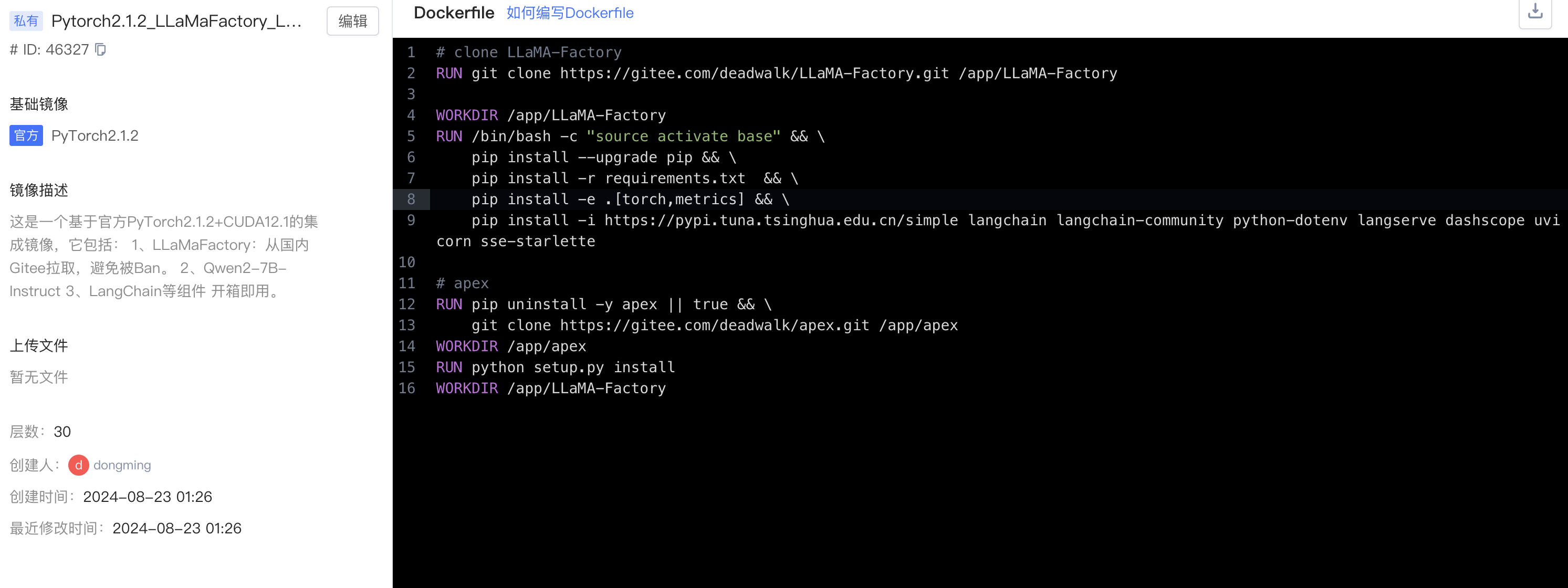
第二种是自己构建镜像,点击右上角 制作镜像 后,输入如下Dockerfile内容:
# clone LLaMA-Factory
RUN git clone https://gitee.com/deadwalk/LLaMA-Factory.git /app/LLaMA-Factory
WORKDIR /app/LLaMA-Factory
RUN /bin/bash -c "source activate base" && \
pip install --upgrade pip && \
pip install -r requirements.txt && \
pip install -e .[torch,metrics] && \
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple langchain langchain-community python-dotenv langserve dashscope uvicorn sse-starlette
# apex
RUN pip uninstall -y apex || true && \
git clone https://gitee.com/deadwalk/apex.git /app/apex
WORKDIR /app/apex
RUN python setup.py install
WORKDIR /app/LLaMA-Factory说明:
- 这种方式会在Dockfile中设定了拉取LLaMa Factory的镜像,所以省去了手动拉取的步骤。
- 上述Dockerfile中在拉取LlaMa Factory时,改为我在Gitee建立的镜像仓库,可以避免Github偶尔会抽风的问题。
- 上述Dockerfile中会提前安装好必要的依赖,包括
langchain、langchain-community、python-dotenv、langserve、dashscope、uvicorn等。
编辑完毕后,构建镜像。稍等片刻,镜像构建完毕即可。
第四步:(可选)启动开发环境
选择完毕之后,点击立即启动即可启动对应的开发环境。
注意:由于趋动云的模型和数据集有其自己的存储方式以及计费策略,所以此处建议先进行数据集和模型的添加后,再启动开发环境以避免浪费算力时。
准备数据集
与魔塔社区中使用git clone方式拉取数据集的方式不同,在趋动云中,需要做以下步骤:
- 创建一个数据集,填写数据集相关信息
- 将数据集上传到数据集
- 在启动开发环境中选择加载添加的数据集,数据集方可使用。
具体上传数据集的步骤,官方有详细的说明:创建并上传数据集。
此处,我仅记录我的操作步骤:
第一步:创建数据集
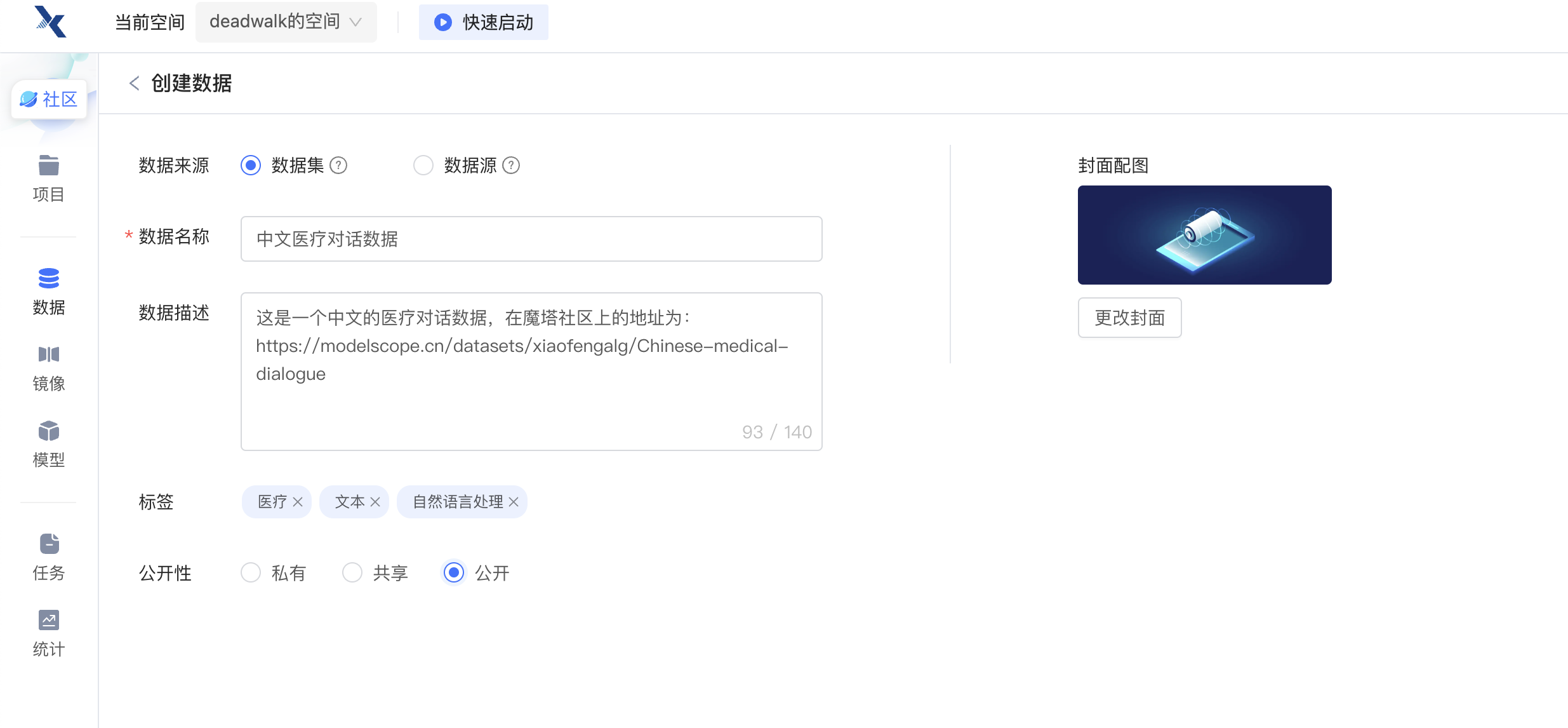
第二步:使用Termius(一款Mac下的SSH客户端),配置服务器地址
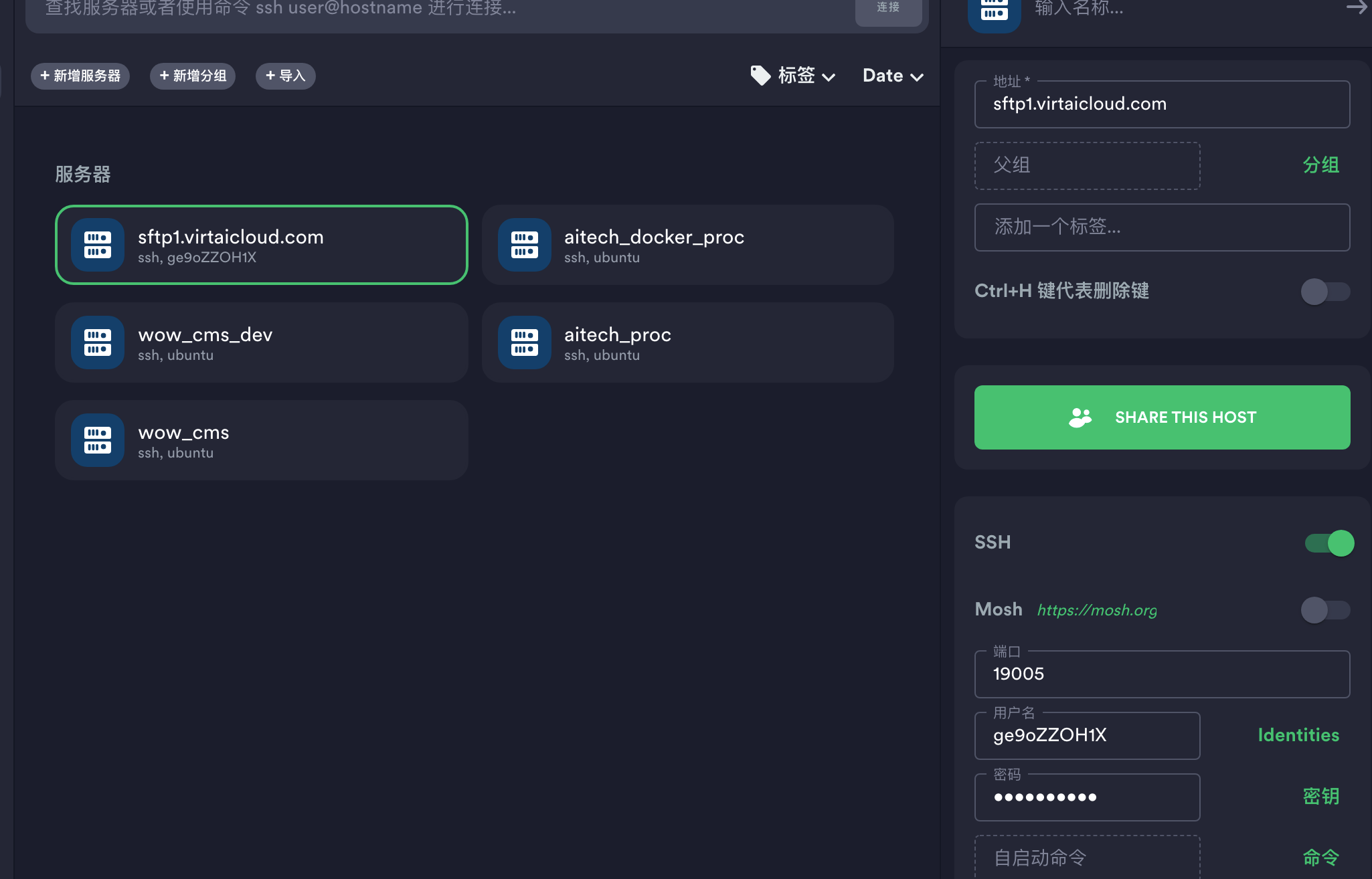
第三步:上传医疗大模型的数据集
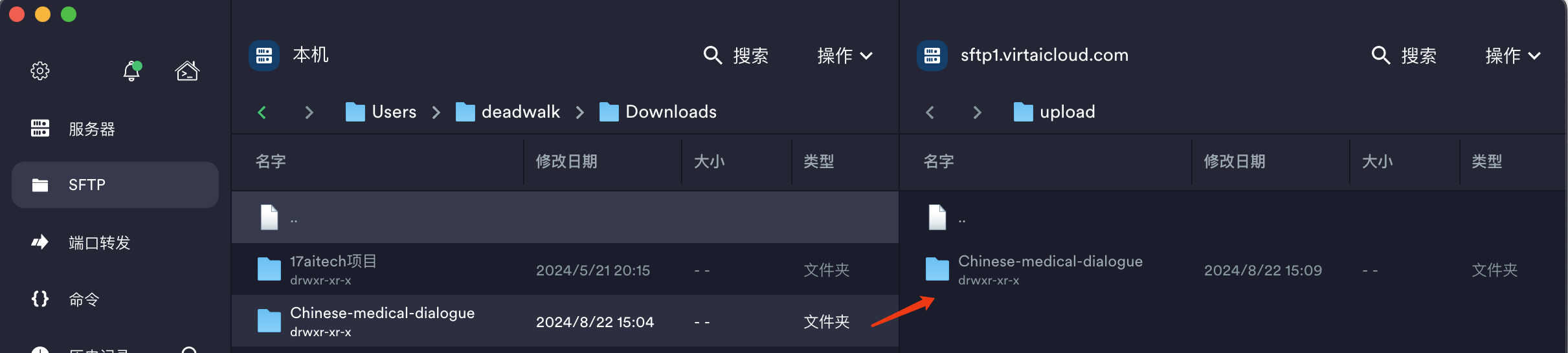
中文医疗对话数据-Chinese-medical-dialogue是我在魔塔社区上git clone到本地机器环境的数据集。
准备训练模型
本次我要使用Qwen2-7B-Instruct作为基座模型,而该模型文件大小为10G以上,无法在构建镜像时直接拉取(如果在构建镜像中拉取,会因为镜像超过10G而报错),所以我们这里通过趋动云页面的模型进行添加。
第一步:页面左侧模型 -> 创建模型 -> 填写模型相关信息
第二步:与上传数据集的方式类似,使用Termius将本地已经下载好的模型上传到服务器。
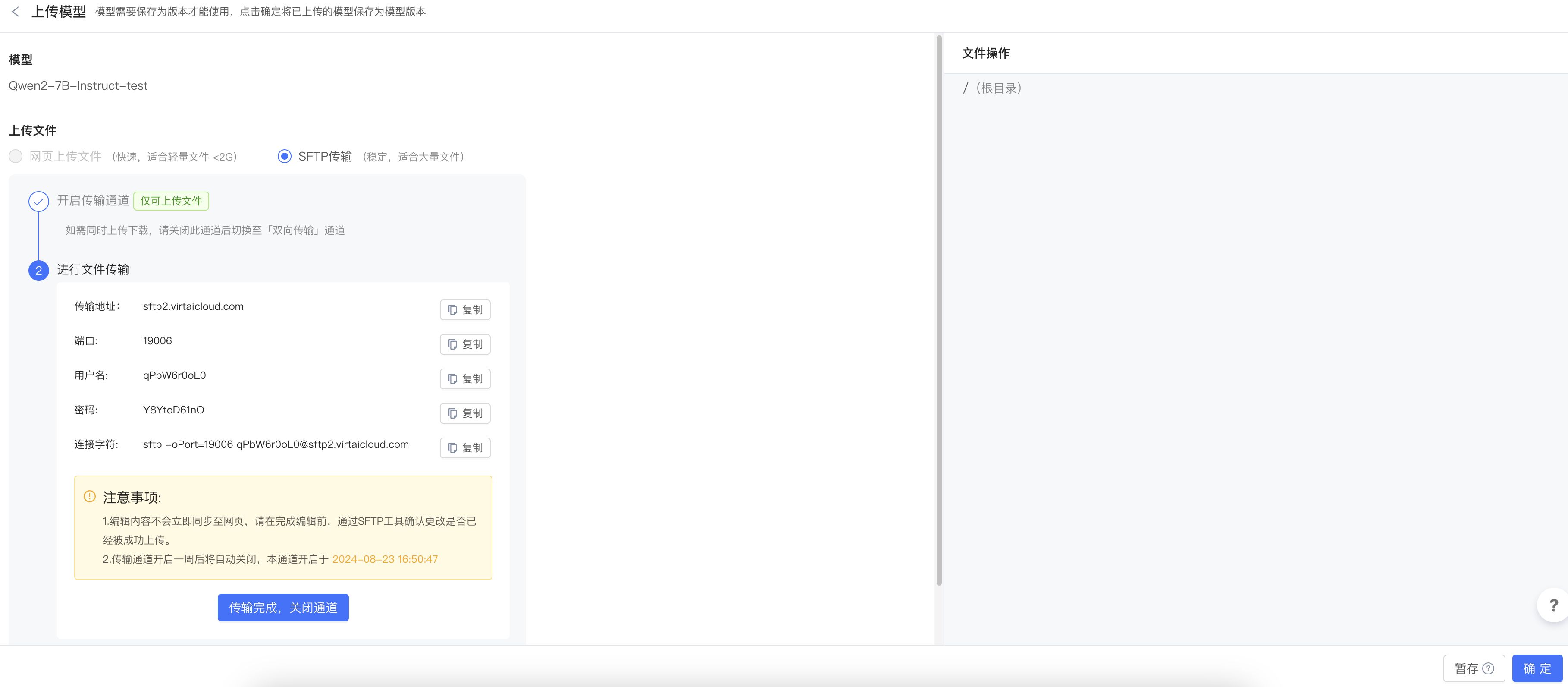
第三步:上传完毕后点击确定。
启动开发环境
通过以上步骤,训练大模型所需要的硬件环境、训练框架、训练模型、数据集等均已准备完毕,点击右下角的立即启动-> 启动开发环境 -> JupyterLab即可。
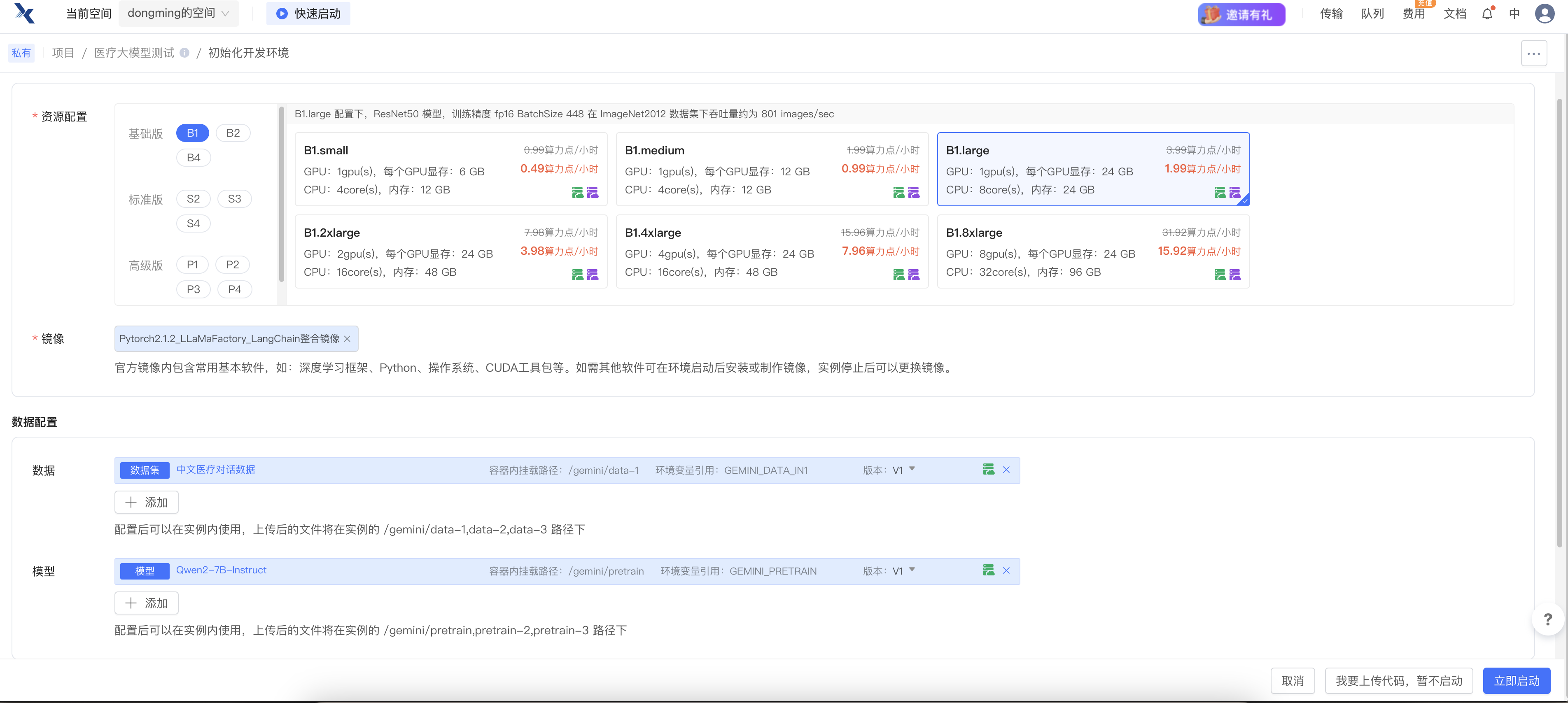
模型、数据集的加载除了在创建项目时可以选择之外,也可以在后续的使用中进行加载,例如:
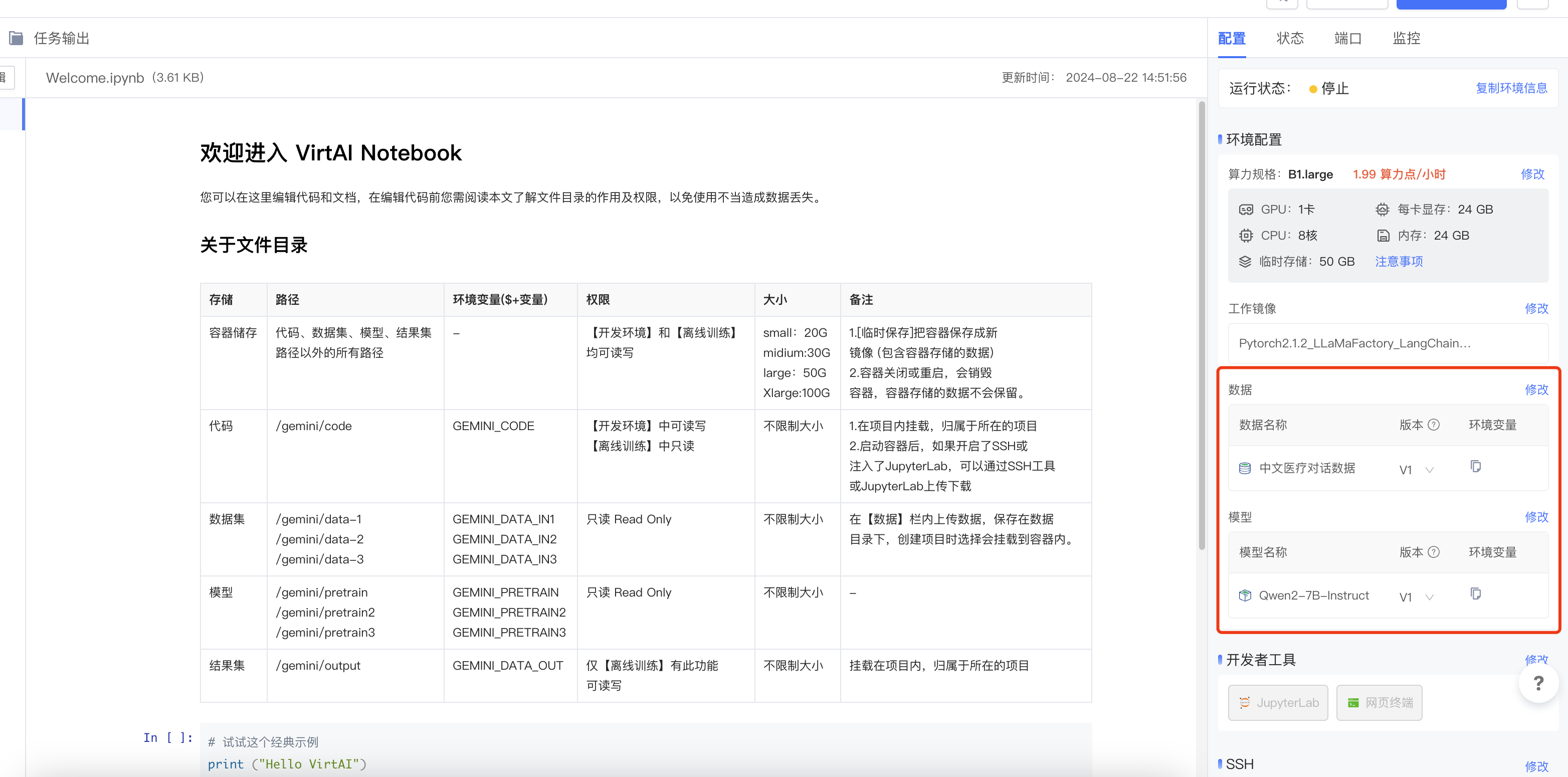
训练参数配置
第一步:启动LLaMa Factory的webui界面
由于在构建镜像时,我们将LLaMa Factory下载到/app/LLaMA-Factory/目录下,所以我们切换至该目录下后启动webui界面。
# 切换至/app/LLaMA-Factory/目录下
cd /app/LLaMA-Factory
# 启动webui界面
llamafactory-cli webui运行效果:
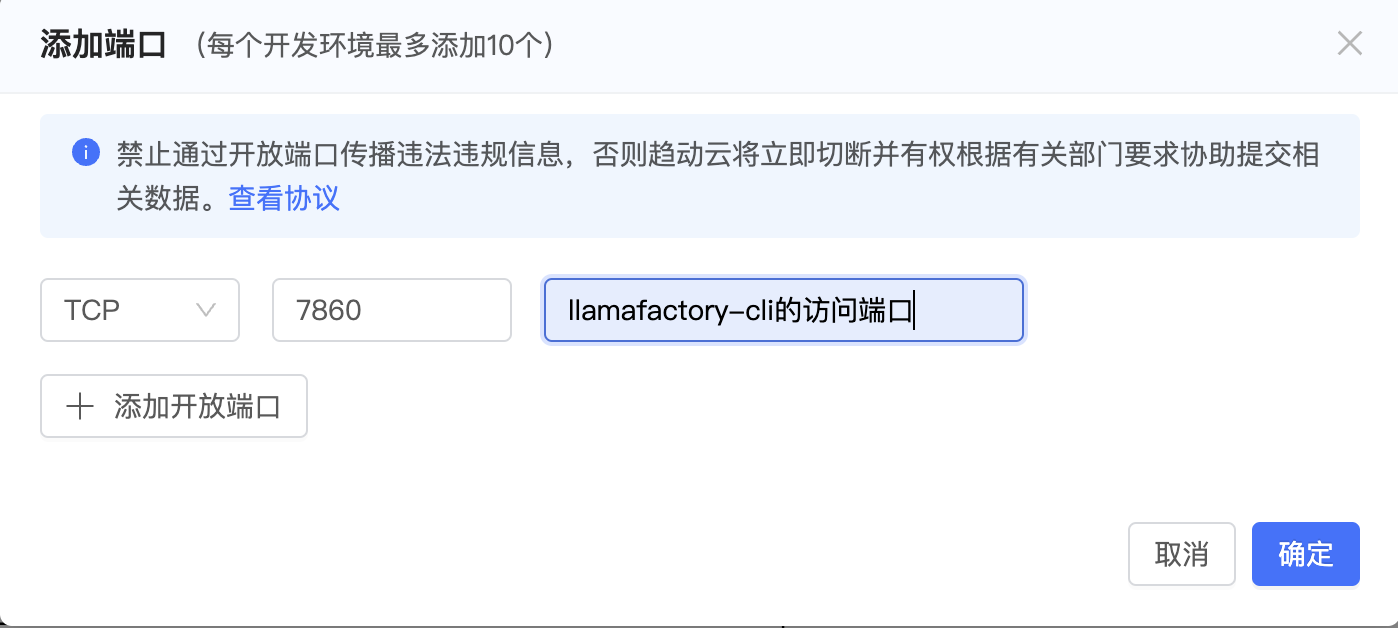
第二步:页面右侧端口 -> 添加端口-> 将7860端口添加到端口列表中
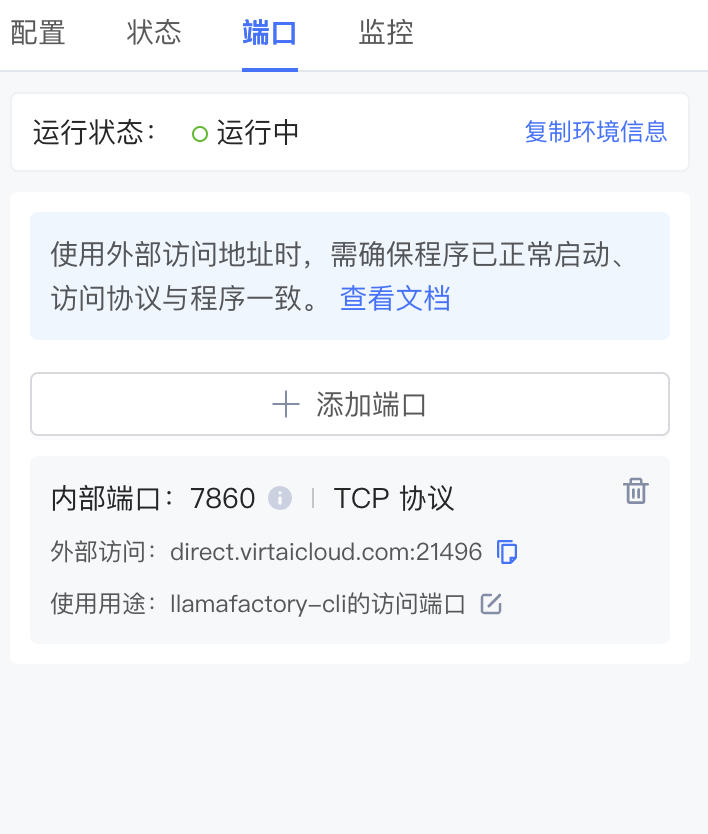
第三步:浏览器中访问端口映射后的地址,例如:direct.virtaicloud.com:21496
第四步:查看各数据集的保存位置
通过 df -h 命令可以看到磁盘的挂载情况,其中:
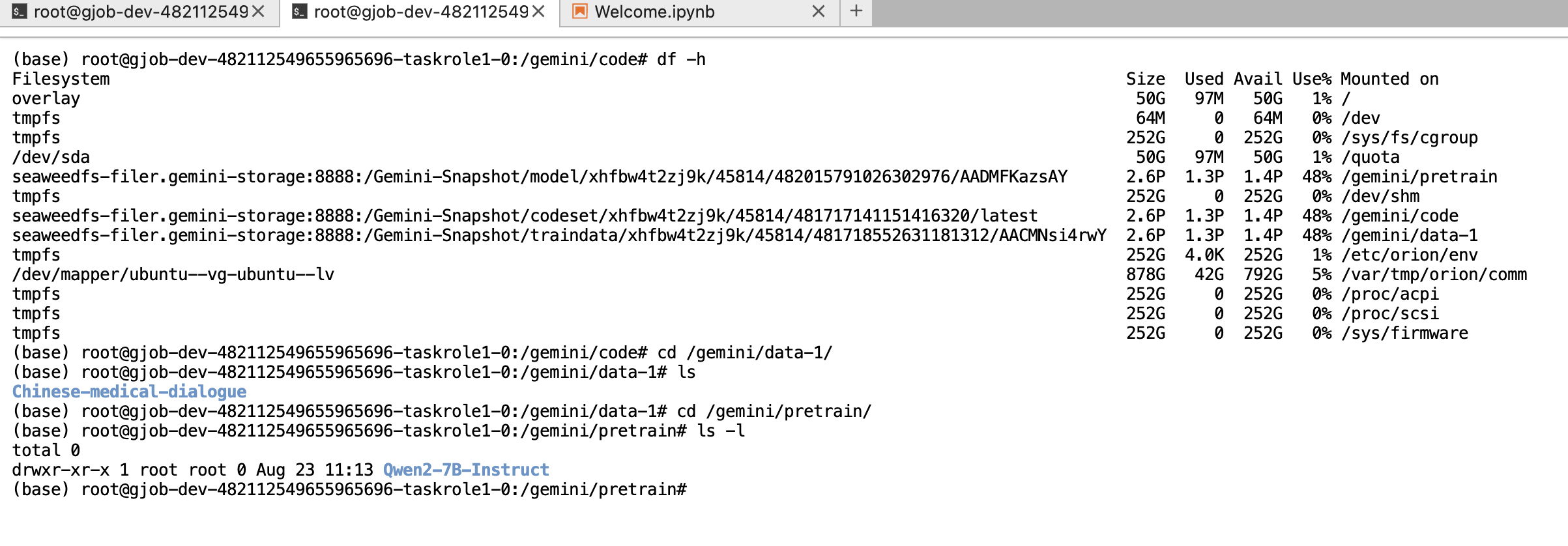
- 在趋动云官方说明文档中给出了各个路径的作用:
- /gemini/code 对应代码路径
- /gemini/pretrain 对应我们之前上传的模型文件
- /gemini/data 对应我们之前上传的数据集
第五步:配置训练参数
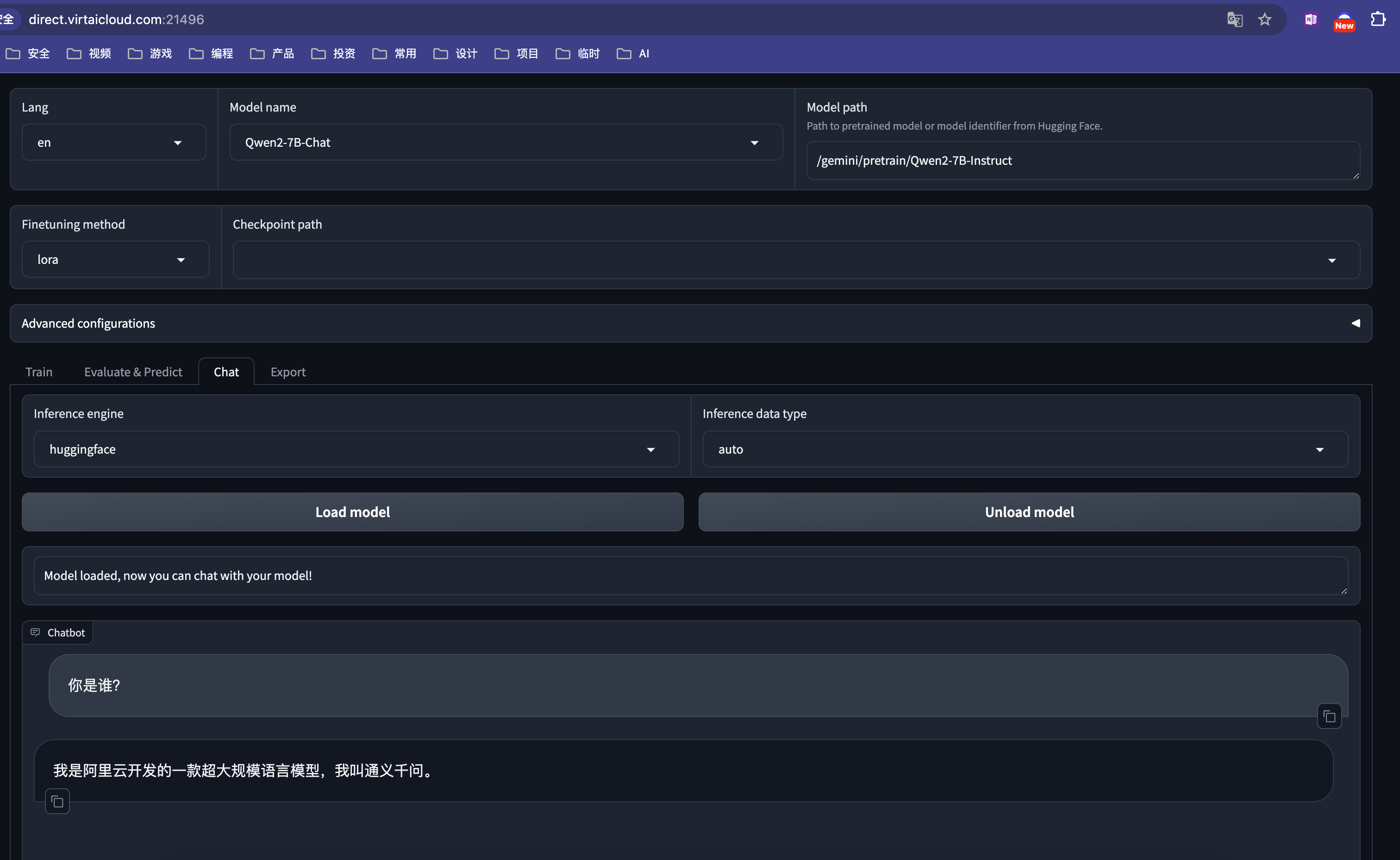
由于我们上传的模型在/gemini/pretrain下,所以训练配置为:
- Model Path填写为
/gemini/pretrain/Qwen2-7B-Instruct - Model name 填写为
Qwen2-7B-Instruct
在Chat中,点击Load Model测试模型可以正常加载。
第六步:配置数据集
如之前项目所学,如果要使用自定义的数据集,需要修改LLaMa Factory/data目录下的dataset_info.json文件。
本例中,我们通过Dockfile构建镜像时,是将LlaMa Factory下载到了/app/LLaMA-Factory/目录,所以,我们进行如下操作:
第七步:在JupyterLab左侧的文件目录,切换至/app/LLaMA-Factory/data目录下
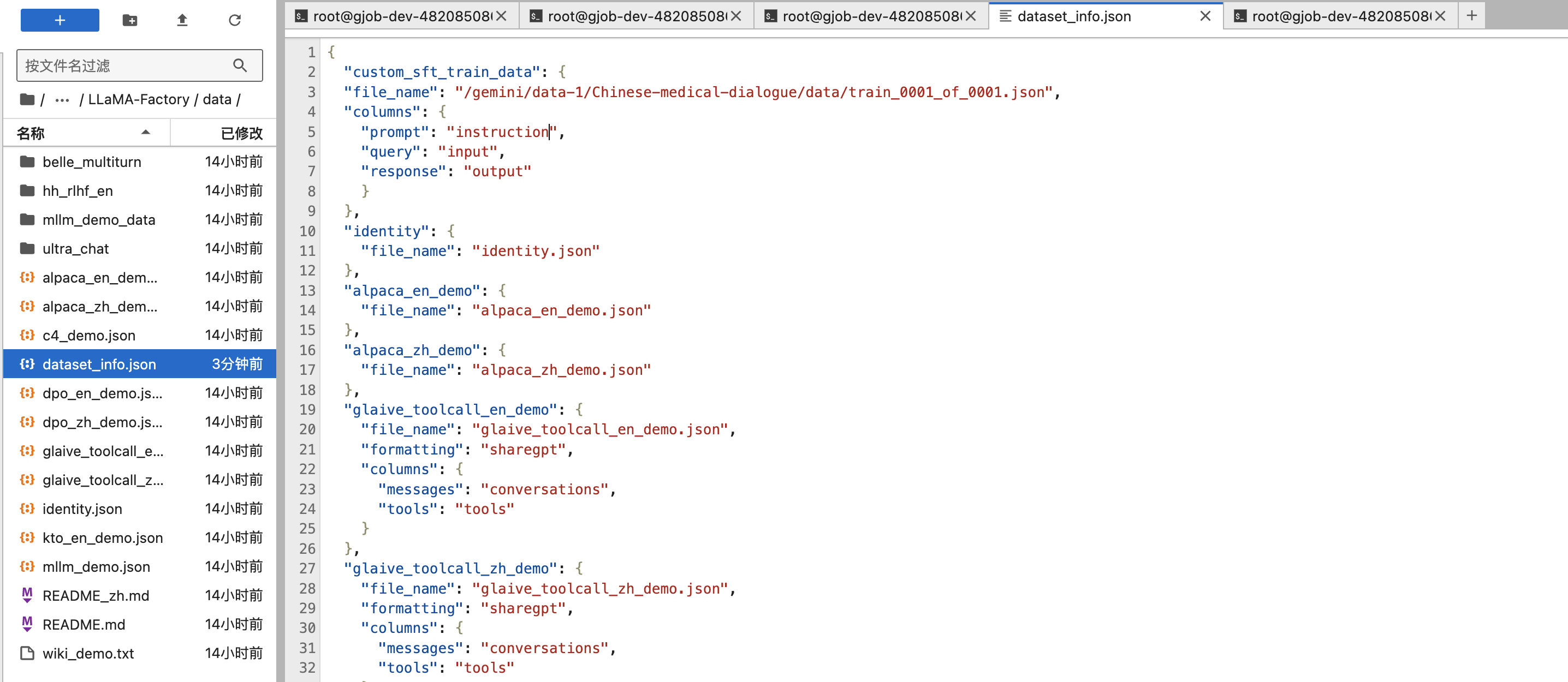
第八步:右键dataset_info.json文件 -> 打开方式 -> 编辑器,添加如下内容:
"custom_sft_train_data": {
"file_name": "/gemini/data-1/Chinese-medical-dialogue/data/train_0001_of_0001.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
说明:
- file_name对应数据集的路径,在本例中我们上传的数据集在
/gemini/data-1/,所以需要修改为对应的路径位置。
第九步:DataSet中选择custom_sft_train_data,进行Preview,查看数据集是否加载成功。
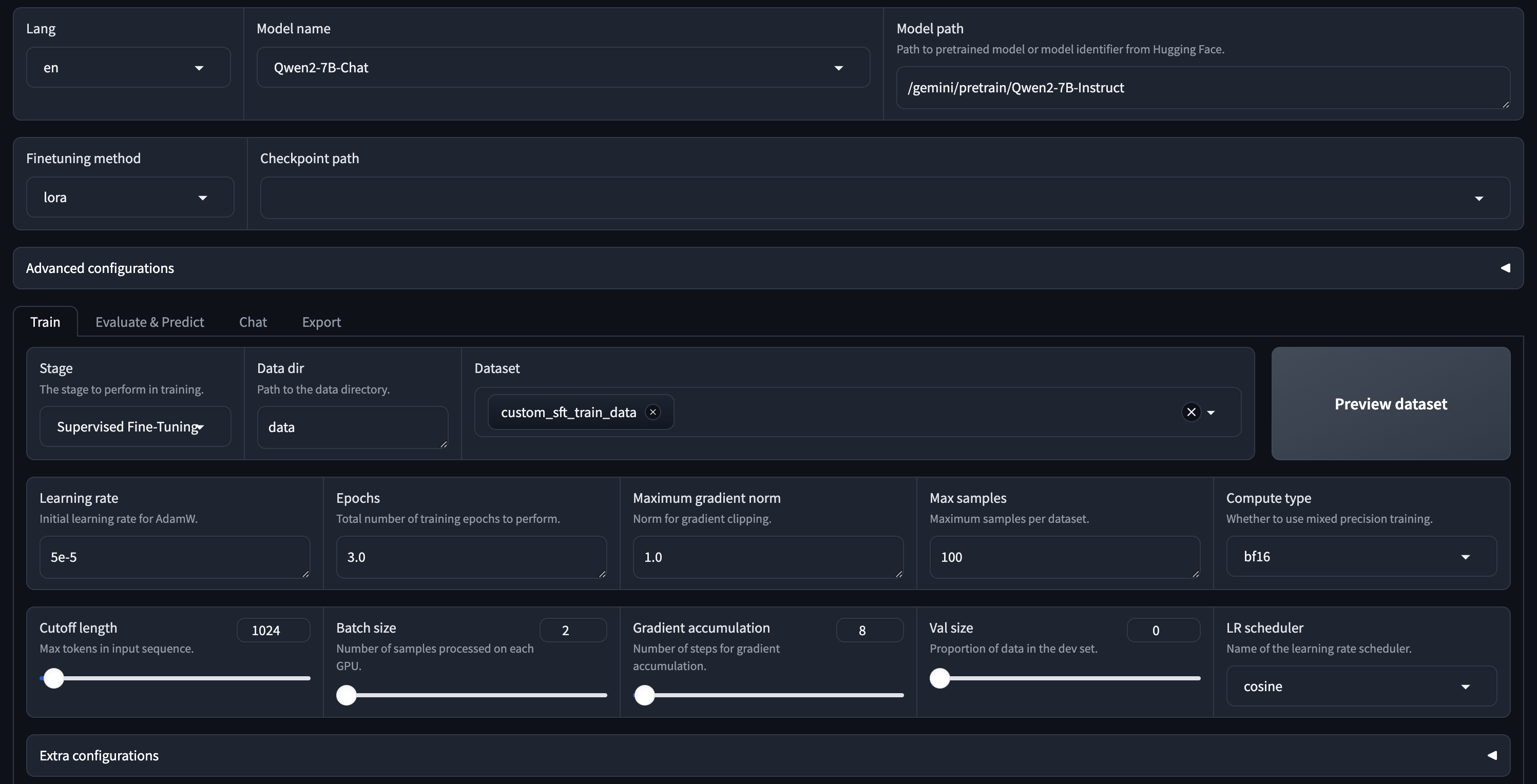
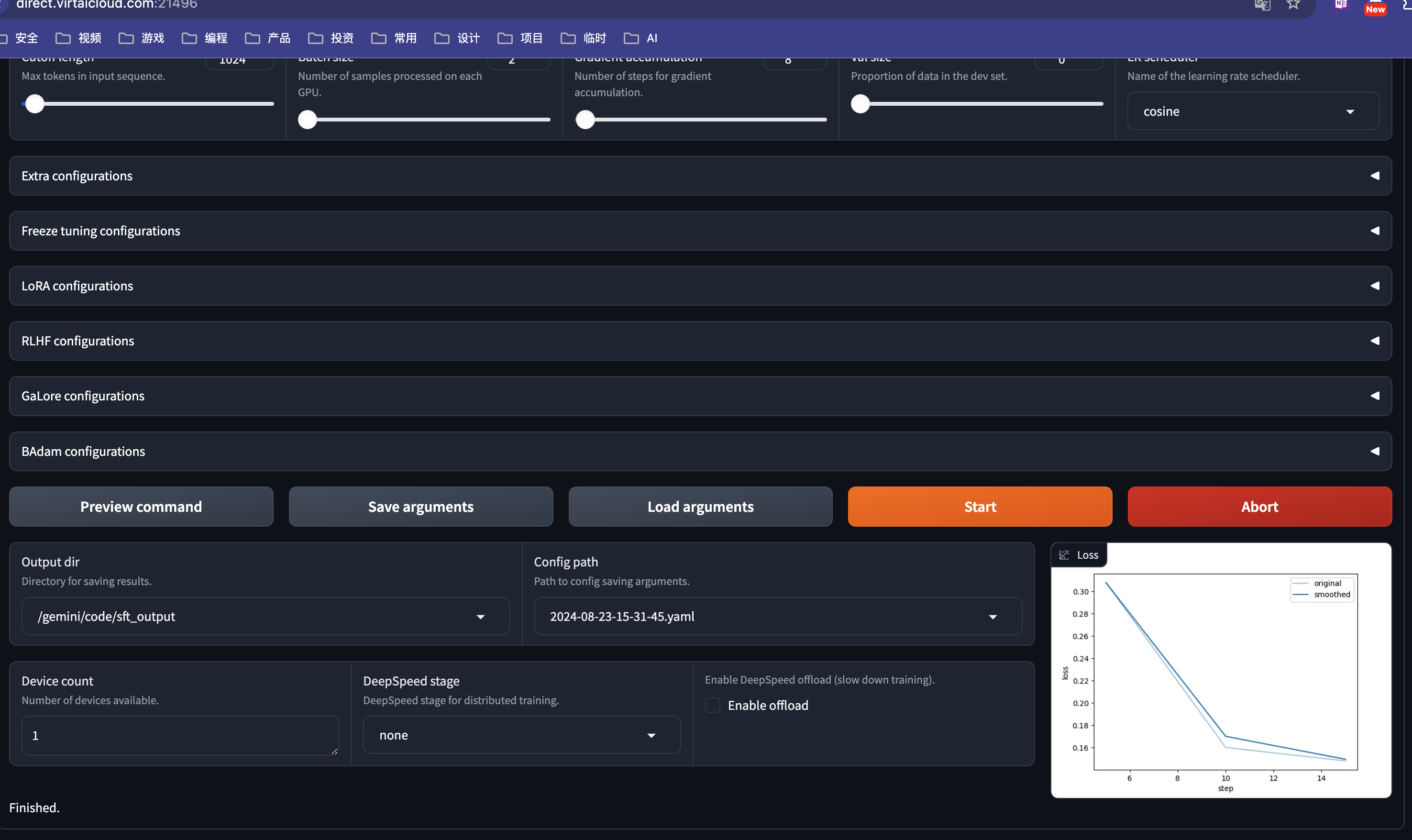
第十步:配置输出路径。
因为 /gemini/code 目录不会被清除,所以,我们选择将训练结果保存在 /gemini/code/sft_output 目录下。
通过实际测试:
- 镜像文件创建的
/app/LLaMA-Factory/目录,在开发环境重启后会被删除- 数据集目录/gemini/data-1、模型目录/gemini/pretrain目录是只读文件
- 所以,模型输出路径我这里选择输出在/gemini/code/下面。
训练过程中可以通过watch -n 1 nvidia-smi 实时查看显存的消耗情况。
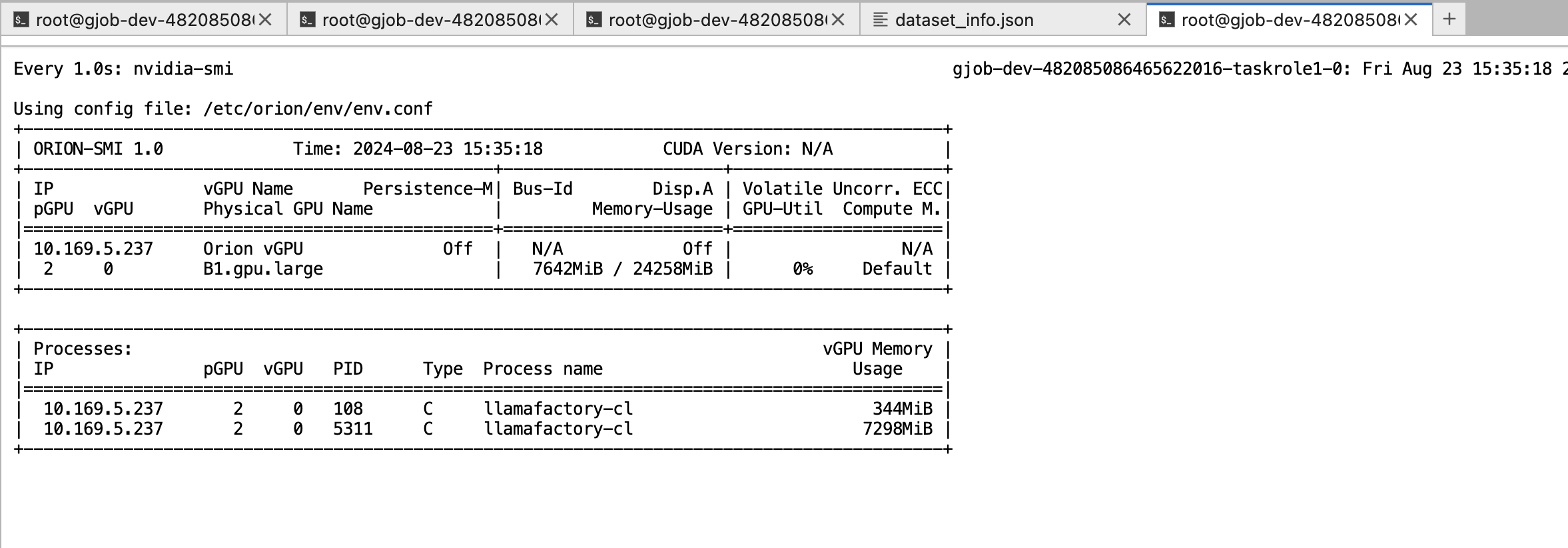
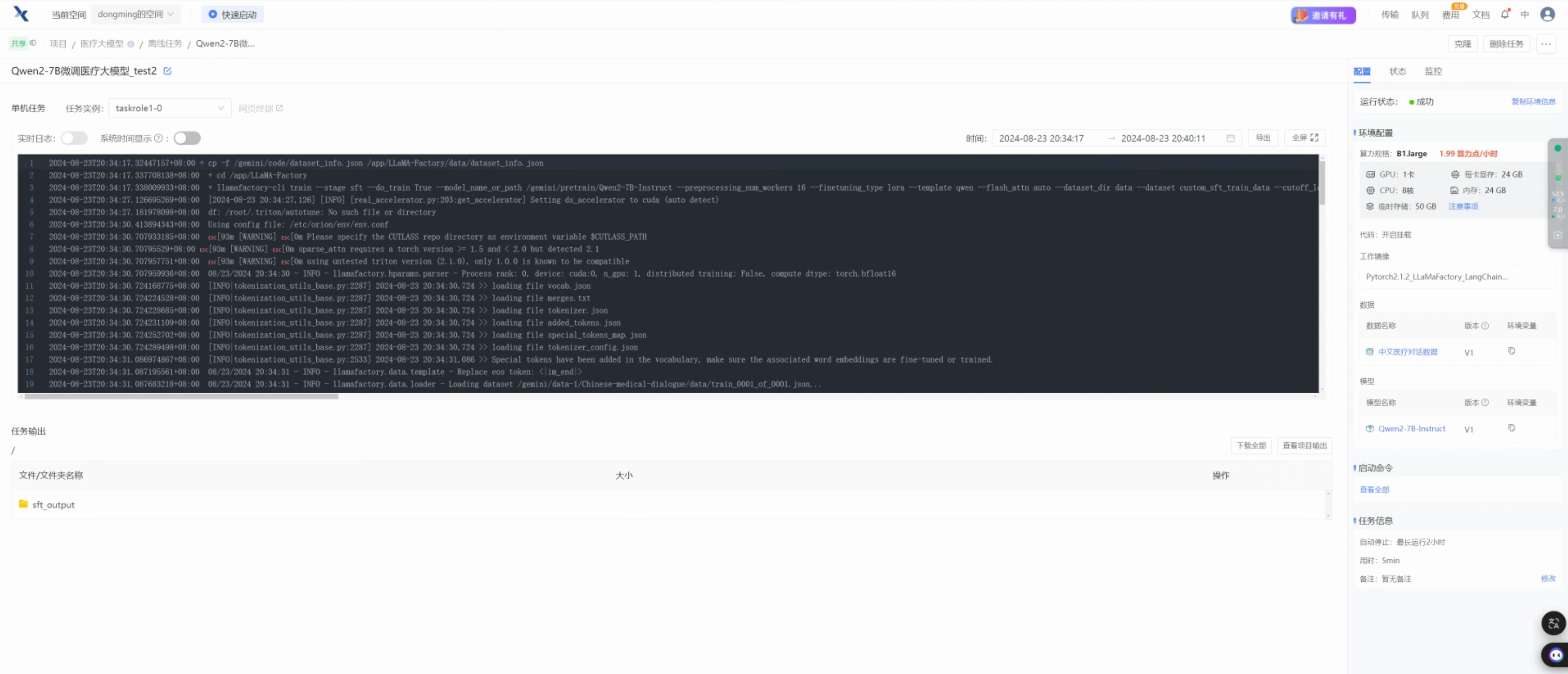
训练完毕
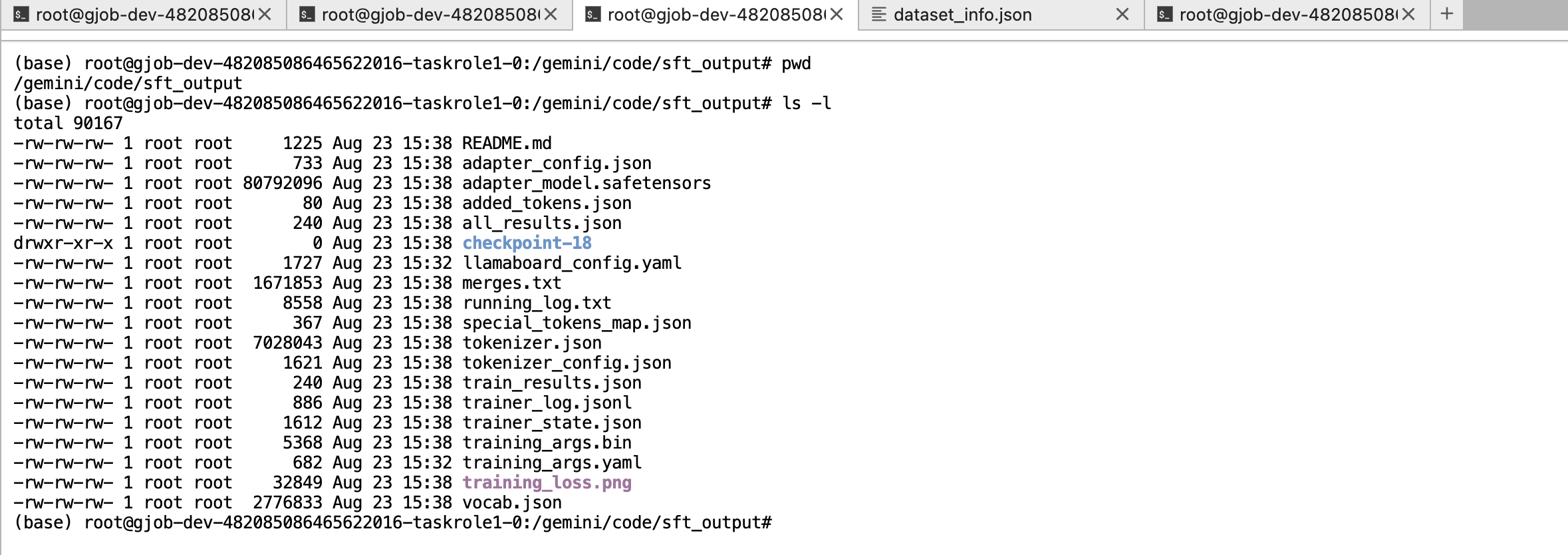
训练完毕后,切换到输出目录查看,可以看到训练结果如下:
离线训练
趋动云平台也提供了离线任务,可以将训练过程编写为脚本,直接交由平台执行而无须人工值守。本次,我们也体验下该功能。
准备dataset_info.json
因为训练的时候需要修改dataset_info.json,所以我将之前配置过自定义数据集的dataset_info.json,保存了一份放在/gemini/code目录下
配置离线任务
第一步:进入之前创建的项目中,点击右上角的离线任务

第二步:配置离线任务信息
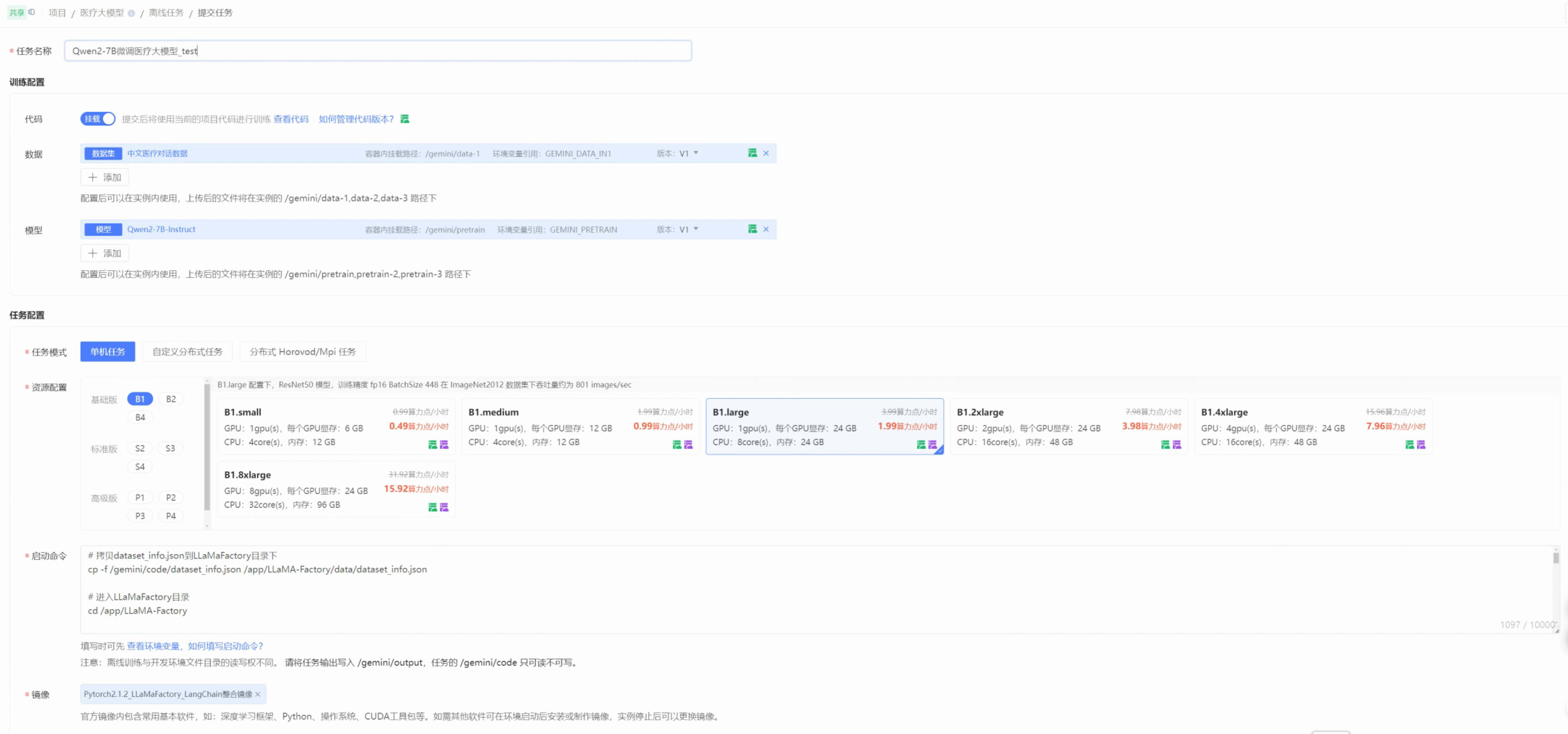
- 数据:选择之前我们上传的中文医疗大数据数据集
- 模型:选择之前我们上传的Qwen2-7B-Instruct模型
- 镜像:选择之前我们自己构建的镜像
- 启动命令中填写如下命令:
# 拷贝dataset_info.json到LLaMaFactory目录下
cp -f /gemini/code/dataset_info.json /app/LLaMA-Factory/data/dataset_info.json
# 进入LLaMaFactory目录
cd /app/LLaMA-Factory
# 执行训练命令
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /gemini/pretrain/Qwen2-7B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--dataset custom_sft_train_data \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 5000 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir /gemini/output/sft_output \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all 说明:
- 以上命令中
cd /app/LLaMA-Factory是因为使用了自己构建的镜像,所以才可使用该目录。如果是其他镜像,需要根据实际情况选择切换的LLaMa Factory目录。 - 以上命令中模型输出路径设置为官方提供的
/gemini/output/,该目录是可写的。/gemini/code在离线任务下是只读的。 - 训练命令中需要将
--save_steps设置大一些(例如:5000),以便减少训练中间产物checkpoint的记录。
运行效果:
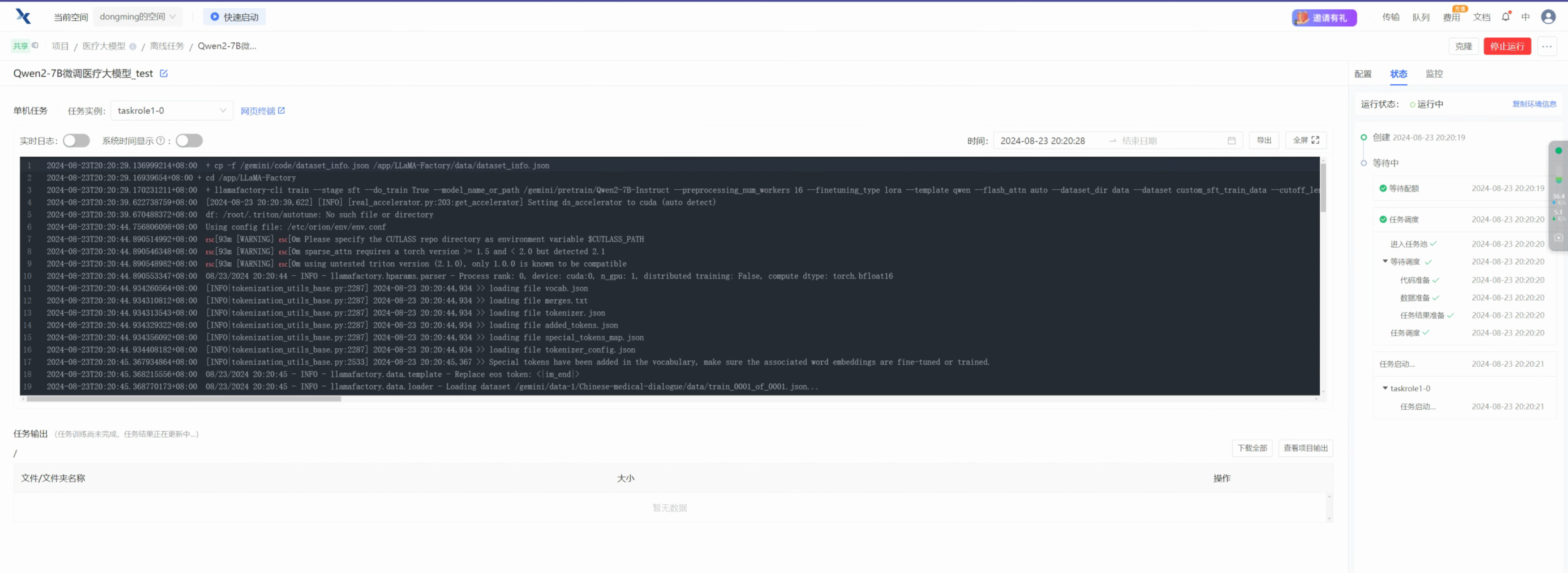
训练完毕后效果:
一些建议
在整体试用使用时发现了两个问题,建议趋动云官方进行优化:
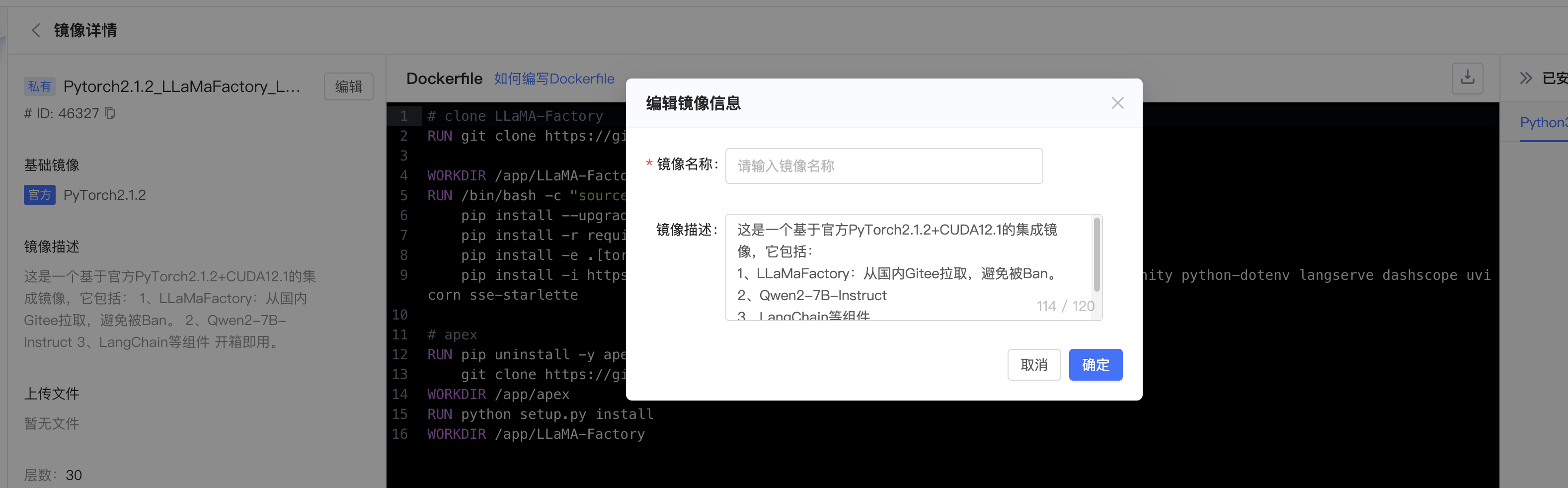
问题:编辑已存在的镜像时,镜像名称会丢失,需要用户重新输入。
复现步骤:
- 在镜像页面选择一个自己建立的镜像
- 点击镜像进入镜像详情
- 点击镜像名称编辑框
预期结果:
编辑框是之前已经创建的镜像名称
实际结果:
编辑框变为空,需要用户重新输入镜像名称,很繁琐。此外,在镜像构建失败二次构建时,也存在此问题。
建议:建议优化数据集和模型的添加方式。
用户在使用数据集和模型时,对比魔塔社区和驱动云的操作路径如下:
魔塔的操作路径是:
- 登录平台(例如魔塔社区)
- 在JupyterLab的终端中,使用git clone命令下载数据集或者模型。(因为一般数据集会使用魔塔已经存在的数据集)
- 下载完毕后,直接使用即可。
趋动云的操作路径是:
- 登录平台
- 下载数据集或者模型到本地
- 在平台上添加数据集或者模型,获取到sftp地址
- 使用 SFTP 上传到服务器
相比魔塔社区,对于开源的数据集,前者用户是在服务器上直接git clone下载,后者是先下载到本地再上传到服务器。建议这里可以增加一个直接Git拉取的功能,免去上面繁琐步骤。


