前言
最近参加了CSDN举办的《2025全球机器学习技术大会》,大会中很多会议议题都与Vibe Coding有关,同时近期围绕Cursor、Claude Code等AI编程工具的话题也比较火热。
因此,本篇内容将以一个项目改造实战为例,介绍Claude Code的实践过程。
问题
通过大会以及近期项目中的交流,AI编程在企业难以落地的问题主要有以下几个:
-
- 垂类的业务不了解。对于一些比较垂类的领域(比如内部
CRM系统、教育课件制作系统等),模型会因为对垂直领域业务知识不了解,无法胜任的问题。
- 垂类的业务不了解。对于一些比较垂类的领域(比如内部
-
- 历史代码资产不能复用。很多自媒体在介绍
Cursor等AI编程时,往往都是以编写一个小游戏或者一个新的项目(如购物网站等)为例,这类任务模型一般是可以胜任的。但是,如果是在一个已有的项目上进行编程,模型可能是无法胜任的,比如:模型在使用库函数时会使用最新的库函数,而既有项目的库函数可能是旧版本,甚至模型可能会从头开始编程实现相关功能,这就导致了企业内部之前历史资产代码不能复用。
- 历史代码资产不能复用。很多自媒体在介绍
-
- 代码质量差。如果直接交由模型生成代码,模型为了完成任务,往往代码是缺少架构设计的,可能会生成很多冗余的代码,最终开发人员不得不重构优化模型生成的屎山代码,导致效率并没有提升。
-
- 安全考虑。代码有敏感性内容,不能直接交由大模型处理,会存在核心技术泄密的问题。
- ……
接下来,我将尝试借助Claude Code的改造One-api系统的实践过程,解决上述的问题1~3。
项目背景介绍
项目简介:one-api系统是一个LLM API 管理 & 分发系统,通过该系统可以将多种 LLM(例如:DeepSeek、智谱、Qwen、OpenAI、Google Gemini)等主流模型,进行统一地 API key 管理,并且实现二次分发。
项目地址:https://github.com/songquanpeng/one-api
项目问题:
目前随着Claude Code的火热,与之相关的anthropic协议也逐步成为主流,但是one-api系统目前仅支持openai以及openai-compatible协议。
因此,我们需要对one-api系统进行改造,使其支持anthropic协议。
开发流程
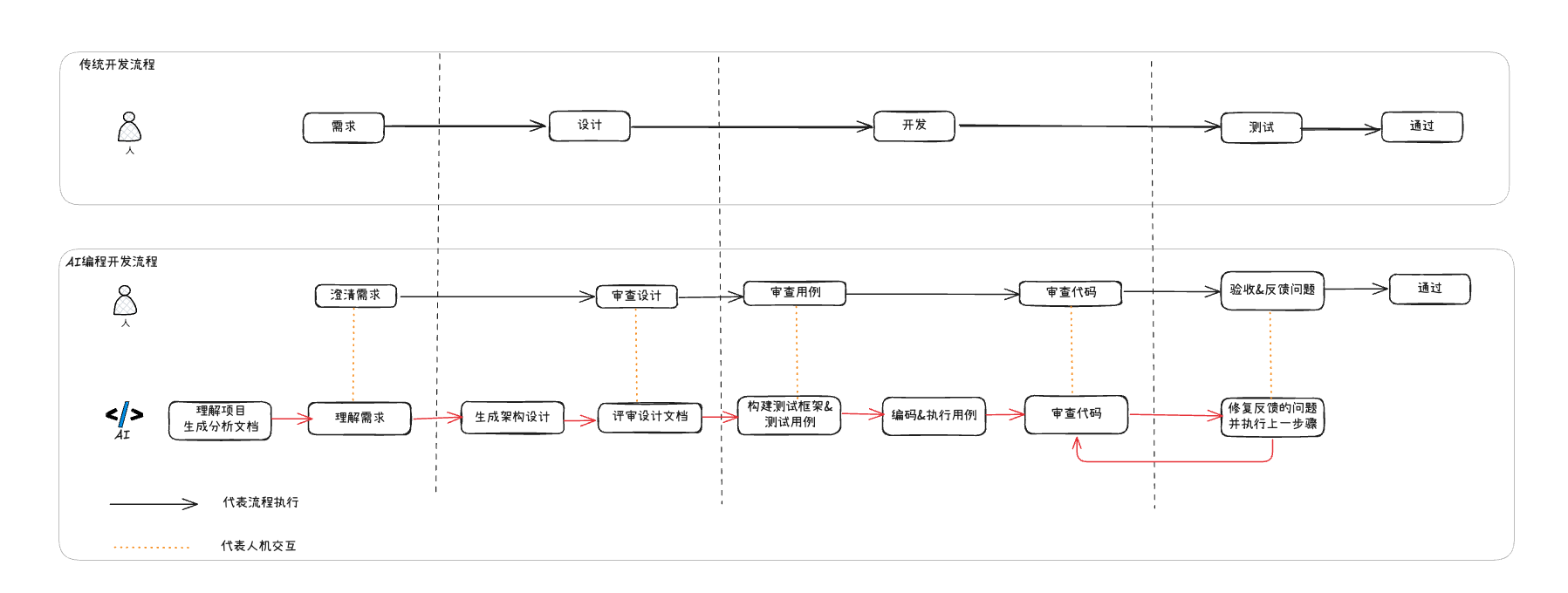
说明:
上图是一个 传统开发流程 与 使用AI编程工具的人机协作流程 对比。相比较传统开发流程会有一些不同之处:
- 人的职责由之前的
执行演变为审查与决策,而AI的职责曾承担更多的执行工作,当然AI也可以利用不同的大模型进行交叉评审。 - 整体的流程概括起来是:
熟悉理解(需求/设计/测试)任务内容–>沉淀任务内容为持久化的文档–>人机协同审查–>执行任务内容–>验证–>迭代。
接下来,我们通过Claude Code介绍上述流程的具体过程。
具体内容
1. 环境准备
1.1 配置Claude Code开发环境
由于本次开发改造使用的是Claude Code,因此我们需要在本地环境配置一个Claude Code开发环境。
上述流程属于人机系统的通用范式,所以我们也可以使用其他的AI编程工具来实现,比如Cursor、Codex、BuddyCode等等。
具体开发环境搭建流程有很多资料,本章不再赘述,详情可以查看《Claude Code+Deepseek模型的配置使用方法》
1.2 拉取对应的代码
我们需要拉取one-api系统代码,所以拉取对应的代码到本地。
git clone https://github.com/songquanpeng/one-api.git2. 理解项目并生成分析文档
2.1 核心目的
在开发流程中,我们提到了在需求开始之前,AI有一个理解项目并生成分析文档,其核心目的是让让AI对当前项目尽可能的进行深入地分析,以便在后续的开发过程中,可以更加精准的给出解决方案。
2.2 解决的问题
解决的问题:这一步骤对应主要是解决## 问题中的第一个问题:垂类的业务不了解。
2.3 具体方法
- 在当前项目创建
docs目录,用于存放文档 - 通过提示词,驱动
Claude Code进行项目梳理分析,生成相应的文档。
请根据我提出的需求,进项项目文档梳理。
背景信息:
1、one-api系统是一个LLM API 管理 & 分发系统,通过该系统可以将多种 LLM(例如:DeepSeek、智谱、Qwen、OpenAI、Google Gemini)等主流模型,进行统一地 API key 管理,并且实现二次分发。
目标:
请根据我提供的代码路径,进行相关项目的梳理,生成核心逻辑梳理。
流程:
1、你需要阅读该项目下的README.md文件
2、你需要仔细阅读项目下的代码
3、基于上述1和2的信息,梳理项目的核心逻辑,并生成相应的文档。
代码路径:
/Users/deadwalk/Code/ai_proj_llm/one-api
文档输出路径:
/Users/deadwalk/Code/ai_proj_llm/one-api/docs
具体要求:
1、文档中一定要包含整体的架构图
2、文档中一定要包含项目核心逻辑的详细描述
3、如果涉及数据库信息,请梳理数据库表结构以及对应字段的信息备注:这一步骤核心是提供详细的文档信息让AI了解,所以如果没有文档让AI自己也阅读项目理解;如果有历史文档,那么可以将文档提供给AI。
通过上述的方式,Claude Code 对项目核心内容进行了梳理,同时使用我提供的数据库地址、用户名、密码等信息,对 PostgreSQL 数据库进行了仔细的分析,最终输出了如下的文档。
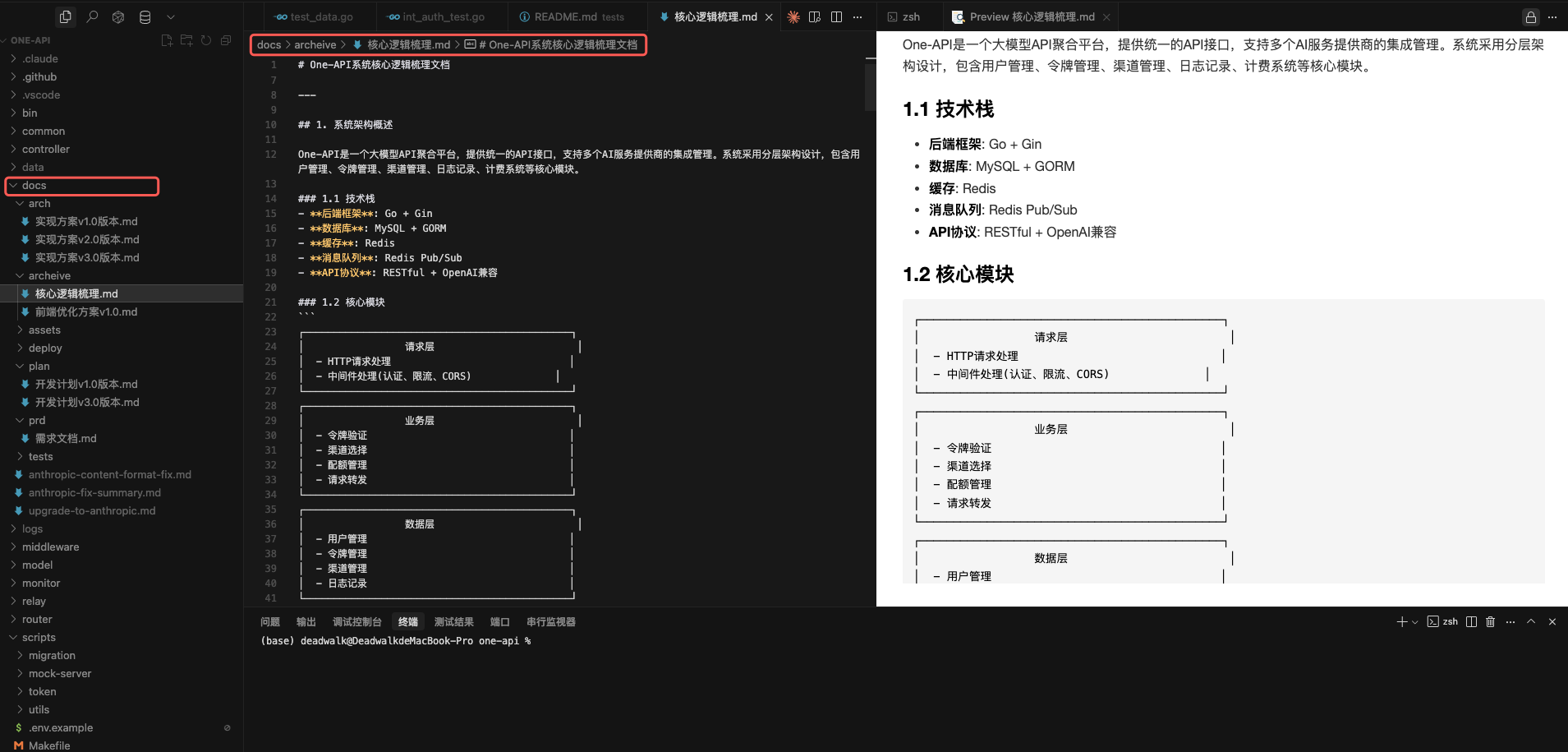
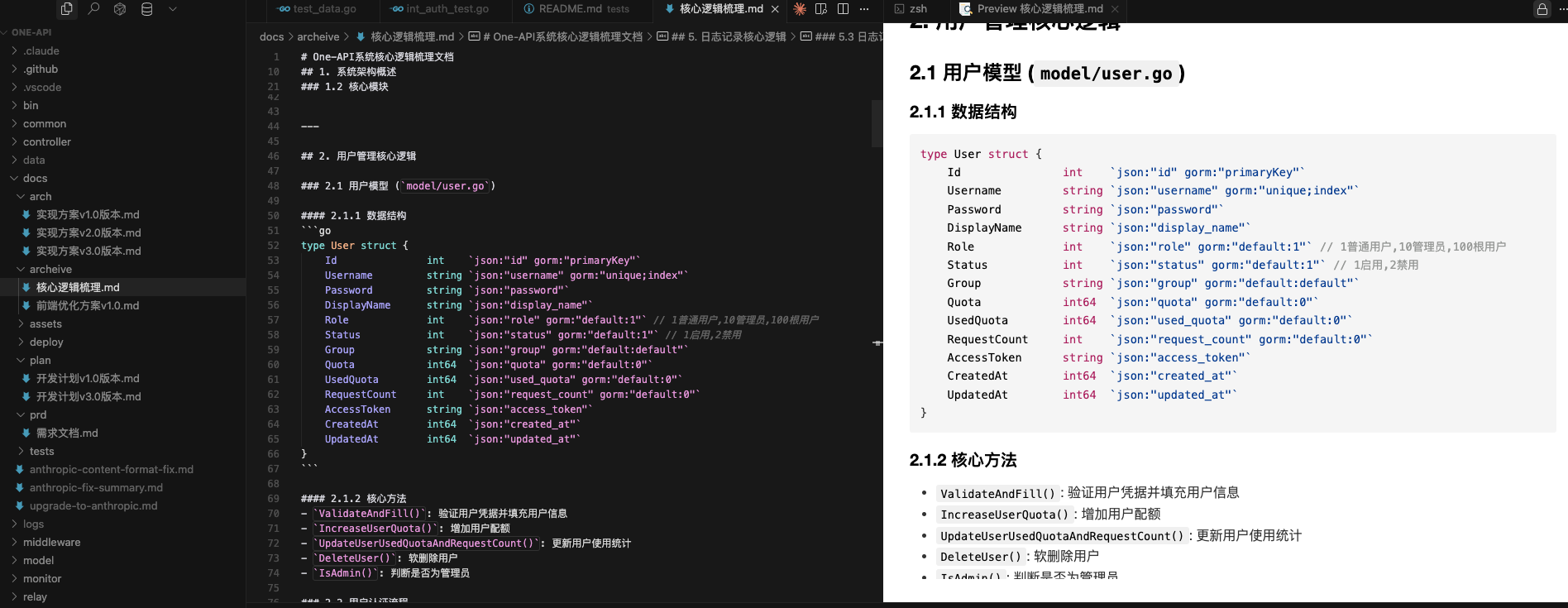
3. 需求澄清
3.1 核心目的
这一步骤主要是类比传统开发流程中的需求撰写和需求澄清,其核心目的主要是解决在AI编程工具运作的过程中,由于不断增大的上下文内容,会导致模型的能力下降而产生幻觉。
所以将需求和方案设计沉淀下来,在AI可能产生幻觉的时候使其重新阅读文档,可以最大限度避免幻觉问题。
3.2 具体方法
- 在
docs目录下创建prd目录,用于存放需求。 - 通过提示词,详细说明需求并生成相应的文档。
我一般使用的提示词如下:
请根据我提出的需求,进行相应的需求梳理并形成文档。
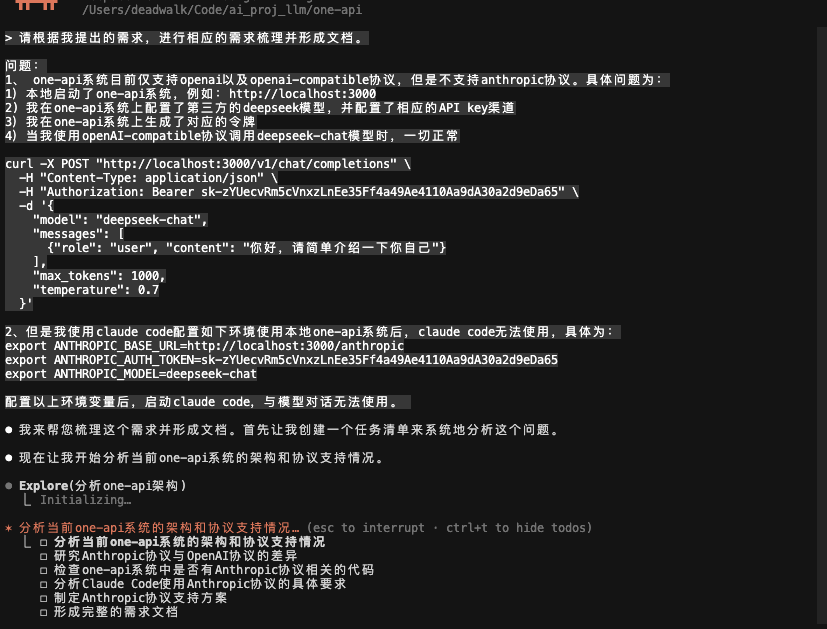
问题:
1、 one-api系统目前仅支持openai以及openai-compatible协议,但是不支持anthropic协议。具体问题为:
1)本地启动了one-api系统,例如:http://localhost:3000
2) 我在one-api系统上配置了第三方的deepseek模型,并配置了相应的API key渠道
3)我在one-api系统上生成了对应的令牌
4)当我使用openAI-compatible协议调用deepseek-chat模型时,一切正常
curl -X POST "http://localhost:3000/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-zYUecvRm5cVnxzLnEe35Ff4a49Ae4110Aa9dA30a2d9eDa65" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "user", "content": "你好,请简单介绍一下你自己"}
],
"max_tokens": 1000,
"temperature": 0.7
}'
2、但是我使用claude code配置如下环境使用本地one-api系统后,claude code无法使用,具体为:
export ANTHROPIC_BASE_URL=http://localhost:3000/anthropic
export ANTHROPIC_AUTH_TOKEN=sk-zYUecvRm5cVnxzLnEe35Ff4a49Ae4110Aa9dA30a2d9eDa65
export ANTHROPIC_MODEL=deepseek-chat
配置以上环境变量后,启动claude code,与模型对话无法使用。注意:
- 以上提示词需要尽可能地提供详细信息,让AI准确地理解需求,切不可以只是简单的一句"请添加anthropic协议"。(一句话需求在现实中,也会被程序员打回去的….)
4 设计方案
4.1 核心目的
这一步骤是基于上述的需求,实现相关的开发方案并持久化为文档,一方面便于人类进行方案合理性的审核,另一方面也是解决模型的幻觉问题。
4.2 具体方法
- 在
docs目录下创建arch目录,用于存放设计方案。 - 通过提示词,生成详细的设计方案。
- 使用其他大模型(例如
GPT-5)对既有的设计方案进行审查。
这一步骤与上述需求类似,也是通过提示词来驱动 Claude Code 干活。我经常使用的提示词如下:
请根据我提供的信息,进行相关功能的架构设计。
问题:
1、由于one-api系统目前仅支持openai以及openai-compatible协议,但是不支持anthropic协议。
目标:
1、请你根据我提出的问题和需求信息,结合行业目前anthropic协议的使用方法,生成一份one-api系统支持anthropic协议的方案。
流程:
1、你需要仔细阅读当前one-api系统的架构实现
2、你需要仔细阅读需求文档
3、你需要查询Claude Code以及anthropic协议资料
4、基于上述你的了解,输出相应的实现方案
相关资料:
1、前端代码:docs/archeive/核心逻辑梳理.md
2、需求文档:docs/prd/需求文档.md
3、Deepseek官网关于anthropic协议资料:https://api-docs.deepseek.com/zh-cn/guides/anthropic_api
要求:
1、架构设计文档应该包含整体的架构设计框架图
2、架构设计文档应该包含数据格式
3、架构设计文档应该包含核心实现流程
输出位置:
输出方案文档到docs/arch
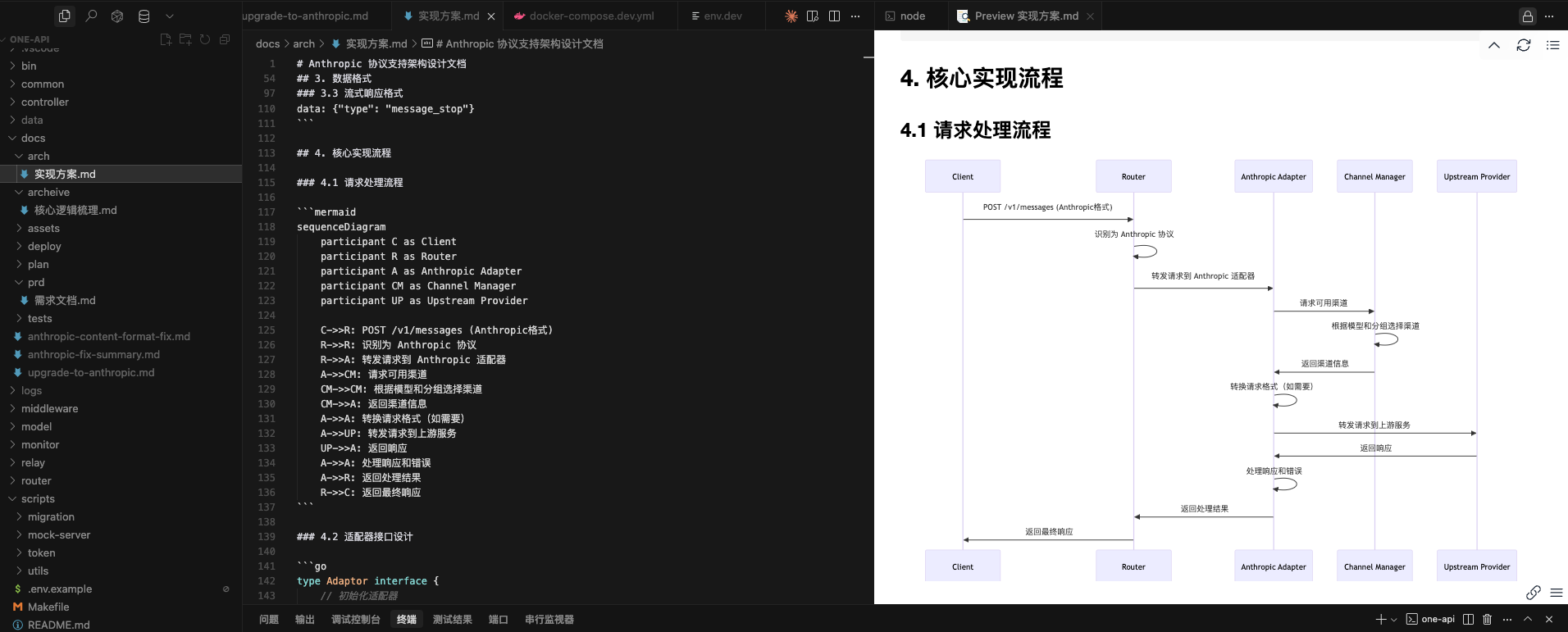
为了确保上述方案的可靠性,我们还可以借助其他大模型对上述方案进行评审,指出问题和给出修改建议。
5. 构建防护网(测试框架及测试用例设计)
5.1 核心目的
在开始编码之前,构建比较完善的防护网,确保模型修改代码时不会引入新的问题。
5.2 具体方法
- 在工程目录下创建
test目录,用于存放测试用例。 - 通过提示词,让模型对当前项目的代码进行分析,生成相应的单元测试用例和接口测试用例。
- 人工走查用例,对用例的合理性进行修正。
- 运行测试用例,确保用例都是有效且通过的。
我一般使用的提示词如下:
请根据我提供的信息,进行测试用例的完善和运行
背景:
当前项目已经进行了相关的方案设计,相关资料请见
1、需求文档:{{需求路径}}
2、实现方案:{{实现方案路径}}
目标:
1、请根据既有的代码,生成并调试并运行测试用例,用例请输出到tests目录下
要求:
1、代码要符合实现方案规划的内容
2、代码文件组织形式,要符合当前项目的文件目录组织结构,你需要对当前项目工程目录组织有个了解,不要在根目录随意创建新的文件夹
3、代码文件在符合文件目录结构的要求前提下,最好将新增代码维护在同一目录下,便于维护
4、代码要符合行业规范,向业界最佳实践看齐
5、代码的测试用例要符合当前项目的测试用例规范要求,即:tests/README.md
补充信息:
1、我已经启动了接口测试所需要的数据库docker容器
2、你在执行用例前需要在执行测试用例的命令中,增加DB_HOST=localhost,方可链接到数据库
3、后端服务日志保存在:项目根目录下的logs目录下,你可以借助后端服务日志了解执行用例失败的原因
6. 编码&调试&测试
6.1 核心目的
让AI按照既定的方案,逐步完成对应的功能实现并执行对应的测试用例,确保没有引入新的问题。
6.2 具体方法
- 让模型对既定方案进行开发计划拆解,分步骤进行开发实现。
- 在提示词中明确开发实现的要求。
我一般使用的提示词如下:
请根据我提供的信息,进行相应的开发工作。
背景:
当前项目已经进行了比较详细的需求梳理、实现方案设计以及开发计划拆分,相应的内容请见:
1、实现方案:{{实现方案路径}}
2、开发计划:{{开发计划路径}}
目标:
1、请根据实现方案进行{{第一阶段}}的开发工作
流程:
1、请你仔细阅读对应的实现方案
2、请你仔细阅读目前的代码实现
3、基于以上1和2的了解,请开发实现对应的代码
要求:
1、代码要符合实现方案规划的内容
2、代码要符合行业规范,向业界最佳实践看齐
3、代码的目录组织结构要符合既定方案中的要求
工具:
1、对于API查询,你可以使用mcp工具context7进行查询通过以上提示词,Claude Code 基本就开始干活了。基于个人的喜好,我通常是它每修改一笔代码我会进行Review代码改动,以确保它实现过程是合理的。
代码实现的示意图:
这个过程是一个持续迭代的过程,有一些注意事项:
- 每开发一部分功能则进行小的功能验证和代码Review,确保新增的代码是可靠的。
- 利用好Git,对新增的代码及时进行版本控制,防止在开发过程中代码被污染。
- 可以在代码关键位置增加日志,这样可以让AI观察代码执行过程,提升修复问题的效率。
最终,经过不断迭代和修改,我们在one-api系统上添加了anthropic协议的支持。
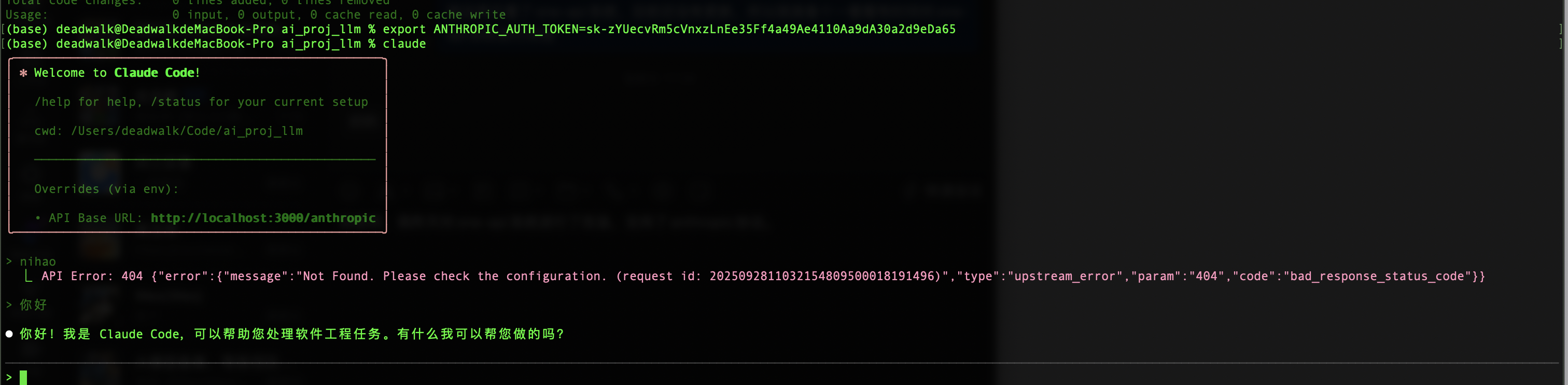
7. 文档梳理
最后一步,当所有功能完成之后,让AI对相关内容进行文档梳理和更新,比如:
- API设计可能与项目之初的方案不一致…
- 数据库的表结构可能实现过程中新增了更多字段…
- 测试用例的执行方法可能需要记录下来,方便后续快速执行。
- ….
总结
- 在 AI编程 兴起的今天,借助人机协同的方式,可以方便项目的整体开发流程
- 整体流程大致分为:
- 项目理解阶段:让 AI 对当前项目进行深度了解,生成持久化的文档,以解决对于领域知识不了解的问题
- 需求澄清阶段:通过多次澄清迭代,在项目目录下创建对应的需求文档,以解决大模型幻觉的问题
- 方案设计阶段:让 AI 根据需求设计相应的实现方案,同时对方案进行人机系统的评审,以解决历史代码不能复用的问题
- 构建防护网:通过生成单元测试、接口测试用例以及代码走查,使得 AI 在迭代的过程中输出的代码质量可靠
- 编码&调试&测试:通过小的功能迭代、验证、测试的过程,逐步完成相关的功能
- 文档梳理:在功能完成之后,对相关的方案文档、API文档、数据库设计文档、测试用例维护方法、项目部署运行等信息进行更新,以便更加方便开展下一次的迭代。



1人评论了“【项目实战】通过ClaudeCode进行one-api系统改造的实践过程总结”
学长的Prompt真好用,效果太好了