
前言
数据结构
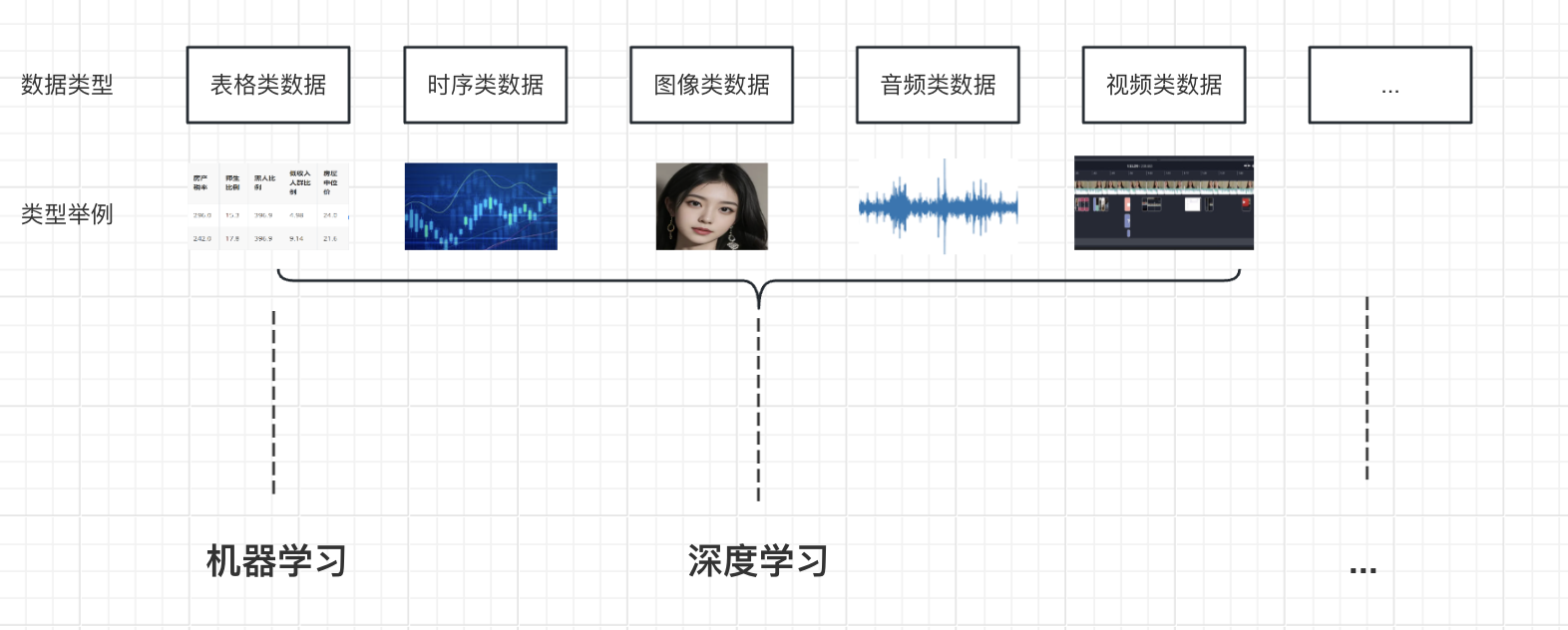
在人工智能领域,机器可以处理的数据类型如上图,大约可以分为以上类别。其中较为常用的数据类别有:
表格类数据
- 数据特点:
- 成行成列:一行一个样本,一列一个特征
- 特征之间相互独立,互不影响
- 解决办法:
- 机器学习算法
- 深度学习(全连接网络)
时序类数据 sequential data:
- 数据特点:
- 一维信号:在一个方向上,不能随便改变顺序
- 特征之间存在某种前后依赖关系
- 特征之间不是相互独立
- 数据举例:
自然语言:"我打你"和"你打我",词是一样的,但是有先后顺序,表达的意思是不一样的
股票
声音
音乐
…
- 解决办法:
- 循环神经网络
- RNN
- transformer
图像类数据 image data
-
数据特点:
- 二维信号:在两个方向上,不能随意改变顺序
-
数据举例:
-
相机拍摄
-
红外线成像
-
雷达成像
-
X光成像
…
-
图像数据操作
读取方式
使用opencv读取图片
import cv2
# 读取图像
img = cv2.imread('./beauty.png', 1)
print(type(img))
# [H, W, C]
# H: Height 高度
# W: Width 宽度
# C: Channel 通道数
# OpenCV通道排布:BGR模式
# Matplotlib通道排布:RGB模式
print(img.shape)
# 显示图像
cv2.imshow('image', mat=img)
# 等待键盘输入
cv2.waitKey(delay=3000)
- 如果未安装opencv,需要访问pypi.org,搜索opencv-python获取安装命令。
- 安装命令一般为:pip install opencv-python
- 如果有多个Python环境,需要注意安装时运行的命令行,详情请见pip安装常见问题
使用matplotlib读取图片
from matplotlib import pyplot as plt
import numpy as np
# 读取图像
img = plt.imread('beauty.png')
print(type(img))
print(img.shape)
print(img.size)
# 显示图像
plt.imshow(img)
# 显示结果
plt.show()
使用PIL读取图片
from PIL import Image
# 读取图像
img = Image.open('beauty.png')
# 显示图像
img.show()三种库的对比
| 库 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| OpenCV | – 专门用于计算机视觉任务 – 速度快 – 支持多种图像格式的读取和保存 |
– 对于简单的图像显示功能不如 Matplotlib | – 实时图像处理、视频处理、计算机视觉任务 |
| Matplotlib | – 强大的绘图库 – 支持各种图形绘制 – 方便进行图像的展示、分析和可视化 |
– 图像处理和操作功能相对较少,不如 OpenCV | – 数据可视化、图像展示、简单图像处理 |
| PIL(Pillow) | – 提供丰富的图像处理功能 – 支持图像的打开、保存、剪裁、旋转等操作 – 方便进行图像处理和转换 |
– 对于复杂的计算机视觉任务功能不如 OpenCV | – 图像处理、图像编辑、简单图像识别 |
滤波处理
均值滤波
先运行一段代码,查看图片显示效果
import cv2
import numpy as np
# 读取图像
img = cv2.imread('beauty.png')
# 不同的 N 值
kernel_sizes = [3, 5, 7, 11, 15]
# 处理不同的 N 值情况
for N in kernel_sizes:
# 创建均值滤波核
kernel = np.ones((N, N)) / N**2
img_filtered = cv2.filter2D(src=img, ddepth=-1, kernel=kernel)
# 显示图像
cv2.imshow(f'Filtered Image N={N}', img_filtered)
# 等待键盘输入和关闭窗口
cv2.waitKey(0)
cv2.destroyAllWindows()运行结果:
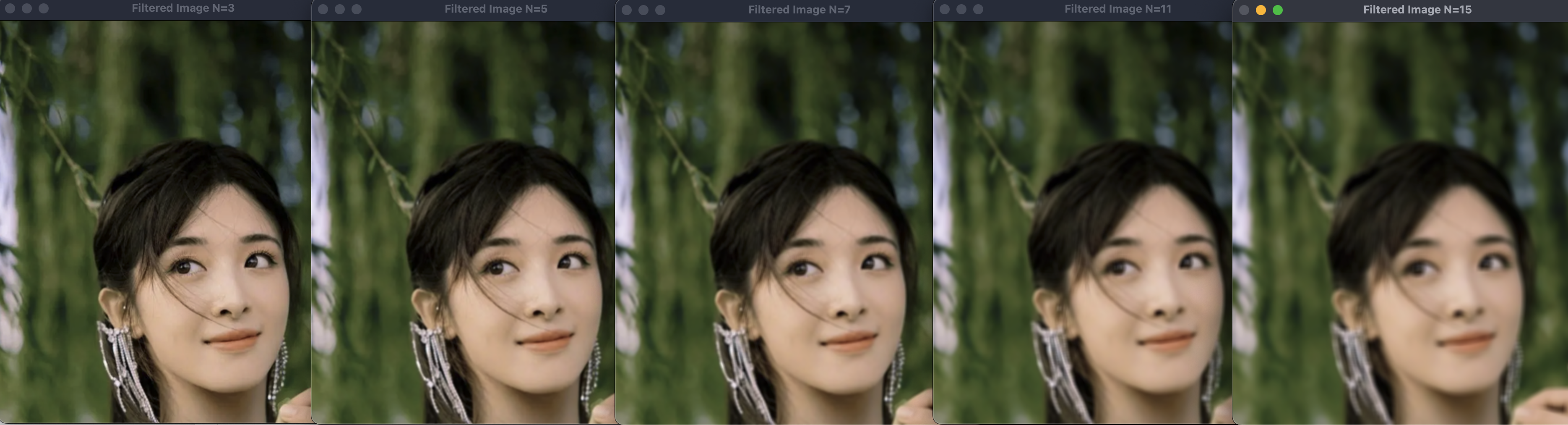
可以看到图片从左向右依次变得模糊,这是因为代码中对图像进行了滤波处理。
-
定义:图像滤波,即在尽量保留图像细节特征的条件下对目标图像的噪声进行抑制,是图像预处理中不可缺少的操作,其处理效果的好坏将直接影响到后续图像处理和分析的有效性和可靠性。
-
原理:
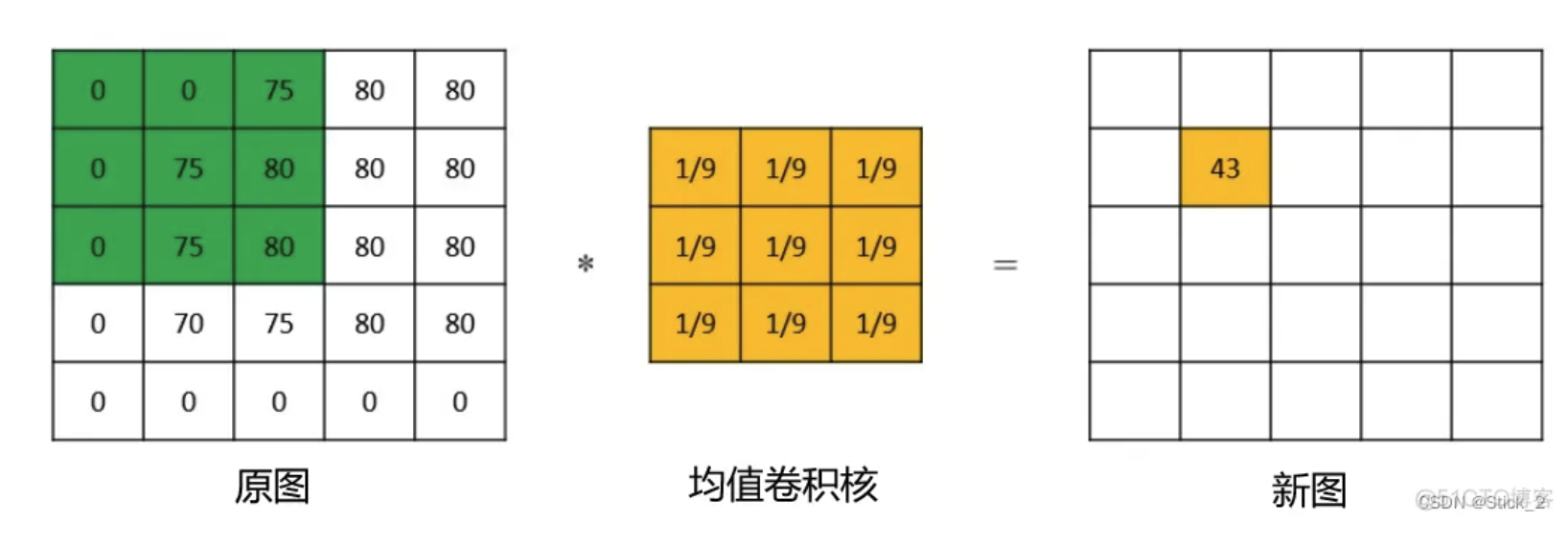
以均值滤波为例:
1、原图与一个给定的模板(例如3×3),进行两个矩阵点乘之后再相加。
2、然后依次向右移动一列,重复1步骤的计算,直到达到图片的右侧边界之后,再向下一行。
以上操作即为卷积操作。
自定义卷积核
我们定义了一个卷积核如下:
kernel = np.array([[-1,-1,-1],[0,0,0],[1,1,1]])
# 相当于如下3×3的矩阵
# 卷积核的中间行为零,第一行为负数,第二行为正数。
# [-1, -1, -1]
# [0 , 0 , 0 ]
# [1 , 1 , 1 ]这样可以突出图像中垂直方向像素有突变的情况。运行结果如下:
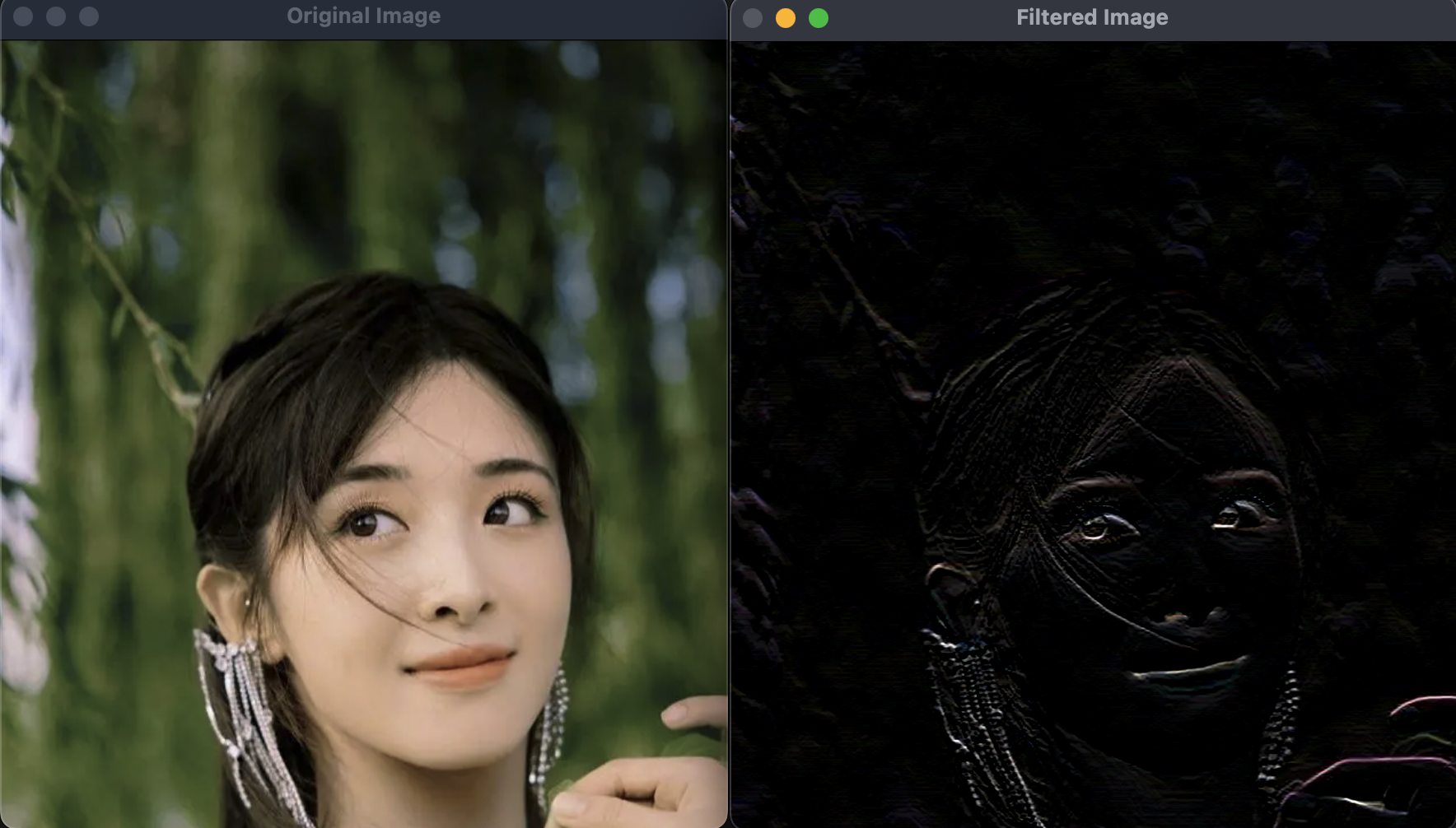
如果像素相同,经过上面卷积核的运算就会上下像素抵消为0,变成黑色;
如果像素不同,经过上面卷积核的运算就会把差异放大抽取出来,从而凸显出像素的突变。
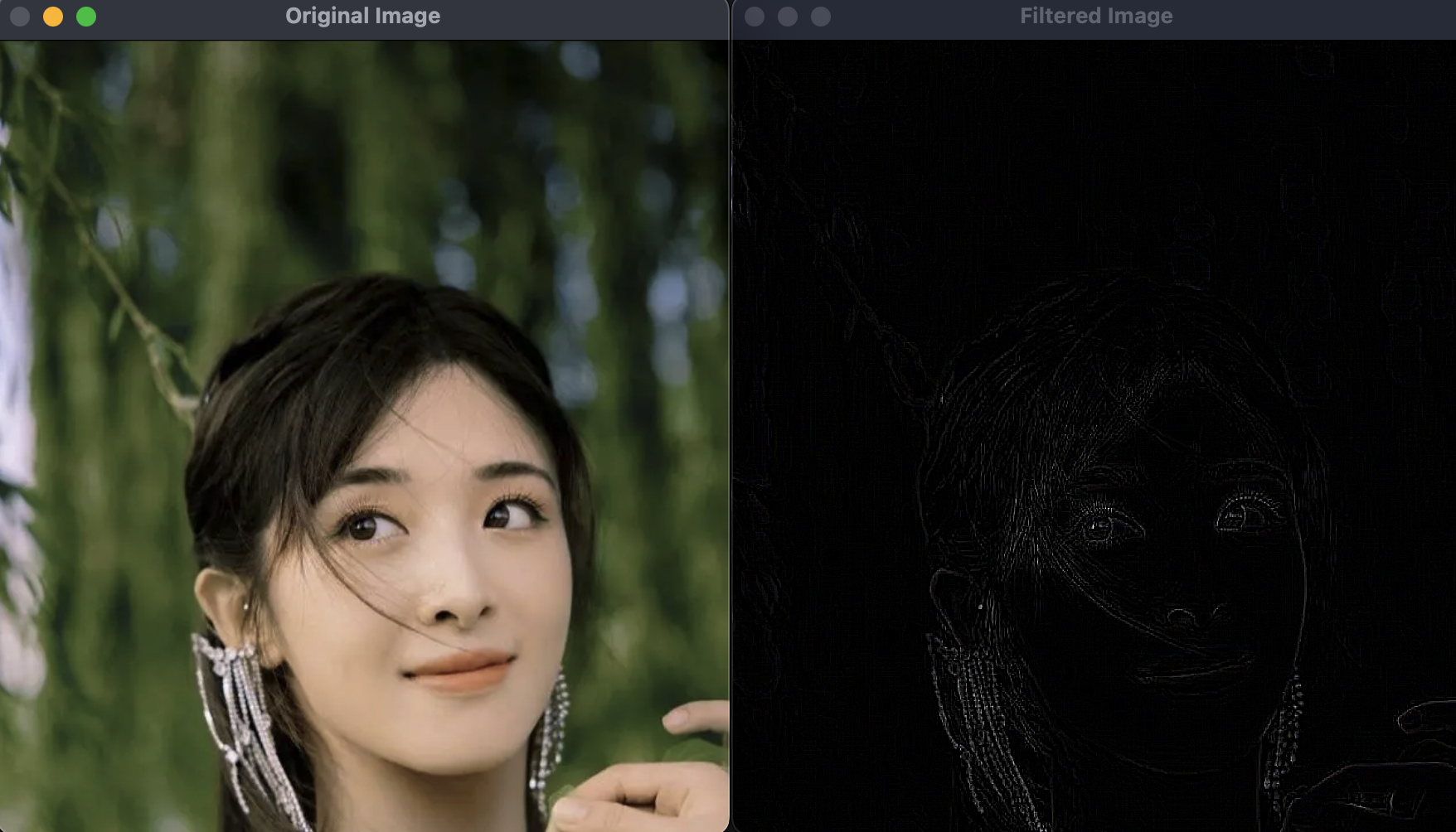
如果我们把卷积核转置一下:
kernel = np.array([[-1,-1,-1],[0,0,0],[1,1,1]])
kernel = kernel.T
# 相当于如下3×3的矩阵
# [-1, 0 , 1 ]
# [-1, 0 , 1 ]
# [-1, 0 , 1 ]这样可以突出图像中水平方向像素有突变的情况,运行结果如下:
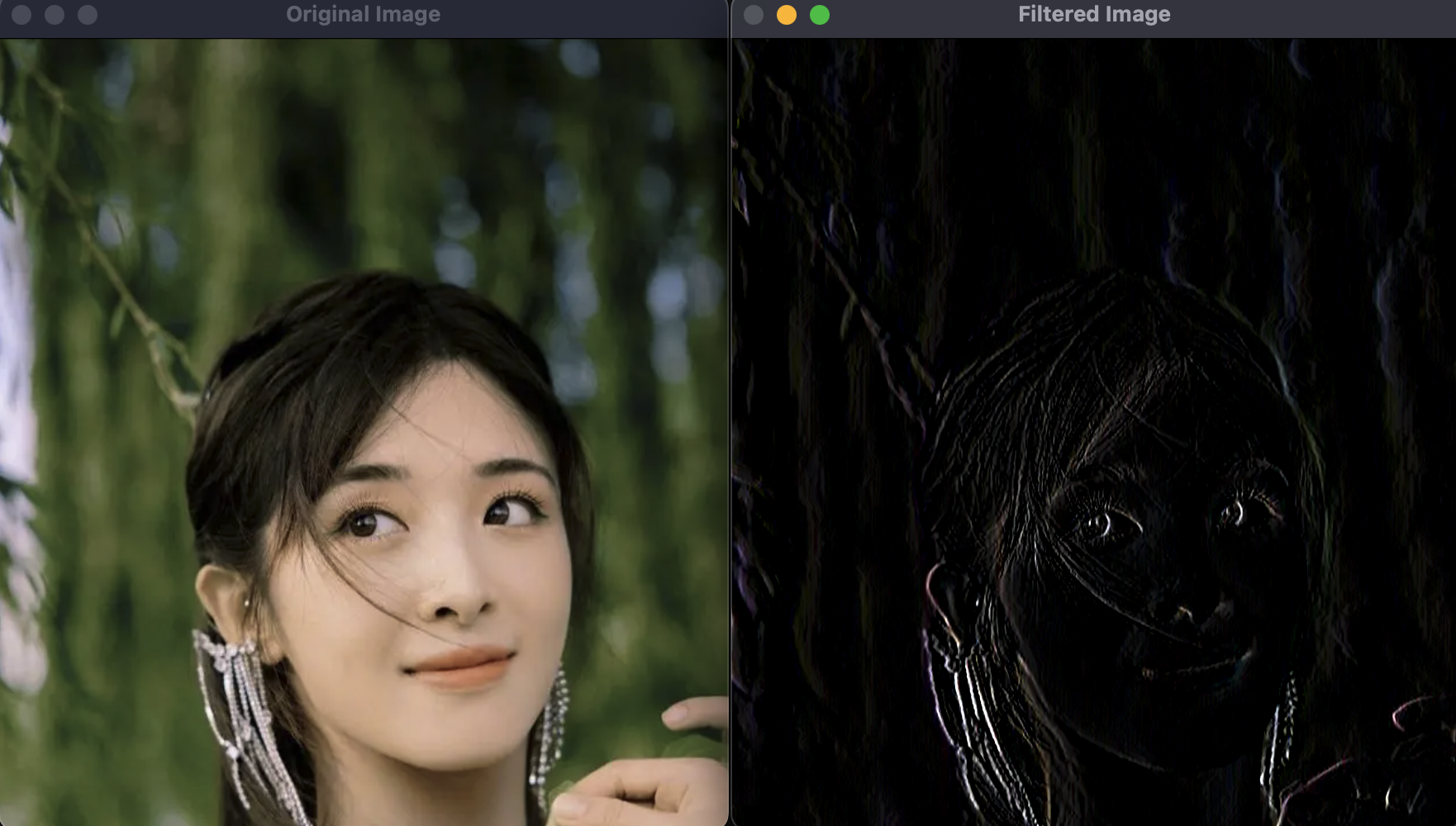
如果我们把卷积核变为如下方式:
kernel = np.array([[-1,-1,-1],[-1,8,-1],[-1,-1,-1]])
# 相当于如下3×3的矩阵
# [-1, -1, -1 ]
# [-1, 8, -1 ]
# [-1, -1, -1 ]运行结果如下:
上述图像中会对上下左右的条纹都进行抽取。
以上方法,在传统的图片处理过程中,常常用于获得图片的轮廓。
卷积操作
传统图像处理的卷积操作与神经网络中的卷积操作,大体情况如下:
-
原理是类似的,都是使用一个核,然后逐行逐列的进行矩阵运算。
-
传统图像处理中,卷积核是由工程师自己设计的;在神经网络中,这些工作都交给程序实现,不需要人参与。
我们通过pytorch的Conv2d来实现一个卷积,代码如下:
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
# 读取图像并转换为 PyTorch Tensor
img = Image.open('beauty.png').convert('L') # 以灰度模式打开图像
transform = transforms.ToTensor()
img_tensor = transform(img).unsqueeze(0) # 添加 batch 维度
# 定义卷积层
conv_layer = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=1, bias=False)
"""
in_channels:输入特征图的通道数。
out_channels:输出特征图的通道。
kernel_size:卷积核的大小,一般是3×3。
stride:卷积核每次移动的步长,默认为1。
padding:图像填充,可以是一个整数。
dilation:膨胀卷积/空洞卷积,卷积核元素之间的间距,控制卷积核的采样间距。
groups:分组卷积的组数,默认值为1。当 groups 大于1时,输入和输出的通道数必须可以被 groups 整除
bias:是否包含偏置项,默认为True。如果设置为False,则卷积层不包含偏置项。
padding_mode:填充方式,一般默认填充为0。由于信息储存在相对大小中,所有填充不影响原始内容的信息。
device:是否使用GPU
"""
# 执行卷积操作(不进行滤波)
output = conv_layer(img_tensor)
# 将输出转换为 PIL 图像
output_img = transforms.ToPILImage()(output.squeeze(0))
# 显示原始图像和卷积后图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img, cmap='gray')
plt.title('Original Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(output_img, cmap='gray')
plt.title('Convolved Image')
plt.axis('off')
plt.show()运行结果:

内容小结
- 人工智能领域处理的数据,总体概括来说有三类数据:表格类、时序类、图像类
- 图像数据处理的库有三种,opencv、matplotlib、PIL,它们各自有其优缺点和适用场景
- 图像的卷积原理,使用一个卷积核与原图进行像素点的相乘再相加计算,从而找到图像的轮廓
- 传统图像处理时需要工程师自己设计卷积核,在神经网络已交给计算机处理
参考资料
欢迎关注公众号以获得最新的文章和新闻




3人评论了“【课程总结】Day8(下):计算机视觉基础入门”
学霸高手
里面有个错字:循环神经网络
谢谢,已改