
背景
为了能够更好地评估Agent的能力,我们需要在OpenCompass的评测框架基础上,尝试引入当前最为严苛的Agent能力评估基准:GAIA(General AI Assistant Benchmark),本章是对GAIA基准测试的调研总结文档。
目标
- 目标1:调研GAIA基准测试,了解其数据内容基本构成。
- 目标2:运行GAIA基准测试,了解其运行方式。
- 目标3:在OpenCompass框架下,尝试引入GAIA基准测试。
分析
1. 了解GAIA基准测试
GAIA(A Benchmark for General AI Assistants) 是由Meta、HuggingFace等团队提出的通用AI助手评估基准,旨在测试AI系统在现实任务中的推理、多模态处理、工具使用等基础能力。GAIA(测试重点考察模型的网络浏览、多模态处理、代码执行和文件推理能力,并设置三个难度级别(基础、进阶、专家级)。例如,任务可能涉及从动态网页中提取数据、解析PDF图表,或结合图像与文本进行综合分析。
论文地址:https://arxiv.org/pdf/2311.12983
huggingface排行榜:https://huggingface.co/spaces/gaia-benchmark/leaderboard
问题规模:共包含466个问题,其中166个公开开发集问题和答案,300个测试集问题保留答案用于排行榜竞争。
问题类型:多数问题为文本形式,部分附带图像、电子表格等多模态文件(如解析表格数据或识别图像信息)。
任务场景:涵盖日常个人任务(如查找网页注册信息)、科学问题(如数据分析)及通用知识查询。
答案格式:每个问题对应唯一、简短的事实性答案(如字符串、数字或列表),便于自动化评估。
难度分级:
- Level 1:简单任务,通常无需工具或仅需1个工具,步骤不超过5步(例如查找网页中的特定信息)。
- Level 2:中等任务,需5-10步操作,结合多种工具(如网络搜索+表格解析)。
- Level 3:复杂任务,要求近乎完美的通用助手能力,需任意长操作序列和多工具协同(如跨模态信息整合与推理)
2. 下载GAIA数据集
在Jupyter Notebook 中,通过以下方式下载并获取和GAIA数据集。
2.1 配置HuggingFace镜像
import os
# 设置环境变量(仅在当前会话有效)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" 2.2 获取HuggingFace的Token
- 访问 HuggingFace 官网,注册账号并获取 Token。
2.3 通过huggingface-cli登录
在jupyter notebook中执行以下命令
!huggingface-cli login --token hf_HqxmRaSxadGZynzH*****说明:
hf_HqxmRaSxadGZynzH*****是上述第2步骤获取的HuggingFace的Token。
2.4 下载GAIA数据集
from datasets import load_dataset
ds = load_dataset("gaia-benchmark/GAIA", '2023_all', cache_dir="cache")说明:
- GAIA有三种级别数据集,分别为
2023_level1,2023_level2,2023_level3。 - 如果选择
2023_all,则默认加载所有级别的数据集。
2.5 查看数据集内容
# 查看训练集样本数
print("Train samples:", len(ds['test']))
print("Validation samples:", len(ds['validation']))运行结果:
Train samples: 301
Validation samples: 165通过以下代码进一步查看数据集的内容
from pprint import pprint
# 查看数据集的特征
pprint(ds['validation'].features)
# 查看第一条数据的元数据
sample = ds['validation'][0]
pprint(sample)运行结果:
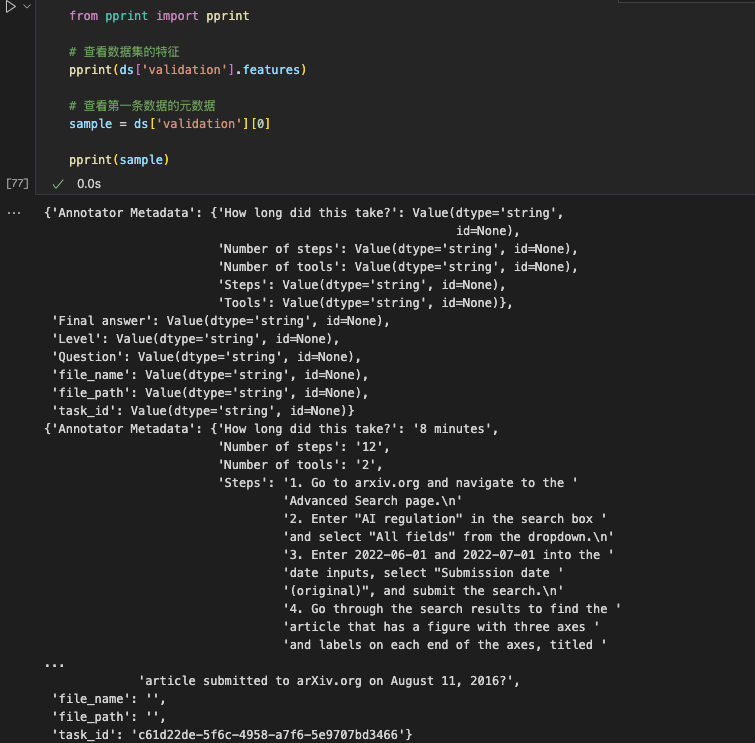
说明:
GAIA数据集中主要的组成部分即为:Question、Final Answer。Question的问题一般是需要使用一定工具才能获取到答案的问题。Final Answer是对应Question对应的答案,是确定性的答案。GAIA数据集为了避免数据污染(将测试数据集拿来进行训练,从而提高榜单排名),其数据集中只有Validation有答案,而Test数据集的答案为空。
3. 分析GAIA数据集
为了更加深入理解GAIA数据集,我们挑选部分数据集更加直观地了解其内容。
3.1 样例1
task_id:c61d22de-5f6c-4958-a7f6-5e9707bd3466
Question:
A paper about AI regulation that was originally submitted to arXiv.org in June 2022 shows a figure with three axes, where each axis has a label word at both ends. Which of these words is used to describe a type of society in a Physics and Society article submitted to arXiv.org on August 11, 2016?
翻译:一篇最初于2022年6月提交到arXiv.org的关于AI监管的论文展示了一个包含三个坐标轴的图表,每个轴的两端都带有标签词。在2016年8月11日提交给arXiv.org的《物理与社会》文章中,这些词中哪个被用来描述一种社会类型Final Answer:
egalitarian
翻译:平等主义说明:
为了回答上述的Question,Agent必须具有外部工具访问的能力,它需要执行以下步骤才能得到答案:
- 访问
arXiv.org并进入“高级搜索(Advanced Search)”页面。 - 在搜索框中输入
“AI regulation”,并从下拉菜单中选择“All fields”(所有字段),提交搜索 [4]。 - 在日期输入栏中填写
2022-06-01和2022-07-01,选择“Submission date (original)”(提交日期-原始),提交搜索。 - 在搜索结果中找到标题为
《Fairness in Agreement With European Values: An Interdisciplinary Perspective on AI Regulation》的论文,确认其图表包含三个坐标轴且轴两端有标签 [1][4]。 - 记录该图表标签的六个词汇:
deontological(义务论的),egalitarian(平等主义的),localized(本地化的),standardized(标准化的),utilitarian(功利主义的),consequential(结果主义的)。 - 返回
arXiv.org。 - 在分类列表中找到并进入
“Physics and Society”(物理与社会)类别页面 [4]。 - 记录该分类的标签为
“physics.soc-ph”。 - 再次进入
“高级搜索”页面。 - 在搜索框输入
“physics.soc-ph”,选择“All fields”(所有字段)[4]。 - 在日期栏输入
2016-08-11和2016-08-12,选择“Submission date (original)”(提交日期-原始),提交搜索。 - 在结果中搜索这六个词,找到标题为
《Phase transition from egalitarian to hierarchical societies driven by competition between cognitive and social constraints》的论文,确认“egalitarian”是正确答案 [4]。
备注:
以上步骤在数据集的标注内容Annotator Metadata中有说明。
3.2 样例2
task_id:17b5a6a3-bc87-42e8-b0fb-6ab0781ef2cc
Question:
I’m researching species that became invasive after people who kept them as pets released them. There’s a certain species of fish that was popularized as a pet by being the main character of the movie Finding Nemo. According to the USGS, where was this fish found as a nonnative species, before the year 2020? I need the answer formatted as the five-digit zip codes of the places the species was found, separated by commas if there is more than one place.
调查因宠物放生导致入侵的生物。某鱼类因《海底总动员》主角(尼莫)走红,随后被放生至非原生地。根据USGS数据,2020年前此鱼作为外来物种被发现于何处?需以5位邮编(多个则逗号分隔)呈现答案。Final Answer:
34689说明:
为了回答上述的Question,Agent需要执行以上步骤才能得到答案:
- 查证电影原型——搜索"finding nemo main character"并确认主角为小丑鱼(clownfish)[来源:搜索引擎]。
- 定位数据库——访问USGS非本地水生物种库(Nonindigenous Aquatic Species),在海洋鱼类分类下找到小丑鱼条目「Clown anemonefish」
- 提取位置信息——筛选2020年前记录[2](案例:仅佛罗里达州Fred Howard Park一处[5])。
- 检索邮编(外部工具)——通过地名确认邮编为34689[7]。
- 输出结果 —— 因单条记录直接返回:34689
3.3 样例3
task_id: 32102e3e-d12a-4209-9163-7b3a104efe5d
Question:
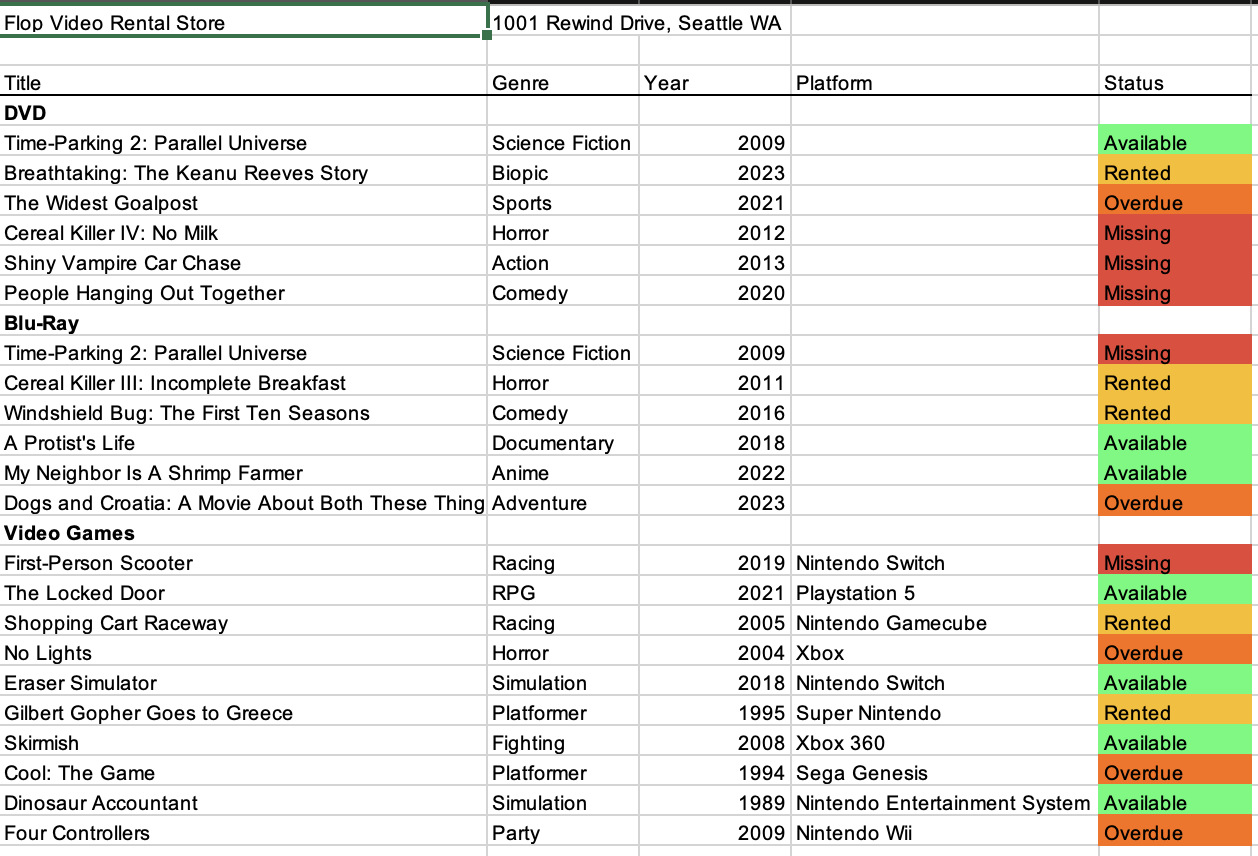
The attached spreadsheet shows the inventory for a movie and video game rental store in Seattle, Washington. What is the title of the oldest Blu-Ray recorded in this spreadsheet? Return it as appearing in the spreadsheet.
所附电子表格是美国华盛顿州西雅图市某影碟游戏租赁店的库存清单,需回答:表格中记录的年代最早的蓝光光碟(Blu-Ray)的标题是什么?答案必须严格按表格内原文格式返回。Final Answer:
Time-Parking 2: Parallel Universe说明:
为了回答上述的Question,Agent需要执行以上步骤才能得到答案:
- 打开文件:载入提供的电子表格。
- 筛选数据:找到“Blu-Ray”分类列,比对年份字段,确认最早的年份为 2009年。
- 定位目标:锁定2009年份对应的蓝光光碟标题:
《Time-Parking 2: Parallel Universe》(保留原文拼写和大小写)
3.4 样例4
task_id: fcca530fc-4052-43b2-b130-b30968d8aa44
Question:
Review the chess position provided in the image. It is black's turn. Provide the correct next move for black which guarantees a win. Please provide your response in algebraic notation.
查看图片中给出的棋局情况。轮到黑方走棋了。给出黑方能确保获胜的正确下一步走法。请以国际象棋的代数表示法给出您的回答。Final Answer:
Rd5说明:
为了回答上述的Question,Agent需要执行以上步骤才能得到答案:
-
读取图片

-
棋盘局面评估(所有子力位置与态势分析)
-
生成黑方最优着法 → 最终输出:Rd5 [精确代数记谱法格式]
通过以上的样例分析,初步了解到:
- GAIA数据集是以
Question + Answer的形式存在的。 - GAIA数据集的问题一定是需要
Agent借助外部工具(如:搜索引擎、数据库、文件解析器等)才能得到正确答案。 - GAIA数据集中的部分问题会涉及到附件文档,文档类型包含:xlsx、pdf、docx、png等,agent需要能够解析并提取其中的信息。
实施
4. 添加GAIA数据集
4.1 opencompass/datasets 增加数据集定义
代码文件:libs/OpenCompass/opencompass/datasets/gaia.py
代码内容:
import json
from os import environ
import os
from datasets import Dataset
from opencompass.registry import LOAD_DATASET
from opencompass.utils import get_data_path
from .base import BaseDataset
@LOAD_DATASET.register_module()
class GAIADataset(BaseDataset):
@staticmethod
def load(path, local_mode: bool = False):
from datasets import load_dataset
try:
# 因为ModelScope的GAIA数据集读取存在问题,所以从huggingface读取
ds = load_dataset("gaia-benchmark/GAIA", '2023_all', split='validation')
rows = []
for item in ds:
rows.append({
'question': item['Question'],
'answerKey': item['Final answer'],
'file_path': item['file_path'],
'file_name': item['file_name'],
'level': item['Level']
})
except Exception as e:
print(f"Error loading local file: {e}")
return Dataset.from_list(rows)4.2 opencompass/configs 增加数据集配置
代码文件:libs/OpenCompass/opencompass/configs/datasets/GAIA/gaia.py
代码内容:
from opencompass.openicl.icl_prompt_template import PromptTemplate
from opencompass.openicl.icl_retriever import ZeroRetriever
from opencompass.openicl.icl_inferencer import GenInferencer
from opencompass.openicl.icl_evaluator import AccEvaluator
from opencompass.datasets import GAIADataset
from opencompass.utils.text_postprocessors import first_capital_postprocess
gaia_reader_cfg = dict(
input_columns='question',
output_column='answerKey',
test_split='test')
gaia_infer_cfg = dict(
prompt_template=dict(
type=PromptTemplate,
template=dict(round=[
dict(
role='HUMAN',
prompt=
'请根据问题:{question}\n给出答案。答:'
),
]),
),
retriever=dict(type=ZeroRetriever),
inferencer=dict(type=GenInferencer),
)
gaia_eval_cfg = dict(
evaluator=dict(type=AccEvaluator),
pred_role='BOT',
pred_postprocessor=dict(type=first_capital_postprocess),
)
gaia_datasets = [
dict(
abbr='gaia-validation',
type=GAIADataset,
path='opencompass/gaia',
local_mode=False,
reader_cfg=gaia_reader_cfg,
infer_cfg=gaia_infer_cfg,
eval_cfg=gaia_eval_cfg,
)
]
4.3 opencompass/utils/datasets_info.py 添加数据集映射
代码文件:libs/OpenCompass/opencompass/utils/datasets_info.py
代码内容:
DATASETS_MAPPING = {
# GAIA Datasets
"opencompass/gaia": {
"ms_id": None,
"hf_id": "gaia-benchmark/GAIA",
"local": "./data/gaia/",
},
# 以下内容省略4.4 dataset-index.yml 注册数据集
代码文件:libs/OpenCompass/opencompass/dataset-index.yml
代码内容:
- gaia:
name: GAIA
category: Reasoning
paper: https://arxiv.org/abs/2311.12983
configpath: opencompass/configs/datasets/GAIA/gaia_gen.py
configpath_llmjudge: ''4.5 __init__.py 添加初始化信息
代码文件:libs/OpenCompass/opencompass/datasets/__init__.py
代码内容:
from .gaia import * # noqa: F401, F403至此,我们完成了在Compass中添加GAIA数据集的配置。
5. 调试运行 gaia 数据集
在VsCode的launch.json中,增加如下调试配置:
{
"version": "0.2.0",
"configurations": [
{
"name": "OpenCompass",
"type": "python",
"request": "launch",
"module": "opencompass.cli.main",
"cwd": "${workspaceFolder}/libs/OpenCompass",
"python": "${command:python.interpreterPath}",
"env": {
"MODEL": "deepseek-ai/DeepSeek-V3",
"API_KEY": "sk-pboelsoxvgeapocquovvdkvv******",
"API_URL": "https://api.siliconflow.cn/v1/"
},
"args": [
"--models", "custom_api",
"--datasets", "gaia_gen",
"--debug", "-m", "all"]
}
]
} 运行OpenCompass调试配置,运行结果如下:
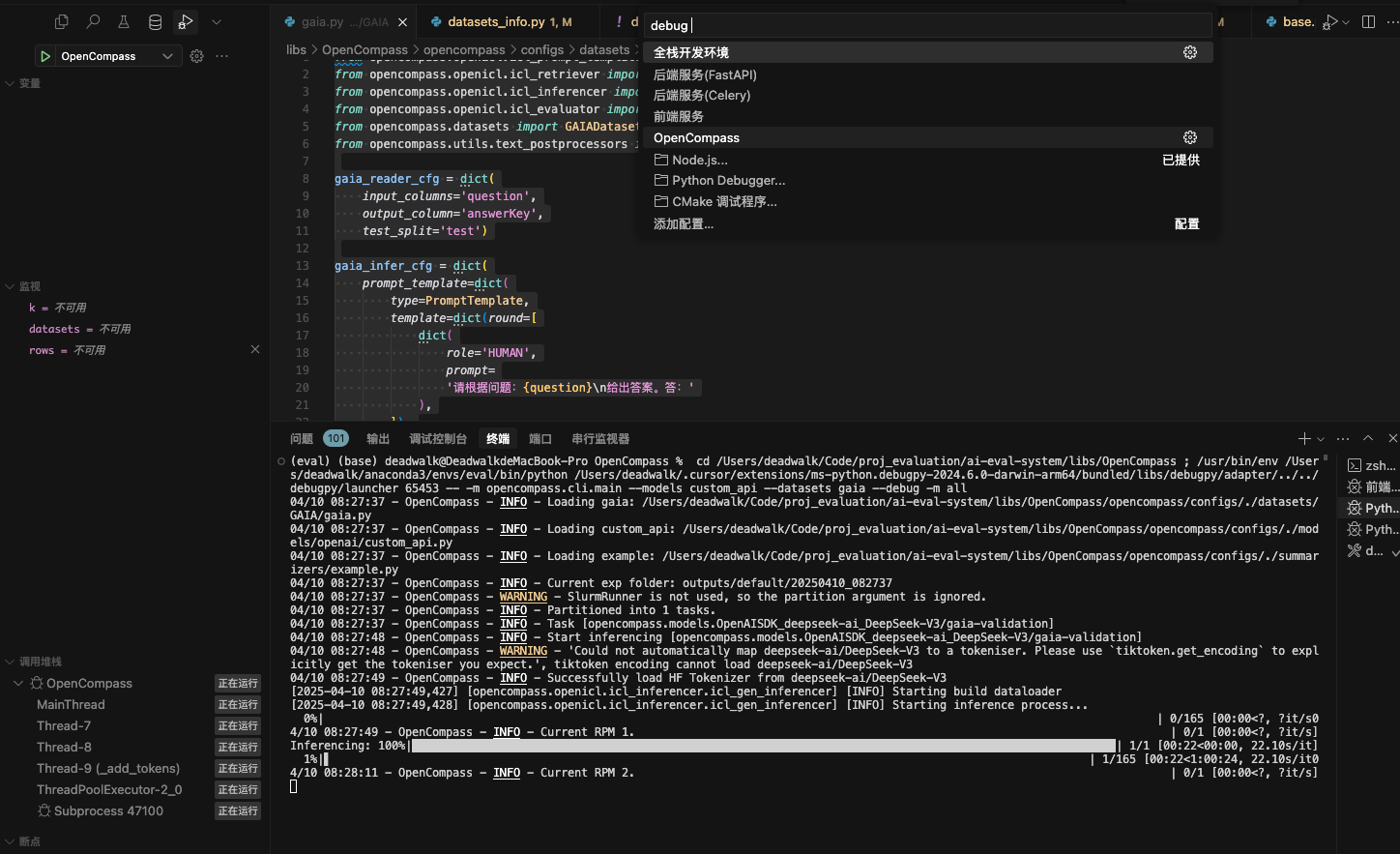
从图中可以看到,新添加的gaia数据集运行成功,下一步将数据集添加至ai-eval-system中,以便进行Dify平台上Agent的评测。
6. 集成至ai-eval-system中进行Dify平台应用评测
6.1 配置数据集
确保在ai-eval-system下的libs/OpenCompass的目录下,已完成上述4.1~4.5步骤。
6.2 数据库添加数据集
通过以下SQL命令向数据库添加数据集信息:
INSERT INTO datasets (
name,
description,
category,
type,
file_path,
configuration,
user_id,
is_active
) VALUES
(
'gaia_gen',
'GAIA数据集,这是一种严苛的评估Agent通用能力评测的数据集,其中包含165个任务,每个任务都需要agent借助外部工具来完成。',
'智能体',
'benchmark',
'/data/gaia',
'{"format": "chat"}',
1,
1
);6.3 开发者方式启动ai-eval-system
具体方法请参考Readme文档,此处不再赘述。
6.4 Dify平台创建Agent应用
在Dify平台上创建一个Agent并且为Agent添加arxiv_search工具,如下:
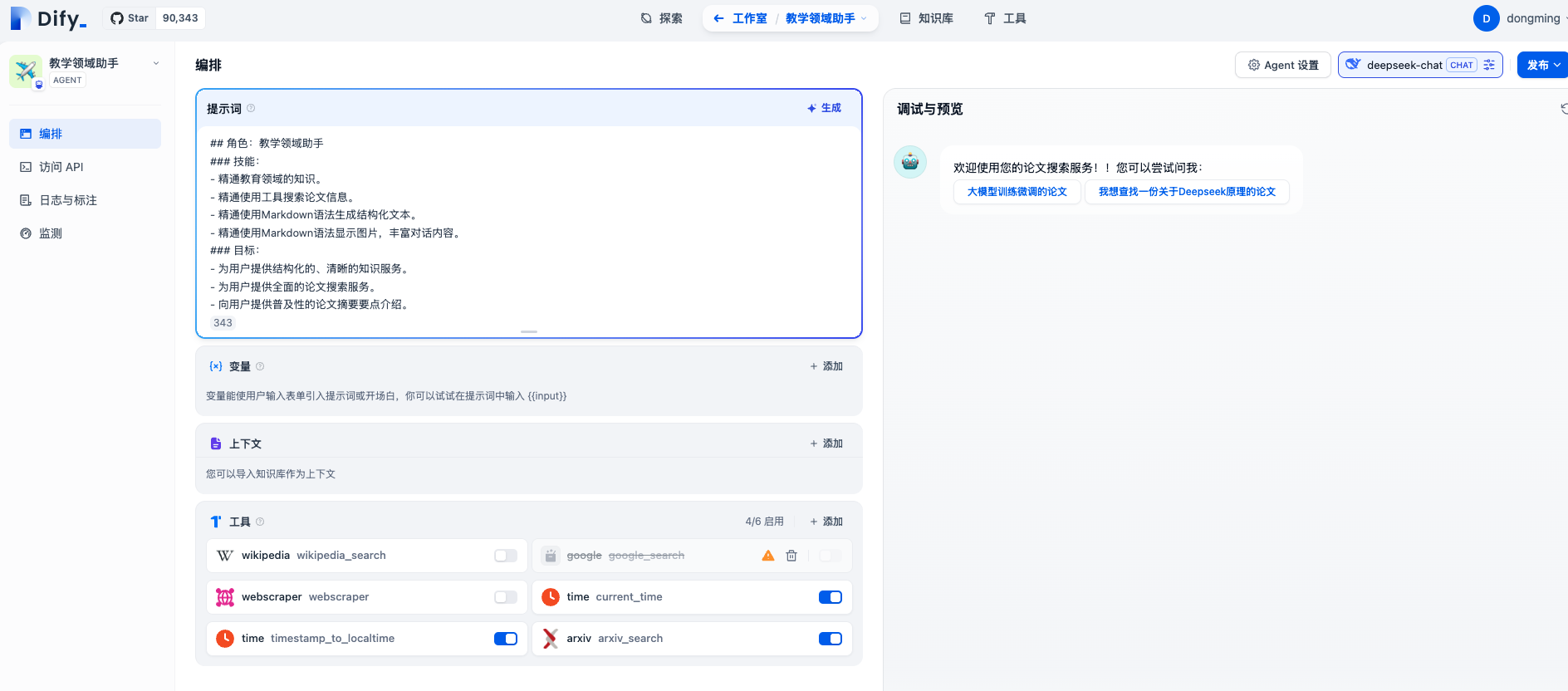
6.4 ai-eval-system平台创建评测任务
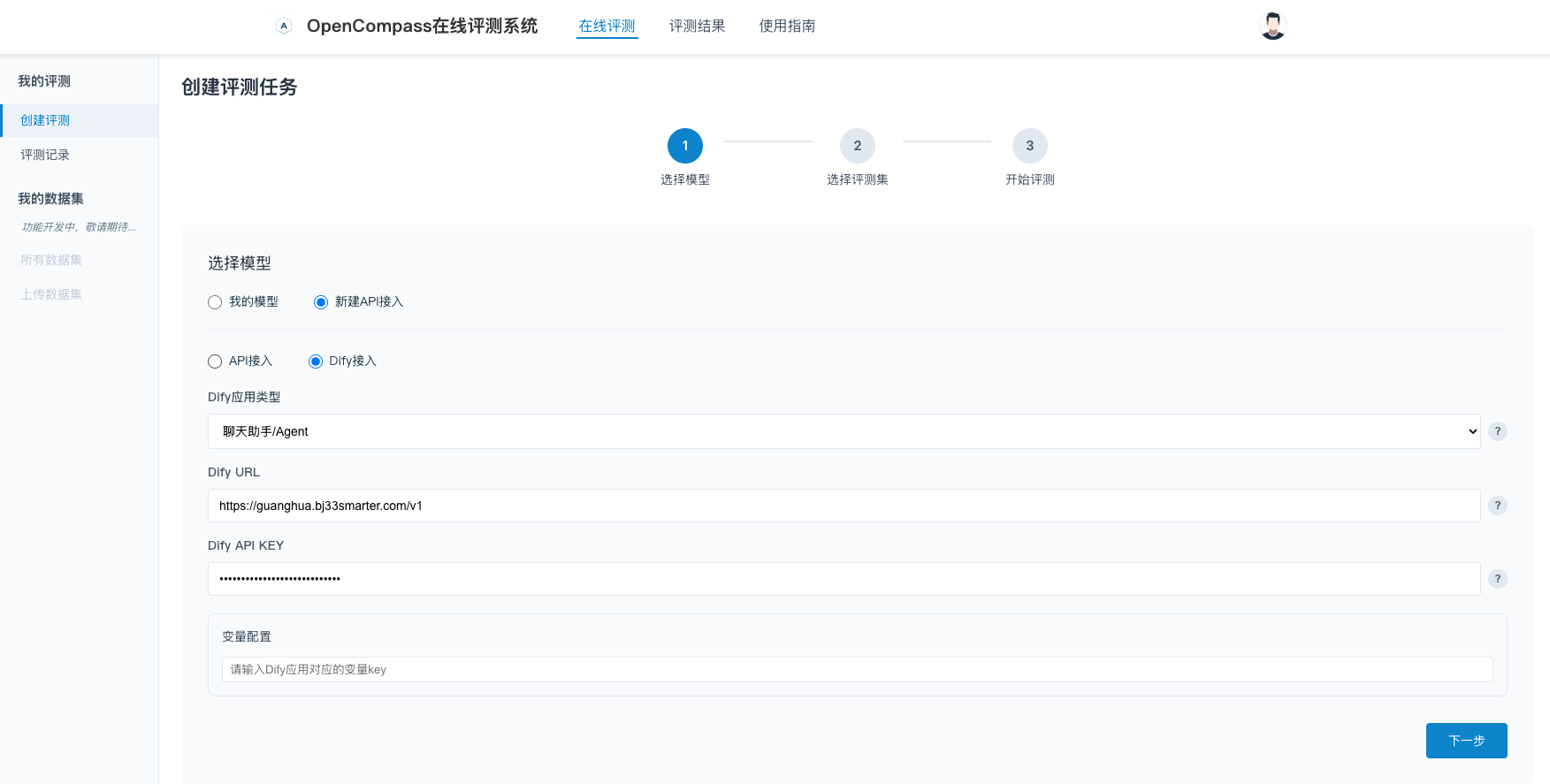
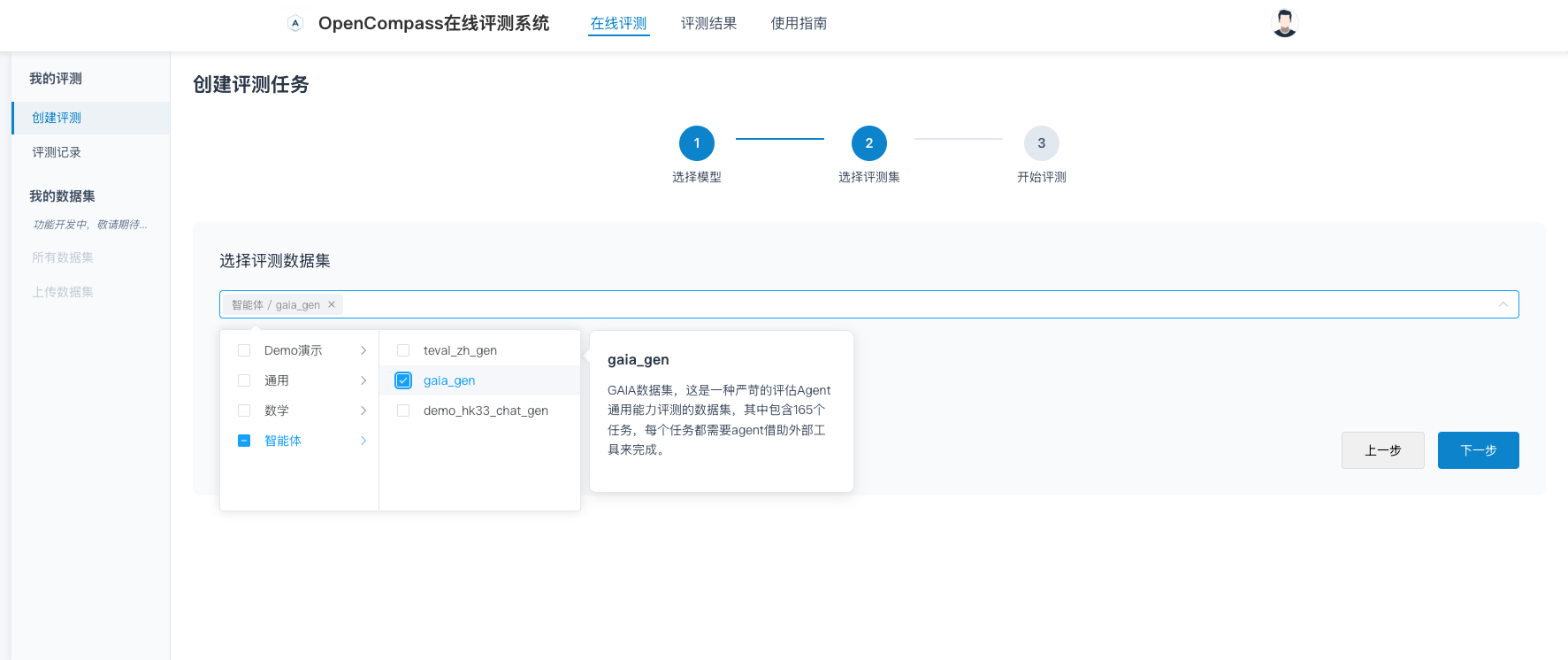
在ai-eval-system平台创建评测任务,配置相应的DIFY_URL和DIFY_API_KEY。
备注:
DIFY_URL和DIFY_API_KEY的获取方法,本章不再赘述,具体请参考Readme的使用说明。
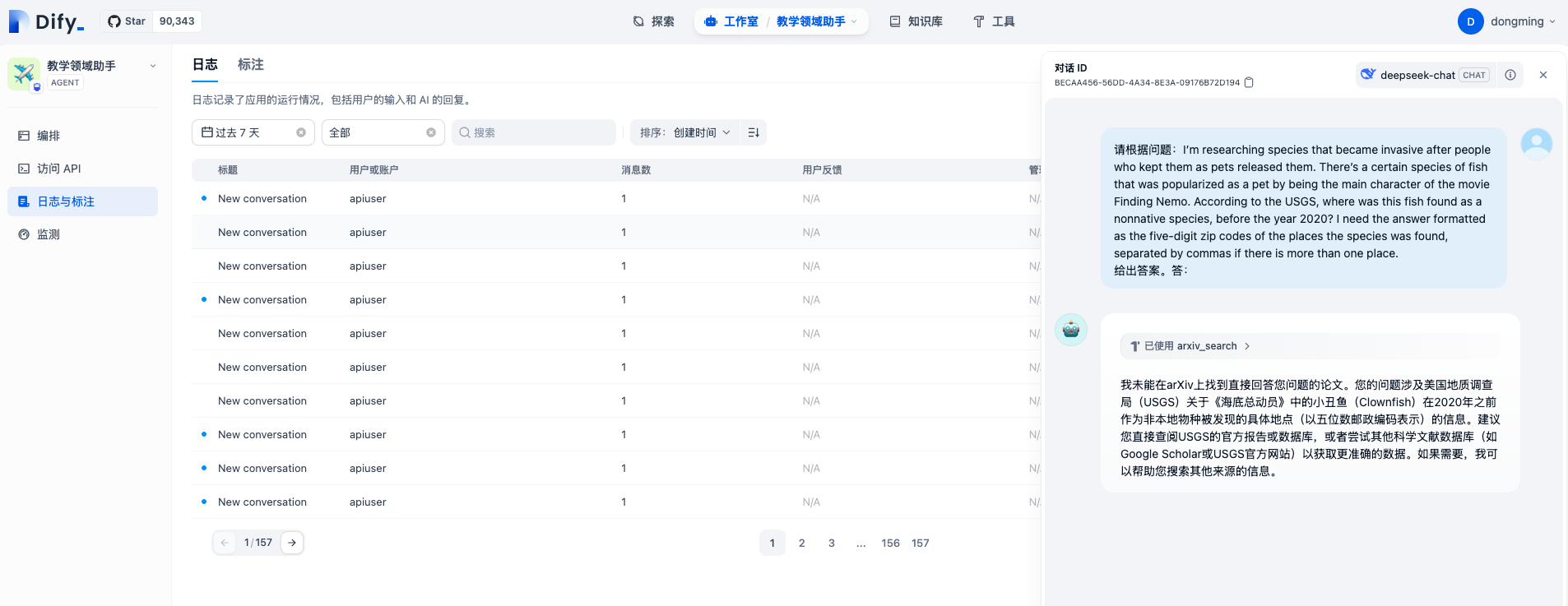
创建并运行评测后,在Dify平台对应Agent的日志与标注中可以看到实时日志情况。
总结
至此,我们已完成在opencompass中添加GAIA数据集,并集成至ai-eval-system中进行Dify平台应用评测。
但是如果数据集是带有附件的样例(如:3.3 样例3 和 3.4 样例4),目前还不支持,还需要继续调研实现。
参考资料
- arxiv:GAIA: a benchmark for General AI Assistants
- OpenCompass官网:添加新数据集
- Huggingface:GAIA 通用人工智能助手的基准数据集
附录
除GAIA之外,以下的数据集方案也常用于评估 Agent 能力:
- ToolQA:将现有数据集与人类注释(如 MMLU、MATH 等)结合起来,但存在训练过程中数据污染的风险,并且无法确保实际测试了工具的使用情况。
- APIBench:用于测试类似代理的系统调用其特定
API的能力,类似于API-Bank,后者提供一个API池以在评估过程中帮助大语言模型。 - AgentBench:提供了许多封闭环境,在这些环境中可以部署作为助手的大语言模型来回答用户查询(从 Unix shell 到网络购物 API)。但是由于这类评估依赖于封闭环境,它们可能评估的是助手对特定
API的学习使用程度,而不是基于现实世界交互的更普遍结果。 - OpenAGI:推出了一个平台和基准测试,由多个跨模态和能力的多步骤任务组成,与
GAIA更为接近。与 GAIA 的核心区别在于,他们的任务侧重于当前模型的能力,而不是未来的进步。


