
前言
在上一章《【课程总结】Day11(下):YOLO的入门使用》的学习中,我们通过YOLO实现了对图片的分类任务。本章的学习内容,将以目标检测为切入口,了解目标检测流程,包括:数据标准、模型训练以及模型预测。
图片分类vs目标检测
通过查看YOLO网站的task目录,我们可以看到:在计算机视觉领域中,常见的任务包括目标检测(detect)、语义分割(segment)、图像分类(classify)、人体姿态估计(pose)、以及有向边界框(Oriented Bounding Box,OBB)等。
- 图像分类(classify)
- 定义:图片分类是指根据图像的内容将其分为不同的类别或标签。
- 输入:
- 输入是一张图像,通常是固定大小的RGB图像。
- 输出:
- 输出是图像所属的类别或标签,通常以概率分布的形式(例如:[0.2, 0.5, 0.1, 0.2])表示每个类别的概率。
- 模型会输出每个类别的概率值,最终选择概率最高的类别作为预测结果。
- 目标检测(detect)
- 定义:目标检测是指在图像中检测和定位物体的任务,同时识别物体的类别。
- 输入:
- 输入是一张图像,同样是RGB图像。
- 输出:
- 输出是图像中检测到的所有物体的边界框和类别信息。
- 通常是一个包含物体位置、类别和置信度的列表。
目标检测的问题

通过上图可以看到,目标检测会遇到以下问题:
- 图片中包含多个动物,并不能简单的分类这张图是长颈鹿还是斑马;
- 图片中的动物所在的位置也是大小不同,位置不同;
- …
传统算法的解决思路
在利用深度学习做物体检测之前,传统算法对于目标检测通常分为3个阶段:区域选取、特征提取和体征分类。
- 区域选取:首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。

- 特征提取:在得到物体位置后,通常使用人工精心设计的提取器进行特征提取,如SIFT和HOG等。由于提取器包含的参数较少,并且人工设计的鲁棒性较低,因此特征提取的质量并不高。

- 特征分类:最后,对上一步得到的特征进行分类,通常使用如SVM、AdaBoost的分类器。
深度学习的解决思路
Anchor-based(基于锚框)
定义:Anchor-based 方法通过在图像上生成一组预定义的锚框(Anchor Boxes),然后利用这些锚框进行目标检测。
流程:
- 生成锚框:在图像上生成一组不同尺寸和长宽比的锚框。
- 特征提取:通过卷积神经网络提取图像特征(套种图片中的物体)。
- 预测:对每个锚框预测偏移量和目标类别信息。
- 筛选:通过非极大值抑制(NMS)等方法筛选出最终的检测结果。
核心思想:
- 死框+修正量
20×20的锚框

40×40的锚框

80×80的锚框

优点:
- 相对容易实现和训练。
- 可以处理多尺度目标和不同长宽比的目标。
缺点:
- 需要预定义大量的锚框,增加了计算复杂度和训练难度。
- 对于不规则形状的目标可能不够灵活。
Anchor-free(无锚框)
定义:Anchor-free 方法不依赖于预定义的锚框,而是直接预测目标的位置和类别信息。
流程:
- 中心点检测:首先,在图像上“撒豆子”(也称为“CenterNet”),即在图像的每个位置(像素)处预测目标中心点的存在概率。这些中心点通常表示可能存在目标的位置。
- 边界框预测:对于每个被预测为目标中心点的位置,模型会进一步预测目标的边界框(向上下左右生长,套住要预测的问题)。
- 后处理:通过后处理算法(如非极大值抑制)来筛选和优化检测结果,以获得最终的目标检测结果。
核心思想:
- 中心点 + 四个方向的生长

优点:
- 更加灵活,可以适应各种目标形状和尺度。
- 减少了预定义锚框带来的计算复杂度。
缺点:
- 相对 Anchor-based 方法,Anchor-free 方法可能需要更多的训练数据和更复杂的网络结构。
- 在处理小目标或密集目标时可能性能略逊于 Anchor-based 方法。
目前,目标检测基本使用anchor-free的方法。
目标检测的两种策略
目标检测具体的开展策略有两种:
| 方式 | 过程 | 代表 |
|---|---|---|
| 方式1 | 1. 先对输入图像进行切片。 2. 对每一片进行特征提取。 3. 对提取的特征进行分类和回归。 |
MTCNN |
| 方式2 | 1. 先对输入图像进行特征提取。 2. 对提取的特征进行切片。 3. 对每一片进行分类和回归。 |
YOLO |
两个例子
获取视频头内容进行目标检测
from ultralytics import YOLO
import cv2
# 加载YOLO模型
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture(0)
while cap.isOpened():
# 读取视频帧
ret, frame = cap.read()
if not ret:
break
# 使用YOLO模型检测物体
results = model(frame)
# 绘制预测结果
img = results[0].plot()
# 显示检测结果
cv2.imshow("frame", img)
if cv2.waitKey(1) == ord("q"):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()运行以上代码,YOLO可以将摄像头中的视频按帧逐帧检测物体。
读取图片进行目标检测
import cv2
from ultralytics import YOLO
import os
# 设置环境变量,解决OMP: Error #15: Initializing libiomp5.dylib, but found libiomp5.dylib already initialized的问题
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# 加载模型
model = YOLO("yolov8n.pt") # 使用预训练模型权重
# 读取图片
image = cv2.imread("animal.png")
# 预测
results = model(image)
result = results[0]
img = result.plot()
from matplotlib import pyplot as plt
# 对对象进行可视化,从RGB转换为BGR
plt.imshow(X=img[:, :, ::-1])
运行结果:

通过查看result的内容,可以得到:
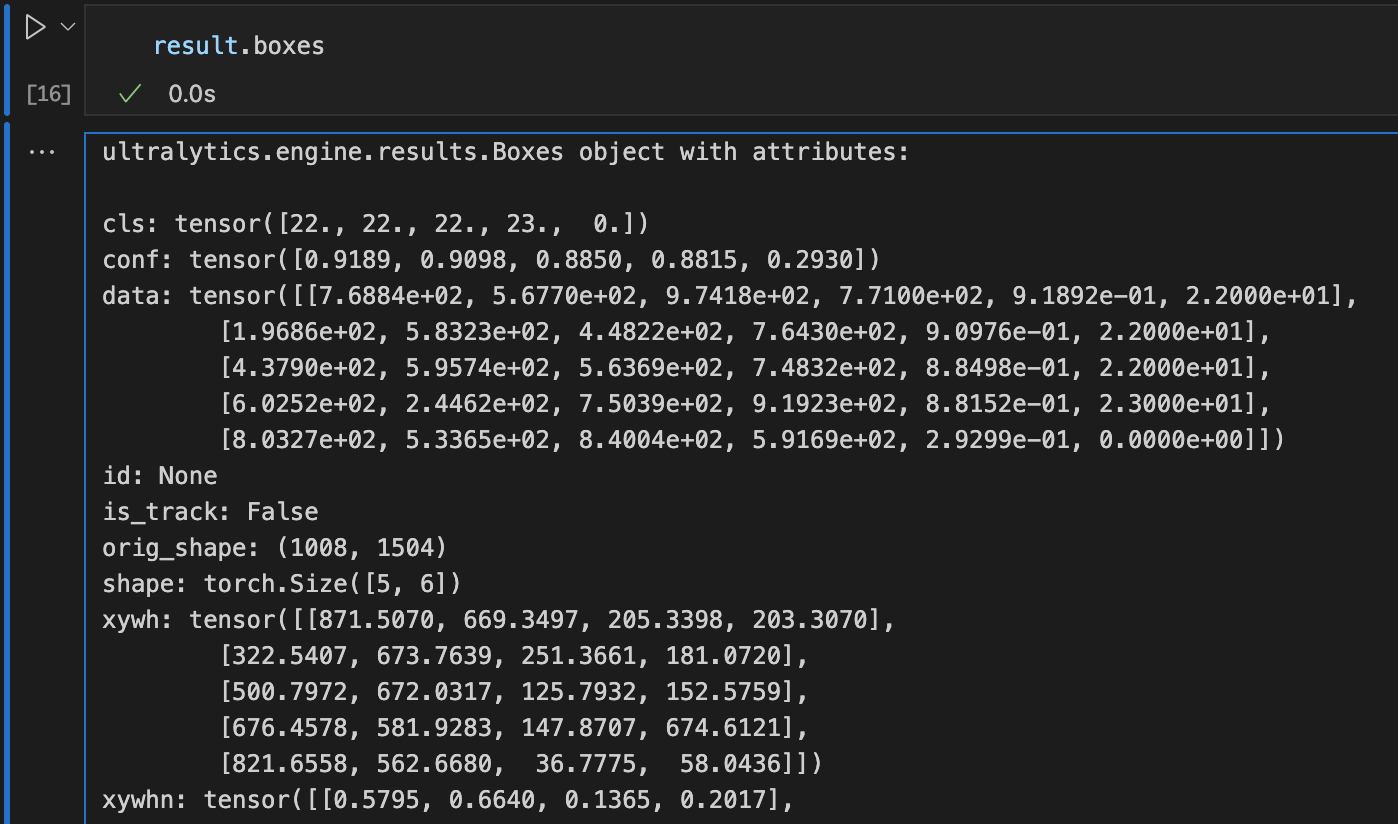
cls: 表示检测到的物体类别,是一个包含类别标识号的张量。
例如:上例分别为类别22、22、22、23和0。这意味着模型在图像中检测到了不同类别的物体。
conf: 表示置信度,即模型对检测结果的信心程度,是一个包含置信度值的张量。
例如:上例分别为[0.9189, 0.9098, 0.8850, 0.8815, 0.2930]表示模型对每个检测结果的置信度,置信度值越高,表示模型对该检测结果的信心程度越高。
data: 包含了检测结果的详细数据,如边界框坐标、置信度、类别等信息。
例如:第一行数据[7.6884e+02, 5.6770e+02, 9.7418e+02, 7.7100e+02, 9.1892e-01, 22]表示一个边界框的左上角和右下角坐标、置信度和类别。
shape: 结果张量的形状。
例如:[5, 6]表示这个张量是一个二维张量,上图中一共预测了5个目标检测结果。
xywh: 表示边界框的中心坐标、宽度和高度。
例如:[[871.5070, 669.3497, 205.3398, 203.3070], [322.5407, 673.7639, 251.3661, 181.0720], …]表示了每个检测结果的边界框信息。
xyxy: 表示边界框的左上角和右下角坐标。
例如:[[768.8371, 567.6962, 974.1769, 771.0032], [196.8576, 583.2280, 448.2238, 764.2999], …]表示了每个检测结果的边界框的左上角和右下角坐标。
自定义模型训练
以上的目标检测都是基于预先训练好的模型,如果想自主实现一个模型的训练以及目标检测,具体流程如下:
数据准备
为了更加接近实战,我计划在天池及飞桨社区找一份数据集进行目标检测的模型训练。
数据集地址:https://aistudio.baidu.com/datasetdetail/91732
数据集简述:
一个理想的智能零售结算系统应当能够精准地识别每一个商品,并且能够返回完整地购物清单及顾客应付的实际商品总价格。这是一份智能零售柜识别的图片数据集,非常适用于进行目标检测。

数据分析
由于该数据集采用VOC格式,其内容形式与YOLOv8的格式不同,所以我们需要做相关的处理。
VOC数据集目录格式:
我有一个VOC的目标检测数据集,其目录结构为:
VOC
|-Annotations
|-ori_000_XYGOC20200313162026456_1.xml
|-ori_000_XYGOC20200313162953549_1.xml
|-ori_001_11_0.xml
|-ori_001_4_0.xml
|-ori_001_6_0.xml
|-ori_t1_TEST20191101164758498_1.xml
|-ori_t1_TEST20191101164829232_1.xml
|-...
|-JPEGImages
|-ori_000_XYGOC20200313162026456_1.jpg
|-ori_000_XYGOC20200313162953549_1.jpg
|-ori_001_11_0.jpg
|-ori_001_4_0.jpg
|-ori_001_6_0.jpg
|-ori_t1_TEST20191101164758498_1.jpg
|-ori_t1_TEST20191101164829232_1.jpg
|-...
|-labels.txt
|-test_list.txt
|-train_list.txt
|-val_list.txt# labels.txt的内容格式为如下:
3+2-2
3jia2
aerbeisi
anmuxi
aoliao
asamu
baicha
baishikele
...
# train_list.txt内容格式如下:
JPEGImages/ori_XYGOC2021042115092870201IK-4_0.jpg Annotations/ori_XYGOC2021042115092870201IK-4_0.xml
JPEGImages/ori_XYGOC2021010413165585501IK-3_0.jpg Annotations/ori_XYGOC2021010413165585501IK-3_0.xmlYOLOv8数据集的目录结构
|-images
|-train
|-ori_000_XYGOC20200313162026456_1.jpg
...
|-val
|-ori_t1_TEST20191101164758498_1.jpg
...
|-lables
|-train
|-ori_000_XYGOC20200313162026456_1.txt
|-val
|-ori_t1_TEST20191101164829232_1.txt数据转换
1. 创建Dataset根目录
import os
# 创建Dataset根目录,同时按照YOLO的格式分别创建train和val目录
def create_directories(base_dir):
dirs = [
os.path.join(base_dir, "images/train"),
os.path.join(base_dir, "images/val"),
os.path.join(base_dir, "labels/train"),
os.path.join(base_dir, "labels/val")
]
for dir in dirs:
os.makedirs(dir, exist_ok=True)2. 读取classes类别
def read_classes(classes_file):
"""
从类别文件中读取类别名称,并返回类别名称与索引的映射字典。
参数:
- classes_file (str): 类别文件路径
返回:
- classes (dict): 类别名称与索引的映射字典
"""
classes = {}
with open(classes_file, "r") as f:
lines = f.readlines()
for index, line in enumerate(lines):
class_name = line.strip()
classes[index] = class_name
return classes
3. 读取xml文件并转换为yolo格式
def parse_xml(xml_path, classes_dict):
"""
解析XML文件,获取图像的宽度、高度以及对象的类别和边界框坐标。
参数:
- xml_path (str): XML文件路径
返回:
- width (int): 图像宽度
- height (int): 图像高度
- objects (list): 包含对象信息的列表,每个对象信息包括类别和边界框坐标
"""
tree = ET.parse(xml_path)
root = tree.getroot()
size = root.find("size")
width = int(size.find("width").text)
height = int(size.find("height").text)
objects = []
for obj in root.findall("object"):
name = obj.find("name").text
label_index = get_label_index(name, classes_dict)
bndbox = obj.find("bndbox")
xmin = int(bndbox.find("xmin").text)
ymin = int(bndbox.find("ymin").text)
xmax = int(bndbox.find("xmax").text)
ymax = int(bndbox.find("ymax").text)
objects.append({"label_index": label_index, "xmin": xmin, "ymin": ymin, "xmax": xmax, "ymax": ymax})
return width, height, objects
def convert_to_yolo_format(width, height, obj):
"""
将对象信息转换为适合YOLO格式的坐标。
参数:
- width (int): 图像宽度
- height (int): 图像高度
- obj (dict): 包含对象信息的字典,包括类别和边界框坐标
"""
x_center = (obj["xmin"] + obj["xmax"]) / 2 / width
y_center = (obj["ymin"] + obj["ymax"]) / 2 / height
w = (obj["xmax"] - obj["xmin"]) / width
h = (obj["ymax"] - obj["ymin"]) / height
return x_center, y_center, w, h
4. 将xml文件转换为txt文件
def write_txt_file(file_path, content):
"""
创建或写入内容到.txt文件
参数:
- file_path (str): 目标.txt文件路径
- content (str): 写入文件的内容
"""
try:
if not os.path.exists(file_path):
open(file_path, 'w').close() # 创建空的目标文件
with open(file_path, "a") as f:
f.write(content)
print(f"成功写入文件 {file_path}")
except Exception as e:
print(f"写入文件时发生异常: {e}")
def process_VOC_data(root_dir, train_list_file, images_dst, labels_dst, classes_dict):
"""
从VOC数据集中读取训练列表文件,解析xml文件并将图像复制到目标目录中,并将类别和bbox信息写入标签文件中。
参数:
- root_dir (str): VOC数据集的根目录
- train_list_file (str): 训练列表文件路径
- image_folder (str): 图像文件夹的相对路径
- images_dst (str): 图像目标目录
- labels_dst (str): 标签目标目录
"""
with open(train_list_file, "r") as f:
lines = f.readlines()
# 逐行读取列表文件
for line in lines:
line = line.strip()
image_path, xml_path = line.split(" ")
# 获取xml文件绝对路径
xml_path = os.path.join(root_dir, xml_path)
# 获取image文件绝对路径
image_path = os.path.join(root_dir, image_path)
width, height, objects = parse_xml(xml_path, classes_dict)
copy_image(image_path, images_dst)
for obj in objects:
label_name = os.path.splitext(os.path.basename(image_path))[0] + ".txt"
label_dst = os.path.join(labels_dst, label_name)
yolo_format = convert_to_yolo_format(width, height, obj)
content = f"{obj['label_index']} {yolo_format[0]} {yolo_format[1]} {yolo_format[2]} {yolo_format[3]}\n"
write_txt_file(label_dst, content)
5. 保存.txt文件到新目录下,同时拷贝图像
def copy_image(image_path, images_dst):
"""
将图像从原路径复制到目标路径。
参数:
- image_path (str): 原图像路径
- images_dst (str): 目标图像路径
"""
image_name = os.path.basename(image_path)
image_dst = os.path.join(images_dst, image_name)
if not os.path.exists(image_path):
print(f"原图像路径 '{image_path}' 未找到文件")
return
if os.path.exists(image_dst):
print(f"目标路径 '{image_dst}' 中已存在同名图像文件")
return
try:
shutil.copy(image_path, image_dst)
print(f"成功复制图像 {image_name} 到目标目录")
except Exception as e:
print(f"拷贝图像时发生异常: {e}")完整代码如下:
import xml.etree.ElementTree as ET
import shutil
import os
# 创建Dataset根目录,同时按照YOLO的格式分别创建train和val目录
def create_directories(base_dir):
dirs = [
os.path.join(base_dir, "images/train"),
os.path.join(base_dir, "images/val"),
os.path.join(base_dir, "labels/train"),
os.path.join(base_dir, "labels/val")
]
for dir in dirs:
os.makedirs(dir, exist_ok=True)
def get_label_index(name, classes_dict):
"""
根据类别名称从类别字典中获取对应的序号。
参数:
- name (str): 类别名称
- classes_dict (dict): 包含类别名称和对应序号的字典
返回:
- label_index (int): 类别名称对应的序号,如果不存在则返回-1
"""
label_index = -1
for key, value in classes_dict.items():
if value == name:
label_index = key
break
return label_index
def parse_xml(xml_path, classes_dict):
"""
解析XML文件,获取图像的宽度、高度以及对象的类别和边界框坐标。
参数:
- xml_path (str): XML文件路径
返回:
- width (int): 图像宽度
- height (int): 图像高度
- objects (list): 包含对象信息的列表,每个对象信息包括类别和边界框坐标
"""
tree = ET.parse(xml_path)
root = tree.getroot()
size = root.find("size")
width = int(size.find("width").text)
height = int(size.find("height").text)
objects = []
for obj in root.findall("object"):
name = obj.find("name").text
label_index = get_label_index(name, classes_dict)
bndbox = obj.find("bndbox")
xmin = int(bndbox.find("xmin").text)
ymin = int(bndbox.find("ymin").text)
xmax = int(bndbox.find("xmax").text)
ymax = int(bndbox.find("ymax").text)
objects.append({"label_index": label_index, "xmin": xmin, "ymin": ymin, "xmax": xmax, "ymax": ymax})
return width, height, objects
def convert_to_yolo_format(width, height, obj):
"""
将对象信息转换为适合YOLO格式的坐标。
参数:
- width (int): 图像宽度
- height (int): 图像高度
- obj (dict): 包含对象信息的字典,包括类别和边界框坐标
"""
x_center = (obj["xmin"] + obj["xmax"]) / 2 / width
y_center = (obj["ymin"] + obj["ymax"]) / 2 / height
w = (obj["xmax"] - obj["xmin"]) / width
h = (obj["ymax"] - obj["ymin"]) / height
return x_center, y_center, w, h
def copy_image(image_path, images_dst):
"""
将图像从原路径复制到目标路径。
参数:
- image_path (str): 原图像路径
- images_dst (str): 目标图像路径
"""
image_name = os.path.basename(image_path)
image_dst = os.path.join(images_dst, image_name)
if not os.path.exists(image_path):
print(f"原图像路径 '{image_path}' 未找到文件")
return
if os.path.exists(image_dst):
print(f"目标路径 '{image_dst}' 中已存在同名图像文件")
return
try:
shutil.copy(image_path, image_dst)
print(f"成功复制图像 {image_name} 到目标目录")
except Exception as e:
print(f"拷贝图像时发生异常: {e}")
def write_txt_file(file_path, content):
"""
创建或写入内容到.txt文件
参数:
- file_path (str): 目标.txt文件路径
- content (str): 写入文件的内容
"""
try:
if not os.path.exists(file_path):
open(file_path, 'w').close() # 创建空的目标文件
with open(file_path, "a") as f:
f.write(content)
print(f"成功写入文件 {file_path}")
except Exception as e:
print(f"写入文件时发生异常: {e}")
def process_VOC_data(root_dir, train_list_file, images_dst, labels_dst, classes_dict):
"""
从VOC数据集中读取训练列表文件,解析xml文件并将图像复制到目标目录中,并将类别和bbox信息写入标签文件中。
参数:
- root_dir (str): VOC数据集的根目录
- train_list_file (str): 训练列表文件路径
- image_folder (str): 图像文件夹的相对路径
- images_dst (str): 图像目标目录
- labels_dst (str): 标签目标目录
"""
with open(train_list_file, "r") as f:
lines = f.readlines()
# 逐行读取列表文件
for line in lines:
line = line.strip()
image_path, xml_path = line.split(" ")
# 获取xml文件绝对路径
xml_path = os.path.join(root_dir, xml_path)
# 获取image文件绝对路径
image_path = os.path.join(root_dir, image_path)
width, height, objects = parse_xml(xml_path, classes_dict)
copy_image(image_path, images_dst)
for obj in objects:
label_name = os.path.splitext(os.path.basename(image_path))[0] + ".txt"
label_dst = os.path.join(labels_dst, label_name)
yolo_format = convert_to_yolo_format(width, height, obj)
content = f"{obj['label_index']} {yolo_format[0]} {yolo_format[1]} {yolo_format[2]} {yolo_format[3]}\n"
write_txt_file(label_dst, content)
def read_classes(classes_file):
"""
从类别文件中读取类别名称,并返回类别名称与索引的映射字典。
参数:
- classes_file (str): 类别文件路径
返回:
- classes (dict): 类别名称与索引的映射字典
"""
classes = {}
with open(classes_file, "r") as f:
lines = f.readlines()
for index, line in enumerate(lines):
class_name = line.strip()
classes[index] = class_name
return classes
def generate_coco8_yaml_content(dataset_root, train_images, val_images, classes):
"""
生成类似COCO8数据集配置文件的内容
参数:
- dataset_root (str): 数据集根目录路径
- train_images (str): 训练图像相对于根目录的路径
- val_images (str): 验证图像相对于根目录的路径
- classes (dict): 类别名称与索引的映射字典
返回:
- content (str): COCO8数据集配置文件内容
"""
content = f"path: ../datasets/{dataset_root} # dataset root dir\n"
content += f"train: {train_images} # train images (relative to 'path') 4 images\n"
content += f"val: {val_images} # val images (relative to 'path') 4 images\n"
content += "test: # test images (optional)\n\n"
content += "# Classes\n"
content += "names:\n"
for index, class_name in classes.items():
content += f" {index}: {class_name}\n"
return content
def write_yaml_file(file_path, content):
"""
创建或写入内容到.yaml文件
参数:
- file_path (str): 目标.yaml文件路径
- content (str): 写入文件的内容
"""
try:
if not os.path.exists(file_path):
open(file_path, 'w').close() # 创建空的目标文件
with open(file_path, "w") as f:
f.write(content)
print(f"成功写入文件 {file_path}")
except Exception as e:
print(f"写入文件时发生异常: {e}")
if __name__ == "__main__":
# VOC数据集根目录
root_dir = "VOC"
train_list_file = os.path.join(root_dir, "train_list.txt")
test_list_file = os.path.join(root_dir, "val_list.txt")
classes_file = "VOC/labels.txt"
# 设置转换后YOLO的图像和标签目录
dataset_root = "cabinet"
train_images = "images/train"
train_labels = "labels/train"
val_images = "images/val"
val_labels = "labels/val"
yaml_file_name = "cabinet.yaml"
images_dst_train = os.path.join(dataset_root, train_images)
labels_dst_train = os.path.join(dataset_root, train_labels)
images_dst_test = os.path.join(dataset_root, val_images)
labels_dst_test = os.path.join(dataset_root, val_labels)
yaml_file = os.path.join(dataset_root, yaml_file_name)
# 创建YOLO数据集目录
create_directories(dataset_root)
# 读取类别文件
classes = read_classes(classes_file)
# 转换训练数据集
process_VOC_data(root_dir, train_list_file, images_dst_train, labels_dst_train, classes)
# 转换测试数据集
process_VOC_data(root_dir, test_list_file, images_dst_test, labels_dst_test, classes)
# 生成COCO8.yaml文件
content = generate_coco8_yaml_content(dataset_root, train_images, val_images, classes)
write_yaml_file(yaml_file, content)以上转换后的数据,我也打包上传到网盘,可直接使用。
网盘地址:https://pan.baidu.com/s/1DyoK7r_74OzrRdoogrtTKw?pwd=q4ww
模型训练
第一步:拷贝数据到YOLO的datasets目录下
第二步:拷贝cabinet.yaml文件到YOLO的cfg\datasets目录下
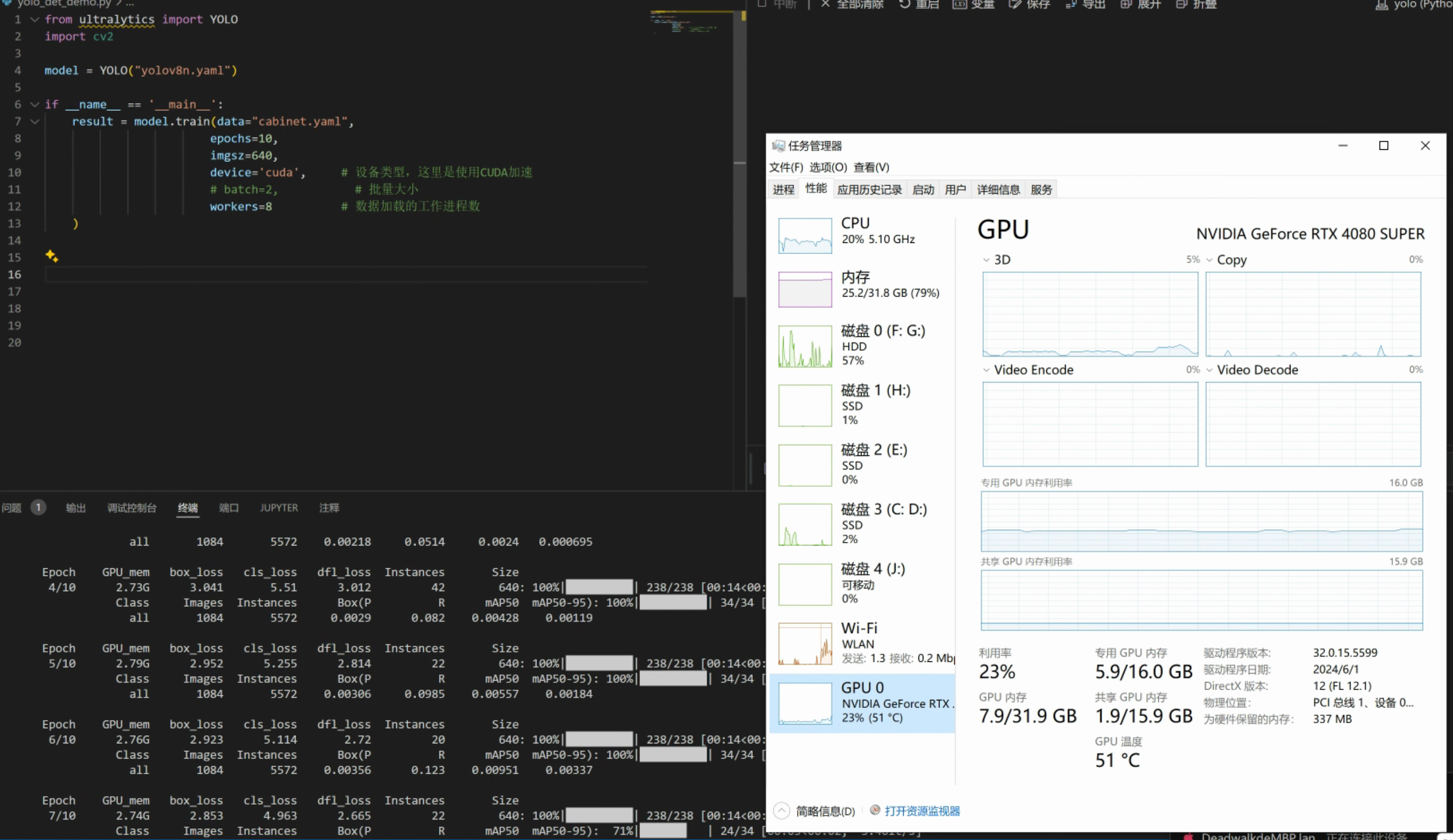
第三步:使用命令行训练模型
from ultralytics import YOLO
import cv2
model = YOLO("yolov8n.yaml")
if __name__ == '__main__':
result = model.train(data="cabinet.yaml",
epochs=10,
imgsz=640,
device='cuda', # 设备类型,这里是使用CUDA加速
# batch=2, # 批量大小
workers=8 # 数据加载的工作进程数
)训练时显存占用情况
训练结果:
训练完毕后,在run\train*目录下生成对应的训练结果
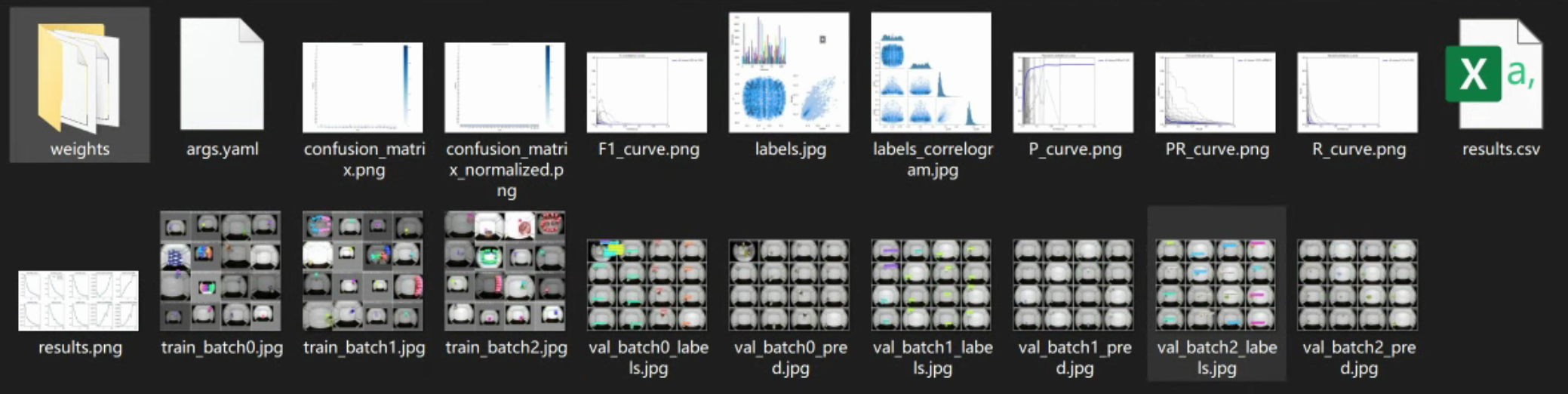
查看其中的验证集显示内容,看起来结果是正常的

由于时间原因,本次就没有开发相关的前端页面来进行模型加载和图片识别,但是可以想象:如果模型加载后同时开启智能柜的摄像头,那么就可以实时对售卖柜内的商品进行目标检测。
附录
labelimg进行数据标注
简介
LabelImg是一个用于图像标注的开源工具,它可以帮助用户快速而准确地为图像创建标注框,并生成相应的标注文件。
使用步骤
安装并打开labelimg
第一步:在conda创建新环境labelimg,指令如下:
conda create -n labelimg python=3.9第二步:激活lalelimg环境,指令如下:
conda activate labelimg第三步:在此环境下安装labelimg,指令可如下:
pip install labelimg第四步:命令行下打开
labelimg
内容小结
- 目标检测理论
- 在计算机视觉领域中,常见的任务包括目标检测(detect)、图像分类(classify)
- 目标检测输入是一张图像,输出是图像中检测到的所有物体的边界框和类别信息
- 目标检测在深度学习下有了新的发展,有
Anchor-based(基于锚框)和Anchor-free(无锚框)两种解决思路 - Anchor-based的核心思想是:
死框+修正量,Anchor-free的核心思想是:中心点 + 四个方向的生长 - 相对 Anchor-based 方法,Anchor-free 方法可能需要更多的训练数据和更复杂的网络结构。
- 目标检测使用
- 使用YOLO进行目标检测后,结果保存在results中,results中有
cls(物体类别)、conf(表示置信度)、data(详细数据,如边界框坐标等) - 如果要自定义数据集训练,可以按照coco8的目录结构和yaml文件准备数据
- 训练数据集可以通过labelimg来进行标注,使用前需要建立独立的虚拟环境
- 如果从网上下载的训练集是VOC格式,需要对其进行转换后训练®
- 使用YOLO进行目标检测后,结果保存在results中,results中有
参考资料
欢迎关注公众号以获得最新的文章和新闻



