文章来源于互联网:连OpenAI都推不动Scaling Law了?MIT把「测试时训练」系统研究了一遍,发现还有路

-
论文标题:The Surprising Effectiveness of Test-Time Training for Abstract Reasoning
-
论文链接:https://ekinakyurek.github.io/papers/ttt.pdf
-
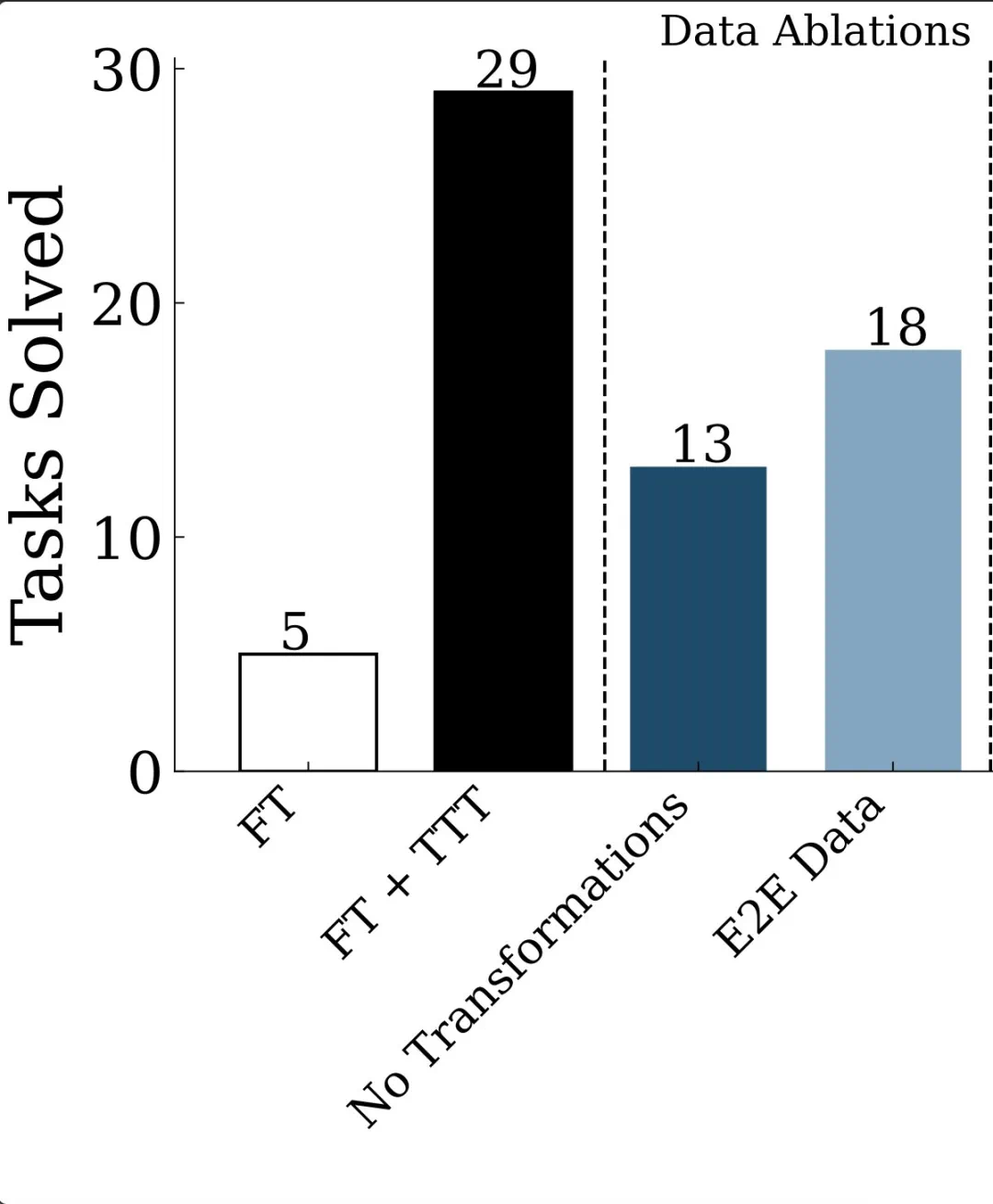
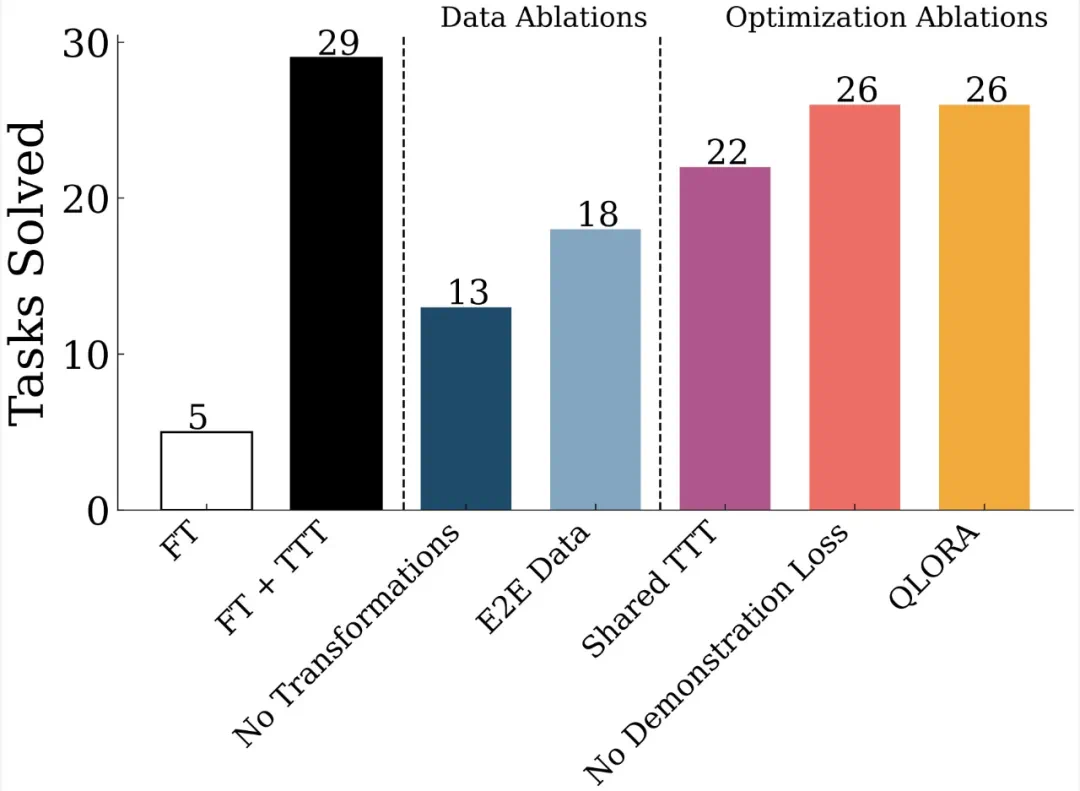
在与测试时类似的合成任务上进行初始微调;
-
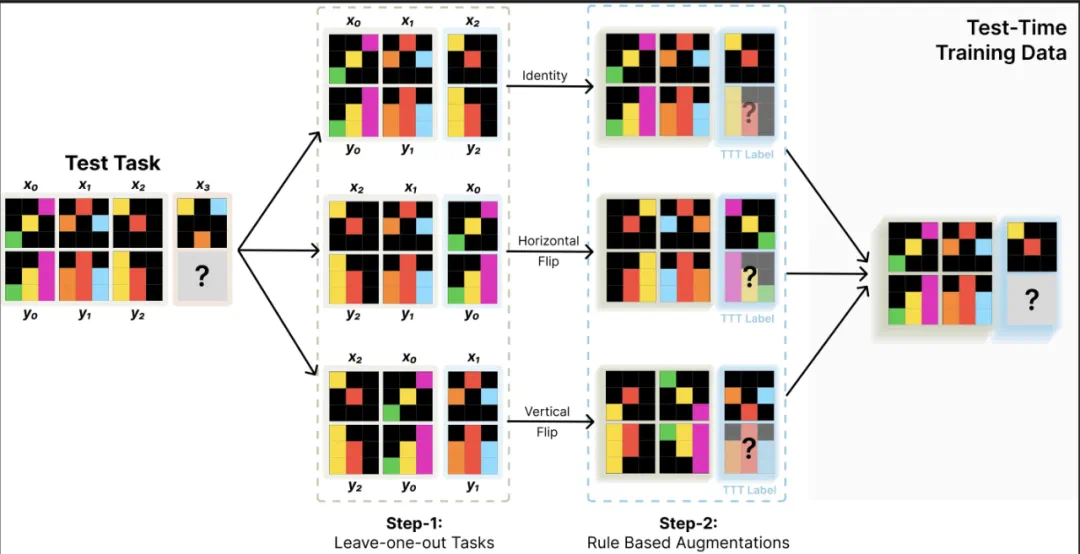
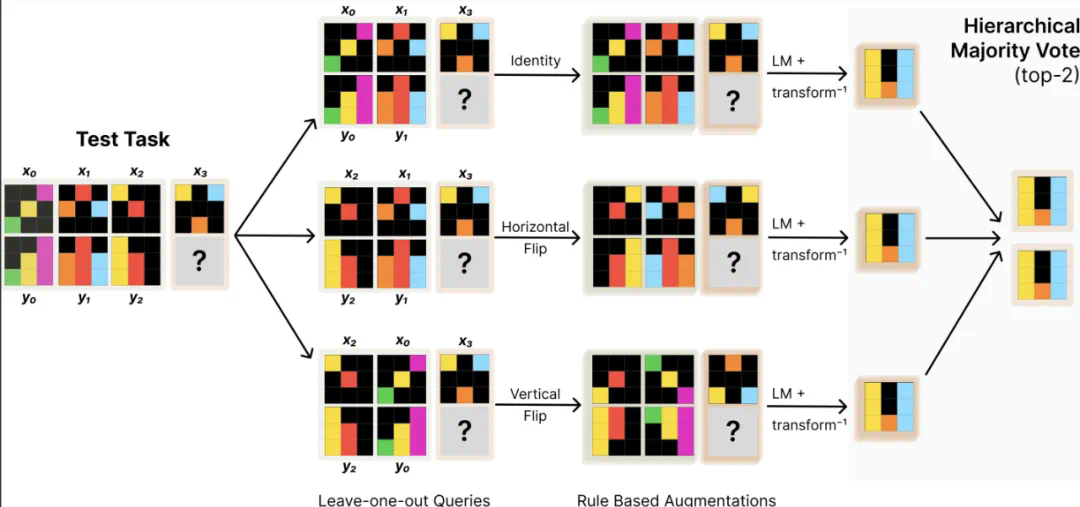
用于构建测试时数据集的增强型 leave-1-out 任务生成策略;
-
训练适用于每个实例的适应器;
-
可逆变换下的自我一致性(self-consistency)方法。
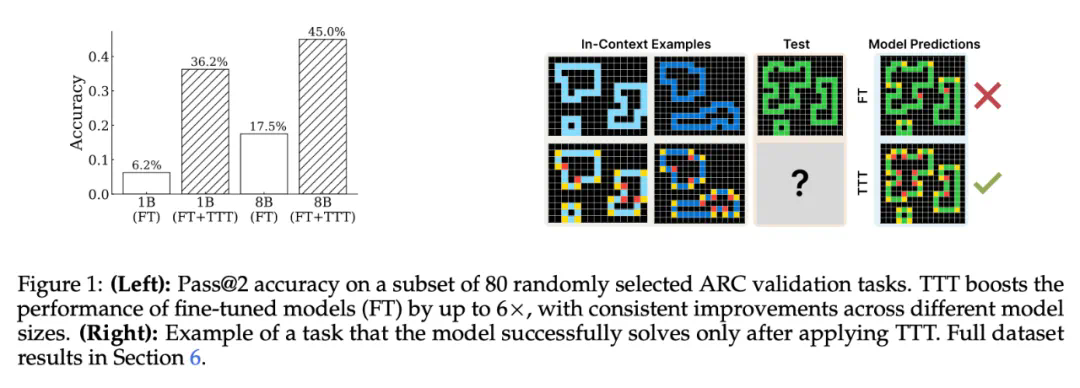
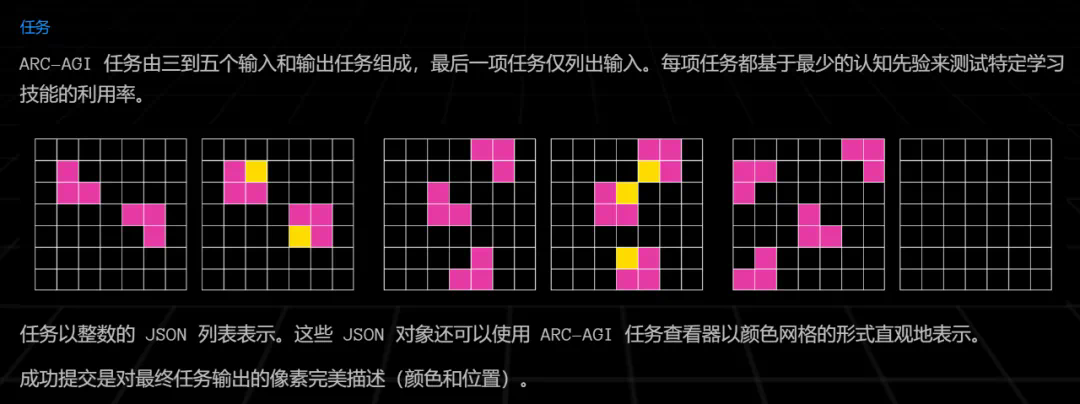 ARC 推理任务示例。可以看到,这是一组类似于智力测试的问题,模型需要找到图形变换的规则,以推导最后的输出结果。
ARC 推理任务示例。可以看到,这是一组类似于智力测试的问题,模型需要找到图形变换的规则,以推导最后的输出结果。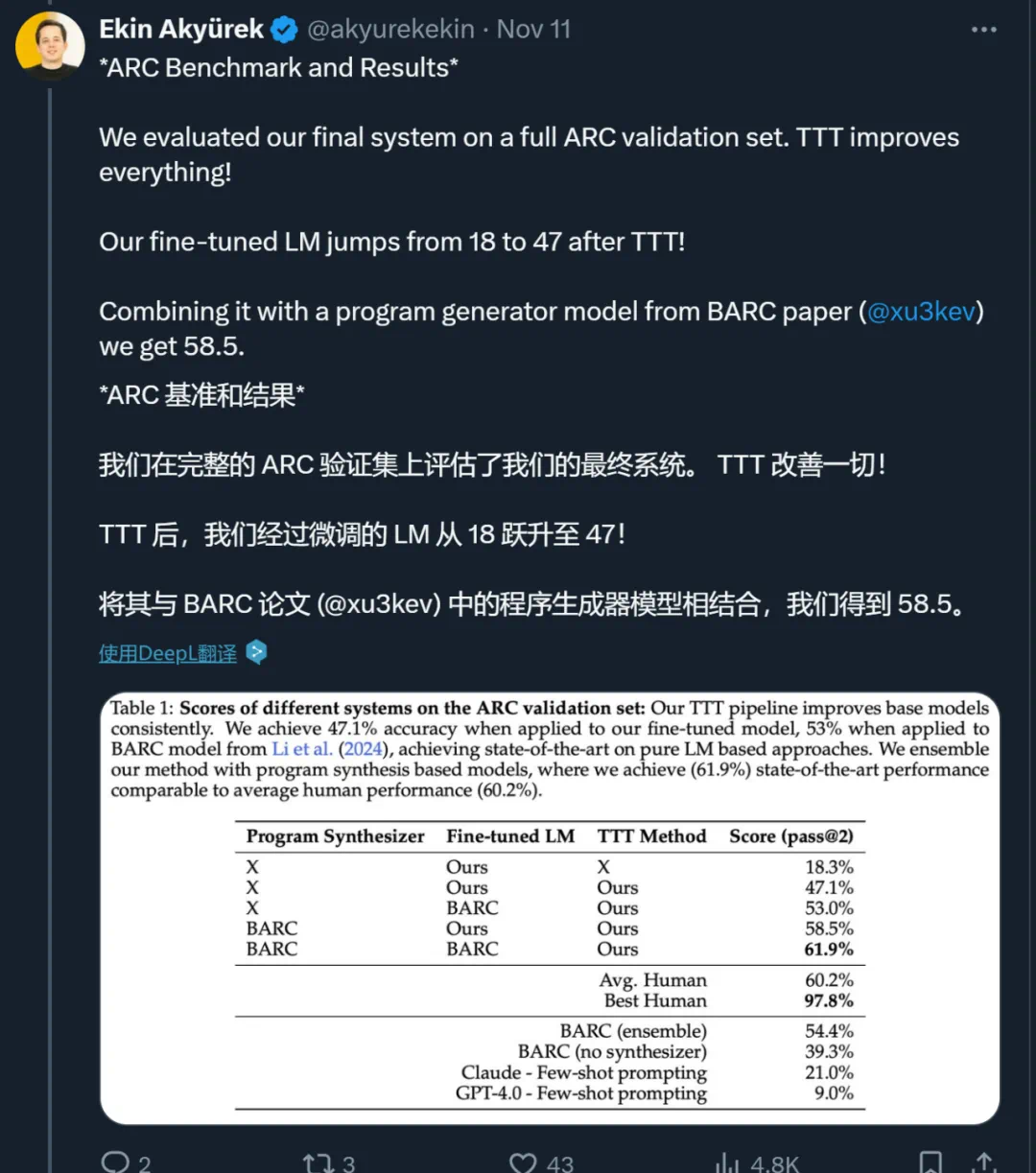



 表示一个任务,其中
表示一个任务,其中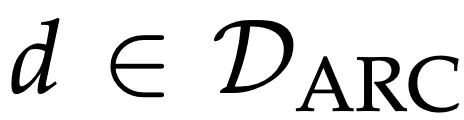 ,即 ARC 任务的集合。ARC 数据集的原始训练集和验证集各由 400 个任务组成。成功标准要求对所有测试输出结果进行精确匹配(如果没有给出部分分数)。
,即 ARC 任务的集合。ARC 数据集的原始训练集和验证集各由 400 个任务组成。成功标准要求对所有测试输出结果进行精确匹配(如果没有给出部分分数)。-
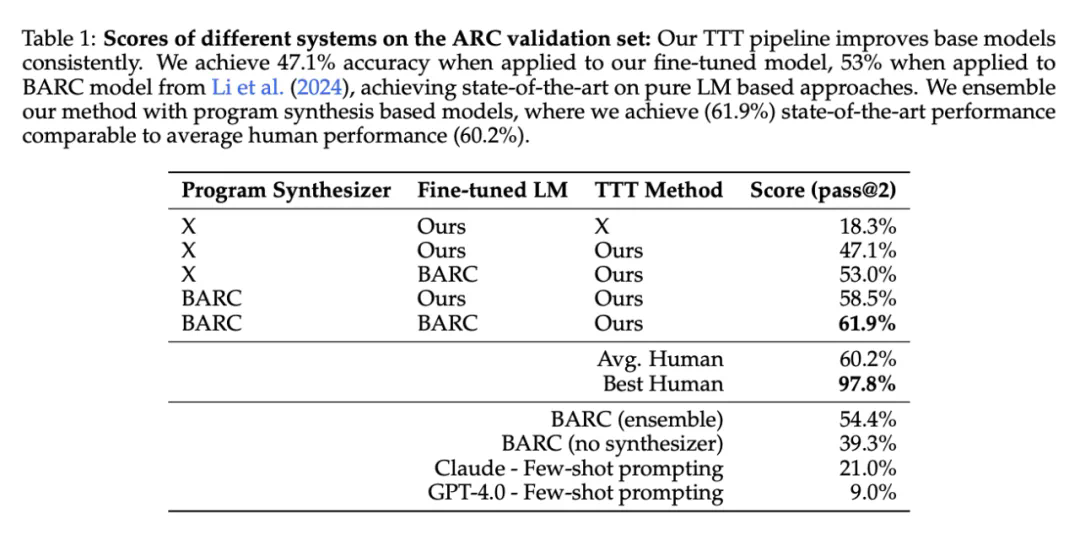
将本文的 TTT pipeline 与神经模型与 BARC 合成器相结合,准确率提高到 58.5%。
-
将本文的 TTT pipeline 与 BARC 神经模型和合成器相结合,准确率提高到 61.9%。