在时间序列预测研究中,一个耐人寻味的现象长期存在:
一方面,模型结构不断演进,从循环网络到 Transformer,再到频域与混合结构;另一方面,几乎所有方法在训练阶段依赖同一类损失函数,即以均方误差(MSE)为代表的点对点误差。
这使得时间序列预测在方法论层面呈现出一种隐性的停滞,即研究重心持续向模型表达能力倾斜,而对损失函数所隐含的统计假设缺乏系统反思。
点对点误差的核心假设在于,标签序列中的各时间步可被视为给定历史条件下相互独立的预测对象。然而,这一假设与时间序列数据的生成机制之间始终存在张力。
真实世界中的时间序列由随机过程演化而来,不同时间点之间存在显著的相关关系。将多步预测问题拆解为一组独立的回归任务,不可避免地为损失函数引入了结构性偏差,使模型难以学习标签序列的整体形态、相关结构以及条件依赖关系。
针对这一问题,北京大学林宙辰团队深入剖析了此类结构性偏差的成因。在此基础上,团队提出了 DistDF:一种通过联合分布对齐训练预测模型的损失函数。DistDF 的提出不仅为时间序列预测提供了一种新的损失函数设计思路,也在更一般的意义上,对序列建模中“应当优化什么”这一长期被默认的问题给出了新的回答。

论文地址:https://arxiv.org/pdf/2510.24574v1
当独立性假设被实验证伪之后
当前时间序列预测领域的主流方法普遍采用逐时间点的均方误差(MSE)作为损失函数:
$$mathcal{L}_{text{MSE}} = |mathbf{y} – g_theta(mathbf{x})|^2=sum_{t=1}^mathrm{T}left(y_t-g_{theta,t}(mathbf{x})right)$$
$$mathcal{L}_mathrm{MSE}$$隐式地做了独立性假设:在给定历史序列的条件下,标签序列各时间点的观测相互独立。然而,真实时间序列存在显著的标签自相关:标签序列各时间点的观测往往存在显著的相关性。因此,$$mathcal{L}_mathrm{MSE}$$的独立性假设与时间序列数据的生成机制相悖,导致其作为损失函数是有偏的(具体见定理1)。
[定理1] 考虑单变量标签序列$$mathbf{y}inmathbb{R}^{Ttimes 1}$$,其条件自相关矩阵为$$mathbf{Sigma}_mathbf{x}inmathbb{R}^{Ttimes T}$$,则标签序列的实用负对数似然可表示为:$$mathcal{L}_mathrm{NLL} = left|mathbf{y}-hat{mathbf{y}}right|_{mathbf{Sigma}^{-1}}^2$$。显然,仅当$$mathbf{Sigma}_mathbf{x}$$是单位阵,即标签自相关不存在时,才有$$mathcal{L}_mathrm{NLL} = mathcal{L}_mathrm{MSE}$$。
研究团队通过实证分析验证了这一矛盾:在给定历史序列$$mathbf{x}$$的条件下,标签序列仍呈现显著的条件相关结构,从而在实证意义上证伪了独立性假设。实验进一步表明,即使采用频域变换或主成分分解等标签变换方法,变换后的标签序列依然存在残余相关性;因此,在变换后的标签应用均方误差作为损失函数仍会导致结构性偏差。

DistDF:基于分布对齐的时间序列损失函数
为规避传统方法中的独立性假设,DistDF 提出直接对齐预测序列的条件分布$$mathbb{P}(hat{mathbf{y}}|mathbf{x})$$与真实标签的条件分布$$mathbb{P}(mathbf{y}|mathbf{x})$$。直观上,该目标可通过最小化两个条件分布间的距离$$mathrm{Disc}(mathbb{P}(hat{mathbf{y}}|mathbf{x}),mathbb{P}(mathbf{y}|mathbf{x}))$$来实现。
然而,直接将其作为损失函数面临严重的样本稀缺问题。对于给定的历史序列$$mathbf{x}$$,时间序列数据集通常仅包含唯一的标签序列$$mathbf{y}$$,模型也仅产生单一预测$$hat{mathbf{y}}$$。这种“单样本”情形导致直接估计条件分布距离$$mathrm{Disc}(mathbb{P}(hat{mathbf{y}}|mathbf{x}),mathbb{P}(mathbf{y}|mathbf{x}))$$在统计上不可靠。
为解决这一难题,我们利用概率恒等式$$mathbb{P}(mathbf{y},mathbf{x}) = mathbb{P}(mathbf{y}|mathbf{x})mathbb{P}(mathbf{x})$$。因为边缘分布$$mathbb{P}(mathbf{x})$$是共享的,若联合分布对齐,则条件分布必然对齐。基于此,我们将条件分布匹配问题转化为联合分布匹配问题。
进一步结合最优传输理论,本文证明了联合分布的 Wasserstein 距离构成了条件分布 Wasserstein 距离期望的上界:
$$int mathcal{W}_pleft(mathbb{P}(mathbf{y}|mathbf{x}), mathbb{P}(hat{mathbf{y}}|mathbf{x})right) dmathbb{P}(mathbf{x}) leq mathcal{W}_p left(mathbb{P}(mathbf{y},mathbf{x}), mathbb{P}(hat{mathbf{y}},mathbf{x})right)$$
因此,通过最小化历史-预测联合分布$$mathbb{P}(hat{mathbf{y}},mathbf{x})$$与历史-标签联合分布$$mathbb{P}(mathbf{y},mathbf{x})$$之间的 Wasserstein 距离,可有效实现条件分布对齐,进一步实现预测模型的无偏训练。同时,这一转换允许利用整个数据集的样本来估计联合分布距离,显著提升了分布距离估计的可靠性。雷峰网(公众号:雷峰网)
DistDF 的实现流程如下:
首先,构造联合序列:$$mathbf{z}=[mathbf{y},mathbf{x}]$$和$$hat{mathbf{z}}=[hat{mathbf{y}},mathbf{x}]$$;
接着,计算两个联合序列之间的Wasserstein距离:$$mathcal{L}_mathrm{dist}=mathcal{W}_p left(mathbb{P}(mathbf{z}), mathbb{P}(hat{mathbf{z}})right)$$,
最后,与 MSE 损失加权融合:$$mathcal{L}_{alpha} = alpha cdot mathcal{L}_mathrm{dist} + (1-alpha) cdot mathcal{L}_mathrm{MSE}$$
DistDF 作为模型无关的损失函数,可适配各类预测模型架构。
在大量实验中,一致验证优势
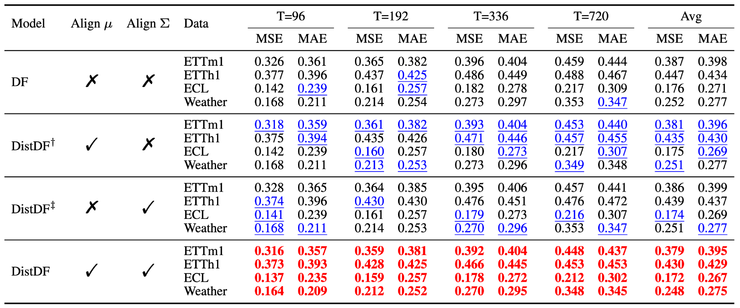
论文首先将DistDF与现有损失函数进行了比较,包括通过标签变换削弱标签相关性的 FreDF 和 Time-o1。结果表明,这些方法虽然减少了似然估计的偏差并提升了性能,但残差偏差仍然存在,因此性能仍有改进空间。而DistDF通过最小化条件分布之间的距离,实现了预测模型的无偏训练,取得了最佳的预测性能。

其次,论文通过消融实验对两个关键因素进行了验证;分别考察在DF的基础上,仅对齐均值、仅对齐协方差以及同时对齐二者的情形。结果表明,两种因素单独对齐时均能带来性能提升,而二者同时对齐时效果最为显著。雷峰网
接着,论文也对模型输出的预测序列进行了可视化分析。结果表明,采用 DistDF 训练的模型能够较好地跟随序列中的突发变化,使得预测序列在整体形态上更加接近真实数据。这进一步表明,DistDF 的作用不仅体现在降低数值误差上,更重要的是在训练过程中引导模型学习到了真实未来时间序列的整体分布形态。
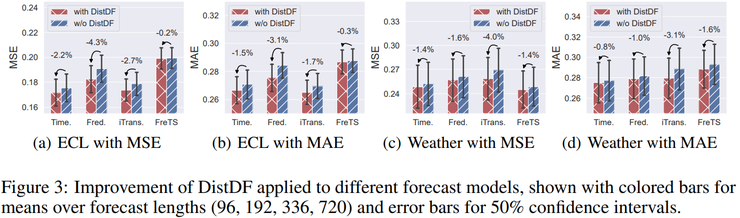
最后,论文对DistDF与不同预测模型的兼容性进行了验证。结果表明,无论模型本身的复杂度和建模方式如何,引入 DistDF 训练策略后,模型预测性能几乎都能够获得进一步提升。这一结果表明,DistDF 的作用并非弥补模型结构本身的不足,而是提供了更好的训练信号。
「多任务学习」需要分布对齐
整体来看,这项研究重新审视了多任务学习场景中的损失函数设计。研究团队强调:多任务学习的核心目标不应局限于对 T个标签的逐点建模,而应转向对一个在任务维度上具有内在相关结构的随机过程进行整体建模。
在这一视角下,传统损失函数(如MSE)隐含了“给定输入条件下各任务标签相互独立”的假设,从而将一个高维、相关的随机过程建模任务退化为一组彼此独立的标量回归任务。因该假设忽略了标签序列的内生结构,这些损失函数往往是有偏的。
DistDF 通过将预测序列与真实标签建模为概率分布,实现对任务维度上相关结构的整体建模。通过优化基于分布对齐的损失函数,模型能够显式学习标签序列的整体形态、相关结构以及条件依赖关系。
进一步看,该研究揭示的问题具有广泛的普适性。只要学习任务的输出构成具有显著相关性的序列(如语音、图像、文本或用户行为),若仍沿用基于独立性假设的损失函数(如 MSE),则必然会引入结构性偏差。因此,DistDF 所倡导的联合分布对齐思想,不仅适用于时间序列预测,也同样适用于语音合成、轨迹预测等任务。它并非针对时间序列任务的特定技巧,而是为多任务学习问题提供了一种更为通用的损失函数构造范式。
作者信息
论文第一作者王浩,现为浙江大学控制学院博士研究生,研究方向聚焦于因果推断、多任务学习技术及其在大语言模型中的应用。2022 年- 2023 年,他曾在蚂蚁金服、微软亚洲研究院科研实习,从事推荐系统理论研究。2025 年起,他在小红书参加 RedStar 实习项目,进行大语言模型、可信奖励模型领域的研究工作。

论文通讯作者林宙辰,现任北京大学智能学院、通用人工智能全国重点实验室教授。他的研究领域包括机器学习和数值优化。他已发表论文360余篇,谷歌学术引用超过42,000次。他是IAPR、IEEE、AAIA、CCF和CSIG会士,多次担任CVPR、NeurIPS、ICML等会议的Senior Area Chair,现任ICML Board Member。

参考链接:https://zhouchenlin.github.io/
本工作得到了北京市科学技术委员会、中关村科技园区管理委员会的大力支持,在此深表感谢。
雷峰网原创文章,未经授权禁止转载。详情见转载须知。

文章来源于互联网:北大林宙辰团队:从最优传输角度训练时序预测模型 丨ICLR 2026
