文章来源于互联网:Scaling Laws终结,量化无用,AI大佬都在审视这篇论文
研究表明,你训练的 token 越多,你需要的精度就越高。
最近几天,AI 社区都在讨论同一篇论文。
UCSD 助理教授 Dan Fu 说它指明了大模型量化的方向。

CMU 教授 Tim Dettmers 则直接说:它是很长一段时间以来最重要的一篇论文。OpenAI 创始成员、特斯拉前 AI 高级总监 Andrej Karpathy 也转发了他的帖子。
-
扩大数据中心规模:未来约 2 年这仍然是可以做到的事;
-
通过动态扩展:路由到更小的专门模型或大 / 小模型上;
-
知识的提炼:这条路线与其他技术不同,并且可能具有不同的特性。

-
论文标题:Scaling Laws for Precision
-
论文链接:https://arxiv.org/abs/2411.04330
-
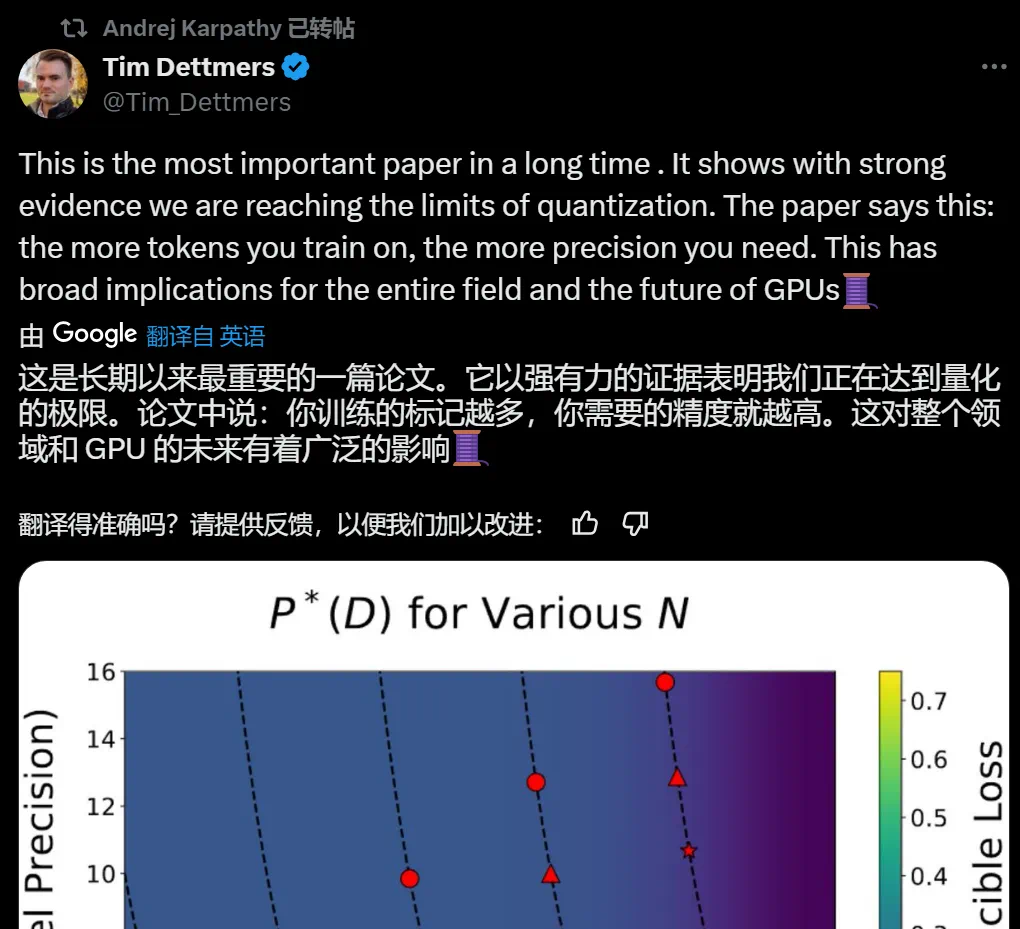
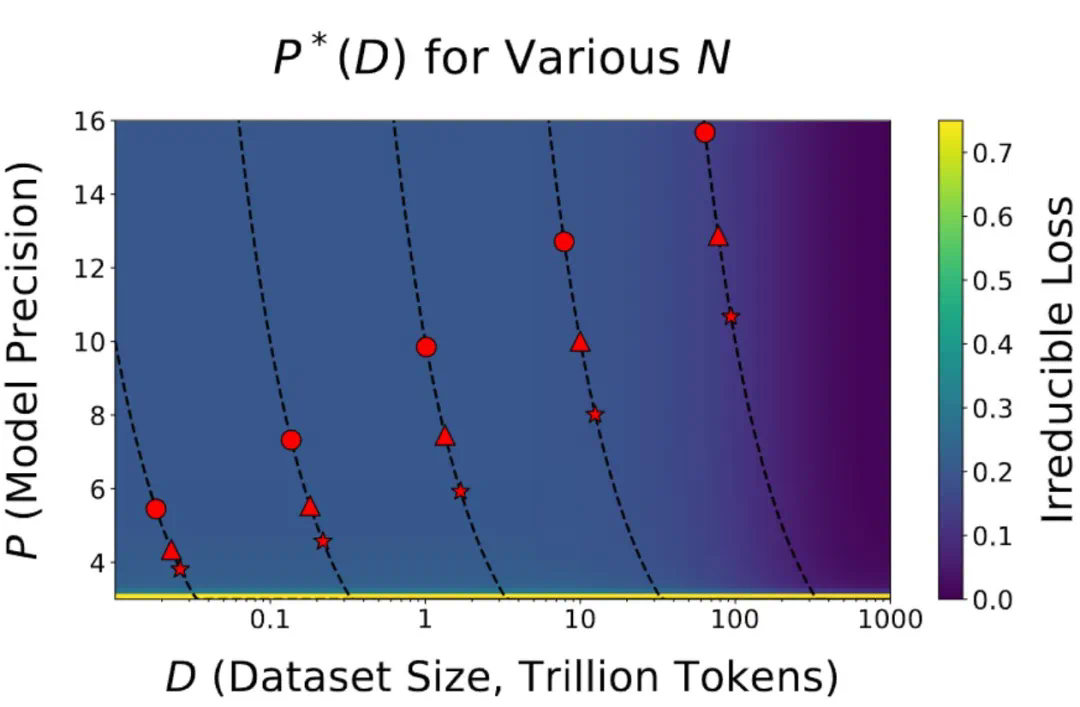
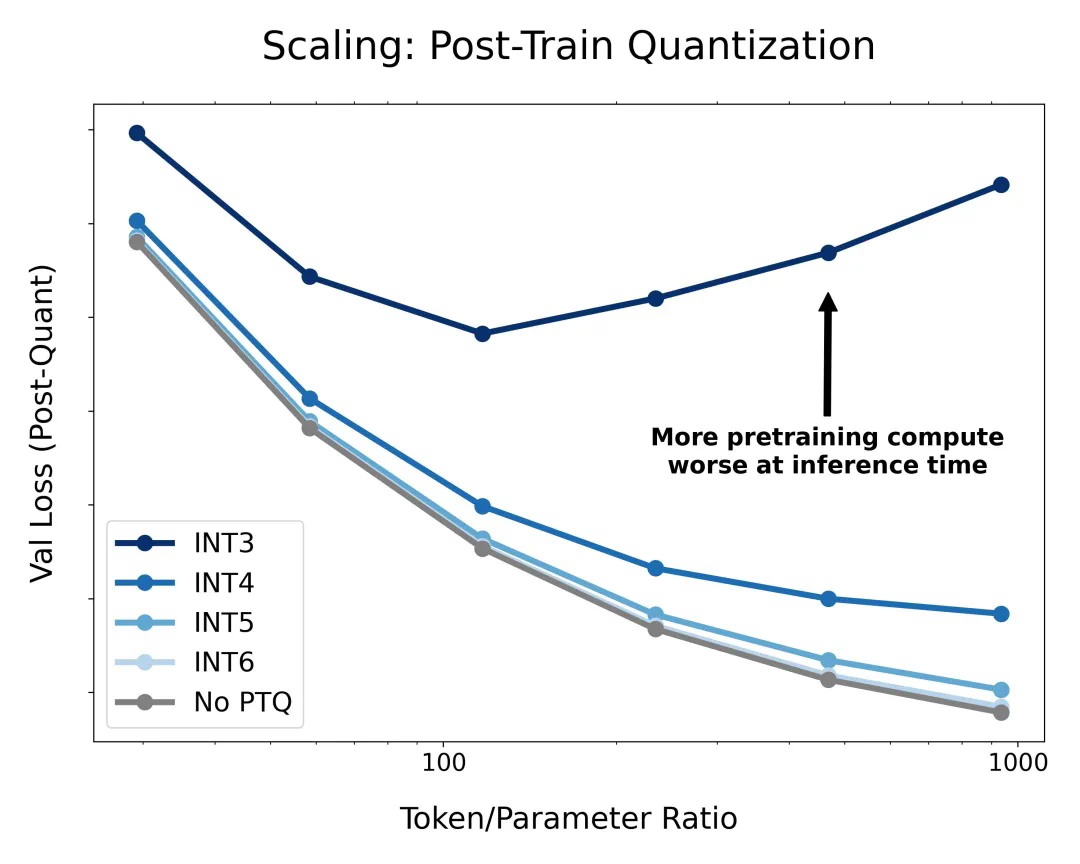
由于当代大模型在大量数据上经历了过度训练,因此训练后量化已变得非常困难。因此,如果在训练后量化,最终更多的预训练数据可能会造成副作用;
-
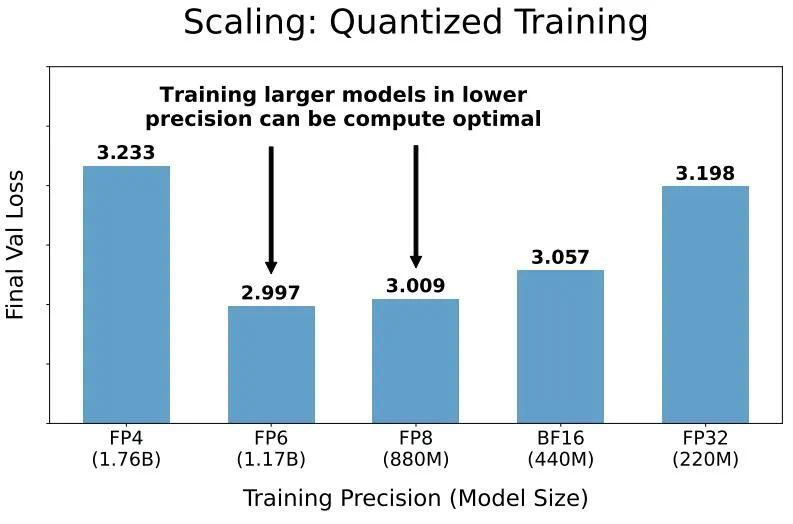
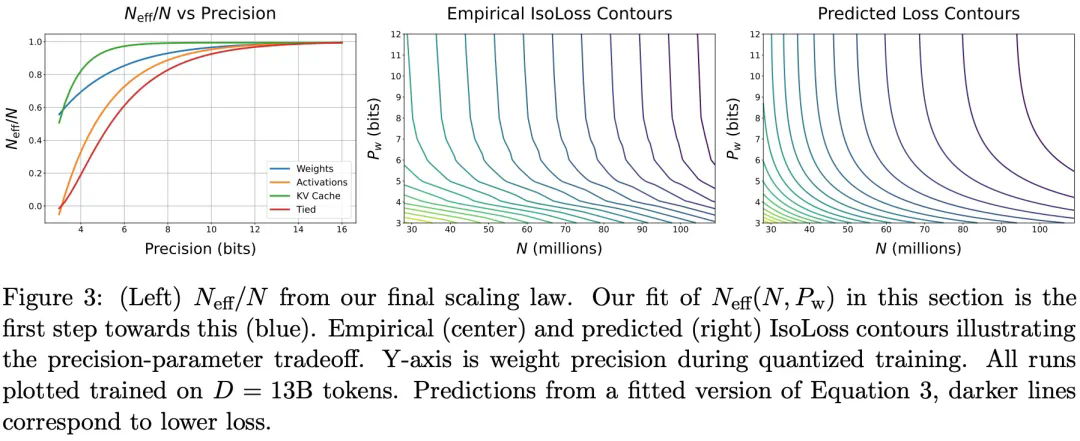
在预训练期间以不同的精度放置权重、激活或注意力的效果是一致且可预测的,并且拟合扩展定律表明,高精度(BF16)和下一代精度(FP4)的预训练可能都是次优的设计选择。
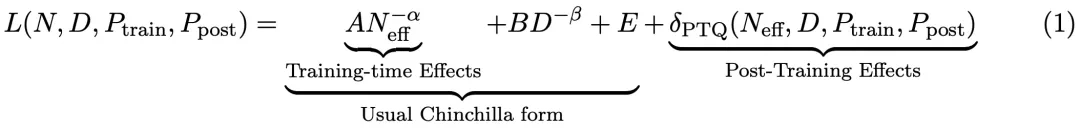



文章来源于互联网:Scaling Laws终结,量化无用,AI大佬都在审视这篇论文
