文章来源于互联网:Scaling Law 撞墙?复旦团队大模型推理新思路:Two-Player架构打破自我反思瓶颈

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
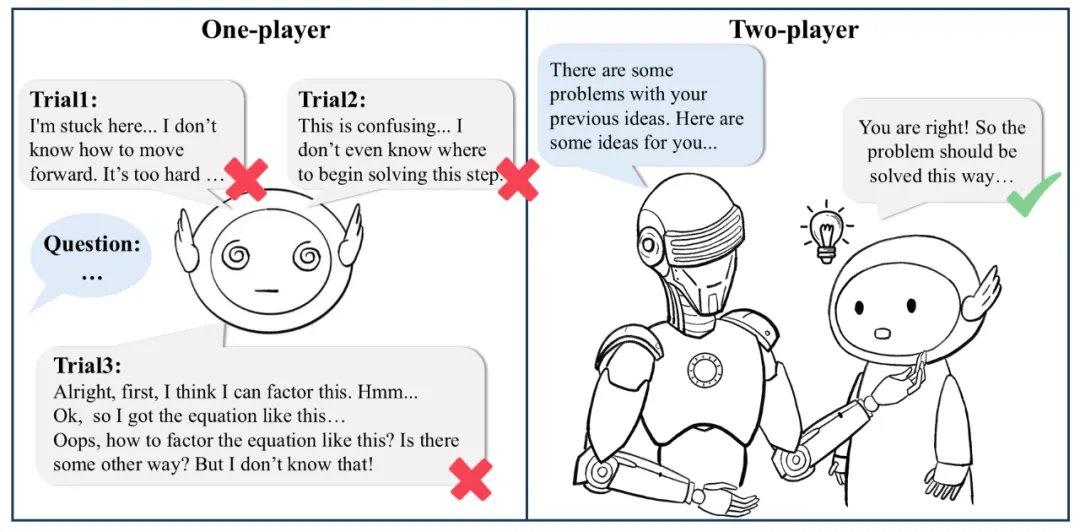
在 AI 领域,近期的新闻焦点无疑是关于「Scaling Law 是否撞墙?」的辩论。这一曾经被视作大模型发展的第一性原理,如今却遭遇了挑战。在这样的背景下,研究人员开始意识到,与其单纯堆砌更多的训练算力和数据资源,不如让模型「花更多时间思考」。以 OpenAI 推出的 o1 模型为例,通过增加推理时间,这种方法让模型能够进行反思、批评、回溯和纠正,大幅提升了推理表现。
但问题在于,传统的自我反思(Self-Reflection)和自我纠正(Self-Correction)方法存在明显局限 —— 模型的表现往往受制于自身能力,缺乏外部信号的引导,因此容易触及瓶颈,止步不前。
-
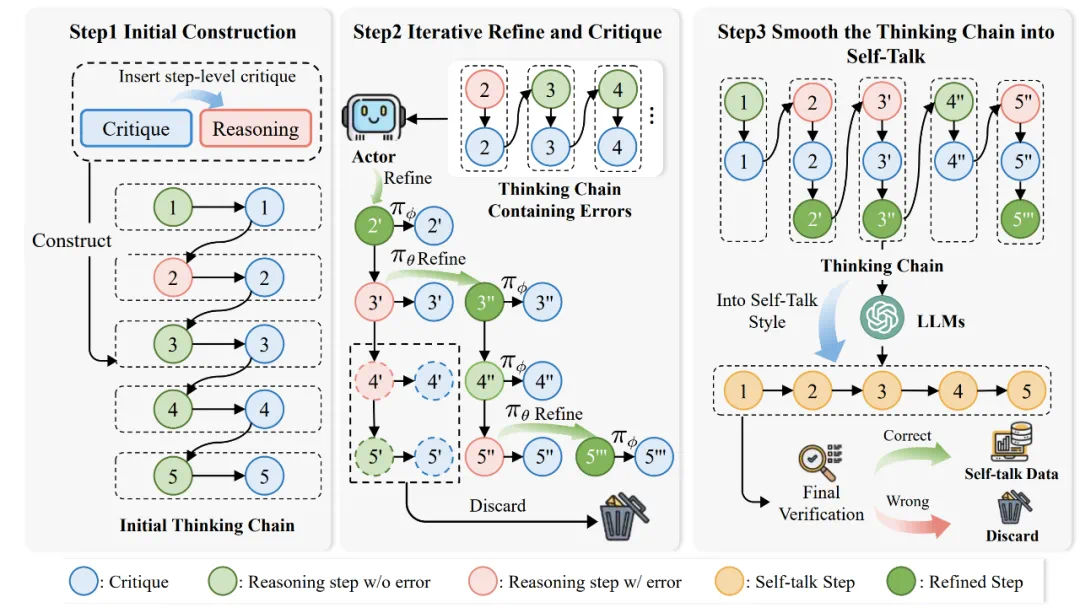
如何自动化构建 critique 数据集,训练高效、可靠的评判模型(Critique Model); -
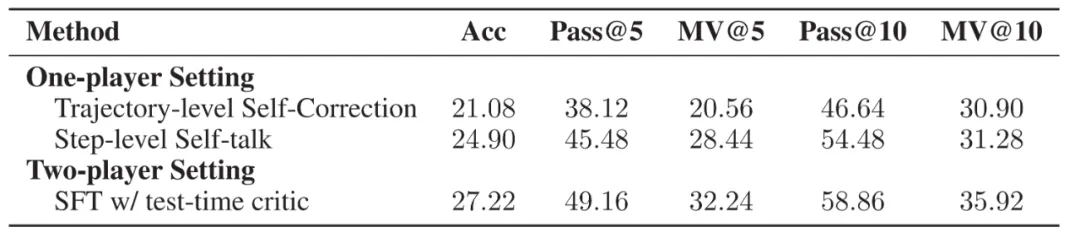
使用评判模型推动测试阶段的扩展(Test-time Scaling); -
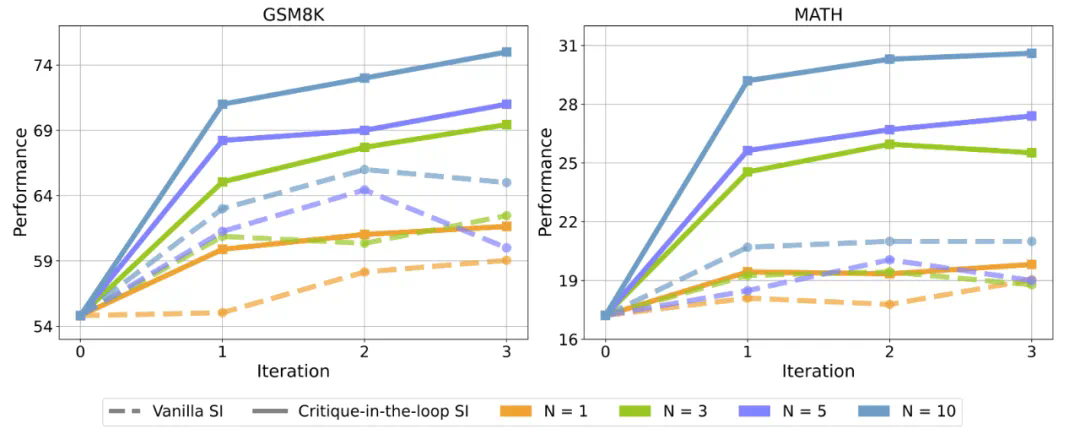
通过交互协作提升行为模型的训练性能(Training-time Scaling); -
基于 critique 数据的 Self-talk 帮助模型自我纠错。

-
论文题目:Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision -
论文地址:http://arxiv.org/abs/2411.16579 -
项目主页:https://mathcritique.github.io/ -
代码仓库:https://github.com/WooooDyy/MathCritique -
数据仓库:https://huggingface.co/datasets/MathCritique/MathCritique-76k -
本工作部分实验基于昇腾 910 完成
-
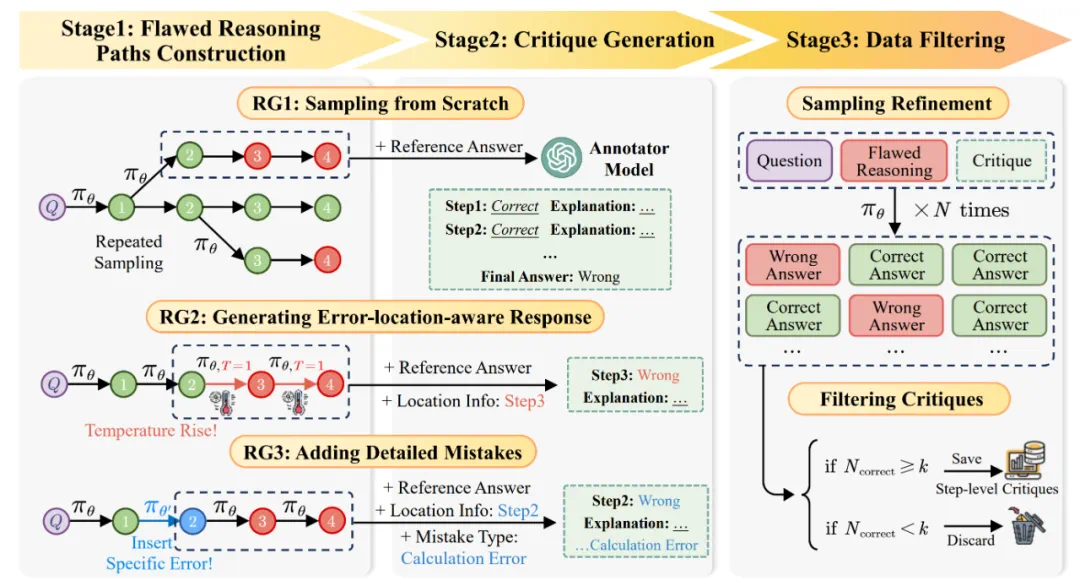
RG1: 直接构建整体推理路径,在高温度下让 Actor 模型进行重复采样,采样出的数据只会包含最终答案的错误信息; -
RG2: 以某一条推理路径为模板,在特定的推理步后逐渐提高温度,让 Actor 模型采样出新的轨迹,采样出的数据会包含最终答案的错误信息与错误步骤的位置信息; -
RG3: 以某一条推理路径为模板,对特定的推理步插入多样化错误内容,让 Actor 模型继续采样出完整轨迹,采样出的数据会包含最终答案的错误信息与错误步骤的位置与错误信息。
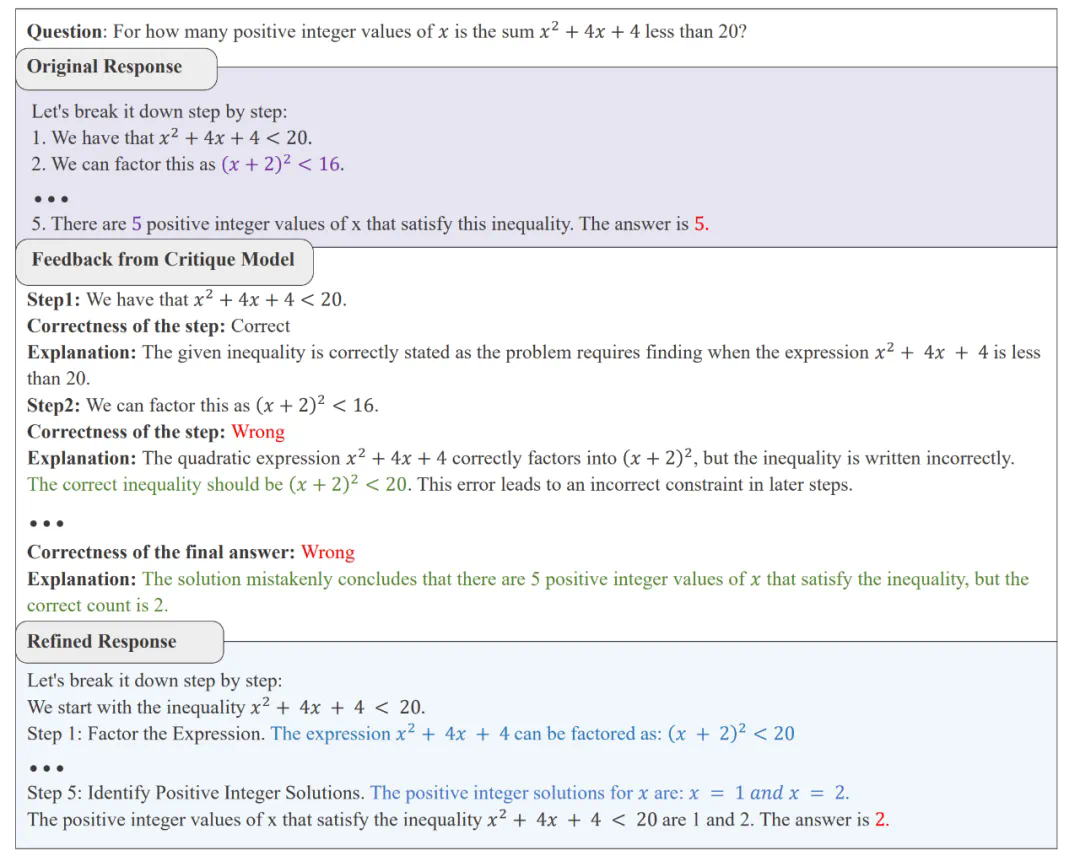

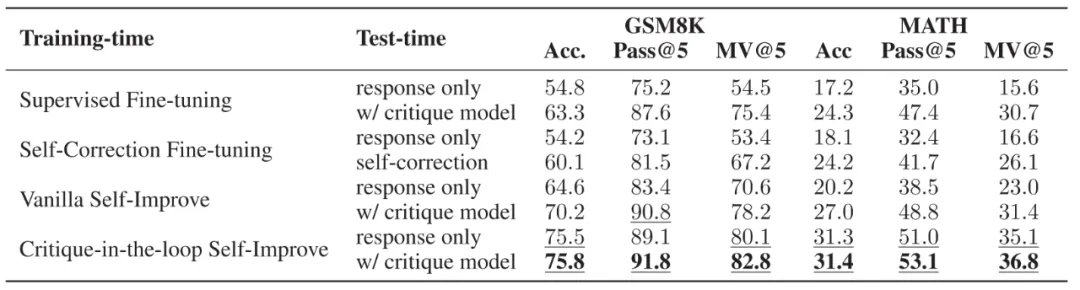
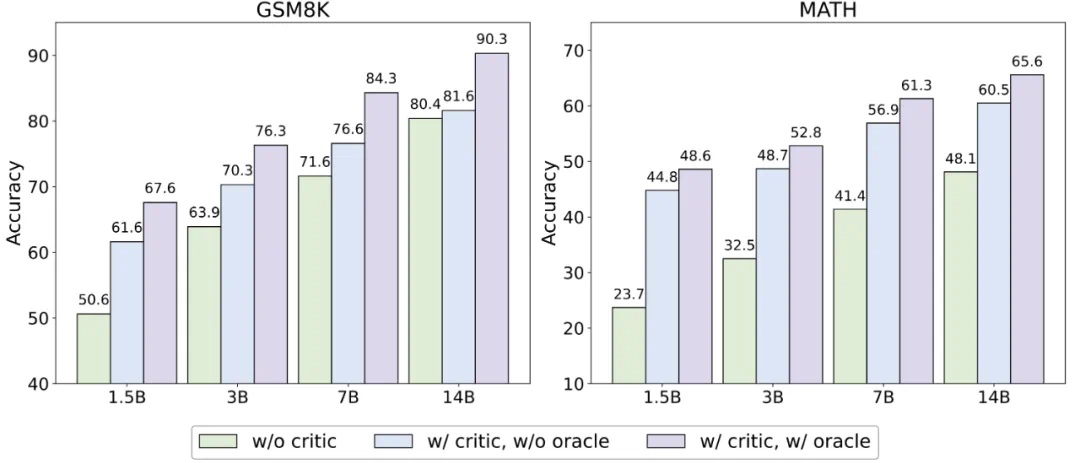
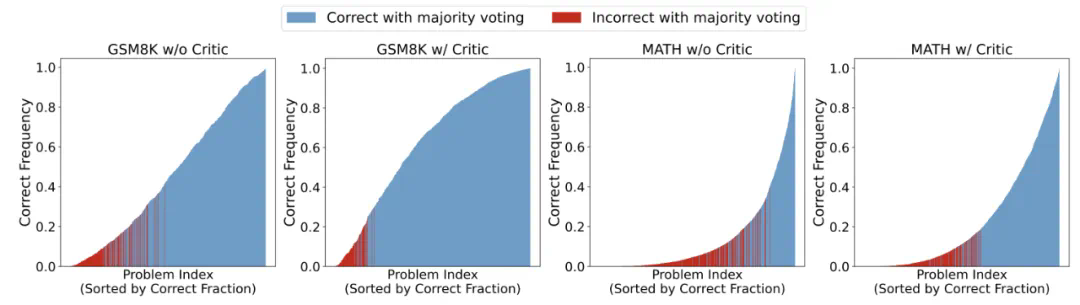
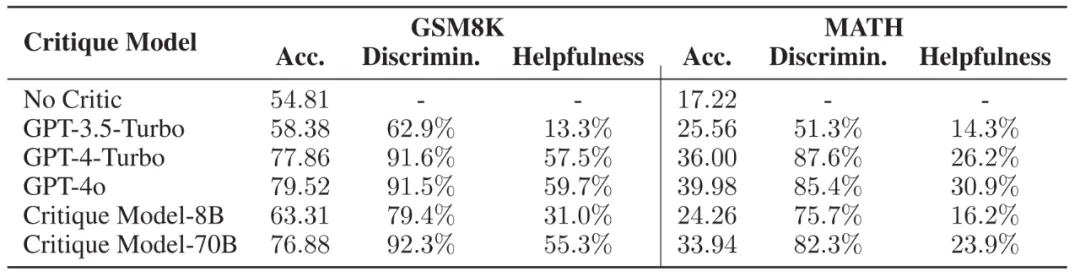 不同 Critique 模型的推理轨迹正误判断能力与对 Actor 模型的帮助,Acc. 代表 Actor 模型在不同 Critique 模型的帮助下能够达到的正确率。
不同 Critique 模型的推理轨迹正误判断能力与对 Actor 模型的帮助,Acc. 代表 Actor 模型在不同 Critique 模型的帮助下能够达到的正确率。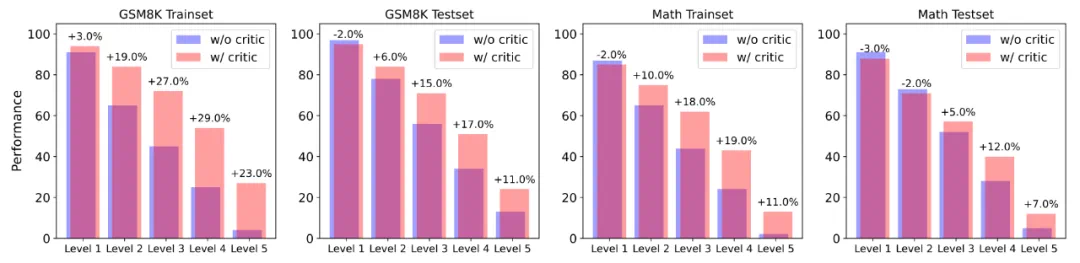




-
提出自动化构造步骤级别 Critique 的框架 AutoMathCritique; -
探究 Critique 模型对于 Actor 模型在推理时的帮助; -
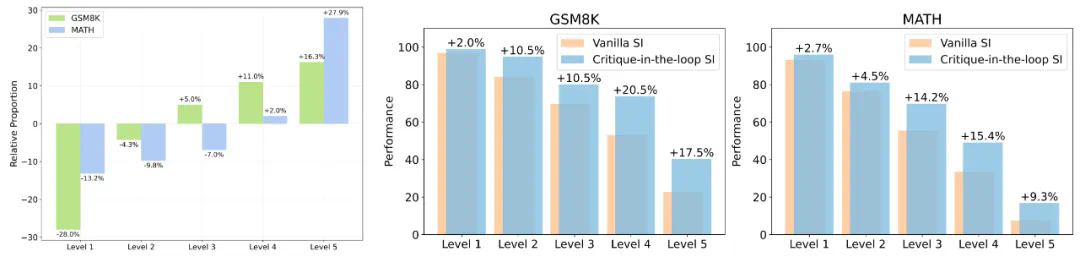
提出拥有难度感知方式的自我改进框架 Critique-in-the-loop Self-Improvement,缓解长尾难题; -
探究测试时的各种 Scaling 策略,包括模型大小,采样策略与采样数量等方面。
