文章来源于互联网:美欧亚三洲开发者联手,全球首个组团训练的大模型来了,全流程开源
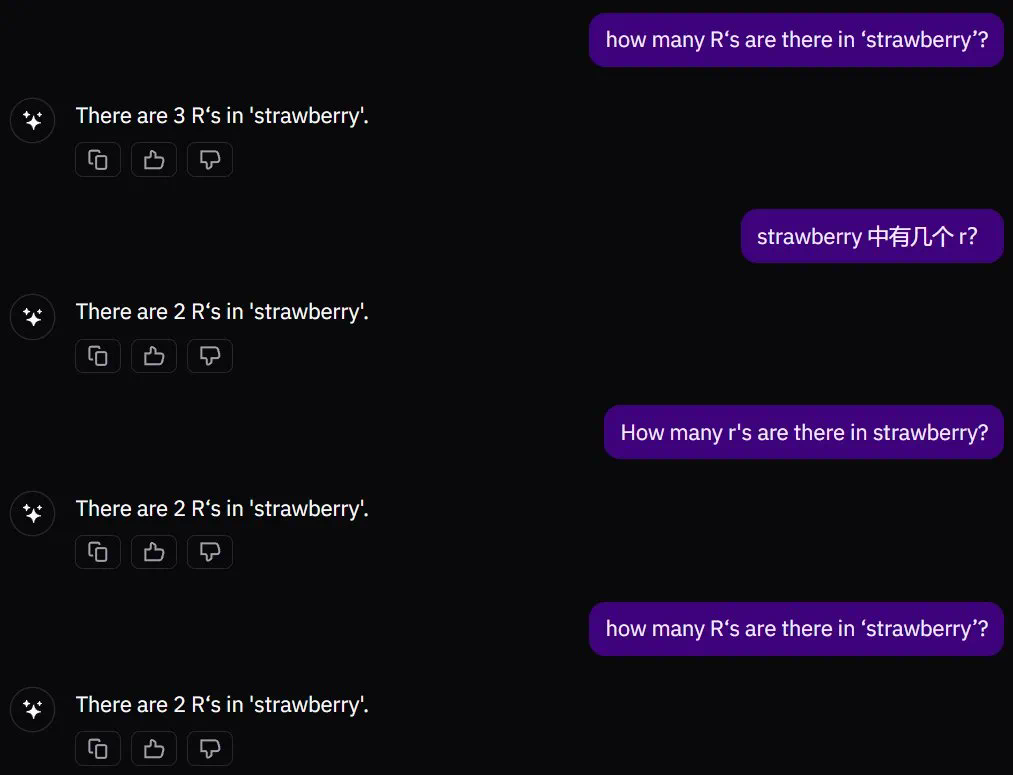
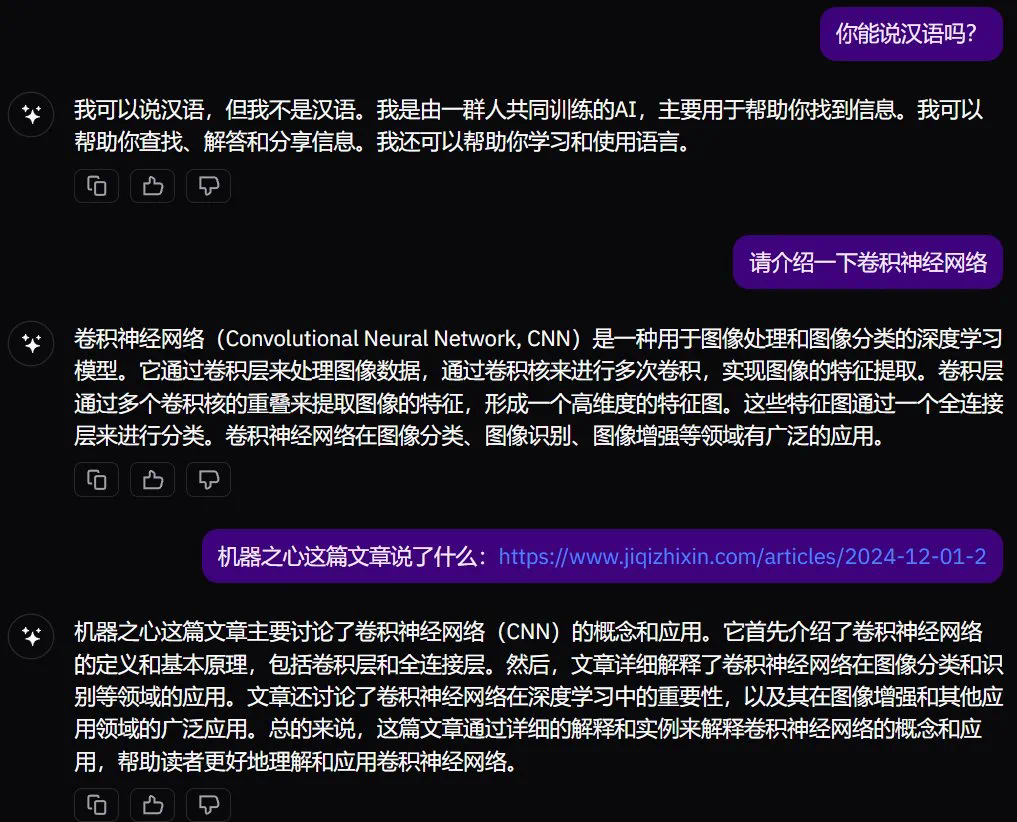
11 月 22 日,Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。

-
技术报告:https://github.com/PrimeIntellect-ai/prime/blob/main/INTELLECT_1_Technical_Report.pdf -
Hugging Face 页面:https://huggingface.co/PrimeIntellect/INTELLECT-1-Instruct -
GitHub 地址:https://github.com/PrimeIntellect-ai/prime -
体验链接:chat.primeintellect.ai


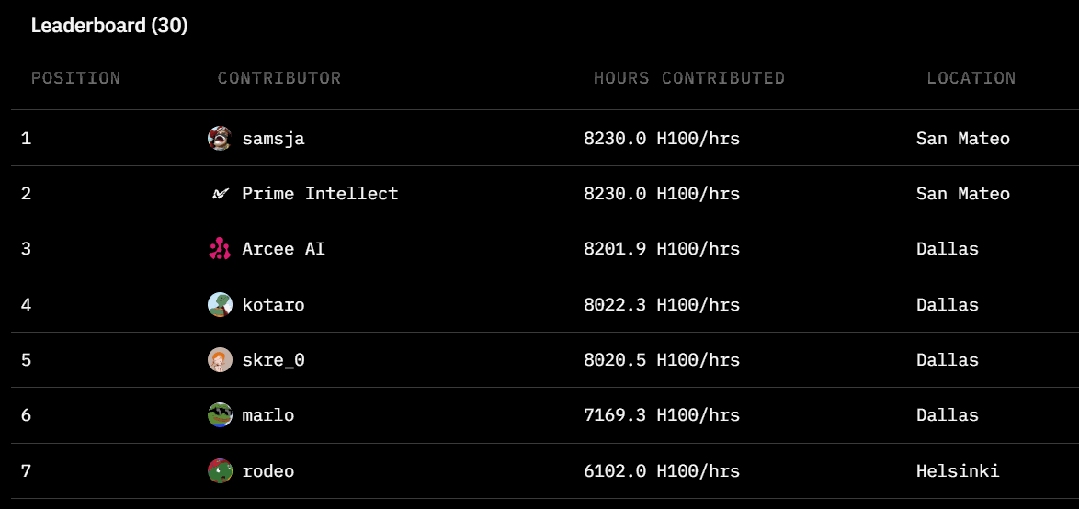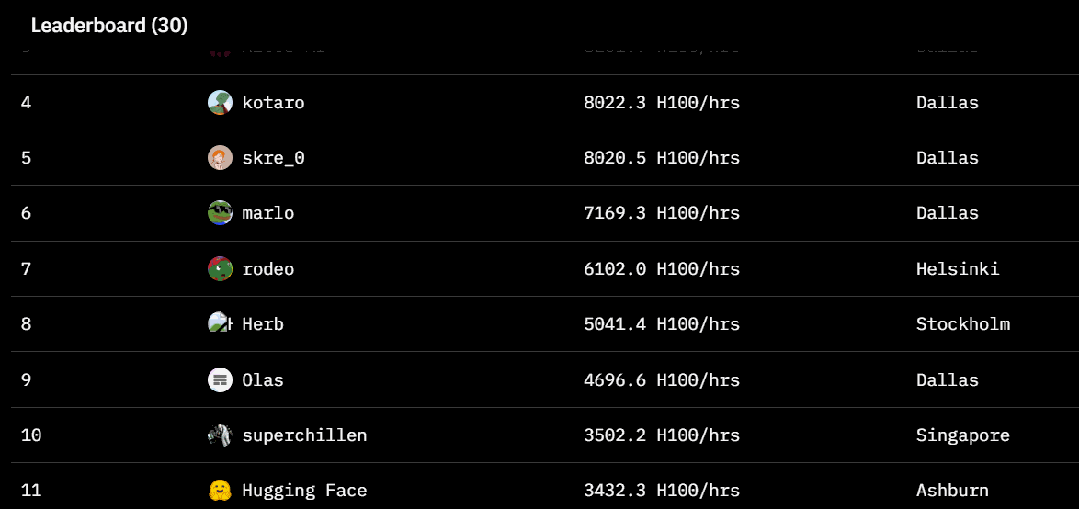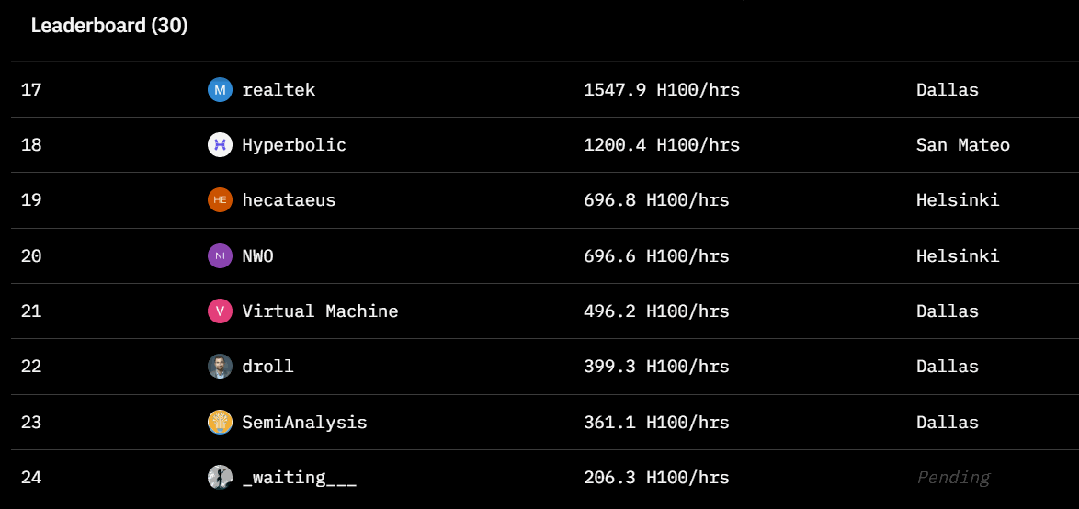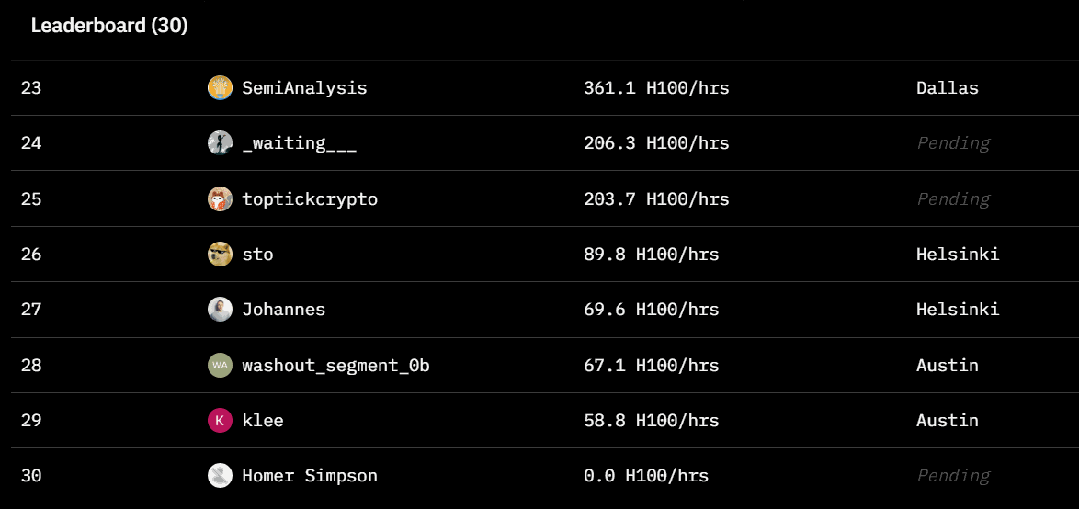
-
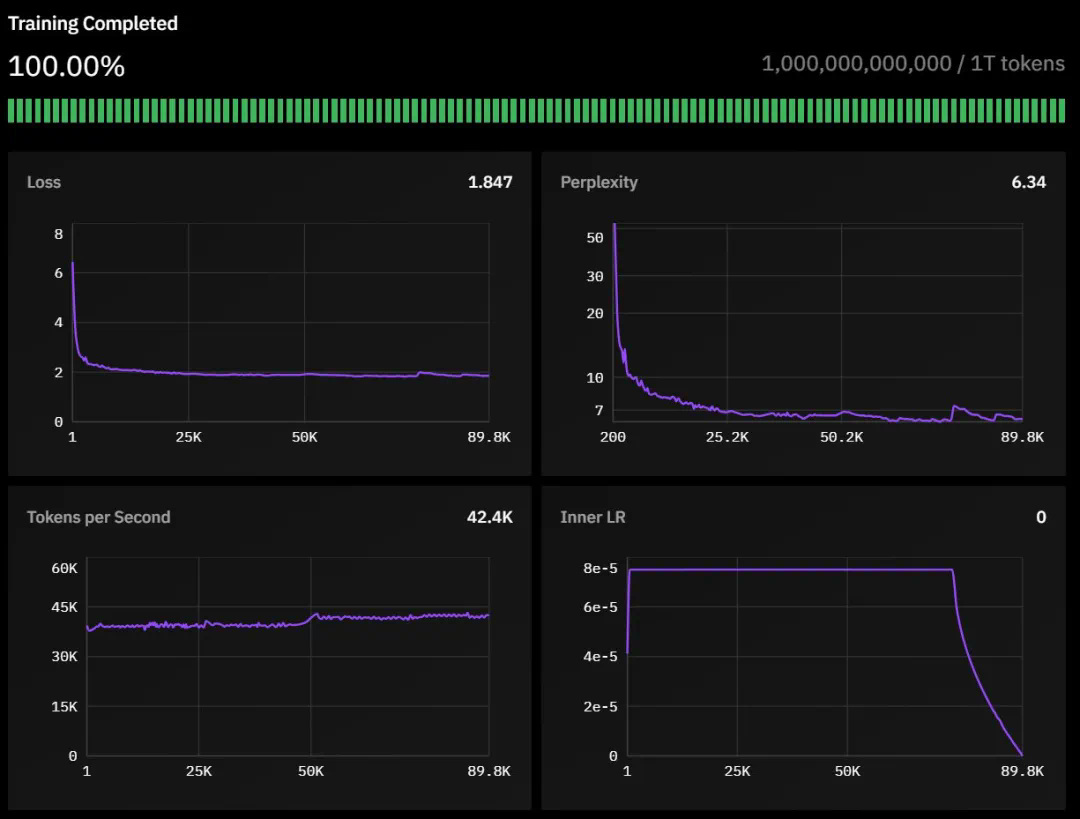
42 层,隐藏维度为 4,096 -
32 个注意力头 -
序列长度为 8,192 -
词表大小为 128,256
-
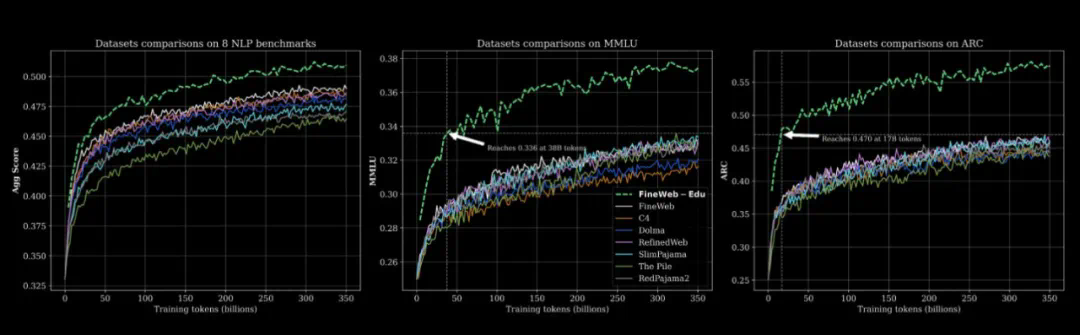
55% FineWeb-Edu -
20% Stack v2(Stack Overflow 等技术问答数据) -
10% FineWeb(精选网页数据) -
10% DCLM-baseline(基准通用语料) -
5% OpenWebMath(数学数据)
-
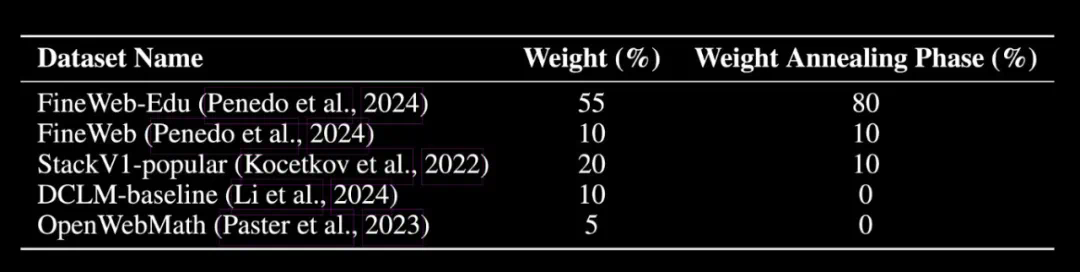
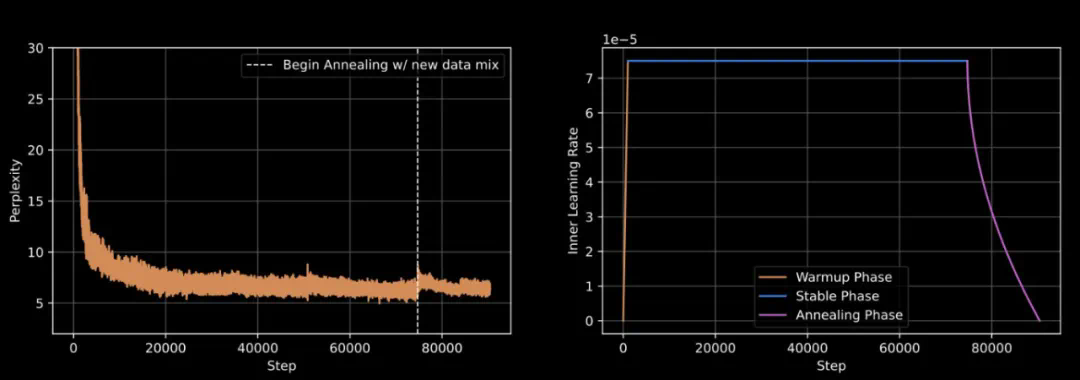
采用 WSD 动态调整学习速度,让模型学习更高效 -
精细调教的学习参数:内层学习率设为 7.5e-5 -
引入特殊的损失函数(max-z-loss)来确保训练过程的稳定性 -
使用 Nesterov 动量优化算法,帮助模型更快更好地学习 -
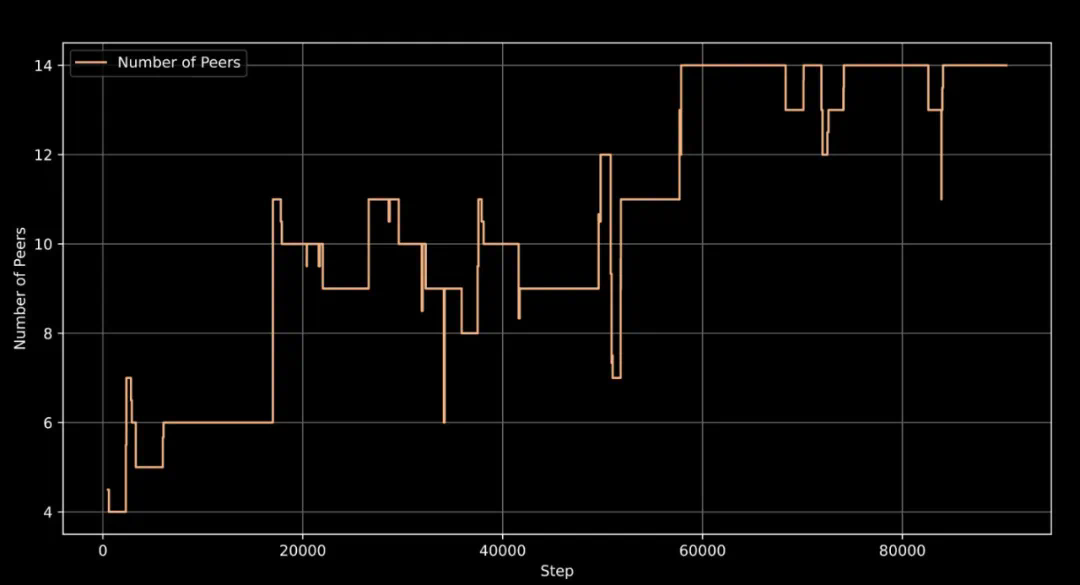
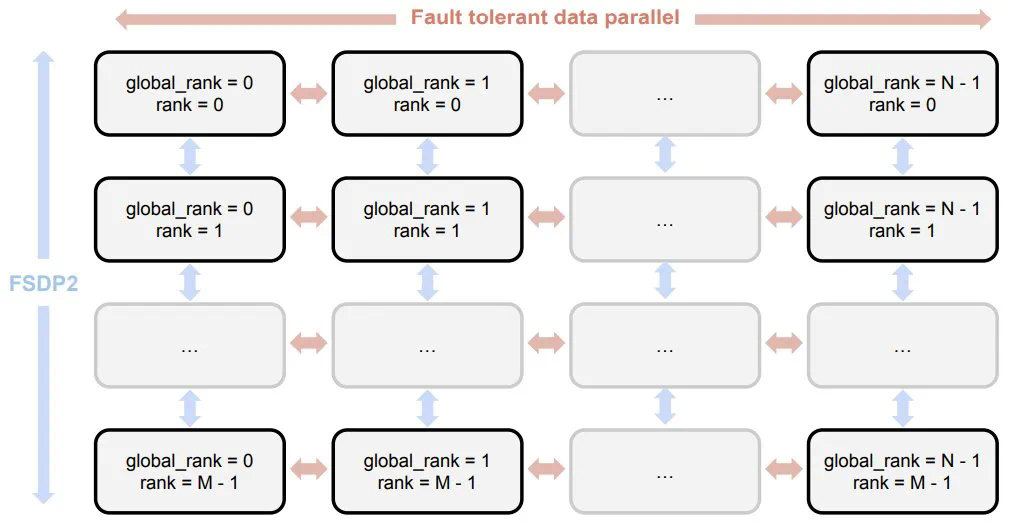
支持训练机器的灵活接入和退出,最多可同时使用 14 台机器协同训练

-
用于容错训练的 ElasticDeviceMesh -
异步分布式检查点 -
实时检查点恢复 -
自定义 Int8 All-Reduce 内核 -
最大化带宽利用率 -
PyTorch FSDP2 / DTensor ZeRO-3 实现 -
CPU 卸载

-
SFT(监督微调,16 轮) -
DPO(直接偏好优化,8 轮) -
使用 MergeKit 整合训练成果

-
继续扩大全球计算网络 -
用更多奖金激励推动社区参与 -
进一步优化 PRIME 去中心化训练架构以支持更大的模型
文章来源于互联网:美欧亚三洲开发者联手,全球首个组团训练的大模型来了,全流程开源
