内容目录
文章来源于互联网:「See Video, Get 3D」,智源开源无标注视频学习3D生成模型See3D
近日,著名 AI 学者、斯坦福大学教授李飞飞团队 World Labs 推出首个【空间智能】模型,仅输入单张图片,即可生成一个逼真的 3D 世界,这被认为是迈向空间智能的第一步。
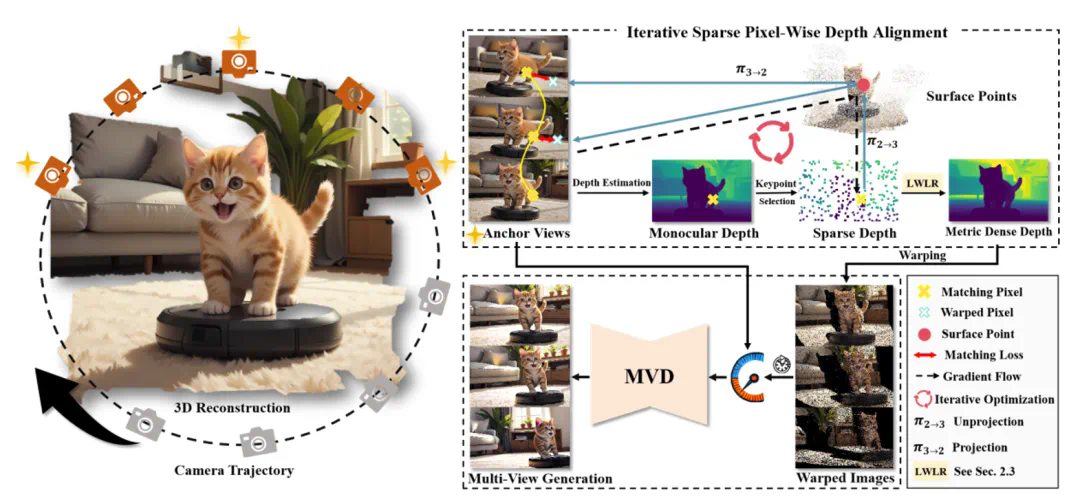
几乎同时,国内智源研究院推出了首个利用大规模无标注的互联网视频学习的 3D 生成模型 See3D—See Video, Get 3D。不同于传统依赖相机参数(pose-condition)的 3D 生成模型,See3D 采用全新的视觉条件(visual-condition)技术,仅依赖视频中的视觉线索,生成相机方向可控且几何一致的多视角图像。这一方法不依赖于昂贵的 3D 或相机标注,能够高效地从多样化、易获取的互联网视频中学习 3D 先验。See3D 不仅支持零样本和开放世界的 3D 生成,还无需微调即可执行 3D 编辑、表面重建等任务,展现出在多种 3D 创作应用中的广泛适用性。
 See3D 支持从文本、单视图和稀疏视图到 3D 的生成,同时还可支持 3D 编辑与高斯渲染。
See3D 支持从文本、单视图和稀疏视图到 3D 的生成,同时还可支持 3D 编辑与高斯渲染。-
论文地址: https://arxiv.org/abs/2412.06699 -
项目地址: https://vision.baai.ac.cn/see3d


 基于 6 张视图的 3D 重建
基于 6 张视图的 3D 重建 


WebVi3D 数据集样本展示
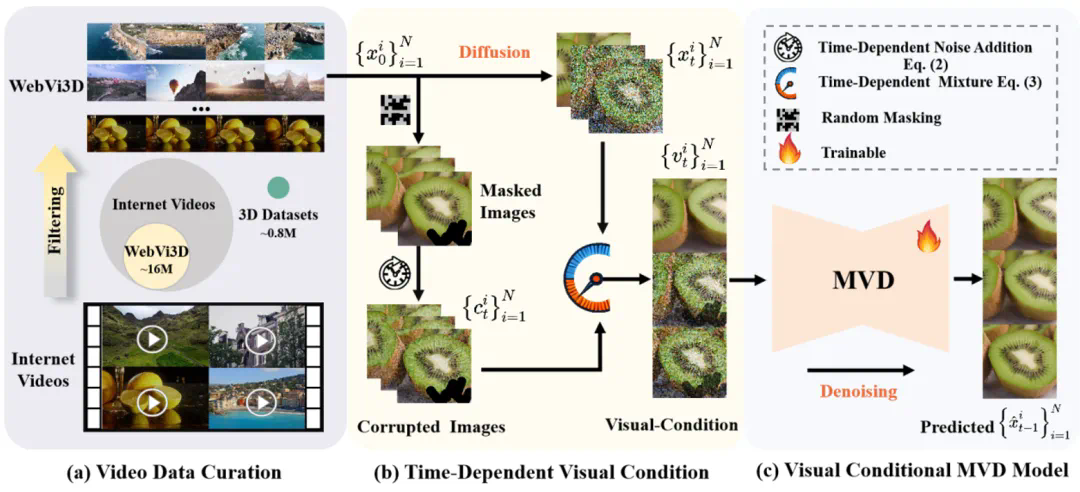 See3D 方法展示
See3D 方法展示