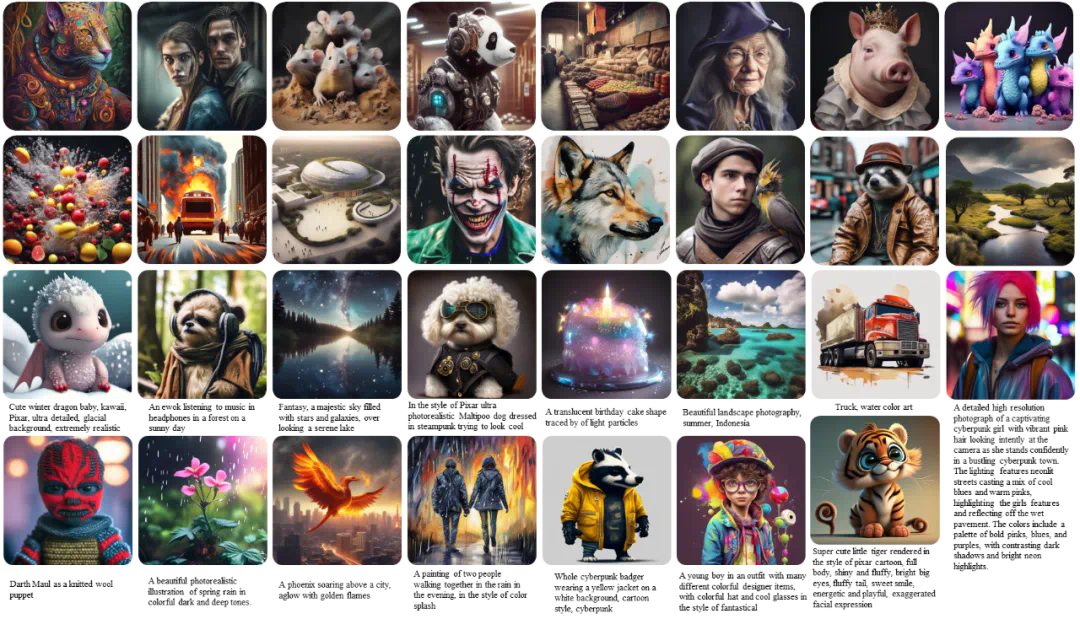
文章来源于互联网:理解生成协同促进?华为诺亚提出ILLUME,15M数据实现多模态理解生成一体化

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
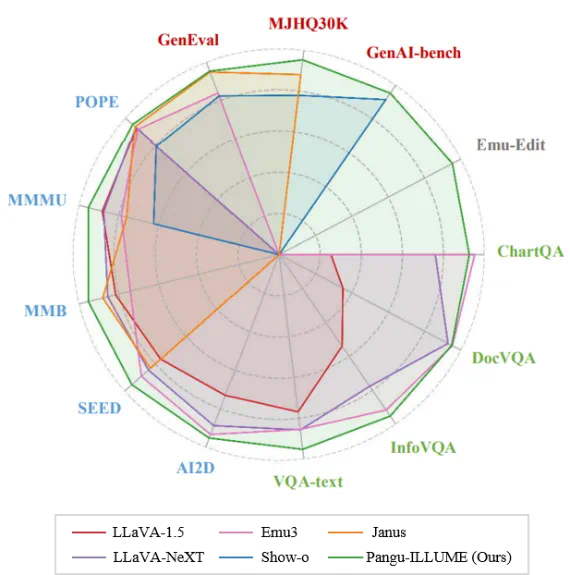
多模态理解与生成一体化模型,致力于将视觉理解与生成能力融入同一框架,不仅推动了任务协同与泛化能力的突破,更重要的是,它代表着对类人智能(AGI)的一种深层探索。通过在单一模型中统一理解与生成,模型能够从语义层面真正 “洞察” 视觉、文本与世界本质之间的深层联系,从而在复杂场景中实现更加智能、灵活的交互与任务执行。
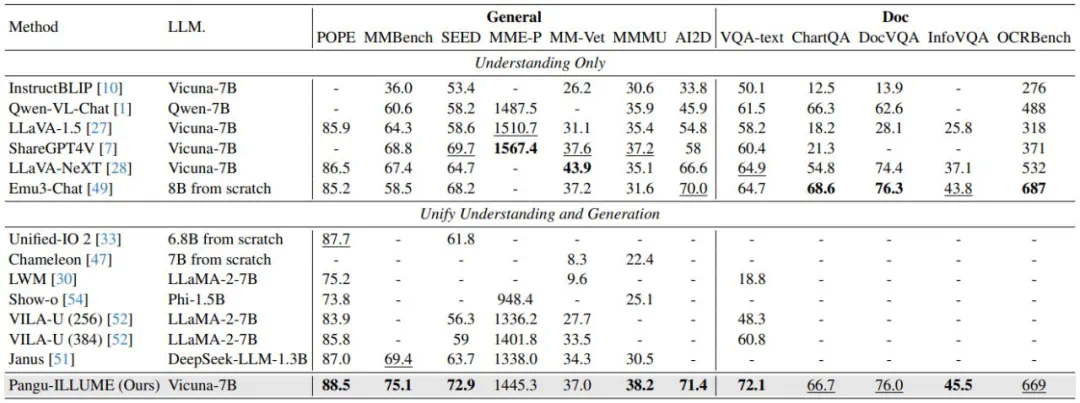
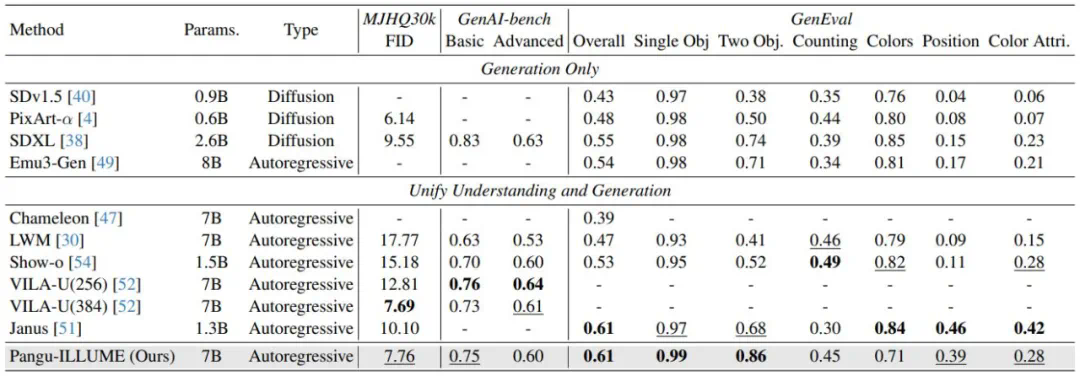
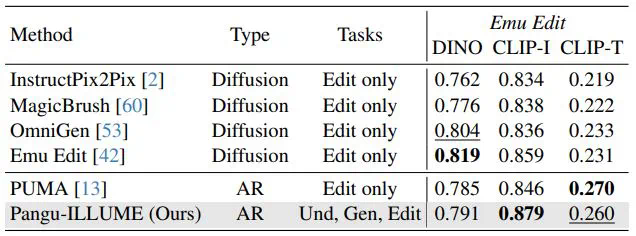
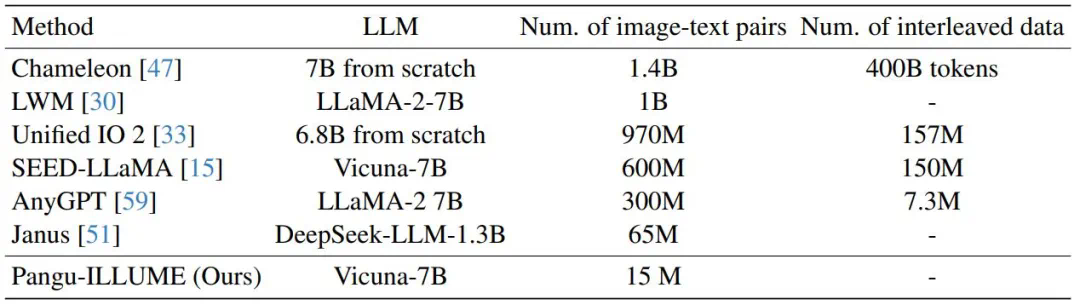
近期,华为诺亚方舟实验室提出了统一多模态大模型 ——ILLUME。这一模型以 LLM 为核心,采用 “连续图像输入 + 离散图像输出” 的架构,巧妙融合了多模态理解与生成的双重能力,并深度挖掘了统一框架下理解与生成能力协同增强的潜力,展示了对多模态任务的全新诠释。

-
论文标题:ILLUME: Illuminating Your LLMs to See, Draw, and Self-Enhance -
论文地址:https://arxiv.org/pdf/2412.06673

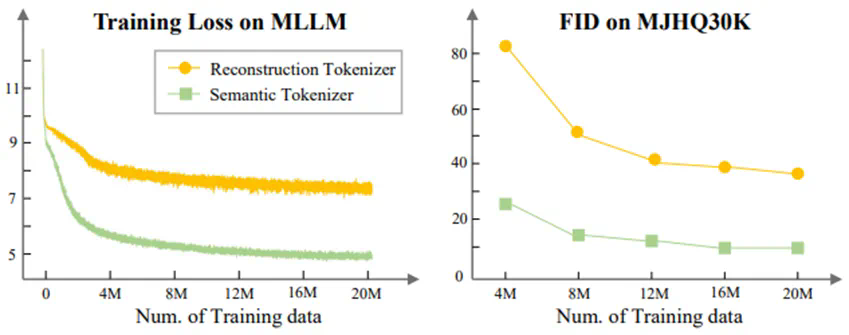
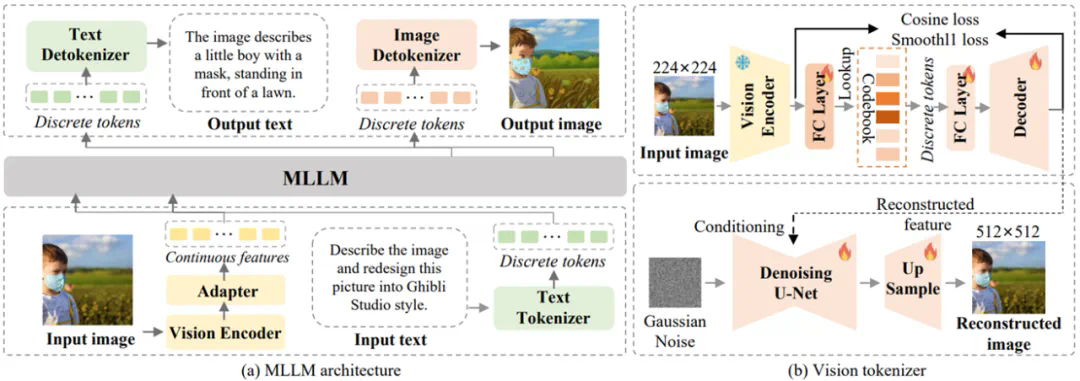
-
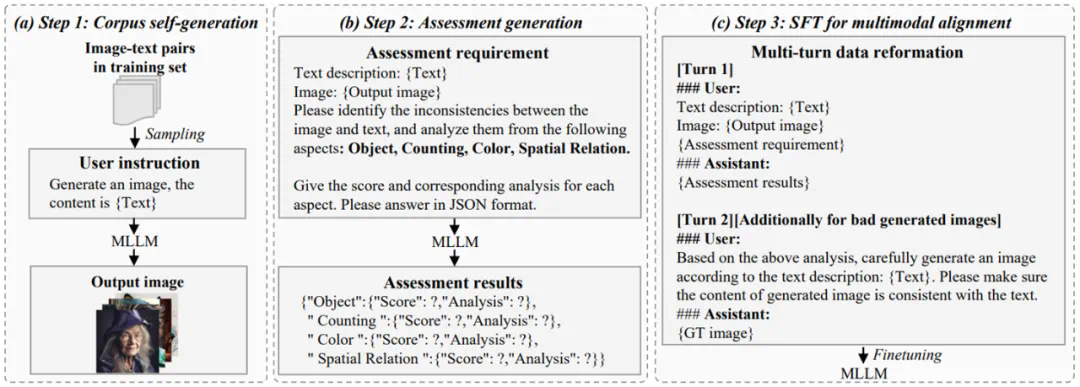
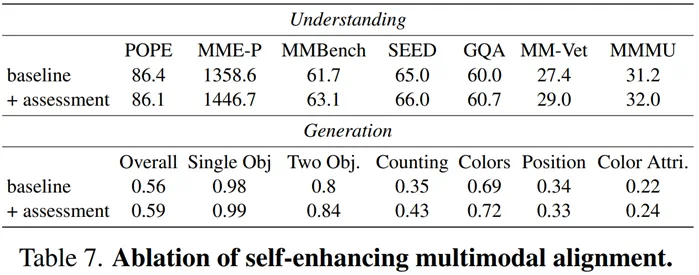
生成促进理解:模型以自我评估的方式分析自己产生的负样本,这种内省过程使模型能够查明并解决其自身弱点,从而更准确地理解图像。 -
理解促进生成:模型可以利用其判别能力来评估其自生成的图像是否与文本一致,并基于此分析进行修正,从而确保模型在推理时更加谨慎和准确,避免在生成图像时出现错误。
-
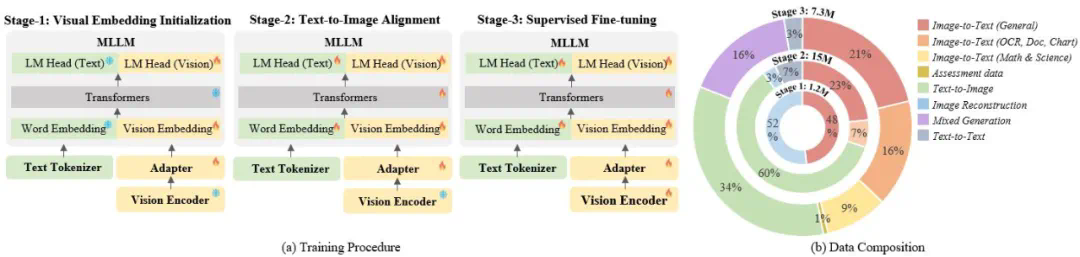
Step 1: 语料自生成。采样训练子集,推理模型生成图像。 -
Step 2: 生成评估数据。从物体、数量、颜色和空间关系多个维度评估图像和文本的一致性,评估数据包括评估得分和相应的分析。 -
Step 3: 多模态对齐。将评估数据重新格式化后加入阶段三训练,使模型在理解与生成层面同时得到强化。