文章来源于互联网:全新模型RoboVLMs解锁VLA无限可能,真实机器人实验交出满分答卷

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com


-
论文标题:Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models -
论文地址:https://arxiv.org/pdf/2412.14058
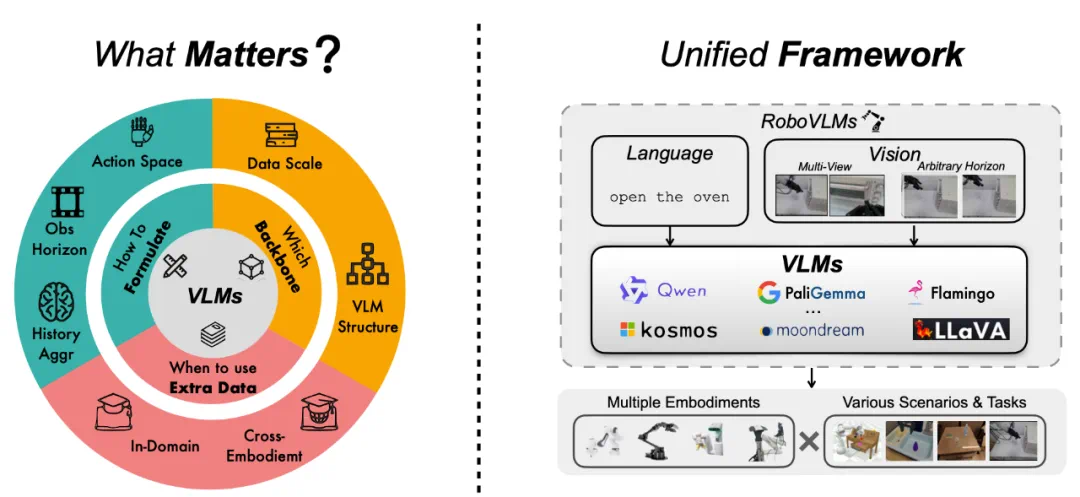
-
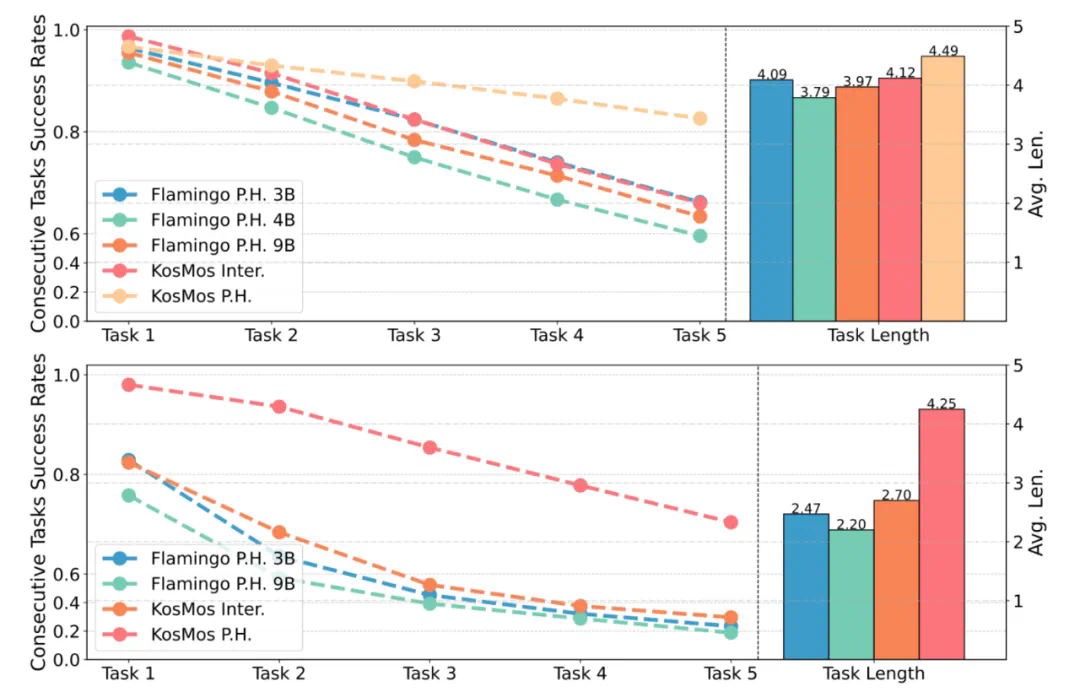
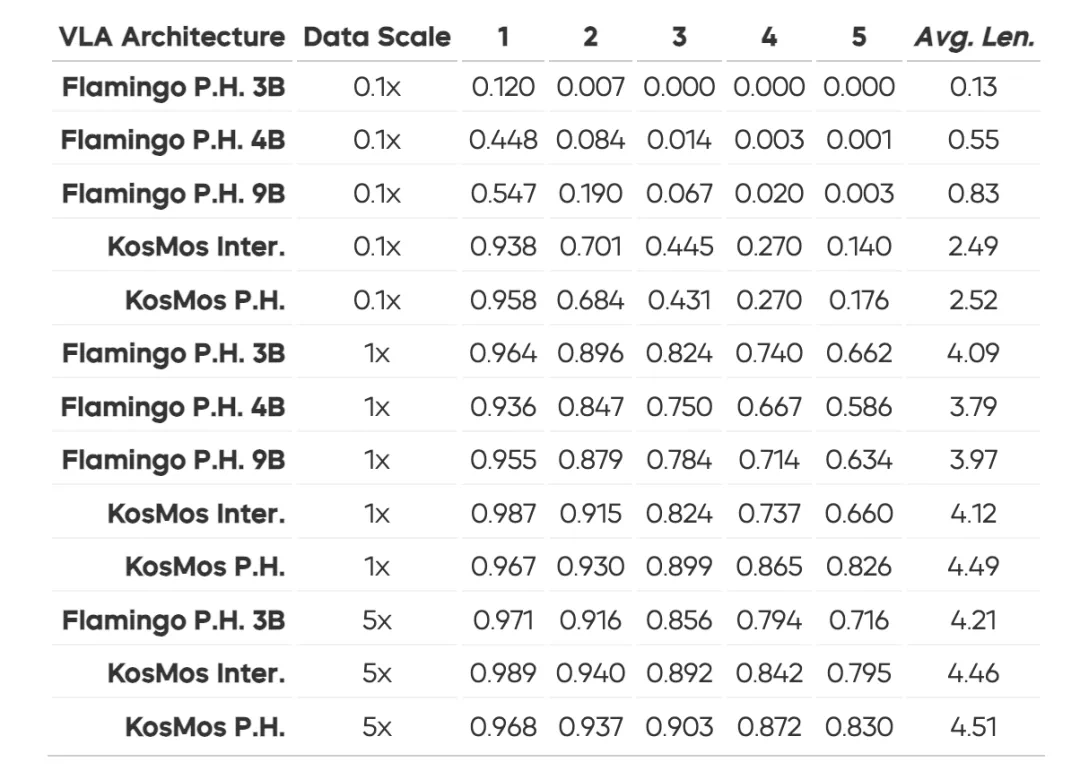
任务成功率:表现稳定且超越主流模型。 -
泛化能力:即使在陌生场景中,表现依然抗打!
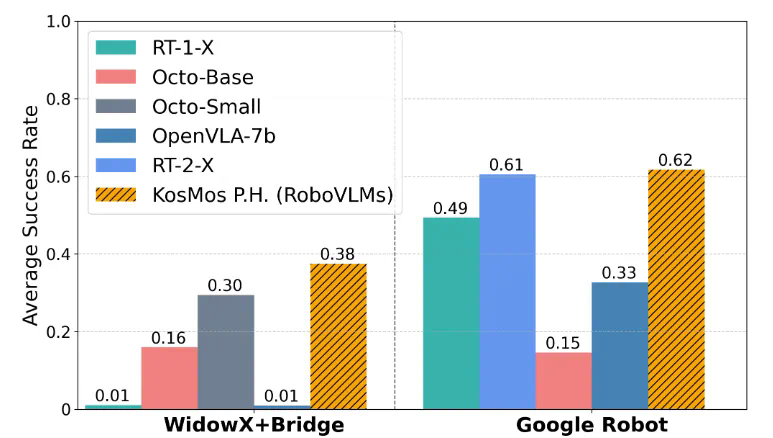
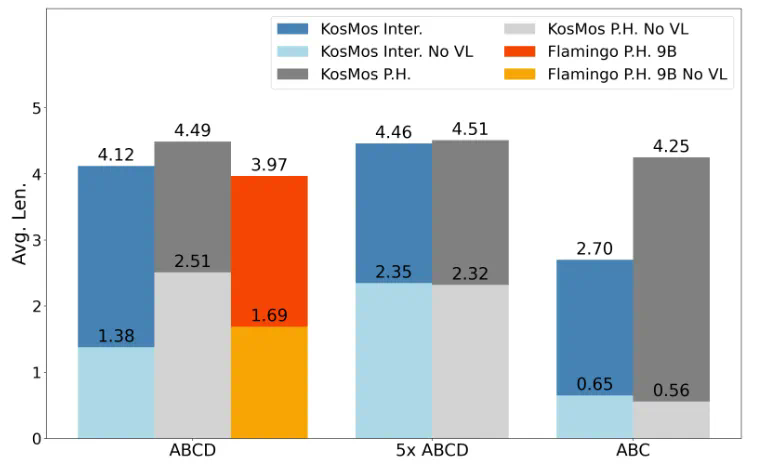


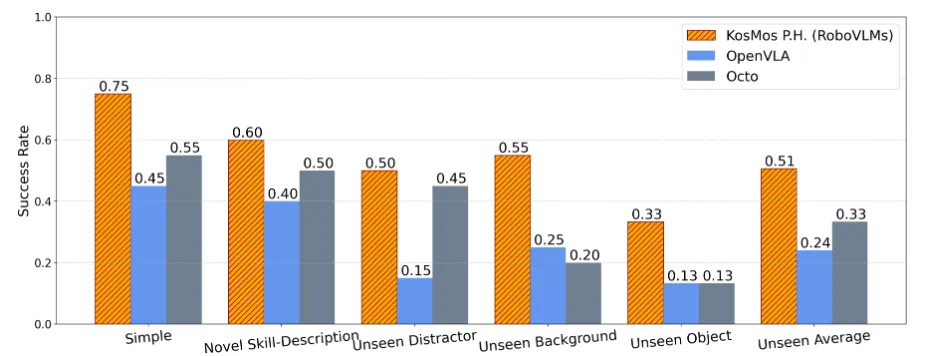

-
动作空间:用连续动作空间比离散的好很多。 -
历史信息:加多步历史信息后,模型的操作更稳准狠。 -
历史信息组织模块:一个专门的模块可以让模型更懂 “上下文”。
-
Bridge Finetune:直接在完整的 Bridge 数据集上微调(测试任务不包括在内)。 -
OXE Pre-Train:先用 OXE 数据集预训练模型。 -
Post-Train:用经过 OXE 预训练的模型再在 Bridge 数据集上微调。
-
RT-Partial Finetune:仅在特定的 RT 任务上微调。 -
RT Finetune:在完整的 RT 数据集上微调(包括测试任务)。 -
OXE Pre-Train:先用 OXE 数据集预训练模型。 -
Post-Train:在 OXE 预训练基础上用 RT 数据集进一步训练。

-
更细化的设计优化:比如再打磨 VLM 内部结构、信息融合模块和训练目标,让它更高效。 -
挑战复杂任务:像 “做早餐” 这种长链条任务,也许是下一个突破点! -
多模态协作能力:进一步让机器人 “看懂”、“听清”、“动得更聪明”。
文章来源于互联网:全新模型RoboVLMs解锁VLA无限可能,真实机器人实验交出满分答卷
